Can Subgraph Explanations Be Weaponized to Steal Graph Neural Networks?
Pith reviewed 2026-06-29 08:31 UTC · model grok-4.3
The pith
Binary explanation masks from graph models enable model extraction attacks under strict black-box constraints with only labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
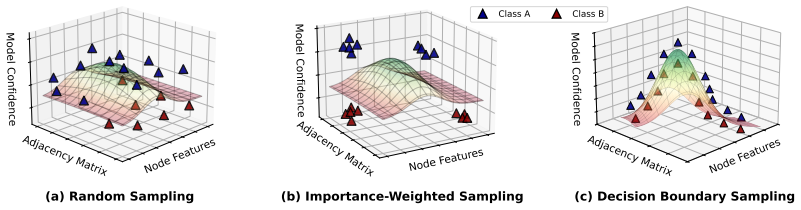
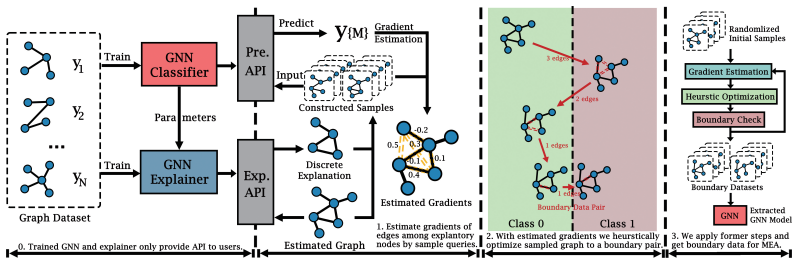
The attack uses model-generated binary explanation masks to direct Monte Carlo sampling of edge sensitivities toward decision boundaries, with provable concentration bounds on estimation accuracy, while the masks themselves narrow the boundary search space for efficient extraction of graph classifiers.
What carries the argument
Explanation-guided Monte Carlo edge sensitivity estimation that leverages binary masks to prioritize edges near decision boundaries and reduce search space.
If this is right
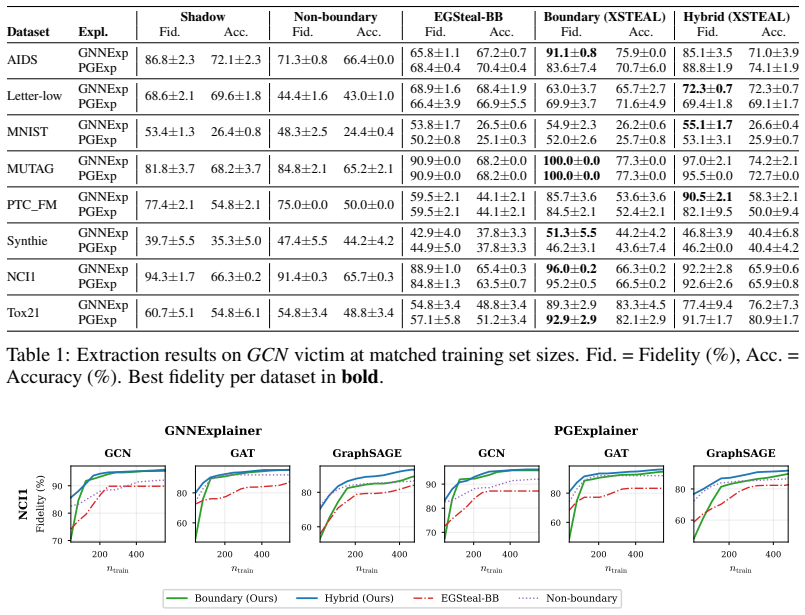
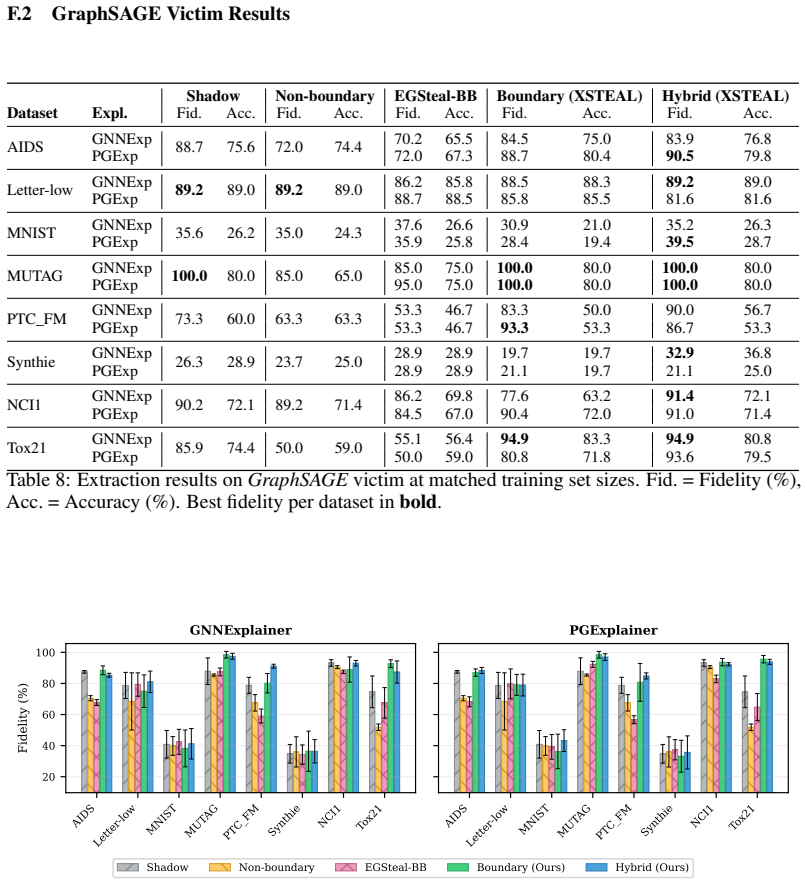
- The method extracts surrogate models that match target accuracy on benchmark graph datasets from multiple domains.
- It outperforms prior black-box extraction baselines that lack access to explanation outputs.
- Explainability interfaces in GMLaaS platforms constitute exploitable attack surfaces even under label-only constraints.
- Results inform both technical defenses and policy considerations around mandatory explainability requirements.
Where Pith is reading between the lines
- Similar attacks could target other structured data domains if explanations reveal decision-relevant substructures.
- Adding controlled noise to explanation masks might serve as a lightweight defense without fully removing transparency.
- Regulators mandating explanations may need to weigh extraction risks against transparency benefits in high-stakes graph applications.
Load-bearing premise
The binary explanation masks produced by the target model carry enough structural information about decision boundaries to meaningfully improve Monte Carlo sampling without any continuous model outputs.
What would settle it
An experiment replacing the model's binary explanation masks with random binary masks of the same density and measuring whether extraction accuracy drops to levels indistinguishable from uniform random querying.
Figures



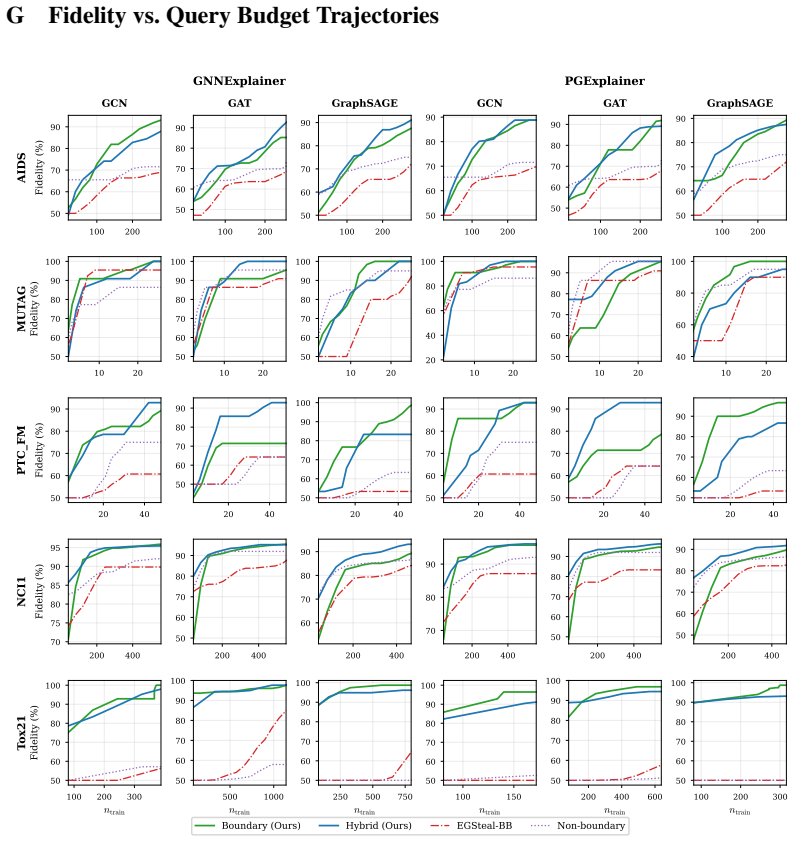
read the original abstract
Graph Machine Learning as a Service (GMLaaS) platforms increasingly implement explainability interfaces to meet regulatory transparency requirements. However, this transparency creates exploitable vulnerabilities for model extraction attacks. We present the first model extraction attack specifically designed for graph classification under strict black-box constraints where the attacker observes only discrete class labels and binary explanation masks (no probability scores, gradients, or confidence values). Our method (1) uses model explanation outputs to guide Monte Carlo edge sensitivity estimation toward decision boundaries, with Hoeffding concentration guarantees on estimation accuracy and (2) exploits explanation subgraphs to efficiently narrow the boundary search space. Extensive experiments on benchmark graph datasets across multiple domains demonstrate our method's superiority over comparable baselines. These findings demonstrate that such explainability interfaces create exploitable attack surfaces, informing both defensive mechanisms and policy frameworks for explainable AI mandates. The implementation code is provided in https://github.com/LabRAI/XSTEAL/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the first model extraction attack on graph neural networks for classification under strict black-box access (only discrete labels and binary explanation masks). The attack guides Monte Carlo edge-sensitivity estimation toward decision boundaries using explanation outputs, invokes Hoeffding concentration bounds for accuracy guarantees, and narrows the search via explanation subgraphs. Experiments on benchmark graph datasets reportedly show superiority over baselines; code is released.
Significance. If the attack and its guarantees hold, the work identifies a concrete attack surface created by mandatory explainability interfaces in GMLaaS, with implications for defenses and policy. Releasing implementation code is a positive contribution to reproducibility. The result would be of interest to the graph-ML security community, though its impact is limited by the unresolved dependence issue in the concentration analysis.
major comments (1)
- [Abstract / Method (Hoeffding section)] Abstract and method description (Hoeffding application): the stated 'Hoeffding concentration guarantees on estimation accuracy' for Monte Carlo edge sensitivity rest on an independence assumption that is violated by graph structure. Perturbing one edge changes neighborhoods and thus the sensitivity estimates of adjacent edges; the manuscript does not derive or substitute a dependence-aware bound (e.g., via McDiarmid or graph-specific concentration), so the claimed accuracy guarantees on the recovered decision boundary are not supported.
minor comments (1)
- [Abstract] The abstract refers to 'benchmark graph datasets across multiple domains' without naming them or providing basic statistics (node/edge counts, class balance); moving a concise table of dataset characteristics to §4 or the experimental setup would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The identification of the dependence issue in the concentration analysis is a valid technical point that we address directly below.
read point-by-point responses
-
Referee: [Abstract / Method (Hoeffding section)] Abstract and method description (Hoeffding application): the stated 'Hoeffding concentration guarantees on estimation accuracy' for Monte Carlo edge sensitivity estimation rest on an independence assumption that is violated by graph structure. Perturbing one edge changes neighborhoods and thus the sensitivity estimates of adjacent edges; the manuscript does not derive or substitute a dependence-aware bound (e.g., via McDiarmid or graph-specific concentration), so the claimed accuracy guarantees on the recovered decision boundary are not supported.
Authors: We agree that this is a substantive issue. The manuscript invokes the standard Hoeffding inequality for the Monte Carlo edge-sensitivity estimates, which formally requires independent samples. Because perturbing one edge alters node neighborhoods, the sensitivity estimates for adjacent edges are statistically dependent; no dependence-aware concentration inequality (such as McDiarmid) or graph-specific analysis is derived or substituted. Consequently, the claimed accuracy guarantees on the recovered decision boundary are not rigorously supported by the stated argument. We will revise the abstract and the Hoeffding subsection to remove the language of 'Hoeffding concentration guarantees.' The Monte Carlo procedure will instead be presented as an empirical estimator whose practical accuracy is demonstrated by the experimental results. A brief discussion noting the dependence limitation and the possibility of future work on bounded-difference or graph-concentration bounds will be added if space allows. These changes will appear in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution is an attack method that applies standard Monte Carlo edge sensitivity estimation guided by binary explanation masks, combined with Hoeffding concentration bounds for accuracy guarantees. No load-bearing step reduces by the paper's own equations to a fitted parameter, self-citation chain, or definitional equivalence; the derivation relies on independent application of concentration inequalities to the proposed sampling procedure without smuggling ansatzes or renaming known results as novel derivations.
Axiom & Free-Parameter Ledger
free parameters (1)
- Monte Carlo sample count
axioms (1)
- standard math Hoeffding's inequality provides valid concentration bounds on the Monte Carlo edge sensitivity estimates
Reference graph
Works this paper leans on
-
[1]
Build a GNN-based real-time fraud detection solution using Amazon SageMaker, Amazon Neptune, and the Deep Graph Library
Amazon Web Services. Build a GNN-based real-time fraud detection solution using Amazon SageMaker, Amazon Neptune, and the Deep Graph Library. https://aws.amazon.com/blo gs/machine-learning/build-a-gnn-based-real-time-fraud-detection-solut ion-using-amazon-sagemaker-amazon-neptune-and-the-deep-graph-library/ , Aug. 2022
2022
-
[2]
M. Biton Dor and Y . Mirsky. Efficient model extraction via boundary sampling. InProceedings of the 2024 Workshop on Artificial Intelligence and Security, AISec ’24, page 1–11, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400712289. doi: 10.1145/3689932.3694756. URLhttps://doi.org/10.1145/3689932.3694756
-
[3]
Biton Dor and Y
M. Biton Dor and Y . Mirsky. Efficient model extraction via boundary sampling. InProceedings of the 2024 Workshop on Artificial Intelligence and Security, pages 1–11, 2024
2024
-
[4]
S. Boucheron, G. Lugosi, and P. Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 02 2013. ISBN 9780199535255. doi: 10.1093/acprof:oso/9780199535255.001.0001. URL https://doi.org/10.1093/acprof: oso/9780199535255.001.0001
work page doi:10.1093/acprof:oso/9780199535255.001.0001 2013
- [5]
-
[6]
SB24-205: Concerning Consumer Protections in Interactions with Artificial Intelligence Systems, 2024
Colorado General Assembly. SB24-205: Concerning Consumer Protections in Interactions with Artificial Intelligence Systems, 2024. URL https://leg.colorado.gov/bills/sb24-205
2024
-
[7]
H. Dai, H. Li, T. Tian, X. Huang, L. Wang, J. Zhu, and L. Song. Adversarial attack on graph structured data, 2018. URLhttps://arxiv.org/abs/1806.02371
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [8]
- [9]
-
[10]
Regulation (eu) 2024/1689 laying down harmonised rules on artificial intelligence (artificial intelligence act)
European Parliament and Council of the European Union. Regulation (eu) 2024/1689 laying down harmonised rules on artificial intelligence (artificial intelligence act). Official Journal of the European Union, L 2024/1689, July 2024
2024
-
[11]
F. Guan, T. Zhu, H. Tong, and W. Zhou. A realistic model extraction attack against graph neural networks.Knowledge-Based Systems, 300:112144, 2024. ISSN 0950-7051. doi: https://doi.org/10.1016/j.knosys.2024.112144. URL https://www.sciencedirect.com/sc ience/article/pii/S0950705124007780
-
[12]
W. L. Hamilton, R. Ying, and J. Leskovec. Inductive representation learning on large graphs,
-
[13]
URLhttps://arxiv.org/abs/1706.02216
work page internal anchor Pith review Pith/arXiv arXiv
- [14]
-
[15]
T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks,
-
[16]
URLhttps://arxiv.org/abs/1609.02907
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
-
[18]
Z. Li, X. Yuan, B. Shen, K. Le, H. Wang, X. Zhou, S. Gao, and Y . Dong. Query-efficient domain knowledge stealing against large language models.Proceedings of the AAAI Conference on Artificial Intelligence, 40(38):31870–31878, Mar. 2026. doi: 10.1609/aaai.v40i38.40456. URL https://ojs.aaai.org/index.php/AAAI/article/view/40456
-
[19]
D. Luo, W. Cheng, D. Xu, W. Yu, B. Zong, H. Chen, and X. Zhang. Parameterized explainer for graph neural network. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 19620–19631. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/p aper/2020...
2020
-
[20]
B. Ma, Y . Feng, M. Lin, and E. Dai. How explanations leak the decision logic: Stealing graph neural networks via explanation alignment, 2025. URL https://arxiv.org/abs/2506.0 3087
2025
-
[21]
N. Maslej, L. Fattorini, R. Perrault, Y . Gil, V . Parli, N. Kariuki, E. Capstick, A. Reuel, E. Bryn- jolfsson, J. Etchemendy, K. Ligett, T. Lyons, J. Manyika, J. C. Niebles, Y . Shoham, R. Wald, T. Walsh, A. Hamrah, L. Santarlasci, J. B. Lotufo, A. Rome, A. Shi, and S. Oak. Artificial intelligence index report 2025, 2025. URLhttps://arxiv.org/abs/2504.07139
-
[22]
S. Milli, L. Schmidt, A. D. Dragan, and M. Hardt. Model reconstruction from model explanations. InProceedings of the Conference on Fairness, Accountability, and Trans- parency, FAT* ’19, page 1–9, New York, NY , USA, 2019. Association for Computing Machinery. ISBN 9781450361255. doi: 10.1145/3287560.3287562. URL https: //doi.org/10.1145/3287560.3287562
-
[23]
T. Miura, T. Shibahara, and N. Yanai. Megex: Data-free model extraction attack against gradient- based explainable ai. InProceedings of the 2nd ACM Workshop on Secure and Trustworthy Deep Learning Systems, SecTL ’24, page 56–66, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400706912. doi: 10.1145/3665451.3665533. URL https://doi...
-
[24]
D. Molina-Pérez, E. A. Portilla-Flores, E. Mezura-Montes, E. Vega-Alvarado, and M. B. Calva- Yañez. Efficiently handling constraints in mixed-integer nonlinear programming problems using gradient-based repair differential evolution.PeerJ Computer Science, 10:e2095, May 2024. ISSN 2376-5992. doi: 10.7717/peerj-cs.2095. URL https://doi.org/10.7717/peerj-c s.2095
-
[25]
Geometric deep learning on graphs and manifolds using mixture model CNNs
F. Monti, D. Boscaini, J. Masci, E. Rodolà, J. Svoboda, and M. M. Bronstein. Geometric deep learning on graphs and manifolds using mixture model cnns, 2016. URL https://arxiv.or g/abs/1611.08402
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
TUDataset: A collection of benchmark datasets for learning with graphs
C. Morris, N. M. Kriege, F. Bause, K. Kersting, P. Mutzel, and M. Neumann. Tudataset: A collection of benchmark datasets for learning with graphs, 2020. URL https://arxiv.org/ abs/2007.08663
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[27]
O. Nimase, Y . Zhao, and Y . Dong. Navigating between explainability and extractability in machine learning as a service. In2025 IEEE International Conference on Data Mining Workshops (ICDMW), pages 2483–2487, 2025. doi: 10.1109/ICDMW69685.2025.00305
-
[28]
A. C. Oksuz, A. Halimi, and E. Ayday. Autolycus: Exploiting explainable artificial in- telligence (xai) for model extraction attacks against interpretable models.Proceedings on Privacy Enhancing Technologies, 2024(4):684–699, Oct. 2024. ISSN 2299-0984. doi: 10.56553/popets-2024-0137. URLhttp://dx.doi.org/10.56553/popets-2024-0137
-
[29]
D. Oliynyk, R. Mayer, and A. Rauber. I know what you trained last summer: A survey on stealing machine learning models and defences.ACM Comput. Surv., 55(14s), July 2023. ISSN 0360-0300. doi: 10.1145/3595292. URLhttps://doi.org/10.1145/3595292
-
[30]
Practical Black-Box Attacks against Machine Learning
N. Papernot, P. McDaniel, I. Goodfellow, S. Jha, Z. B. Celik, and A. Swami. Practical black-box attacks against machine learning, 2017. URLhttps://arxiv.org/abs/1602.02697. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
C. Piao, T. Xu, X. Sun, Y . Rong, K. Zhao, and H. Cheng. Computing graph edit distance via neural graph matching.Proc. VLDB Endow., 16(8):1817–1829, Apr. 2023. ISSN 2150-8097. doi: 10.14778/3594512.3594514. URLhttps://doi.org/10.14778/3594512.3594514
-
[32]
M. Podhajski, J. Dubi ´nski, F. Boenisch, A. Dziedzic, A. Pregowska, and T. P. Michalak. Efficient model-stealing attacks against inductive graph neural networks, 2024. URL https: //arxiv.org/abs/2405.12295
-
[33]
Riesen and H
K. Riesen and H. Bunke. Iam graph database repository for graph based pattern recognition and machine learning. In N. da Vitoria Lobo, T. Kasparis, F. Roli, J. T. Kwok, M. Georgiopoulos, G. C. Anagnostopoulos, and M. Loog, editors,Structural, Syntactic, and Statistical Pattern Recognition, pages 287–297, Berlin, Heidelberg, 2008. Springer Berlin Heidelber...
2008
-
[34]
R. Rosenbacke, Å. Melhus, M. McKee, and D. Stuckler. How explainable artificial intelligence can increase or decrease clinicians’ trust in AI applications in health care: Systematic review. JMIR AI, 3:e53207, 2024. doi: 10.2196/53207. URLhttps://doi.org/10.2196/53207
- [35]
- [36]
-
[37]
Tramèr, F
F. Tramèr, F. Zhang, A. Juels, M. K. Reiter, and T. Ristenpart. Stealing machine learning models via prediction apis. InProceedings of the 25th USENIX Conference on Security Symposium, SEC’16, page 601–618, USA, 2016. USENIX Association. ISBN 9781931971324
2016
-
[38]
GNNIE: GNN-recommender-as-a-service
UC Berkeley School of Information. GNNIE: GNN-recommender-as-a-service. https: //www.ischool.berkeley.edu/projects/2022/gnnie-gnn-recommender-service , 2023
2022
-
[39]
P. Veliˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y . Bengio. Graph attention networks, 2018. URLhttps://arxiv.org/abs/1710.10903
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [40]
- [41]
-
[42]
S. Wu, F. Sun, W. Zhang, X. Xie, and B. Cui. Graph neural networks in recommender systems: A survey.ACM Comput. Surv., 55(5), Dec. 2022. ISSN 0360-0300. doi: 10.1145/3535101. URLhttps://doi.org/10.1145/3535101
- [43]
- [44]
- [45]
-
[46]
J. Zhou, G. Cui, S. Hu, Z. Zhang, C. Yang, Z. Liu, L. Wang, C. Li, and M. Sun. Graph neural networks: A review of methods and applications.AI Open, 1:57–81, 2020. ISSN 2666-6510. doi: https://doi.org/10.1016/j.aiopen.2021.01.001. URL https://www.sciencedirect.co m/science/article/pii/S2666651021000012
-
[47]
Zhuang, C
Y . Zhuang, C. Shi, M. Zhang, J. Chen, L. Lyu, P. Zhou, and L. Sun. Unveiling the secrets without data: can graph neural networks be exploited through data-free model extraction attacks? In Proceedings of the 33rd USENIX Conference on Security Symposium, SEC ’24, USA, 2024. USENIX Association. ISBN 978-1-939133-44-1. 12 APPENDIXCONTENTS A Related Work 14 ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.