The Long-Term Effects of Data Selection in LLM Fine-Tuning
Pith reviewed 2026-06-29 08:57 UTC · model grok-4.3
The pith
Short-term data selectors in multi-stage LLM fine-tuning can slow later learning and increase forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
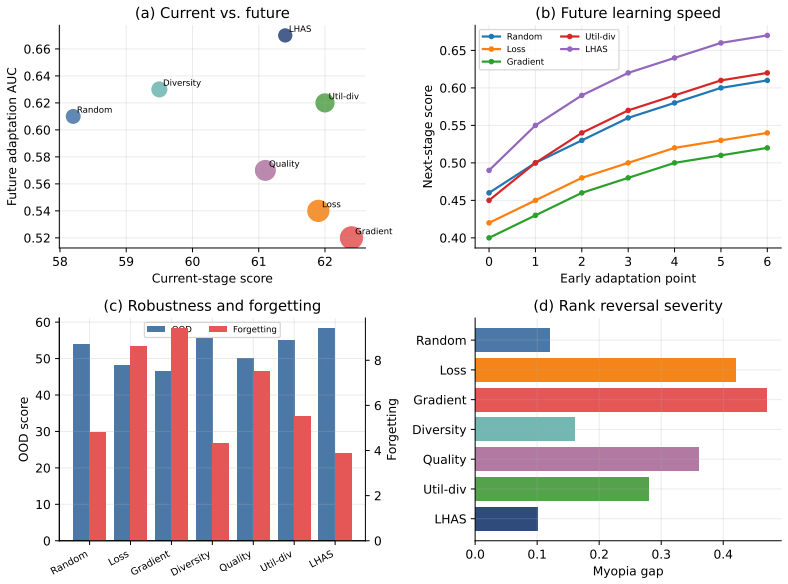
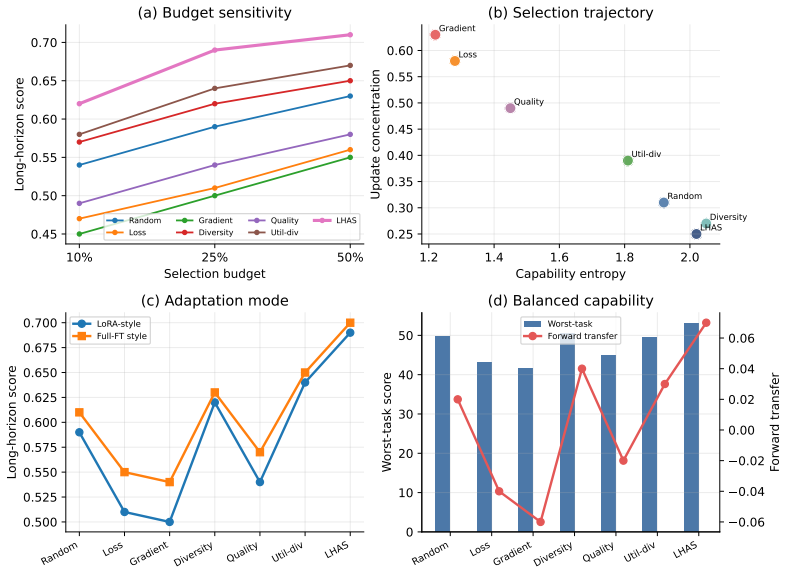
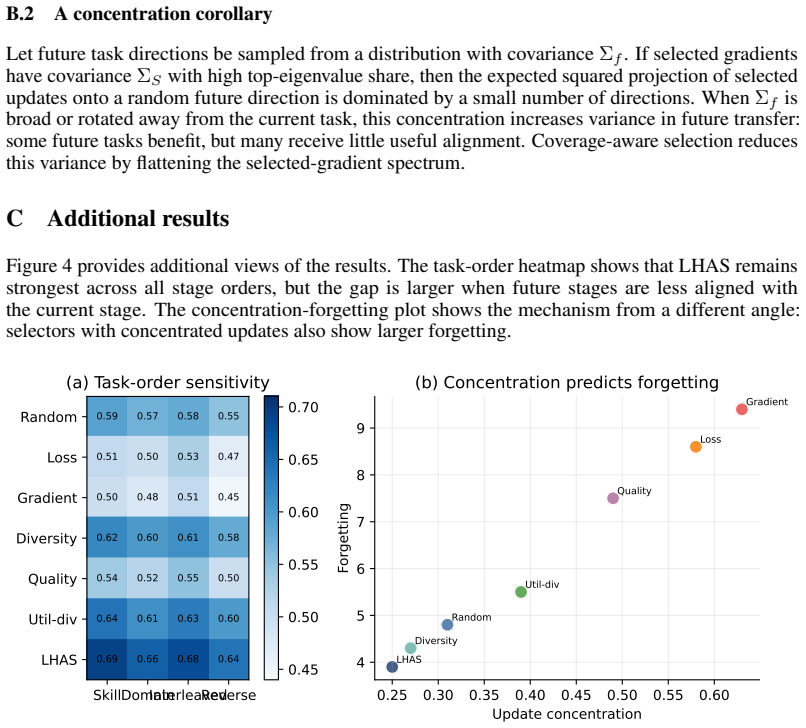
Short-term selectors exhibit myopic selection: they improve the current stage while slowing subsequent learning and increasing forgetting. Data selection should therefore be evaluated as a training intervention that shapes the model's overall learning trajectory rather than only as a local data-efficiency mechanism.
What carries the argument
The multi-stage evaluation protocol that measures not only immediate task performance but also future adaptation speed, forgetting, capability imbalance, and out-of-distribution robustness, together with the Long-Horizon Aware Selection (LHAS) objective that augments immediate utility with coverage, future-proxy transfer, and anti-concentration terms.
If this is right
- Selectors must be scored on future-stage metrics, not only current utility, to avoid rank reversal.
- The LHAS objective provides one concrete way to trade a small immediate cost for better long-horizon adaptability.
- Diversity-based and random selectors may preserve future learning speed better than pure loss- or gradient-based selectors.
- Data selection decisions act as trajectory-shaping interventions whose effects compound across stages.
- Forgetting and out-of-distribution robustness become first-class evaluation criteria for selection methods.
Where Pith is reading between the lines
- If the pattern holds, selection pipelines could incorporate cheap future-stage proxies during the choice step itself.
- The same myopic risk may appear in other staged training settings such as continual learning or curriculum design.
- Testing whether the reversal persists when stage boundaries are soft rather than hard would clarify the scope of the finding.
Load-bearing premise
The controlled multi-stage protocol used in the experiments accurately captures the dynamics of real-world staged LLM fine-tuning without confounding factors from model scale or data distribution shifts.
What would settle it
A follow-up experiment that applies the same selectors to production-scale models in an actual multi-stage pipeline and finds no rank reversal or difference in later-stage adaptation speed would falsify the central claim.
Figures

read the original abstract
Data selection is increasingly used to reduce the cost of large language model (LLM) fine-tuning, with recent methods prioritizing samples by current utility, diversity, quality, or influence. This paper studies a different question: when fine-tuning occurs over multiple stages, can selection strategies that look optimal now make the model less adaptable later? We introduce a long-horizon view of LLM data selection in which a selector is evaluated not only by immediate task performance, but also by future adaptation speed, forgetting, capability imbalance, and out-of-distribution robustness. We compare representative random, loss-based, gradient-based, diversity-based, quality-based, and utility-diversity selection families under a unified multi-stage protocol. Through controlled experiments designed to instantiate this protocol, we show how short-term selectors can exhibit rank reversal: they improve the current stage while slowing subsequent learning and increasing forgetting. We formalize this behavior as \emph{myopic selection}, provide a simple local analysis of why it can occur, and propose a diagnostic Long-Horizon Aware Selection (LHAS) objective that augments immediate utility with coverage, future-proxy transfer, and anti-concentration terms. The study argues that data selection should be evaluated as a training intervention that shapes the model's learning trajectory, rather than only as a local data-efficiency mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that data selection strategies in multi-stage LLM fine-tuning that optimize for immediate performance can exhibit rank reversal, improving the current stage while slowing subsequent learning, increasing forgetting, and harming long-term adaptability. It introduces a long-horizon evaluation framework incorporating future adaptation speed, forgetting, capability imbalance, and OOD robustness; compares random, loss-based, gradient-based, diversity-based, quality-based, and utility-diversity selectors under a unified multi-stage protocol; formalizes myopic selection with a local analysis; and proposes the LHAS objective augmenting immediate utility with coverage, future-proxy transfer, and anti-concentration terms.
Significance. If the empirical results on rank reversal hold under the described protocol, the work would be significant for reframing data selection as a training intervention that shapes learning trajectories rather than a purely local efficiency tool. The LHAS proposal offers a practical diagnostic augmentation to existing utilities, and the cross-family comparisons provide a basis for trajectory-aware evaluation in staged LLM training.
major comments (2)
- [Abstract] Abstract: the central claim of rank reversal under short-term selectors rests on 'controlled experiments designed to instantiate' the multi-stage protocol, yet the text provides no information on model sizes, stage definitions (task sequence or data volume per stage), metrics, statistical tests, data exclusion rules, or controls for scale-dependent effects. This is load-bearing for the claim that observed myopic behavior is a general property of selection rather than an artifact of the protocol.
- [Abstract] Abstract (multi-stage protocol description): without details on whether distribution shifts between stages are controlled or induced, or statistical controls for scale, it is unclear if reversal would persist at larger scales or with smoother distributions, undermining the generality of the myopic selection formalization.
minor comments (1)
- [Abstract] The abstract introduces LHAS but does not specify the relative weighting of the added terms or how future-proxy transfer is operationalized; a concrete equation or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding the experimental protocol. We agree these details are important for evaluating the generality of the rank reversal and myopic selection claims, and we will revise the abstract to incorporate key elements from the methods while preserving brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of rank reversal under short-term selectors rests on 'controlled experiments designed to instantiate' the multi-stage protocol, yet the text provides no information on model sizes, stage definitions (task sequence or data volume per stage), metrics, statistical tests, data exclusion rules, or controls for scale-dependent effects. This is load-bearing for the claim that observed myopic behavior is a general property of selection rather than an artifact of the protocol.
Authors: We acknowledge that the abstract omits these specifics. The full manuscript details them in Section 3 (model scales, task sequences with per-stage volumes, evaluation metrics including adaptation speed and forgetting, statistical reporting, filtering rules, and multi-scale controls). To make the central claim more robust, we will expand the abstract with a concise summary of these protocol elements. revision: yes
-
Referee: [Abstract] Abstract (multi-stage protocol description): without details on whether distribution shifts between stages are controlled or induced, or statistical controls for scale, it is unclear if reversal would persist at larger scales or with smoother distributions, undermining the generality of the myopic selection formalization.
Authors: The manuscript specifies the protocol in Section 3.2, including how shifts are induced via task changes with controlled overlap and volume, plus scale variations across experiments. We will update the abstract to note that shifts are task-induced under controlled conditions and that results are reported across tested scales, thereby clarifying the scope of the myopic selection analysis. revision: yes
Circularity Check
No circularity; claims rest on experimental protocol and conceptual augmentation
full rationale
The provided abstract and description contain no equations, fitted parameters, or self-citations that reduce any prediction or formalization to inputs by construction. The long-horizon view, myopic selection concept, and LHAS objective are presented as an augmentation of existing utilities rather than a redefinition or renaming that forces equivalence. The multi-stage protocol is described as a controlled experimental design whose results are offered as empirical observations, not as a derivation that collapses to its own assumptions. This is the most common honest finding for papers whose core contribution is experimental comparison rather than a closed mathematical chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A multi-stage fine-tuning protocol can be designed to measure future adaptation speed, forgetting, and robustness independently of immediate utility.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
M., Longpre, S., Lambert, N., Wang, X., Muennighoff, N., Hou, B., Pan, L., Jeong, H., et al
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haeju Jeong, et al. A survey on data selection for language models.arXiv preprint arXiv:2402.16827,
-
[5]
Deduplicating Training Data Makes Language Models Better
Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison- Burch, and Nicholas Carlini. Deduplicating training data makes language models better.arXiv preprint arXiv:2107.06499,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Heming Zou, Yixiu Mao, Yun Qu, Qi Wang, and Xiangyang Ji. Utility-diversity aware online batch selection for llm supervised fine-tuning.arXiv preprint arXiv:2510.16882, 2025a. 10 Ilya Loshchilov and Frank Hutter. Online batch selection for faster training of neural networks.arXiv preprint arXiv:1511.06343,
-
[7]
Angela H. Jiang, Daniel L.-K. Wong, Giulio Zhou, David G. Andersen, Jeffrey Dean, Gregory R. Ganger, Gauri Joshi, Michael Kaminsky, Michael Kozuch, Zachary C. Lipton, et al. Accelerating deep learning by focusing on the biggest losers.arXiv preprint arXiv:1910.00762,
-
[8]
Andrei A. Rusu, Neil C. Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Heming Zou, Yunliang Zang, and Xiangyang Ji. Structural features of the fly olfactory circuit mitigate the stability-plasticity dilemma in continual learning.arXiv preprint arXiv:2502.01427, 2025b. Heming Zou, Yunliang Zang, Wutong Xu, and Xiangyang Ji. Fly-cl: A fly-inspired framework for enhancing efficient decorrelation and reduced training time in pre...
-
[10]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing,
2021
-
[11]
Yuxin Yang, Aoxiong Zeng, and Xiangquan Yang. Towards specialized generalists: A multi-task moe-lora framework for domain-specific llm adaptation.arXiv preprint arXiv:2601.07935, 2026a. Yuxin Yang, Haoran Zhang, Mingxuan Li, Jiachen Xu, Ruoxi Shen, Zhenyu Wang, Tianhao Liu, Siqi Chen, and Weilin Huang. Neurolora: Context-aware neuromodulation for paramete...
-
[12]
Training Verifiers to Solve Math Word Problems
12 Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.