Improving Relative Representations with Learned Anchors and Whitened Inner Products
Pith reviewed 2026-06-29 08:19 UTC · model grok-4.3
The pith
Learned anchors as semantic prototypes and whitened inner products enable nearly lossless cross-model communication via relative representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By learning anchors as robust semantic prototypes and employing a geometry-aware whitened inner product similarity metric that preserves magnitude information and remains invariant to affine shifts, relative representations can achieve significant performance gains and enable nearly lossless information transfer and stable zero-shot communication between highly heterogeneous neural architectures such as small language models of varying scales.
What carries the argument
Learned semantic prototype anchors paired with whitened inner products for similarity measurement.
If this is right
- Significant gains in performance and consistency across vision and language tasks.
- Nearly lossless information transfer between independently trained models.
- Stable zero-shot communication between highly heterogeneous architectures such as small language models of varying scales.
- Improved handling of anisotropic geometries found in modern transformer models.
Where Pith is reading between the lines
- If the method works, independently trained modules could be assembled into larger systems without separate alignment training.
- The same anchor-learning and metric changes might apply to modalities beyond vision and language.
- Scaling the approach to much larger models could test whether the consistency gains persist.
Load-bearing premise
That learning anchors as semantic prototypes and switching to whitened inner products will reliably overcome the anisotropic geometries that defeat random anchors and cosine similarity.
What would settle it
High error rates or unstable zero-shot performance when transferring between small language models of different scales using the learned anchors and whitened inner products.
Figures
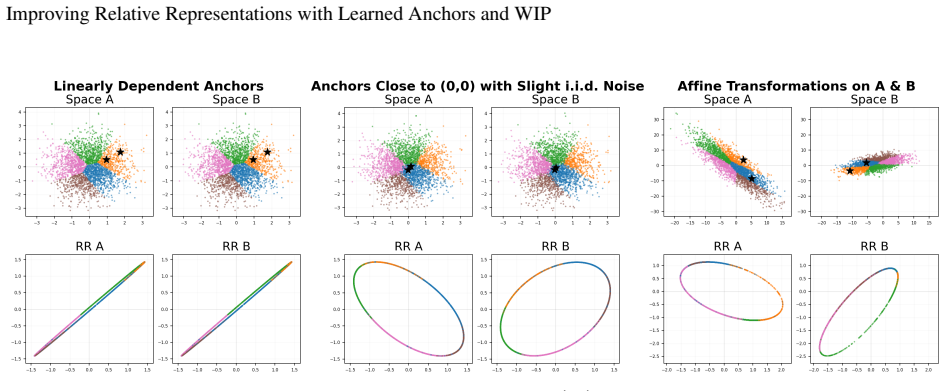
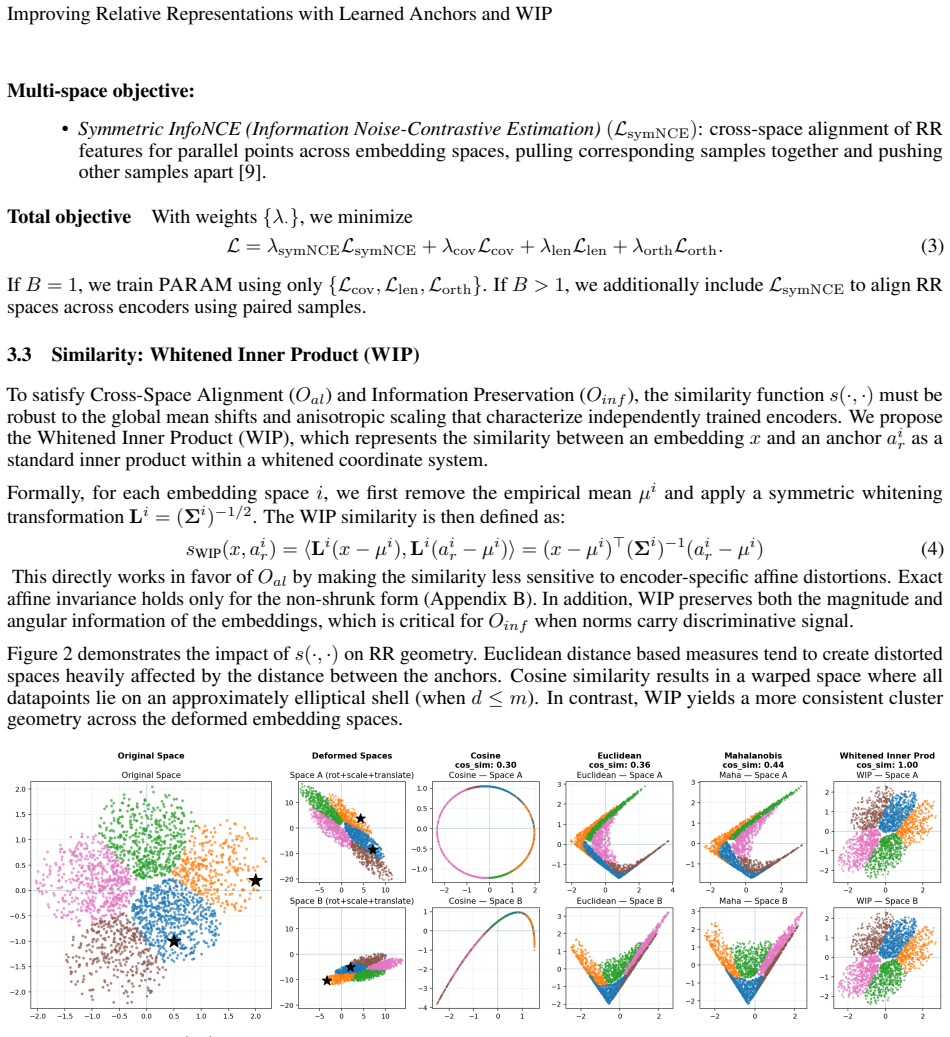
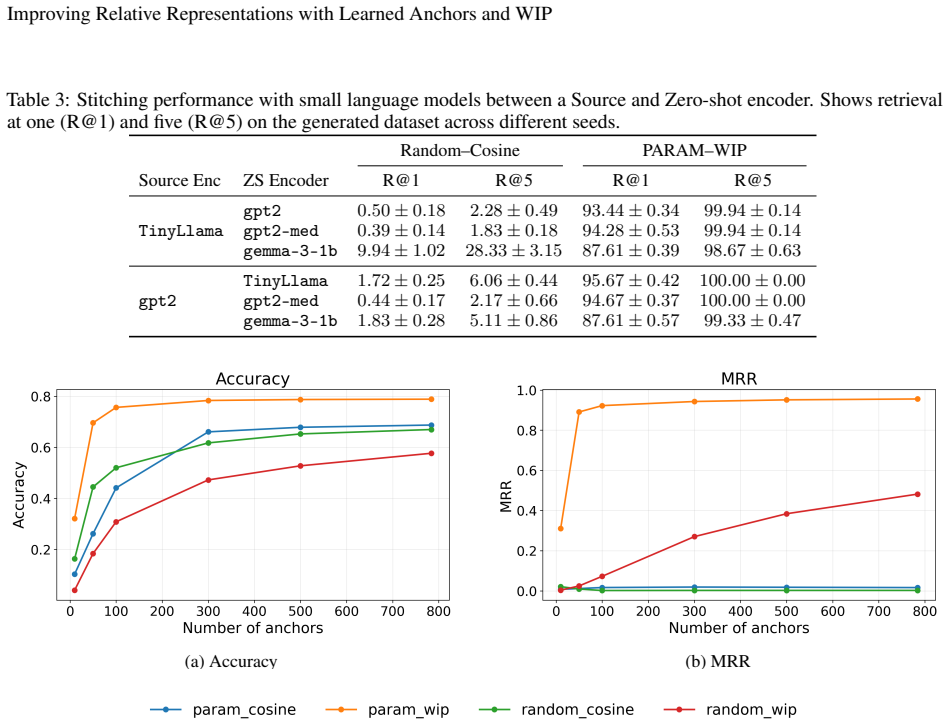
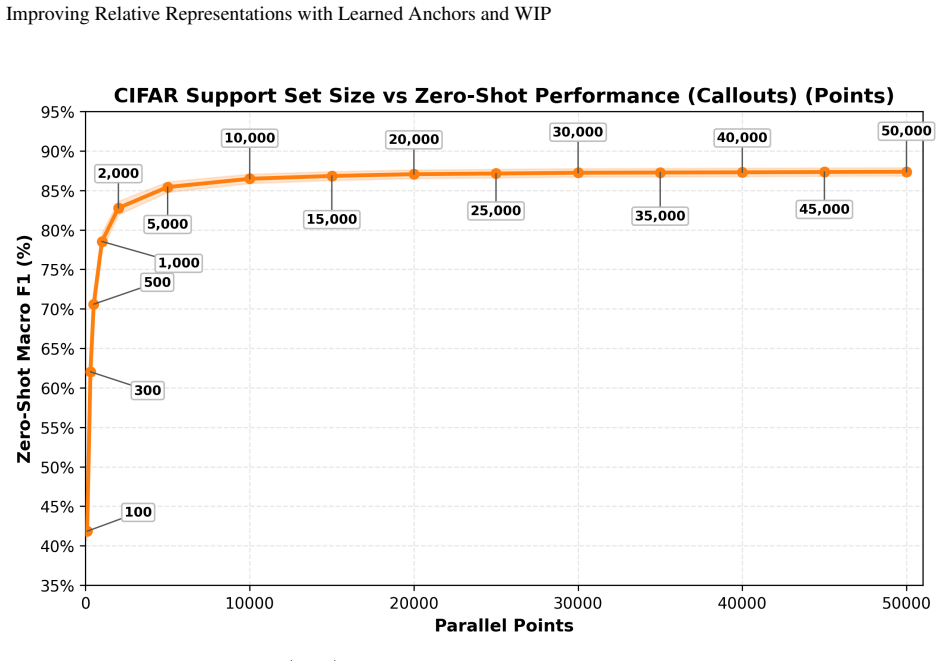

read the original abstract
Independently trained neural models typically converge to incompatible latent representations, creating a fundamental barrier to highly modular AI systems. While Relative Representations (RR) address this by mapping absolute coordinates to a shared space defined by similarities to common anchor points, traditional implementations rely on randomly sampled anchors and cosine similarity, which frequently fail to capture the anisotropic geometries of modern architectures like Transformers. In this work, we propose a robust framework for cross-model communication based on two improvements. We learn anchors as robust semantic prototypes and utilize a geometry-aware similarity metric which preserves discriminative magnitude information and is invariant to affine shifts. Our approach demonstrates significant gains in performance and consistency across vision and language tasks. Notably, it enables nearly lossless information transfer and stable zero-shot communication even between highly heterogeneous architectures, such as small language models of varying scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that independently trained neural models produce incompatible latent representations, and that Relative Representations can be improved by learning anchors as semantic prototypes and replacing cosine similarity with a whitened inner-product metric that preserves magnitude and is invariant to affine shifts. These changes are asserted to yield significant gains in performance and consistency on vision and language tasks, enabling nearly lossless information transfer and stable zero-shot communication even between highly heterogeneous architectures such as small language models of varying scales.
Significance. If the empirical results hold with proper controls and metrics, the work could meaningfully advance modular AI by reducing the barrier of representation incompatibility. The geometry-aware similarity addresses a known limitation of standard RR implementations on anisotropic spaces such as those produced by Transformers.
major comments (1)
- [Abstract] Abstract: the central claims of 'significant gains in performance and consistency' and 'nearly lossless information transfer' are stated without any quantitative metrics, baselines, statistical tests, or experimental details. This prevents assessment of whether the reported improvements are load-bearing or merely incremental.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater specificity in the abstract. We agree that the current abstract is too high-level and will revise it to incorporate key quantitative results from our experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'significant gains in performance and consistency' and 'nearly lossless information transfer' are stated without any quantitative metrics, baselines, statistical tests, or experimental details. This prevents assessment of whether the reported improvements are load-bearing or merely incremental.
Authors: We agree with this observation. While the body of the manuscript contains detailed experimental results with metrics, baselines, and comparisons across vision and language tasks, the abstract does not reference any specific numbers. In the revised manuscript we will update the abstract to include concrete performance figures (e.g., accuracy or transfer fidelity on representative benchmarks) along with brief mention of the evaluation protocol, thereby allowing readers to assess the magnitude of the reported gains. revision: yes
Circularity Check
No significant circularity; empirical method with independent experimental validation
full rationale
The manuscript proposes an empirical improvement to relative representations via learned anchors and whitened inner-product similarity, then reports performance gains on vision and language tasks. No mathematical derivation chain, equations, or self-citations are presented that reduce the claimed gains or zero-shot transfer results to quantities defined by construction from fitted parameters, prior self-referential normalizations, or load-bearing self-citations. The central claims rest on experimental outcomes rather than any self-definitional or fitted-input-called-prediction pattern, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Relative representations enable zero-shot latent space communication
Luca Moschella, Valentino Maiorca, Marco Fumero, Antonio Norelli, Francesco Locatello, and Emanuele Rodolà. Relative representations enable zero-shot latent space communication. InInternational Conference on Learning Representations, 2023. arXiv:2209.15430. 8 Improving Relative Representations with Learned Anchors and WIP
-
[2]
On the Importance of Embedding Norms in Self-Supervised Learning
Andrew Draganov, Sharvaree Vadgama, Sebastian Damrich, Jan Niklas Böhm, Lucas Maes, Dmitry Kobak, and Erik Bekkers. On the importance of embedding norms in self-supervised learning, 2025. arXiv:2502.09252
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019. arXiv:1909.00512
-
[4]
Anisotropy is inherent to self-attention in transformers
Nathan Godey, Éric de la Clergerie, and Benoît Sagot. Anisotropy is inherent to self-attention in transformers. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics,
-
[5]
Latent space translation via inverse relative projection, 2024
Valentino Maiorca, Luca Moschella, Marco Fumero, Francesco Locatello, and Emanuele Rodolà. Latent space translation via inverse relative projection, 2024. arXiv:2406.15057
-
[6]
Similarity of Neural Network Representations Revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, 2019. arXiv:1905.00414
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis, 2024. arXiv:2405.07987
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Relative representations of latent spaces enable efficient semantic channel equalization, 2024
Tomás Hüttebräucker, Simone Fiorellino, Mohamed Sana, Paolo Di Lorenzo, and Emilio Calvanese Strinati. Relative representations of latent spaces enable efficient semantic channel equalization, 2024. arXiv:2411.19719
-
[9]
Representation learning with contrastive predictive coding,
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding,
-
[10]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Rethinking channel dimensions for efficient model design
Dongyoon Han, Sangdoo Yun, Byeongho Heo, and YoungJoon Yoo. Rethinking channel dimensions for efficient model design. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021. arXiv:2007.00992
- [13]
-
[14]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, 2019. arXiv:1810.04805. 9 Improving Relative Representations with Learned Anchors and WIP Ap...
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.