Generative Quantum Data Embeddings for Supervised Learning
Pith reviewed 2026-06-28 22:08 UTC · model grok-4.3
The pith
An energy-based generative framework synthesizes quantum embeddings to improve supervised classification performance, with Wasserstein distance bounding the gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
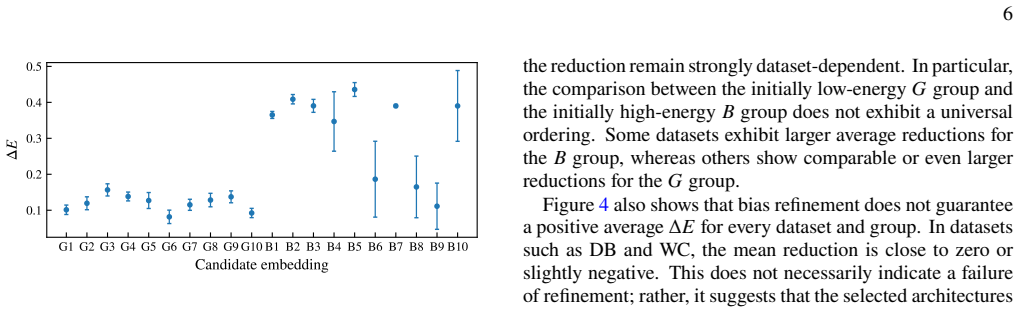
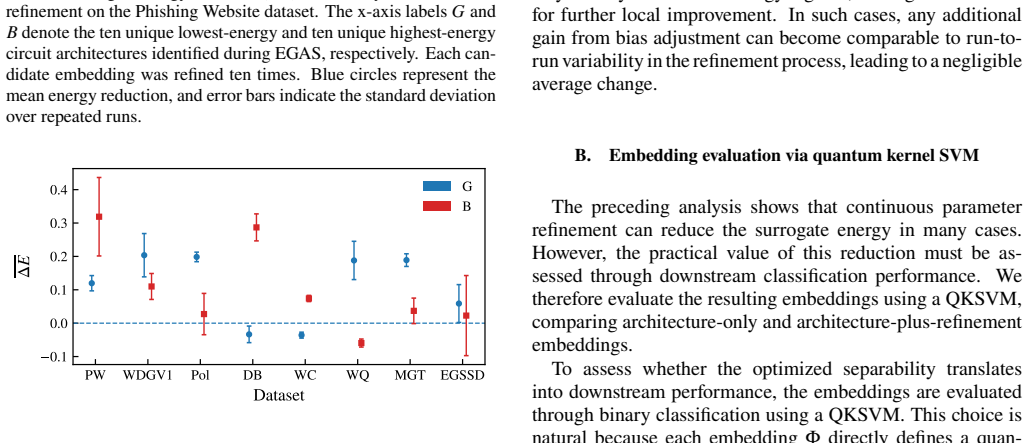
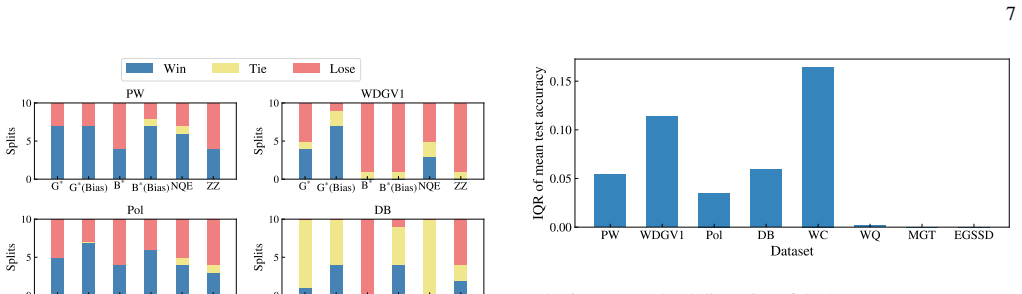
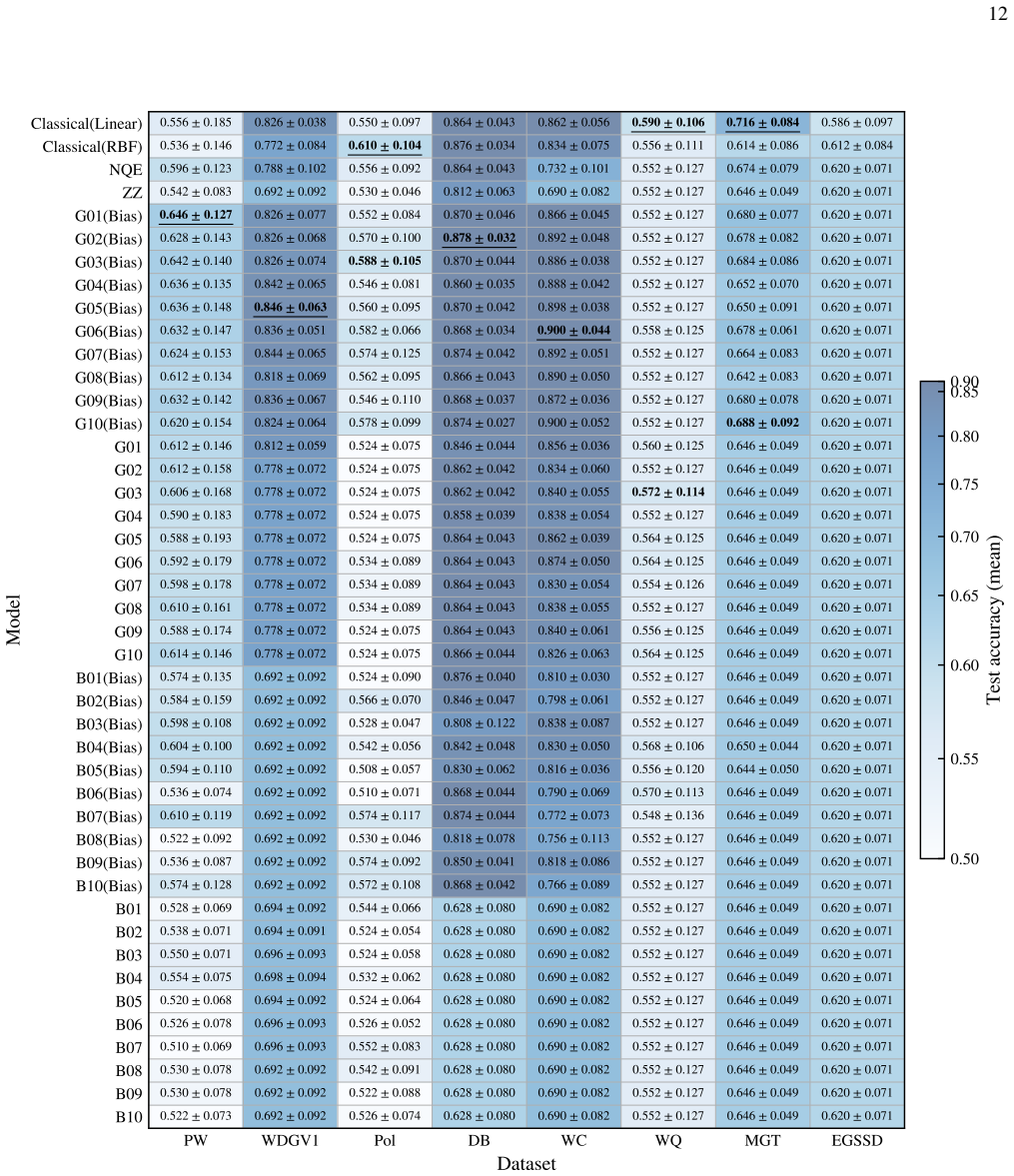
The authors claim that their energy-based generative learning framework can synthesize gate sequences to optimize embedding structures and refine data-tailored parameters using a fidelity-based surrogate objective, leading to improved classification performance, while bounds on achievable empirical risk in terms of the Wasserstein distance in the input space provide an a priori diagnostic for when substantial gains are unlikely.
What carries the argument
energy-based generative learning framework synthesizing gate sequences guided by a fidelity-based surrogate objective to optimize quantum embeddings
Load-bearing premise
The fidelity-based surrogate objective is a reliable proxy for downstream classification performance and the generative model can sufficiently explore the space of embedding circuits within the considered family.
What would settle it
An experiment where the generative method fails to improve classification accuracy on datasets with large Wasserstein distance between classes would challenge the effectiveness of the surrogate objective.
Figures



read the original abstract
Many practically relevant applications of quantum machine learning involve classical data, for which performance depends critically on how inputs are embedded into quantum states. Yet the use of a fixed embedding circuit ansatz remains standard practice. We propose an energy-based generative learning framework that synthesizes gate sequences to optimize embedding structures and refine data-tailored parameters, using a fidelity-based surrogate objective to guide the search toward improved class distinguishability. Empirically, the method improves classification performance across diverse settings, while also revealing datasets where architecture search within the present embedding family yields only limited additional gains. We explain this saturation by deriving bounds on the achievable empirical risk in terms of the Wasserstein distance in the input space, showing that classical data geometry provides an \emph{a priori} diagnostic for regimes in which substantial gains from embedding optimization are unlikely. The results establish a practically useful and theoretically motivated framework for searching effective quantum data embeddings through generative optimization, with the attainable gains diagnosed through the geometry of the underlying classical data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an energy-based generative learning framework for synthesizing gate sequences that optimize quantum embedding circuits and their parameters for classical data in supervised learning. A fidelity-based surrogate objective guides the search toward improved class distinguishability. The method is reported to yield empirical gains in classification performance across settings, while Wasserstein-distance bounds on achievable empirical risk are derived to diagnose regimes where embedding optimization within the considered family produces only limited additional gains due to the geometry of the underlying classical data.
Significance. If the central claims hold, the work supplies a generative procedure for data-tailored quantum embeddings together with an a priori, parameter-free diagnostic (the Wasserstein bound expressed in input-space geometry) that identifies when further architecture search is unlikely to help. The bound is a clear strength because it is logically downstream of the generative step yet remains independent of any fitted parameters of the generative model itself.
major comments (2)
- [Abstract] Abstract: the central claim that optimizing the fidelity-based surrogate produces embeddings that measurably lower downstream classification risk rests on the unverified assumption that surrogate values are a reliable proxy for test accuracy. No correlation plots, ablation tables, or statistical tests are referenced that would show the surrogate predicts accuracy better than random or fixed embeddings; without such evidence the empirical-improvement statement cannot be regarded as strongly supported.
- [Abstract] Abstract: the reported empirical gains are stated without reference to experimental controls, statistical significance testing, or the precise mapping from surrogate optimization steps to the final risk bound. These omissions leave the soundness of the performance claims difficult to evaluate even though the Wasserstein diagnostic itself is logically independent of the surrogate-performance link.
minor comments (1)
- The abstract refers to 'diverse settings' and 'datasets where architecture search yields only limited additional gains' without naming the concrete datasets or tasks, which would help readers assess the scope of the reported saturation behavior.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address the two major comments on the abstract below, agreeing that additional validation and clarification are warranted. We will revise the manuscript accordingly to strengthen the empirical support and presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that optimizing the fidelity-based surrogate produces embeddings that measurably lower downstream classification risk rests on the unverified assumption that surrogate values are a reliable proxy for test accuracy. No correlation plots, ablation tables, or statistical tests are referenced that would show the surrogate predicts accuracy better than random or fixed embeddings; without such evidence the empirical-improvement statement cannot be regarded as strongly supported.
Authors: We agree that the abstract does not reference supporting analyses for the surrogate-accuracy link. The full manuscript reports classification improvements on multiple datasets (Sections 4–5) using the optimized embeddings versus baselines, but to directly address the concern we will add correlation plots between surrogate fidelity values and test accuracy, ablation tables comparing to random/fixed embeddings, and statistical significance tests in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the reported empirical gains are stated without reference to experimental controls, statistical significance testing, or the precise mapping from surrogate optimization steps to the final risk bound. These omissions leave the soundness of the performance claims difficult to evaluate even though the Wasserstein diagnostic itself is logically independent of the surrogate-performance link.
Authors: We acknowledge that the abstract would benefit from explicit references to controls and testing. The manuscript already includes comparisons to fixed and random embeddings across datasets with multiple runs; we will revise the abstract to cite these controls and add reporting of statistical significance (e.g., p-values or confidence intervals). The Wasserstein bound is derived independently from input-space geometry (Section 3) as an a priori diagnostic and does not depend on the surrogate optimization trajectory; we will clarify this separation explicitly in the text and abstract. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces a generative optimization procedure that searches embedding circuits via a fidelity-based surrogate objective, reports empirical classification gains, and derives Wasserstein-based bounds on empirical risk from classical input-space geometry. None of these steps reduce by construction to fitted parameters, self-citations, or redefinitions of the target quantity; the surrogate is an independent proxy for distinguishability, the bounds are a priori diagnostics external to the generative model, and no load-bearing claim collapses to a self-referential equation or prior author result. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fidelity between embedded states serves as a faithful surrogate for downstream supervised classification performance.
Reference graph
Works this paper leans on
-
[1]
Training proceeds for 4,000 iterations, with a lin- early decreasing temperature schedule fromT max =100 to 10 Tmin =0.04
Details on architecture search Architecture search is performed using an autoregressive GPT generator with vocabulary size|C| +1, including a start token. Training proceeds for 4,000 iterations, with a lin- early decreasing temperature schedule fromT max =100 to 10 Tmin =0.04. At each iteration, candidate sequences are gen- erated and evaluated using the ...
-
[2]
Its output is scaled by a constant gain factor of 10 before being injected into the circuit parameters
Details on bias tuning The bias function𝑏 𝜔 (𝑥), which provides an additive offset to all parameterized gates, is implemented as a small multi- layer perceptron with a zero-initialized output head. Its output is scaled by a constant gain factor of 10 before being injected into the circuit parameters. Training uses RMSprop with learn- ing rate 5×10 −4 and ...
-
[3]
Details on quantum kernel SVM Downstream evaluation is performed with a QKSVM to isolate the effect of embedding geometry. For each train- test split, an SVM is trained with a precomputed quantum kernel: the training kernel matrix𝐾 train is constructed from all train-train pairs, and the test kernel matrix𝐾 test is constructed from all test-train pairs. A...
-
[4]
Biamonte, P
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Quantum machine learning, Nature549, 195 (2017)
2017
-
[5]
Cerezo, G
M. Cerezo, G. Verdon, H.-Y. Huang, L. Cincio, and P. J. Coles, Challenges and opportunities in quantum machine learning, Na- ture computational science2, 567 (2022)
2022
-
[6]
Rebentrost, M
P. Rebentrost, M. Mohseni, and S. Lloyd, Quantum support vector machine for big data classification, Physical review letters 113, 130503 (2014)
2014
-
[7]
Schuld, M
M. Schuld, M. Fingerhuth, and F. Petruccione, Implementing a distance-based classifier with a quantum interference circuit, Europhysics Letters119, 60002 (2017)
2017
-
[8]
Seong and D
M. Seong and D. K. Park, Hamiltonian formulations of centroid- based clustering, Frontiers in Physics13, 1544623 (2025)
2025
-
[9]
J. Choi, T. Hur, D. K. Park, N.-Y. Shin, S.-K. Lee, H. Lee, and S. Han, Early-stage detection of cognitive impairment by hybrid quantum-classical algorithm using resting-state functional mri time-series, Knowledge-Based Systems310, 112922 (2025)
2025
-
[10]
Havl´ıˇcek, A
V. Havl´ıˇcek, A. D. C´orcoles, K. Temme, A. W. Harrow, A. Kan- dala, J. M. Chow, and J. M. Gambetta, Supervised learning with quantum-enhanced feature spaces, Nature567, 209 (2019)
2019
-
[11]
Giovannetti, S
V. Giovannetti, S. Lloyd, and L. Maccone, Quantum random access memory, Physical review letters100, 160501 (2008)
2008
-
[12]
Schuld and N
M. Schuld and N. Killoran, Quantum machine learning in feature hilbert spaces, Physical review letters122, 040504 (2019)
2019
- [13]
-
[14]
Schuld, R
M. Schuld, R. Sweke, and J. J. Meyer, Effect of data encoding on the expressive power of variational quantum-machine-learning models, Physical Review A103, 032430 (2021)
2021
-
[15]
M. C. Caro, E. Gil-Fuster, J. J. Meyer, J. Eisert, and R. Sweke, Encoding-dependent generalization bounds for parametrized quantum circuits, Quantum5, 582 (2021)
2021
-
[16]
Thanasilp, S
S. Thanasilp, S. Wang, M. Cerezo, and Z. Holmes, Exponential concentration in quantum kernel methods, Nature communica- tions15, 5200 (2024)
2024
-
[17]
Hur and D
T. Hur and D. K. Park, Understanding generalization in quantum machine learning with margins, inProceedings of the 42nd International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 267, edited by A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, and J. Zhu (PMLR, 2025) pp. 26338–26360
2025
-
[18]
C. W. Helstrom, Quantum detection and estimation theory, Jour- nal of Statistical Physics1, 231 (1969)
1969
-
[19]
Bae and L.-C
J. Bae and L.-C. Kwek, Quantum state discrimination and its ap- plications, Journal of Physics A: Mathematical and Theoretical 48, 083001 (2015)
2015
-
[20]
R. Giuntini, H. Freytes, D. K. Park, C. Blank, F. Holik, K. L. Chow, and G. Sergioli, Quantum state discrimination for super- vised classification, arXiv preprint arXiv:2104.00971 (2021)
arXiv 2021
-
[21]
D. Lee, K. Baek, J. Huh, and D. K. Park, Variational quantum state discriminator for supervised machine learning, Quantum Science and Technology9, 015017 (2023)
2023
-
[22]
T. Hur, I. F. Araujo, and D. K. Park, Neural quantum embedding: Pushing the limits of quantum supervised learning, Physical Review A110, 022411 (2024)
2024
-
[23]
Schuld and F
M. Schuld and F. Petruccione,Machine learning with quantum computers, Vol. 676 (Springer, 2021)
2021
-
[24]
Y. Kim, A. Eddins, S. Anand, K. X. Wei, E. van den Berg, S. Rosenblatt, H. Nayfeh, Y. Wu, M. Zaletel, K. Temme, and A. Kandala, Evidence for the utility of quantum computing be- fore fault tolerance, Nature618, 500 (2023)
2023
-
[25]
Hubregtsen, D
T. Hubregtsen, D. Wierichs, E. Gil-Fuster, P.-J. H. Derks, P. K. Faehrmann, and J. J. Meyer, Training quantum embedding ker- nels on near-term quantum computers, Physical Review A106, 042431 (2022)
2022
-
[26]
Gentinetta, D
G. Gentinetta, D. Sutter, C. Zoufal, B. Fuller, and S. Woerner, Quantum kernel alignment with stochastic gradient descent, in 2023 IEEE International Conference on Quantum Computing and Engineering (QCE), Vol. 1 (IEEE, 2023) pp. 256–262
2023
-
[27]
H. Liu, T. Hur, S. Zhang, L. Che, X. Long, X. Wang, K. Huang, Y.-a. Fan, Y. Zheng, Y. Feng,et al., Neural quantum embedding via deterministic quantum computation with one qubit, Physical Review Letters135, 080603 (2025)
2025
-
[28]
Y. Kim, C. Im, T. Kim, T. Hur, and D. K. Park, Multi-channel convolutional neural quantum embedding, Advanced Quantum Technologies , e00575 (2025)
2025
-
[29]
K¨ ubler, S
J. K¨ ubler, S. Buchholz, and B. Sch¨olkopf, The inductive bias of quantum kernels, Advances in Neural Information Processing Systems34, 12661 (2021)
2021
-
[30]
Y. Du, T. Huang, S. You, M.-H. Hsieh, and D. Tao, Quantum circuit architecture search for variational quantum algorithms, npj Quantum Information8, 62 (2022)
2022
-
[31]
Incudini, D
M. Incudini, D. L. Bosco, F. Martini, M. Grossi, G. Serra, and A. Di Pierro, Automatic and effective discovery of quantum ker- nels, IEEE Transactions on Emerging Topics in Computational Intelligence (2024)
2024
-
[32]
Pellow-Jarman, A
R. Pellow-Jarman, A. Pillay, I. Sinayskiy, and F. Petruccione, Hybrid genetic optimization for quantum feature map design, Quantum Machine Intelligence6, 45 (2024)
2024
-
[33]
Islam, V
I. Islam, V. Jha, S. Thomas, K. F. Egan, A. Nobel, S. Kim, M. Chaudhary, S. Ogundele, D. Kneidel, B. Phillips,et al., Quantum circuit synthesis using fuzzy-logic-assisted genetic al- gorithms, Algorithms18, 178 (2025)
2025
-
[34]
Phalak, A
K. Phalak, A. Ghosh, and S. Ghosh, Optimizing quantum em- bedding using genetic algorithm for qml applications, in2025 26th International Symposium on Quality Electronic Design (ISQED)(IEEE, 2025) pp. 1–9
2025
-
[35]
F. Rapp, D. A. Kreplin, M. F. Huber, and M. Roth, Reinforce- ment learning-based architecture search for quantum machine learning, Machine Learning: Science and Technology6, 015041 (2025)
2025
-
[36]
T. F ¨osel, M. Y. Niu, F. Marquardt, and L. Li, Quantum circuit optimization with deep reinforcement learning, arXiv preprint arXiv:2103.07585 (2021)
arXiv 2021
-
[37]
M. K ¨olle, T. Schubert, P. Altmann, M. Zorn, J. Stein, and C. Linnhoff-Popien, A reinforcement learning environ- ment for directed quantum circuit synthesis, arXiv preprint arXiv:2401.07054 (2024)
arXiv 2024
-
[38]
Kundu, P
A. Kundu, P. Bede lek, M. Ostaszewski, O. Danaci, Y. J. Patel, V. Dunjko, and J. A. Miszczak, Enhancing variational quantum state diagonalization using reinforcement learning techniques, New Journal of Physics26, 013034 (2024)
2024
-
[39]
Montagna,Quantum circuit design with reinforcement learn- ing, Ph.D
F. Montagna,Quantum circuit design with reinforcement learn- ing, Ph.D. thesis, Politecnico di Torino (2021)
2021
-
[40]
Altmann, J
P. Altmann, J. Stein, M. K ¨olle, A. B ¨arligea, M. Zorn, T. Ga- bor, T. Phan, S. Feld, and C. Linnhoff-Popien, Challenges for reinforcement learning in quantum circuit design, in2024 IEEE International Conference on Quantum Computing and Engi- neering (QCE), Vol. 1 (IEEE, 2024) pp. 1600–1610
2024
-
[41]
Ostaszewski, L
M. Ostaszewski, L. M. Trenkwalder, W. Masarczyk, E. Scerri, and V. Dunjko, Reinforcement learning for optimization of vari- 14 ational quantum circuit architectures, Advances in neural infor- mation processing systems34, 18182 (2021)
2021
-
[42]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al., Language models are unsupervised multitask learners, OpenAI blog1, 9 (2019)
2019
-
[43]
K. Nakaji, L. B. Kristensen, J. A. Campos-Gonzalez-Angulo, M. G. Vakili, H. Huang, M. Bagherimehrab, C. Gorgulla, F. Wong, A. McCaskey, J.-S. Kim,et al., The generative quan- tum eigensolver (gqe) and its application for ground state search, arXiv preprint arXiv:2401.09253 (2024)
arXiv 2024
-
[44]
M. A. Nielsen and I. L. Chuang,Quantum computation and quantum information(Cambridge university press, 2010)
2010
-
[45]
Huang, M
H.-Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, Power of data in quantum machine learning, Nature communications12, 2631 (2021)
2021
-
[46]
Wang and Z
Q. Wang and Z. Zhang, Fast quantum algorithms for trace dis- tance estimation, IEEE Transactions on Information Theory70, 2720 (2023)
2023
-
[47]
Buhrman, R
H. Buhrman, R. Cleve, J. Watrous, and R. De Wolf, Quantum fingerprinting, Physical review letters87, 167902 (2001)
2001
-
[48]
M. M. Wilde,Quantum information theory(Cambridge univer- sity press, 2013)
2013
-
[49]
C. A. Fuchs and J. Van De Graaf, Cryptographic distinguishabil- ity measures for quantum-mechanical states, IEEE Transactions on Information Theory45, 1216 (2002)
2002
-
[50]
Recio-Armengol, J
E. Recio-Armengol, J. Eisert, and J. J. Meyer, Single-shot quan- tum machine learning, Physical Review A111, 042420 (2025)
2025
-
[51]
J. L. W. V. Jensen, Sur les fonctions convexes et les in ´egalit´es entre les valeurs moyennes, Acta mathematica30, 175 (1906)
1906
-
[52]
Villaniet al.,Optimal transport: old and new, Vol
C. Villaniet al.,Optimal transport: old and new, Vol. 338 (Springer, 2008)
2008
-
[53]
Mazumder, R., Meng, X., and Wang, H
R. Mohammad and L. McCluskey, Phishing Web- sites, UCI Machine Learning Repository (2012), DOI: https://doi.org/10.24432/C51W2X
-
[54]
L. Breiman and C. Stone, Waveform Database Generator (Version 1), UCI Machine Learning Repository (1984), DOI: https://doi.org/10.24432/C5CS3C
-
[55]
Vanschoren, J
J. Vanschoren, J. N. Van Rijn, B. Bischl, and L. Torgo, Openml: networked science in machine learning, ACM SIGKDD Explo- rations Newsletter15, 49 (2014)
2014
-
[56]
Grinsztajn, E
L. Grinsztajn, E. Oyallon, and G. Varoquaux, Why do tree- based models still outperform deep learning on typical tabular data?, Advances in neural information processing systems35, 507 (2022)
2022
-
[57]
Dry Bean, UCI Machine Learning Repository (2020), DOI: https://doi.org/10.24432/C50S4B
-
[58]
P. Cortez, A. Cerdeira, F. Almeida, T. Matos, and J. Reis, Wine Quality, UCI Machine Learning Repository (2009), DOI: https://doi.org/10.24432/C56S3T
-
[59]
R. Bock, MAGIC Gamma Telescope, UCI Machine Learning Repository (2004), DOI: https://doi.org/10.24432/C52C8B
-
[60]
V. Arzamasov, Electrical Grid Stability Simulated Data , UCI Machine Learning Repository (2018), DOI: https://doi.org/10.24432/C5PG66
-
[61]
F. F¨ urrutter, Z. Chandani, I. Hamamura, H. J. Briegel, and G. Mu ˜noz-Gil, Synthesis of discrete-continuous quan- tum circuits with multimodal diffusion models, arXiv preprint arXiv:2506.01666 (2025)
Pith/arXiv arXiv 2025
-
[62]
Efron, Bootstrap methods: another look at the jackknife, inBreakthroughs in statistics: Methodology and distribution (Springer, 1992) pp
B. Efron, Bootstrap methods: another look at the jackknife, inBreakthroughs in statistics: Methodology and distribution (Springer, 1992) pp. 569–593
1992
-
[63]
Bengio, J
Y. Bengio, J. Louradour, R. Collobert, and J. Weston, Curricu- lum learning, inProceedings of the 26th annual international conference on machine learning(2009) pp. 41–48
2009
-
[64]
V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V. Ajith, M. S. Alam, G. Alonso-Linaje, B. Akash- Narayanan, A. Asadi,et al., Pennylane: Automatic differentia- tion of hybrid quantum-classical computations, arXiv preprint arXiv:1811.04968 (2018)
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.