MLIPilot: LLM-Driven Auto-Research for Machine-Learned Interatomic Potentials
Pith reviewed 2026-06-28 20:28 UTC · model grok-4.3
The pith
LLM agents move constraint-violating MLIP baselines to accepted models using a physical scorecard
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tool-calling LLM agents can serve as autonomous operators for MLIP development workflows when their search is constrained by a fixed, physically constrained scorecard, allowing them to discover training strategies that move initially constraint-violating baselines to accepted models across molecular and periodic settings.
What carries the argument
The fixed, physically constrained scorecard that evaluates candidate MLIPs on accuracy, dynamical stability, and computational throughput to decide acceptance or reversion of code edits.
If this is right
- Stronger LLM agents discover training strategies including output normalization, loss-function changes, progressive training schedules, and model-capacity adjustments.
- Initially constraint-violating baselines can reach accepted status through the automated loop of hypothesis, edit, and scorecard evaluation.
- MLIP development can shift from manual trial-and-error toward auditable, automated experimentation when validation criteria are domain-specific.
- LLM agents can function as operators for scientific machine-learning workflows under fixed physical constraints.
Where Pith is reading between the lines
- The same constrained-agent pattern could extend to other computational chemistry tasks where multiple competing performance criteria must be balanced simultaneously.
- Reducing human oversight in the tuning loop might accelerate iteration when developing potentials for new material systems.
- Integration with future, more capable models could enlarge the set of discoverable training adjustments beyond those found in the current benchmarks.
Load-bearing premise
The fixed, physically constrained scorecard used by the agents is sufficient to identify production-quality MLIPs without missing important failure modes that would only appear in larger-scale or longer simulations.
What would settle it
An accepted model that exhibits instability or large errors during independent long-timescale molecular dynamics simulations outside the scorecard metrics would show the scorecard is insufficient.
Figures



read the original abstract
Constructing production-quality machine-learned interatomic potentials (MLIPs) requires balancing accuracy, dynamical stability, and computational throughput under constraints that are not captured by a single training loss. We introduce MLIPilot, an auto-research framework in which tool-calling large language models propose hypotheses, edit MLIP training code, launch HPC jobs, and accept or revert changes using a fixed, physically constrained scorecard. We evaluate MLIPilot on MACE potential optimization using both commercial and open-weight LLM agents, including GPT-5.5, GPT-4.1, Mistral-24B, and Qwen3-32B. The benchmarks span molecular and periodic settings: a QM7-derived dataset for which we generated B3LYP/6-31G(d) energies and forces, and a Cu EMT dataset with periodic copper supercells labeled by ASE's Effective Medium Theory calculator. Across these benchmarks, the strongest agents move initially constraint-violating baselines to accepted models by discovering useful training strategies, including output normalization, loss-function changes, progressive training schedules, and model-capacity adjustments. These results suggest that LLM agents can serve as autonomous operators for scientific machine-learning workflows when their search is constrained by domain-specific validation criteria, shifting part of MLIP development from manual trial-and-error toward auditable, automated experimentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MLIPilot, an LLM-based auto-research framework in which tool-calling agents propose hypotheses, edit MLIP training code, launch HPC jobs, and accept/revert changes according to a fixed, physically constrained scorecard. On two small benchmarks (QM7-derived molecules with B3LYP labels and periodic Cu supercells with EMT labels), the strongest agents (including GPT-5.5) are reported to convert initially constraint-violating MACE baselines into accepted models by discovering strategies such as output normalization, loss-function modifications, progressive schedules, and capacity adjustments. The central claim is that domain-specific physical constraints enable LLM agents to serve as autonomous operators for scientific ML workflows.
Significance. If the fixed scorecard reliably identifies production-quality MLIPs without missing scale-dependent or long-time instabilities, the work would demonstrate a concrete path toward auditable, automated MLIP development that reduces manual trial-and-error. The approach is novel in its closed-loop integration of hypothesis generation, code editing, and HPC execution under physical constraints, and the reported discovery of standard training heuristics by the agents is a positive indicator of the framework's utility on the tested scales.
major comments (3)
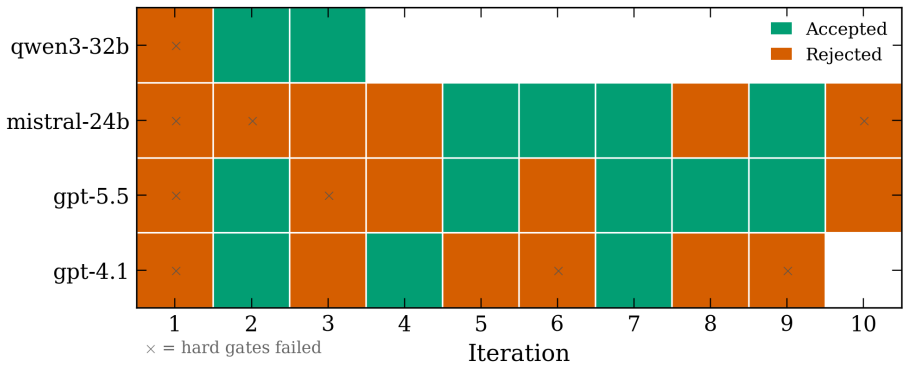
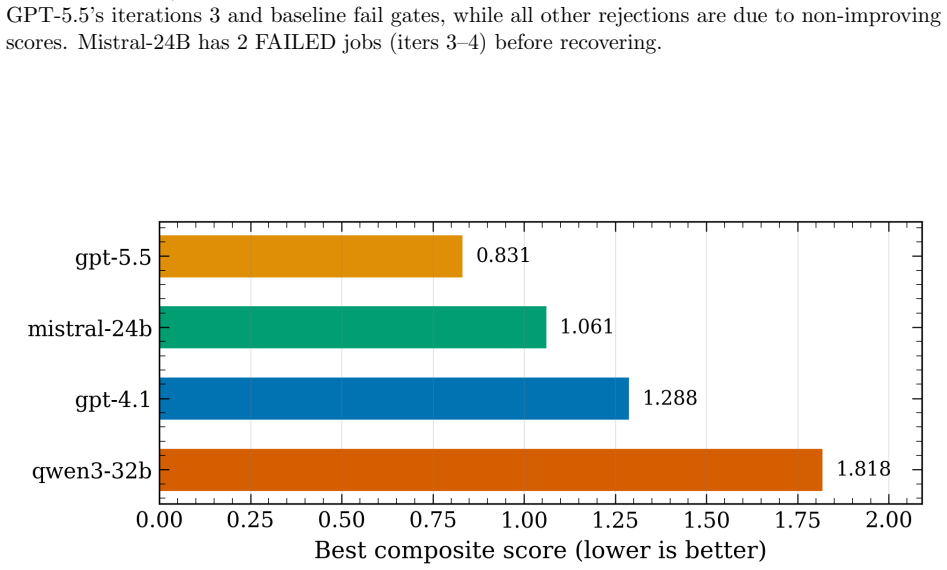
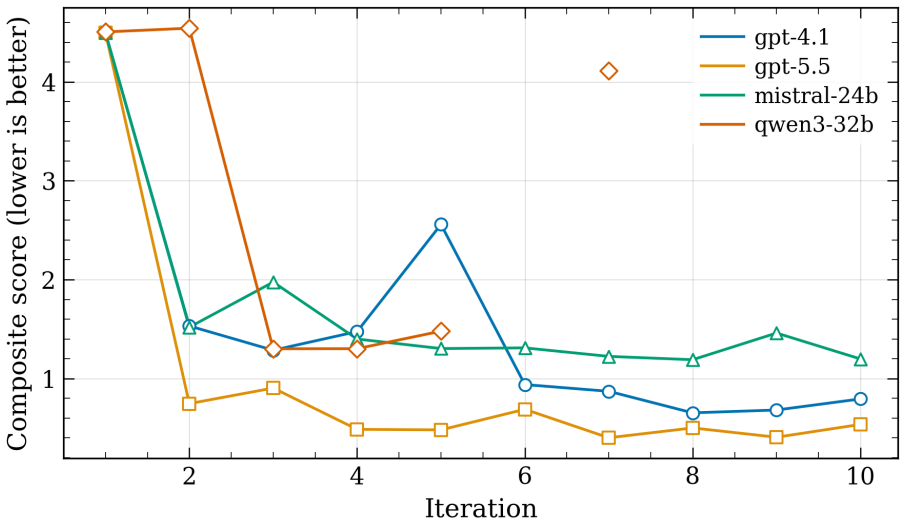
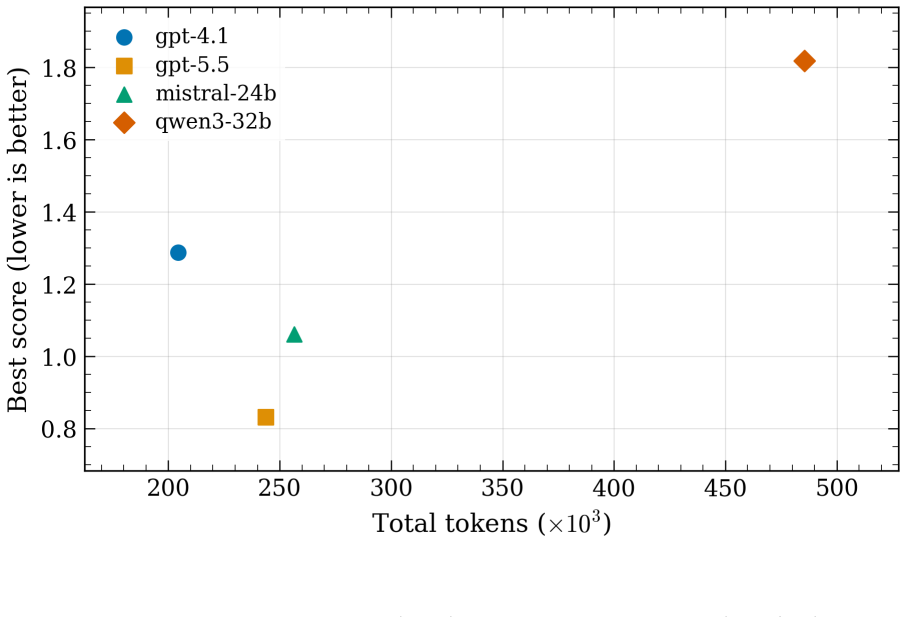
- [Abstract] Abstract and evaluation description: the claim that agents 'move initially constraint-violating baselines to accepted models' is presented without any quantitative metrics, error bars, definition of the scorecard criteria, or controls for prompt sensitivity. This is load-bearing for the central claim, as success is defined solely by passage through the scorecard.
- [Benchmarks] Benchmarks section (molecular and periodic settings): evaluation is confined to small QM7-derived molecules and small Cu supercells. No results are shown for extended MD trajectories, larger system sizes, or properties outside the scorecard (e.g., phonon spectra, defect migration), leaving open whether the scorecard is a sufficient proxy for production-quality behavior as required by the central claim.
- [Methods] Methods / scorecard description: the paper states that the scorecard is 'fixed' and 'physically constrained' but provides no explicit list of criteria, thresholds, or validation that these criteria capture dynamical stability and throughput under conditions beyond the small test systems. This directly affects whether the reported 'accepted models' generalize.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive report. We address each major comment point by point below, indicating the revisions we will incorporate. Our responses focus on strengthening the manuscript while remaining faithful to the scope and results of the current study.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the claim that agents 'move initially constraint-violating baselines to accepted models' is presented without any quantitative metrics, error bars, definition of the scorecard criteria, or controls for prompt sensitivity. This is load-bearing for the central claim, as success is defined solely by passage through the scorecard.
Authors: We agree that the abstract and evaluation sections require quantitative support for the central claim. In the revised manuscript we will report concrete metrics including the fraction of runs that reached accepted models, average number of iterations and code edits per successful run, and standard deviations across repeated trials. The scorecard criteria will be defined explicitly within the abstract and early methods. We will also add a brief discussion of prompt sensitivity, either by reporting results from multiple prompt variants or by noting it as a limitation with suggested controls for future work. revision: yes
-
Referee: [Benchmarks] Benchmarks section (molecular and periodic settings): evaluation is confined to small QM7-derived molecules and small Cu supercells. No results are shown for extended MD trajectories, larger system sizes, or properties outside the scorecard (e.g., phonon spectra, defect migration), leaving open whether the scorecard is a sufficient proxy for production-quality behavior as required by the central claim.
Authors: The present work is a proof-of-concept demonstration on small systems chosen to isolate the closed-loop agent behavior. We acknowledge that this scope leaves the sufficiency of the scorecard for production-quality MLIPs as an open question. In revision we will add an explicit limitations subsection that qualifies the central claim, discusses the scorecard as a necessary but not necessarily sufficient proxy, and outlines the additional validation (extended MD, phonon spectra, defect properties) required for broader applicability. New experiments on larger systems lie outside the computational budget of the current study. revision: partial
-
Referee: [Methods] Methods / scorecard description: the paper states that the scorecard is 'fixed' and 'physically constrained' but provides no explicit list of criteria, thresholds, or validation that these criteria capture dynamical stability and throughput under conditions beyond the small test systems. This directly affects whether the reported 'accepted models' generalize.
Authors: We will expand the methods section to provide a complete, enumerated list of all scorecard criteria together with their numerical thresholds. This will include the precise definitions of energy/force accuracy targets, short-trajectory stability checks, and throughput constraints. The revised text will also note that these criteria were chosen to enforce basic physical consistency on the tested system sizes while remaining computationally tractable. revision: yes
Circularity Check
No circularity; external fixed scorecard and empirical benchmarks
full rationale
The paper presents an empirical demonstration of LLM agents optimizing MLIPs against a fixed, physically constrained external scorecard on QM7-derived and Cu EMT datasets. No equations, fitted parameters, predictions derived from inputs by construction, or load-bearing self-citations appear in the text. The derivation chain is self-contained, relying on independent domain-specific validation criteria rather than any reduction to self-defined quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MACE: Higher order equivariant message passing neural networks for fast and accurate force fields.Advances in Neural Information Processing Systems, 35:11423–11436, 2022
Ilyes Batatia, D´ avid P´ eter Kov´ acs, Gregor N C Simm, Christoph Ortner, and G´ abor Cs´ anyi. MACE: Higher order equivariant message passing neural networks for fast and accurate force fields.Advances in Neural Information Processing Systems, 35:11423–11436, 2022
2022
-
[2]
E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials.Nature Communications, 13:2453, 2022
Simon Batzner, Albert Musaelian, Lixin Sun, Mario Geiger, Jonathan P Mailoa, Mordechai Kornbluth, Nicola Molinari, Tess E Smidt, and Boris Kozinsky. E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials.Nature Communications, 13:2453, 2022
2022
-
[3]
Springer, 2019
Frank Hutter, Lars Kotthoff, and Joaquin Vanschoren.Automated Machine Learning: Methods, Systems, Challenges. Springer, 2019
2019
-
[4]
AutoML: A survey of the state-of-the-art.Knowledge- Based Systems, 212:106622, 2021
Xin He, Kaiyong Zhao, and Xiaowen Chu. AutoML: A survey of the state-of-the-art.Knowledge- Based Systems, 212:106622, 2021. 14
2021
-
[5]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
1901
-
[6]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
AutoResearch: AI agents running research on single-GPU nanochat training automatically.https://github.com/karpathy/AutoResearch, 2026
Andrej Karpathy. AutoResearch: AI agents running research on single-GPU nanochat training automatically.https://github.com/karpathy/AutoResearch, 2026
2026
-
[9]
Nanochat: Autoresearch round 1 improvements
Andrej Karpathy. Nanochat: Autoresearch round 1 improvements. https://github.com/ karpathy/nanochat/commit/6ed7d1d82cee16c2e26f45d559ad3338447a6c1b, 2026
2026
-
[10]
Generalized neural-network representation of high- dimensional potential-energy surfaces.Physical Review Letters, 98:146401, 2007
J¨ org Behler and Michele Parrinello. Generalized neural-network representation of high- dimensional potential-energy surfaces.Physical Review Letters, 98:146401, 2007
2007
-
[11]
SchNet – a deep learning architecture for molecules and materials.The Journal of Chemical Physics, 148:241722, 2018
Kristof T Sch¨ utt, Huziel E Sauceda, P-J Kindermans, Alexandre Tkatchenko, and Klaus-Robert M¨ uller. SchNet – a deep learning architecture for molecules and materials.The Journal of Chemical Physics, 148:241722, 2018
2018
-
[12]
Fast and uncertainty-aware directional message passing for non-equilibrium molecules
Johannes Gasteiger, Shankari Giri, Johannes T Margraf, and Stephan G¨ unnemann. Fast and uncertainty-aware directional message passing for non-equilibrium molecules. InMachine Learning for Molecules Workshop, NeurIPS, 2020
2020
-
[13]
Learning local equivariant representations for large-scale atomistic dynamics.Nature Communications, 14:579, 2023
Albert Musaelian, Simon Batzner, Anders Johansson, Lixin Sun, Cameron J Owen, Mordechai Kornbluth, and Boris Kozinsky. Learning local equivariant representations for large-scale atomistic dynamics.Nature Communications, 14:579, 2023
2023
-
[14]
PaiNN: Polarizable atom interaction neural network
Kristof T Sch¨ utt, Oliver T Unke, and Michael Gastegger. PaiNN: Polarizable atom interaction neural network. InInternational Conference on Machine Learning, pages 9377–9388, 2021
2021
-
[15]
GemNet: Universal directional graph neural networks for molecules
Johannes Gasteiger, Florian Becker, and Stephan G¨ unnemann. GemNet: Universal directional graph neural networks for molecules. InAdvances in Neural Information Processing Systems, volume 34, pages 6790–6802, 2021
2021
-
[16]
A foundation model for atomistic materials chemistry
Ilyes Batatia, Philipp Benner, Yuan Chiang, Alin M Elena, D´ avid P Kov´ acs, Janosh Riebesell, et al. A foundation model for atomistic materials chemistry.arXiv preprint arXiv:2401.00096, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
A universal graph deep learning interatomic potential for the periodic table.Nature Computational Science, 2:718–728, 2022
Chi Chen and Shyue Ping Ong. A universal graph deep learning interatomic potential for the periodic table.Nature Computational Science, 2:718–728, 2022
2022
-
[18]
CHGNet as a pretrained universal neural network potential for charge-informed atomistic modelling.Nature Machine Intelligence, 5:1031–1041, 2023
Bowen Deng, Peichen Zhong, KyuJung Jun, Janosh Riebesell, Kevin Han, Christopher J Bartel, and Gerbrand Ceder. CHGNet as a pretrained universal neural network potential for charge-informed atomistic modelling.Nature Machine Intelligence, 5:1031–1041, 2023
2023
-
[19]
Forces are not enough: Benchmark and critical evaluation for machine learning force fields with molecular simulations.Transactions on Machine Learning Research, 2023
Xiang Fu, Zhenghao Wu, Wujie Wang, Tian Xie, Sinan Keten, Rafael Gomez-Bombarelli, and Tommi Jaakkola. Forces are not enough: Benchmark and critical evaluation for machine learning force fields with molecular simulations.Transactions on Machine Learning Research, 2023. 15
2023
-
[20]
Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dess` ı, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36, 2023
2023
-
[21]
Tool Learning with Foundation Models
Yujia Qin, Shengding Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, et al. Tool learning with foundation models.arXiv preprint arXiv:2304.08354, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Autonomous chemical research with large language models.Nature, 624:570–578, 2023
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624:570–578, 2023
2023
-
[23]
ChemCrow: Augmenting large-language models with chemistry tools.Nature Machine Intelligence, 6:525–535, 2024
Andres M Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. ChemCrow: Augmenting large-language models with chemistry tools.Nature Machine Intelligence, 6:525–535, 2024
2024
-
[24]
14 examples of how LLMs can transform materials science and chemistry: a reflection on a large language model hackathon.Digital Discovery, 2:1233–1250, 2023
Kevin Maik Jablonka, Qianxiang Ai, Alexander Al-Feghali, Shruti Baber, David Balcells, et al. 14 examples of how LLMs can transform materials science and chemistry: a reflection on a large language model hackathon.Digital Discovery, 2:1233–1250, 2023
2023
-
[25]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco J R Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625:468–475, 2024
2024
-
[26]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2623–2631, 2019
2019
-
[28]
BOHB: Robust and efficient hyperparameter optimization at scale
Stefan Falkner, Aaron Klein, and Frank Hutter. BOHB: Robust and efficient hyperparameter optimization at scale. InInternational Conference on Machine Learning, pages 1437–1446, 2018
2018
-
[29]
Neural architecture search with reinforcement learning
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. In International Conference on Learning Representations, 2017
2017
-
[30]
Neural architecture search: A survey
Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. Journal of Machine Learning Research, 20:1–21, 2019
2019
-
[31]
Population Based Training of Neural Networks
Max Jaderberg, Valentin Dalibard, Simon Osindero, Wojciech M Czarnecki, Jeff Donahue, Ali Razavi, Oriol Vinyals, Tim Green, Iain Dunning, Karen Simonyan, et al. Population based training of neural networks.arXiv preprint arXiv:1711.09846, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
The atomic simulation environment – a Python library for working with atoms.Journal of Physics: Condensed Matter, 29:273002, 2017
Ask Hjorth Larsen, Jens Jørgen Mortensen, Jakob Blomqvist, Ivano E Castelli, Rune Chris- tensen, Marcin Du lak, Jesper Friis, Michael N Groves, Bjørk Hammer, Cory Hargus, et al. The atomic simulation environment – a Python library for working with atoms.Journal of Physics: Condensed Matter, 29:273002, 2017. 16
2017
-
[33]
Anatole von Lilienfeld
Matthias Rupp, Alexandre Tkatchenko, Klaus-Robert M¨ uller, and O. Anatole von Lilienfeld. Fast and accurate modeling of molecular atomization energies with machine learning.Physical Review Letters, 108:058301, 2012
2012
-
[34]
970 million druglike small molecules for virtual screening in the chemical universe database GDB-13.Journal of the American Chemical Society, 131:8732–8733, 2009
Lorenz C Blum and Jean-Louis Reymond. 970 million druglike small molecules for virtual screening in the chemical universe database GDB-13.Journal of the American Chemical Society, 131:8732–8733, 2009. 17
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.