Learning Multi-Agent Coordination via Sheaf-ADMM
Pith reviewed 2026-06-28 23:19 UTC · model grok-4.3
The pith
Multi-agent systems learn coordination by solving neural-parameterized convex subproblems linked through cellular sheaf constraints in unrolled ADMM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
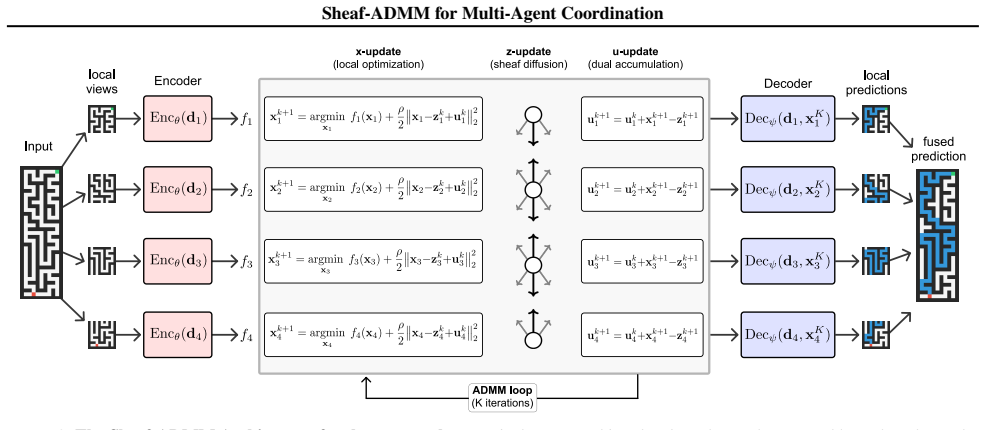
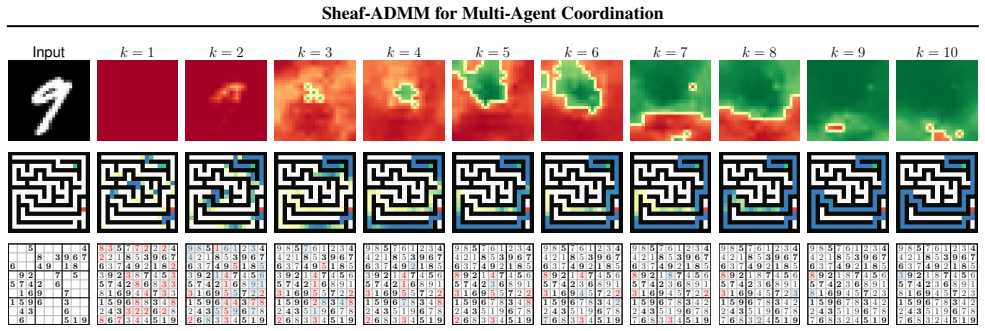
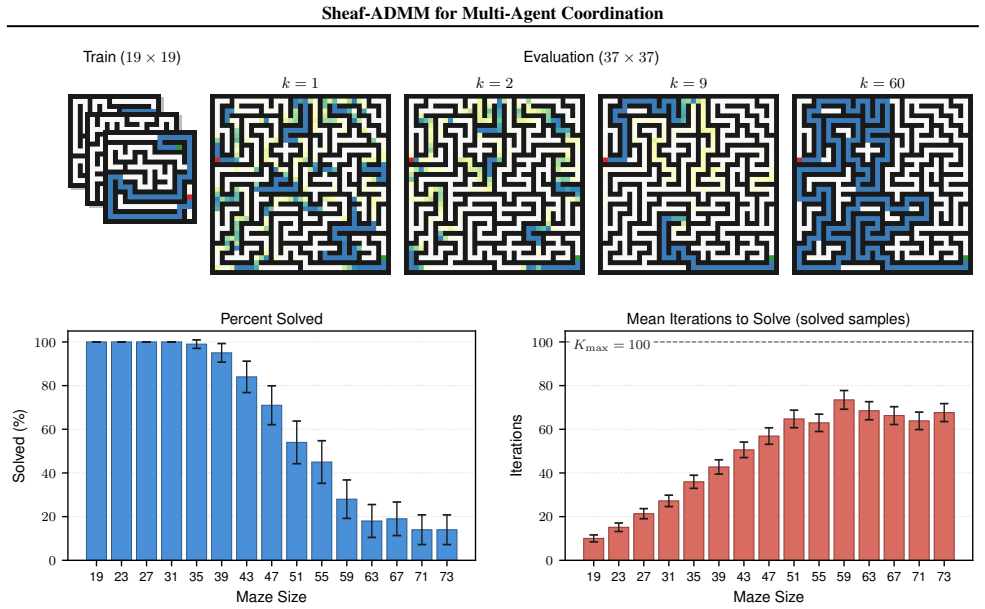
Decomposing an input into local views processed by agents solving convex subproblems and coordinating them via ADMM under cellular-sheaf agreement constraints allows the system to learn correct global outputs from partial information, yielding improved robustness to distribution shifts on MNIST relative to a standard CNN and markedly higher solve rates on Sudoku than parameter-matched MPNN baselines.
What carries the argument
Cellular sheaf constraints inside the ADMM iterations, which encode heterogeneous inter-agent agreement requirements and allow the full pipeline of neural encoders plus optimization steps to be trained end-to-end by differentiation through the unrolled solver.
If this is right
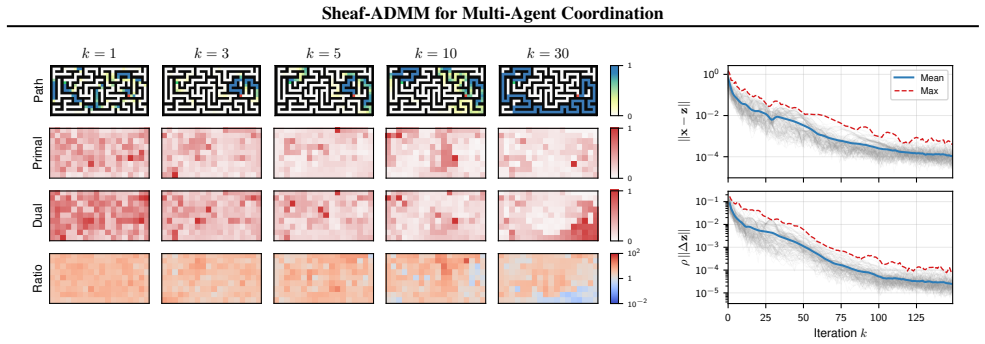
- The exposed primal, consensus, and dual variables make coordination dynamics directly observable and intervenable.
- The framework supports tasks in which different agents must agree on different aspects of the solution.
- End-to-end training through the unrolled solver produces systems that outperform standard message-passing networks on constraint-satisfaction and robustness benchmarks.
Where Pith is reading between the lines
- The dual variables could be monitored at inference time to detect when coordination is failing.
- Automatic learning of the sheaf structure itself would reduce reliance on hand-specified constraints.
- The same decomposition into local convex subproblems might apply to other distributed decision problems whose consistency requirements can be expressed as sheaves.
Load-bearing premise
Cellular sheaves can be specified or learned that exactly capture the agreement constraints needed for the task, and the neural-parameterized subproblems stay convex enough for ADMM to converge reliably.
What would settle it
If the Sudoku solve rates achieved by the sheaf-ADMM agents are not markedly higher than those of parameter-matched MPNN baselines, or if robustness to distribution shifts on MNIST does not exceed that of a standard CNN.
Figures



read the original abstract
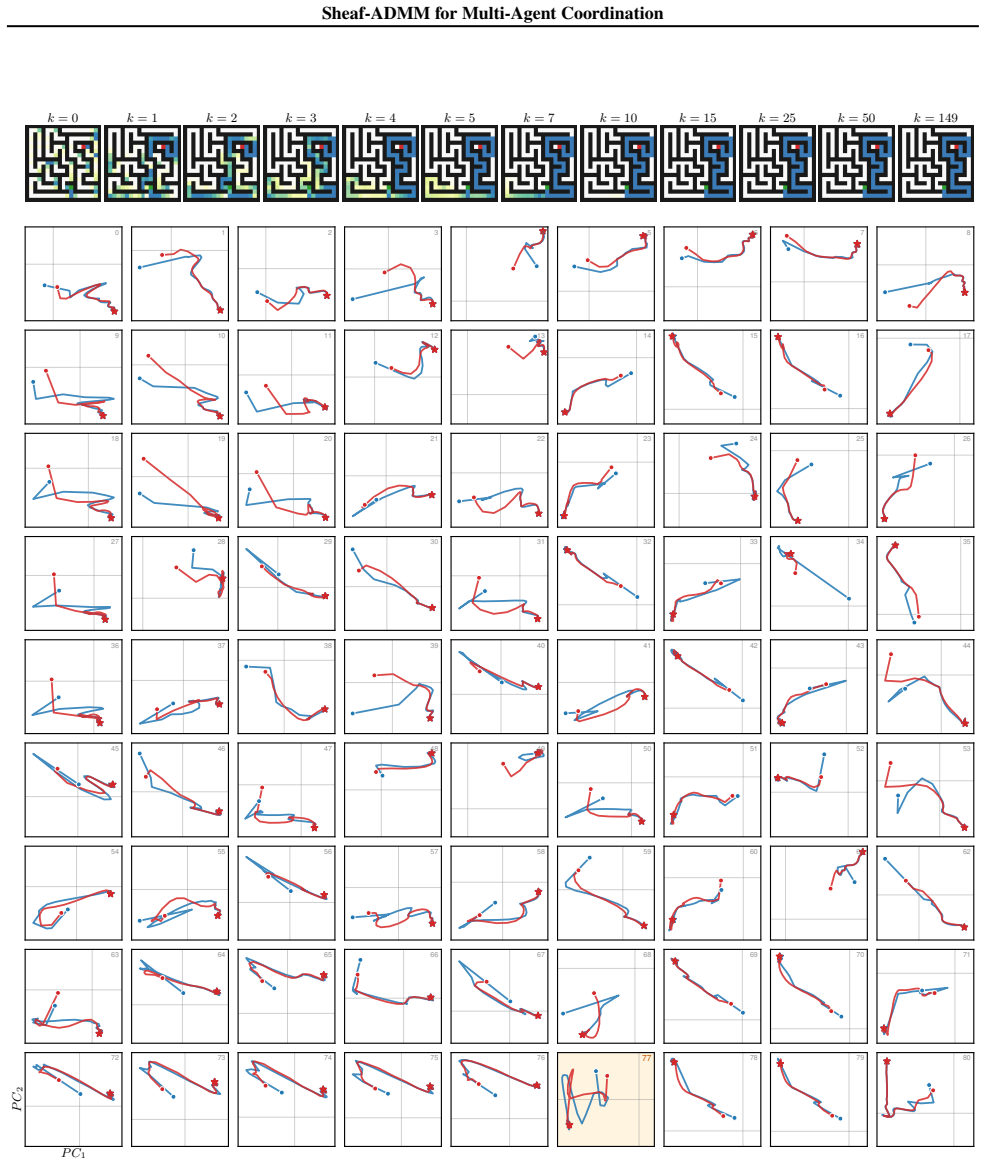
We present a differentiable optimization framework for multi-agent coordination. An input is decomposed into overlapping local views, each processed by an agent that solves a convex subproblem parameterized by a neural encoder. Agents coordinate through the Alternating Direction Method of Multipliers (ADMM) with inter-agent constraints specified by a cellular sheaf. The sheaf specifies which aspects of neighboring solutions must agree, allowing for heterogeneous notions of global consensus. Backpropagating through the unrolled optimization jointly trains all components of the multi-agent system. We evaluate on maze pathfinding, image classification, and Sudoku, where agents with individually insufficient local views learn to coordinate to produce correct global outputs. On MNIST, the local-view decomposition yields improved robustness to distribution shifts relative to a standard CNN. On Sudoku, the optimization-derived structure yields markedly higher solve rates than parameter-matched MPNN baselines. Finally, the ADMM structure exposes distinct primal, consensus, and dual state variables, opening the coordination dynamics to direct analysis and intervention -- a property unavailable in standard message-passing architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sheaf-ADMM, a differentiable multi-agent coordination framework in which an input is decomposed into overlapping local views. Each agent solves a convex subproblem whose objective and constraints are parameterized by a neural encoder; inter-agent agreement constraints are encoded by a cellular sheaf and enforced via ADMM. The entire system is trained end-to-end by back-propagation through unrolled ADMM iterations. Empirical results are reported on maze pathfinding, MNIST classification under distribution shift, and Sudoku, with claims that the optimization-derived coordination yields improved robustness and higher solve rates than parameter-matched MPNN baselines, while also exposing interpretable primal, consensus, and dual states.
Significance. If the convexity and convergence claims hold, the framework would offer a principled way to embed optimization structure into multi-agent neural systems, enabling heterogeneous consensus via sheaves and direct inspection of coordination dynamics unavailable in standard message-passing models. The explicit separation of primal, consensus, and dual variables is a concrete strength that could support future analysis and intervention work.
major comments (2)
- [Abstract] Abstract: the statement that each agent 'solves a convex subproblem parameterized by a neural encoder' is load-bearing for the claimed ADMM convergence and for attributing performance gains to 'optimization-derived structure.' No mechanism (e.g., quadratic forms, PSD constraints, or restricted activations) is described that would guarantee convexity once the encoder weights are free parameters; standard ADMM theory does not apply to arbitrary non-convex objectives.
- [Abstract] Abstract and evaluation sections: the reported MNIST robustness and Sudoku solve-rate improvements are presented as consequences of the sheaf-ADMM coordination. Without verification that the unrolled iterations reach stationary points under the learned neural parameterization, these gains cannot be confidently distinguished from generic message-passing effects.
minor comments (2)
- The manuscript should report error bars, data splits, and ablation controls for all three tasks to allow verification of the empirical claims.
- Notation for the cellular sheaf and the precise form of the ADMM updates should be introduced with explicit equations rather than high-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the convexity assumptions and the need to verify convergence of the unrolled iterations. We address each point below and will revise the manuscript accordingly to strengthen the theoretical grounding and empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that each agent 'solves a convex subproblem parameterized by a neural encoder' is load-bearing for the claimed ADMM convergence and for attributing performance gains to 'optimization-derived structure.' No mechanism (e.g., quadratic forms, PSD constraints, or restricted activations) is described that would guarantee convexity once the encoder weights are free parameters; standard ADMM theory does not apply to arbitrary non-convex objectives.
Authors: We agree that the manuscript does not describe an explicit mechanism to guarantee convexity of the subproblems once the neural encoder weights become free parameters. This limits the direct applicability of standard ADMM convergence theory. In the revised manuscript we will add a subsection specifying that subproblem objectives are restricted to quadratic forms whose Hessians are constrained to be positive semi-definite (via parameterization or projection steps), and we will state the resulting conditions under which ADMM convergence guarantees continue to hold. revision: yes
-
Referee: [Abstract] Abstract and evaluation sections: the reported MNIST robustness and Sudoku solve-rate improvements are presented as consequences of the sheaf-ADMM coordination. Without verification that the unrolled iterations reach stationary points under the learned neural parameterization, these gains cannot be confidently distinguished from generic message-passing effects.
Authors: We concur that without explicit checks that the unrolled ADMM iterations reach stationary points, it is difficult to isolate the contribution of the optimization-derived coordination. In the revision we will include additional figures and tables reporting primal and dual residual norms across training and test iterations for the MNIST and Sudoku experiments, together with a short analysis confirming that the learned parameterizations produce convergent behavior on the reported tasks. revision: yes
Circularity Check
No circularity: derivation is self-contained against external benchmarks
full rationale
The paper introduces a differentiable Sheaf-ADMM framework in which agents solve neural-parameterized convex subproblems coordinated by cellular sheaves, with backpropagation through unrolled iterations. The abstract and described evaluations on MNIST robustness and Sudoku solve rates are presented as empirical outcomes of this architecture relative to standard CNN and MPNN baselines. No equations, claims, or performance metrics are shown to reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations; the coordination dynamics and optimization-derived structure are treated as independent contributions. The framework is therefore self-contained and externally falsifiable on the reported tasks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural encoder weights
axioms (2)
- domain assumption Each agent's subproblem remains convex after neural parameterization
- domain assumption Cellular sheaves can be chosen to encode the necessary inter-agent constraints
invented entities (1)
-
Cellular sheaf for heterogeneous consensus
no independent evidence
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Adler, J. and \"O ktem, O. Learned primal-dual reconstruction. IEEE Transactions on Medical Imaging, 37 0 (6): 0 1322--1332, 2018. doi:10.1109/TMI.2018.2799231
-
[3]
Agrawal, A., Amos, B., Barratt, S., Boyd, S., Diamond, S., and Kolter, J. Z. Differentiable convex optimization layers. Advances in neural information processing systems, 32, 2019
2019
-
[4]
and Kolter, J
Amos, B. and Kolter, J. Z. OptNet : Differentiable optimization as a layer in neural networks. In International Conference on Machine Learning, pp.\ 136--145, 2017
2017
-
[5]
M., and Vandergheynst, P
Arroyo, A., Gravina, A., Gutteridge, B., Barbero, F., Gallicchio, C., Dong, X., Bronstein, M. M., and Vandergheynst, P. On vanishing gradients, over-smoothing, and over-squashing in GNNs : Bridging recurrent and graph learning. In Advances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=N4cyRMuLyl
2025
-
[6]
M., Dong, X., Li \`o , P., Pascanu, R., and Vandergheynst, P
Arroyo, A., Barbero, F., Blayney, H., Bronstein, M. M., Dong, X., Li \`o , P., Pascanu, R., and Vandergheynst, P. A survey on over-smoothing and over-squashing: Unified propagation perspectives on graph neural networks and transformers. OpenReview, 2026. URL https://openreview.net/forum?id=H9zhC5pVnH. Accepted by Transactions on Machine Learning Research
2026
-
[7]
Z., and Koltun, V
Bai, S., Kolter, J. Z., and Koltun, V. Deep equilibrium models. Advances in Neural Information Processing Systems, 32, 2019
2019
-
[8]
P., Li \`o , P., and Bronstein, M
Bodnar, C., Di Giovanni, F., Chamberlain, B. P., Li \`o , P., and Bronstein, M. M. Neural sheaf diffusion: A topological perspective on heterophily and oversmoothing in GNN s. In Advances in Neural Information Processing Systems, 2022
2022
-
[9]
Boyd, S., Parikh, N., Chu, E., Peleato, B., and Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3 0 (1): 0 1--122, 2011. doi:10.1561/2200000016
-
[10]
Curry, J. M. Sheaves, Cosheaves and Applications. PhD thesis, University of Pennsylvania, 2014. URL https://arxiv.org/abs/1303.3255
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
a usner, P., Hern \'a ndez Escobar , D., and Sj \
Doerks, H., H \"a usner, P., Hern \'a ndez Escobar , D., and Sj \"o lund, J. Learning to accelerate distributed ADMM using graph neural networks. In Proceedings of the 8th Annual Conference on Learning for Dynamics and Control, volume 331 of Proceedings of Machine Learning Research, pp.\ 1--26. PMLR, 2026. URL https://openreview.net/forum?id=9vOQ9B6Q1k
2026
-
[12]
Sheaves reloaded: A direction awakening
Fiorini, S., Aktas, H., Duta, I., Morerio, P., Del Bue, A., Li \`o , P., and Coniglio, S. Sheaves reloaded: A direction awakening. In International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=iDiiETH7Qv
2026
-
[13]
Ghadimi, E., Teixeira, A., Shames, I., and Johansson, M. Optimal parameter selection for the alternating direction method of multipliers ( ADMM ): Quadratic problems. IEEE Transactions on Automatic Control, 60 0 (3): 0 644--658, 2015. doi:10.1109/TAC.2014.2354892
-
[14]
S., Riley, P
Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O., and Dahl, G. E. Neural message passing for quantum chemistry. In International Conference on Machine Learning, pp.\ 1263--1272, 2017
2017
-
[15]
Giselsson, P. and Boyd, S. Diagonal scaling in Douglas-Rachford splitting and ADMM . In 53rd IEEE Conference on Decision and Control, pp.\ 5033--5039. IEEE, 2014. doi:10.1109/CDC.2014.7040175
-
[16]
Adaptive computation time for recurrent neural networks
Graves, A. Adaptive computation time for recurrent neural networks. arXiv [cs.NE], 2016
2016
-
[17]
and LeCun, Y
Gregor, K. and LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the 27th International Conference on Machine Learning, pp.\ 399--406. Omnipress, 2010
2010
-
[18]
Ha, D. and Tang, Y. Collective intelligence for deep learning: A survey of recent developments. Collective Intelligence, 1 0 (1): 0 26339137221114874, 2022. doi:10.1177/26339137221114874
-
[19]
F., Bou Barcelo , J., Copeland, A., Dixon, W., and Fairbanks, J
Hanks, T., Nino, C. F., Bou Barcelo , J., Copeland, A., Dixon, W., and Fairbanks, J. Heterogeneous multi-agent multi-target tracking using cellular sheaves, 2025 a . URL https://arxiv.org/abs/2512.24886
-
[20]
Distributed multi-agent coordination over cellular sheaves
Hanks, T., Riess, H., Cohen, S., Gross, T., Hale, M., and Fairbanks, J. Distributed multi-agent coordination over cellular sheaves. In 2025 IEEE 64th Conference on Decision and Control (CDC), pp.\ 3057--3064. IEEE, 2025 b . doi:10.1109/CDC57313.2025.11312066
-
[21]
and Gebhart, T
Hansen, J. and Gebhart, T. Sheaf neural networks. In NeurIPS 2020 Workshop on Topological Data Analysis and Beyond, 2020. URL https://openreview.net/forum?id=GgcgIJsT8HD
2020
-
[22]
Distributed optimization with sheaf homological constraints
Hansen, J. and Ghrist, R. Distributed optimization with sheaf homological constraints. In 2019 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton), pp.\ 565--571. IEEE, 2019 a . doi:10.1109/ALLERTON.2019.8919796
-
[23]
Hansen, J. and Ghrist, R. Learning sheaf laplacians from smooth signals. In ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 5446--5450. IEEE, 2019 b . doi:10.1109/ICASSP.2019.8683709
-
[24]
Hansen, J. and Ghrist, R. Toward a spectral theory of cellular sheaves. Journal of Applied and Computational Topology, 3 0 (4): 0 315--358, 2019 c . doi:10.1007/s41468-019-00038-7
-
[25]
Hansen, J. and Ghrist, R. Opinion dynamics on discourse sheaves. SIAM Journal on Applied Mathematics, 81 0 (5): 0 2033--2060, 2021. doi:10.1137/20M1341088
-
[26]
Hong, M., Luo, Z.-Q., and Razaviyayn, M. Convergence analysis of alternating direction method of multipliers for a family of nonconvex problems. SIAM Journal on Optimization, 26 0 (1): 0 337--364, 2016. doi:10.1137/140990309
-
[27]
Gated graph sequence neural networks
Li, Y., Tarlow, D., Brockschmidt, M., and Zemel, R. Gated graph sequence neural networks. In International Conference on Learning Representations, 2016. URL https://openreview.net/forum?id=HSgW989Kp-q
2016
-
[28]
Monga, V., Li, Y., and Eldar, Y. C. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing. IEEE Signal Processing Magazine, 38 0 (2): 0 18--44, 2021. doi:10.1109/MSP.2020.3016905
-
[29]
Growing neural cellular automata
Mordvintsev, A., Randazzo, E., Niklasson, E., and Levin, M. Growing neural cellular automata. Distill, 2020. doi:10.23915/distill.00023. https://distill.pub/2020/growing-ca
-
[30]
Noah, Y. and Shlezinger, N. Distributed learn-to-optimize: Limited communications optimization over networks via deep unfolded distributed ADMM . IEEE Transactions on Mobile Computing, 24 0 (4): 0 3012--3024, 2025. doi:10.1109/TMC.2024.3502574
-
[31]
Sudoku-Dataset
Rastogi, R. Sudoku-Dataset . https://huggingface.co/datasets/Ritvik19/Sudoku-Dataset, 2024. Accessed: 2025-01-28
2024
-
[32]
L., Belieni, J., Souza, A
Ribeiro, A., Ten \'o rio, A. L., Belieni, J., Souza, A. H., and Mesquita, D. Cooperative sheaf neural networks. In International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=AHpexliCTM
2026
-
[33]
D., Kuperman, H., Oshin, A., Abdul, A
Saravanos, A. D., Kuperman, H., Oshin, A., Abdul, A. T., Pacelli, V., and Theodorou, E. A. Deep distributed optimization for large-scale quadratic programming. In International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=hzuumhfYSO
2025
-
[34]
Sumpter, D. J. T. Collective animal behavior. Princeton University Press, 2010
2010
-
[35]
Learning to coordinate: Distributed meta-trajectory optimization via differentiable ADMM - DDP
Wang, B., Gao, Y., Sun, T., and Zhao, L. Learning to coordinate: Distributed meta-trajectory optimization via differentiable ADMM - DDP . arXiv [cs.LG], 2025 a
2025
-
[36]
Wang, G., Li, J., Sun, Y., Chen, X., Liu, C., Wu, Y., Lu, M., Song, S., and Abbasi Yadkori , Y. Hierarchical reasoning model, 2025 b . URL https://arxiv.org/abs/2506.21734
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Global convergence of ADMM in nonconvex nonsmooth optimization
Wang, Y., Yin, W., and Zeng, J. Global convergence of ADMM in nonconvex nonsmooth optimization. Journal of Scientific Computing, 78 0 (1): 0 29--63, 2019. doi:10.1007/s10915-018-0757-z
-
[38]
ADMM penalty parameter selection by residual balancing
Wohlberg, B. ADMM penalty parameter selection by residual balancing. arXiv [math.OC], 2017
2017
-
[39]
Differentiable linearized ADMM
Xie, X., Wu, J., Zhong, Z., Liu, G., and Lin, Z. Differentiable linearized ADMM . In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp.\ 6902--6911. PMLR, 2019. URL https://proceedings.mlr.press/v97/xie19c.html
2019
-
[40]
Adaptive ADMM with spectral penalty parameter selection
Xu, Z., Figueiredo, M., and Goldstein, T. Adaptive ADMM with spectral penalty parameter selection. In Artificial Intelligence and Statistics, pp.\ 718--727. PMLR, 2017
2017
-
[41]
Deep ADMM -net for compressive sensing MRI
Yang, Y., Sun, J., Li, H., and Xu, Z. Deep ADMM -net for compressive sensing MRI . Advances in Neural Information Processing Systems, 29, 2016
2016
-
[42]
Yang, Y., Guan, X., Jia, Q.-S., Yu, L., Xu, B., and Spanos, C. J. A survey of ADMM variants for distributed optimization: Problems, algorithms and features. arXiv [cs.DC], 2022
2022
-
[43]
Asynchronous nonlinear sheaf diffusion for multi-agent coordination
Zhao, Y., Hanks, T., Riess, H., Cohen, S., Hale, M., and Fairbanks, J. Asynchronous nonlinear sheaf diffusion for multi-agent coordination. arXiv [math.OC], 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.