Generalizing Multi-Scale Time-Series Modeling with a Single Operator
Pith reviewed 2026-06-28 23:13 UTC · model grok-4.3
The pith
A single learnable operator generalizes multi-scale time-series models by replacing fixed discrete scaling with distance-aware kernels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing scaling operators all rely on fixed and discrete scaling; SiGMA removes this limit by inserting a learnable discrete Gaussian kernel that performs distance-aware scaling inside one unified architecture, producing the best results on 13 of 16 long-term forecasting settings plus training speed-ups of up to 5.3 times and memory reductions of up to 3.8 times.
What carries the argument
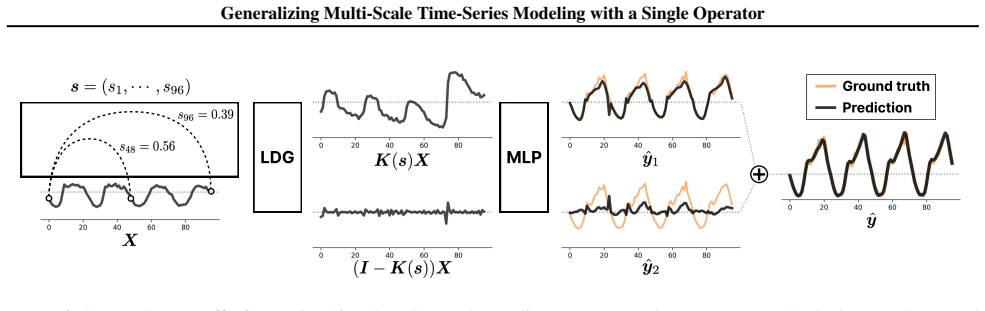
The learnable discrete Gaussian (LDG) kernel, which supplies continuous, distance-dependent scaling inside the unified scaling operator family.
If this is right
- One architecture suffices for both long-term and short-term forecasting instead of separate designs.
- Training runs up to 5.3 times faster than the strongest competing multi-scale models.
- Memory use drops by up to 3.8 times relative to the strongest competitors.
- The same operator family unification applies across the evaluated benchmarks.
Where Pith is reading between the lines
- The same kernel idea could be tested on sequence tasks outside forecasting, such as anomaly detection or imputation.
- If the unification holds, future work can focus on refining the kernel rather than inventing new operator families.
- The distance-aware property may allow the model to adapt scale choices automatically when input sampling rates change.
Load-bearing premise
The learnable discrete Gaussian kernel actually removes the fixed discrete scaling limit that the paper attributes to all earlier methods.
What would settle it
On the same long-term and short-term forecasting benchmarks, SiGMA fails to match or exceed the strongest prior multi-scale baselines in accuracy while also failing to deliver the reported speed and memory gains.
Figures


read the original abstract
Multi-scale modeling has emerged as an effective design principle for time-series forecasting by capturing temporal dynamics at multiple resolutions. As no principled foundation has been established in the literature, we unify existing scaling methods into a scaling operator family, revealing a fundamental limitation of existing approaches: reliance on fixed and discrete scaling. To address this limitation, we propose SiGMA (Single Generalized Multi-scale Architecture), which enables distance-aware scaling via the learnable discrete Gaussian (LDG) kernel grounded in scale-space theory. We evaluate SiGMA comprehensively on long- and short-term forecasting benchmarks against state-of-the-art multi-scale baselines. SiGMA outperforms all competitors on both tasks, especially achieving the best performance in 13 out of 16 long-term evaluation settings. Beyond accuracy, SiGMA significantly improves training speed by up to 5.3 times and reduces memory consumption by up to 3.8 times over the strongest competitors. Code is available at https://github.com/cheonwoolee/SiGMA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript unifies existing multi-scale time-series forecasting methods into a scaling operator family whose shared limitation is reliance on fixed and discrete scaling. It proposes SiGMA, a single architecture that replaces this with a learnable discrete Gaussian (LDG) kernel grounded in scale-space theory to enable distance-aware scaling. On long- and short-term forecasting benchmarks, SiGMA is reported to outperform all competitors (best in 13 of 16 long-term settings) while improving training speed by up to 5.3 imes and reducing memory by up to 3.8 imes.
Significance. If the LDG construction is shown to support scalings strictly between the discrete grids of prior methods, the work would supply a principled generalization of multi-scale modeling and a practical single-operator architecture with measurable efficiency gains. The reported breadth of outperformance and speed/memory improvements would then constitute a concrete contribution to time-series forecasting.
major comments (2)
- [Unification section] The unification of prior methods and the diagnosis that fixed/discrete scaling is their sole shared defect is load-bearing for the motivation, yet no explicit check is provided that the family is exhaustive or that omitted methods already support non-discrete scaling.
- [LDG kernel and scale-space grounding] No derivation or explicit construction shows that the LDG kernel parameters can realize continuous scalings lying strictly between the discrete grid points used by every baseline; without this, the claim that the kernel removes the attributed limitation remains an assumption rather than a demonstrated property.
minor comments (2)
- A brief operational comparison (e.g., how the learned kernel width or variance differs from fixed discrete kernels at inference time) would clarify the distance-aware claim.
- [Experimental results] The experimental tables would be strengthened by reporting standard deviations across seeds or statistical significance tests for the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the unification and the LDG kernel. We address each major comment below and will incorporate clarifications and derivations in the revision.
read point-by-point responses
-
Referee: [Unification section] The unification of prior methods and the diagnosis that fixed/discrete scaling is their sole shared defect is load-bearing for the motivation, yet no explicit check is provided that the family is exhaustive or that omitted methods already support non-discrete scaling.
Authors: The unification section groups the predominant multi-scale methods appearing in recent time-series forecasting literature into a scaling operator family to identify their shared reliance on fixed discrete scales; it does not assert exhaustiveness. The diagnosis follows directly from the explicit operator definitions of the included methods. To address the concern, we will add a short discussion paragraph noting that certain omitted techniques (such as continuous wavelet transforms) may support non-discrete scaling, while emphasizing that the discrete-grid limitation holds for the representative baselines used in our experiments and comparisons. revision: yes
-
Referee: [LDG kernel and scale-space grounding] No derivation or explicit construction shows that the LDG kernel parameters can realize continuous scalings lying strictly between the discrete grid points used by every baseline; without this, the claim that the kernel removes the attributed limitation remains an assumption rather than a demonstrated property.
Authors: The LDG kernel is obtained by making the scale and variance parameters of the discrete Gaussian approximation learnable, consistent with scale-space theory in which the Gaussian supports continuous scale. The manuscript presents the resulting formulation and its distance-aware property. We agree that an explicit derivation or numerical illustration (e.g., LDG output at a non-integer scale such as 1.5 when baselines are restricted to integer grids) would make the interpolation property concrete rather than implicit. We will add this derivation together with a small illustrative example in the revised Section 3.2. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper unifies prior multi-scale methods into a scaling-operator family and attributes a shared limitation (fixed discrete scaling) to them, then introduces the LDG kernel as grounded in external scale-space theory to address it. No equations, fitted parameters, or self-citations are shown that reduce the claimed unification, the diagnosed limitation, or the performance gains to quantities defined by construction from the inputs. Empirical results on benchmarks are presented as independent validation rather than tautological outputs of the model definition. The central claims therefore retain independent content and do not collapse into self-definition or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing multi-scale methods can be unified into a single scaling operator family whose shared limitation is fixed and discrete scaling.
- domain assumption Scale-space theory supplies a valid foundation for the learnable discrete Gaussian kernel.
Reference graph
Works this paper leans on
-
[1]
Adap- tive multi-scale decomposition framework for time se- ries forecasting
Hu, Y ., Liu, P., Zhu, P., Cheng, D., and Dai, T. Adap- tive multi-scale decomposition framework for time se- ries forecasting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp. 17359–17367, 2025a. Hu, Y ., Zhang, G., Liu, P., Lan, D., Li, N., Cheng, D., Dai, T., Xia, S.-T., and Pan, S. TimeFilter: Patch-specific spatial- tem...
2004
-
[2]
Because the bump function ϕ(·) is C ∞ and the normalization preserves smoothness, the weightswj(s) are differentiable in s for all non-integer values
Thus the generalized operator reduces exactly to the classical operator at integer scales, ensuring consistency. Because the bump function ϕ(·) is C ∞ and the normalization preserves smoothness, the weightswj(s) are differentiable in s for all non-integer values. Since the output is a convex combination of the fj(x), the entire operator f(x|s) is differen...
2023
-
[3]
SIGMAachieves the smallest forecasting errors in 55 out of 80 evaluation settings and the second-best in 19 cases. MethodSIGMA(Ours) AMD(2025a)MultiPatch.(2025)WPMixer(2025)TimeMixer(2024)MSGNet(2024) MICN(2023)TimesNet(2023) Pyra.(2022b)MetricMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAEMSE MAE Weather 960.160 0.2040.182 0.2270.172 0.2110.164 ...
-
[4]
A standard definition based on tail mass is W(ϵ) = min w: X |d|>w Kd ≤ϵ X d Kd ,(10) whereϵis a user-specified tolerance (Greengard & Strain, 1991)
Here,Wdenotes the effective kernel support. A standard definition based on tail mass is W(ϵ) = min w: X |d|>w Kd ≤ϵ X d Kd ,(10) whereϵis a user-specified tolerance (Greengard & Strain, 1991). We report the computational time and memory usage of different LDG implementations in Figure
1991
-
[5]
On the long-term forecasting benchmarks, SIGMAachieves lower average MSE and MAE than AMD on nearly all datasets, while maintaining sufficiently small standard deviations. On the short-term M4 benchmark, the averaged SMAPE, MASE, and OW A scores of SIGMAremain consistently better, and the corresponding standard deviations are of similar or smaller magnitu...
2025
-
[6]
Across the long-term forecasting benchmarks, SIGMA generally achieves the best accuracy on datasets with fewer variables (e.g., ETT)
for long-term forecasting and short-term forecasting. Across the long-term forecasting benchmarks, SIGMA generally achieves the best accuracy on datasets with fewer variables (e.g., ETT). As the number of variables increases (e.g., Traffic), TimeFilter obtains the strongest overall performance, owing to its patch-wise filtration mechanism that explicitly ...
2025
-
[7]
L L= 24 L= 48 L= 96 L= 192 L= 336 L= 512 L= 720 Metric MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE MSE MAE Weather 96 0.220 0.247 0.208 0.242 0.174 0.216 0.157 0.204 0.153 0.203 0.151 0.204 0.158 0.214 192 0.262 0.279 0.251 0.275 0.220 0.257 0.202 0.245 0.198 0.246 0.202 0.252 0.203 0.256 336 0.323 0.322 0.306 0.313 0.278 0.298 0.259 0.288 0.254 0.289...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.