Softsign: Smooth Sign in Your Optimizer For Better Parameter Heterogeneity Handling
Pith reviewed 2026-06-28 22:49 UTC · model grok-4.3
The pith
Replacing the hard sign with a temperature-controlled soft sign lets optimizers adapt updates to each parameter's scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
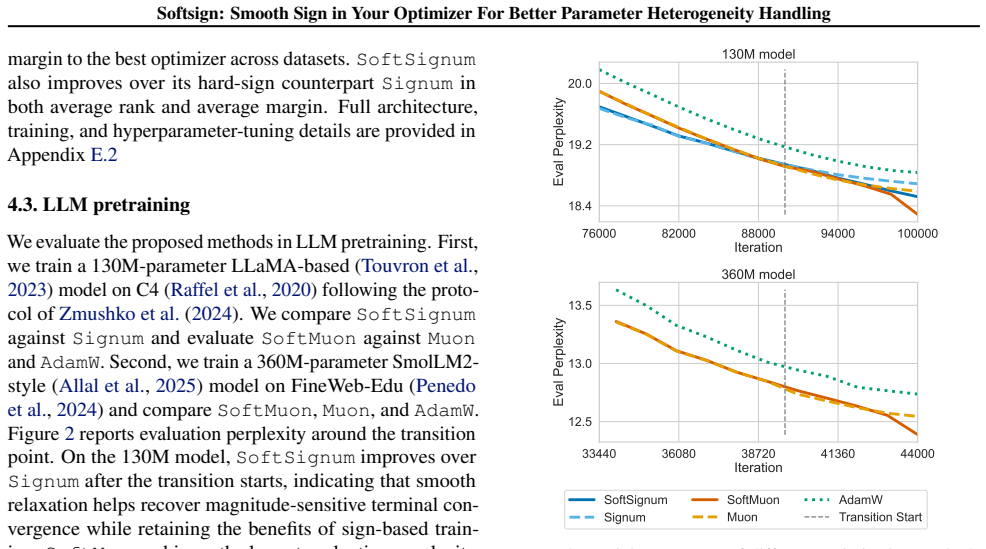
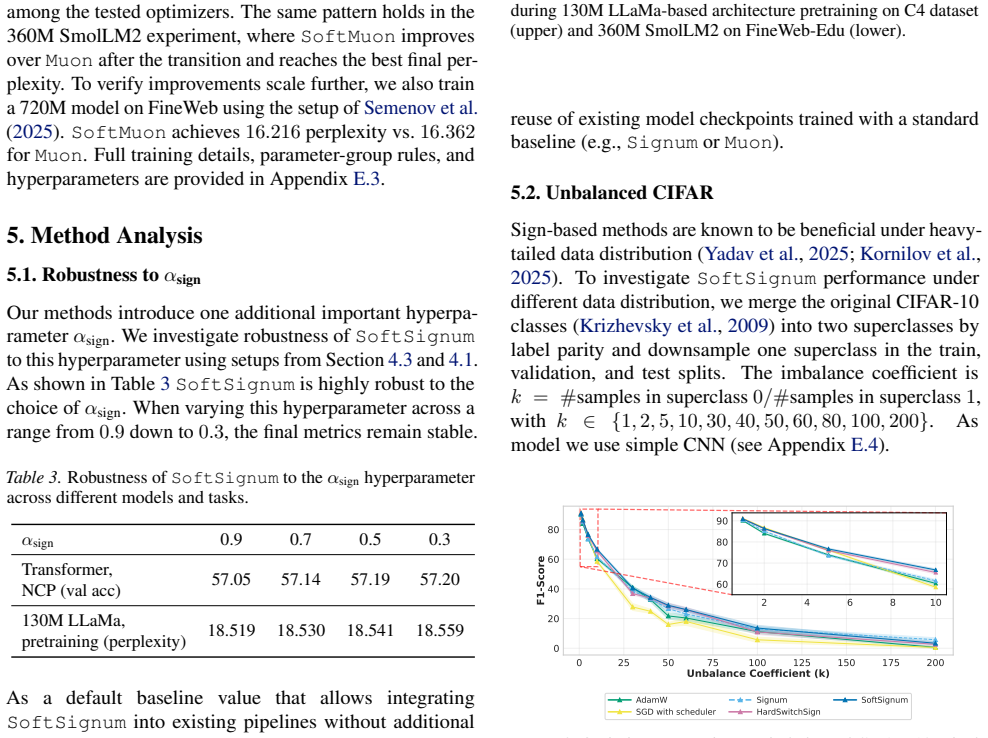
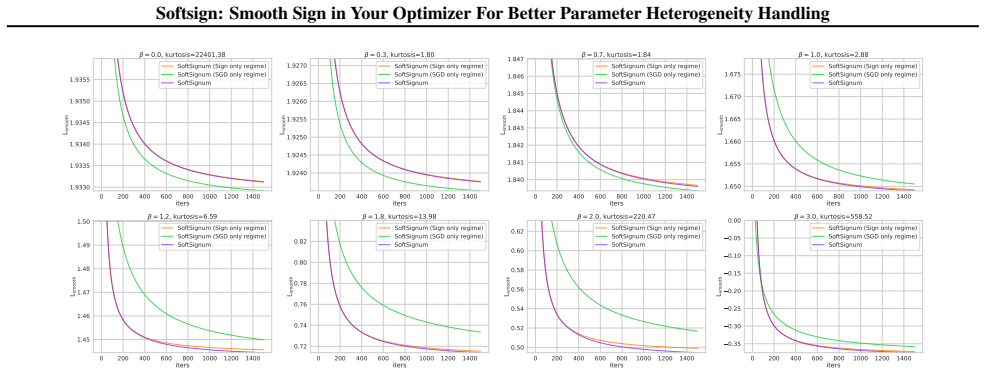
SoftSignum replaces the hard sign map with a temperature-controlled soft-sign transformation that enables a parameter-wise transition from sign-like updates to magnitude-sensitive SGD-like steps, complemented by an adaptive quantile-based temperature schedule. This principle extends to SoftMuon for matrix-valued parameters. A generalized geometry-relaxation framework based on strongly convex regularizers and Fenchel conjugates establishes convergence in the stochastic non-convex setting. Empirical results on diverse deep learning tasks, including LLM pretraining, show consistent improvements.
What carries the argument
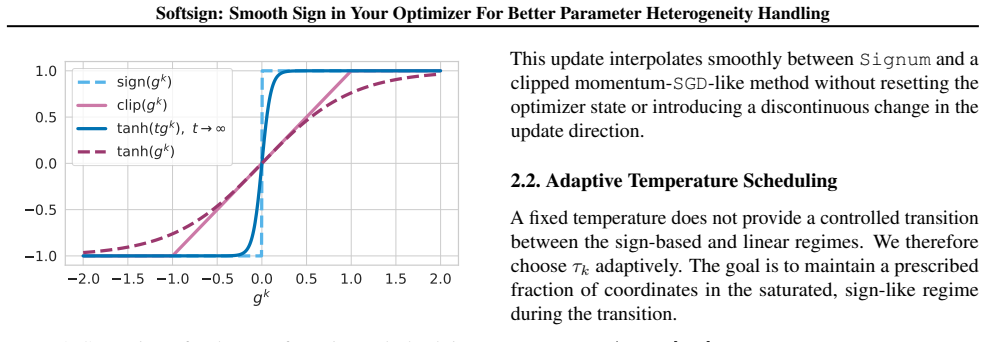
The temperature-controlled soft-sign transformation, which approximates the sign function continuously and scales updates based on gradient magnitude relative to the temperature parameter.
If this is right
- Sign-based optimizers can achieve better terminal convergence by incorporating magnitude information adaptively.
- The same relaxation principle applies to matrix-valued optimizers like Muon.
- Convergence is guaranteed for stochastic non-convex optimization under the generalized framework.
- Adaptive temperature scheduling reduces oscillation without manual per-task tuning.
Where Pith is reading between the lines
- The soft-sign approach could be applied to other non-differentiable or piecewise optimizers to improve stability.
- Quantile-based scheduling might generalize to other adaptive mechanisms in optimizers.
- Testing on a wider range of architectures could reveal how parameter heterogeneity varies across model types.
Load-bearing premise
The quantile-based temperature schedule and soft-sign transformation reliably reduce oscillation without introducing new instabilities or requiring per-task retuning.
What would settle it
Running SoftSignum or SoftMuon on an LLM pretraining task and observing equal or worse performance compared to the hard sign counterpart or AdamW would falsify the improvement claim.
Figures

read the original abstract
Sign-based and LMO-inspired optimizers have recently attracted substantial attention in deep learning due to their strong performance and low memory footprint. However, their fixed-magnitude updates can hurt terminal convergence: they decouple update mechanisms from gradient magnitudes and fail to account for parameter heterogeneity, often leading to oscillation rather than convergence. We propose SoftSignum, a smooth relaxation of sign-based optimization that replaces the hard sign map with a temperature-controlled soft-sign transformation, enabling a parameter-wise transition from sign-like updates to magnitude-sensitive SGD-like steps. We complement it with an adaptive quantile-based temperature schedule and extend the same principle to matrix-valued optimizers, obtaining SoftMuon. We also develop a generalized geometry-relaxation framework based on strongly convex regularizers and Fenchel conjugates, proving convergence in stochastic non-convex setting. Experiments on diverse deep learning tasks, including LLM pretraining, show that SoftSignum and SoftMuon consistently improve over their hard sign-based counterparts and standard AdamW.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SoftSignum, a smooth relaxation of sign-based optimization via a temperature-controlled soft-sign transformation that transitions parameter-wise from sign-like to magnitude-sensitive updates. It introduces an adaptive quantile-based temperature schedule, extends the approach to matrix-valued optimizers as SoftMuon, and develops a generalized geometry-relaxation framework using strongly convex regularizers and Fenchel conjugates to prove convergence in the stochastic non-convex setting. Experiments on diverse deep learning tasks including LLM pretraining report consistent improvements over hard sign-based counterparts and AdamW.
Significance. If the convergence result applies to the implemented algorithm and the empirical gains prove robust across tasks, the work could provide a useful bridge between memory-efficient sign methods and standard SGD-like behavior for handling parameter heterogeneity. The generalized framework based on regularizers and conjugates represents a potential conceptual contribution if the derivations are complete and the assumptions are clearly stated.
major comments (3)
- [Abstract / Theoretical Framework] Abstract and theoretical section: The convergence proof is claimed for the generalized geometry-relaxation framework in the stochastic non-convex setting, yet the practical SoftSignum and SoftMuon rely on a data-dependent adaptive quantile temperature schedule. The proof assumptions (likely requiring fixed or bounded-variation temperature) appear incompatible with the evolving schedule, rendering the guarantee inapplicable to the reported algorithm; this is load-bearing for the central theoretical claim.
- [Abstract] Abstract: The manuscript asserts consistent experimental gains and a convergence proof but supplies no derivation details, error bars, dataset descriptions, or hyperparameter selection protocol. Without these, it is impossible to verify whether the quantile schedule parameters were chosen independently of final performance or whether gains reflect post-hoc tuning.
- [Adaptive Schedule] Adaptive quantile schedule: The temperature schedule is explicitly data-dependent, which risks reducing to a fitted hyperparameter and introduces potential circularity with the performance metric; this directly affects both the claimed convergence and the reliability of the reported improvements over baselines.
minor comments (1)
- [Title / Abstract] Abstract: The title uses 'Softsign' while the text introduces 'SoftSignum'; standardize nomenclature for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, providing clarifications on the theoretical framework, experimental reporting, and adaptive schedule while indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Theoretical Framework] Abstract and theoretical section: The convergence proof is claimed for the generalized geometry-relaxation framework in the stochastic non-convex setting, yet the practical SoftSignum and SoftMuon rely on a data-dependent adaptive quantile temperature schedule. The proof assumptions (likely requiring fixed or bounded-variation temperature) appear incompatible with the evolving schedule, rendering the guarantee inapplicable to the reported algorithm; this is load-bearing for the central theoretical claim.
Authors: The generalized framework is formulated around strongly convex regularizers and Fenchel conjugates to accommodate temperature schedules satisfying boundedness and limited-variation conditions. The quantile schedule is constructed from gradient statistics to ensure the temperature parameter remains within these bounds while transitioning smoothly. We will revise the theoretical section to add an explicit lemma verifying that the adaptive quantile schedule meets the convergence assumptions, thereby extending the guarantee to the implemented algorithm. revision: yes
-
Referee: [Abstract] Abstract: The manuscript asserts consistent experimental gains and a convergence proof but supplies no derivation details, error bars, dataset descriptions, or hyperparameter selection protocol. Without these, it is impossible to verify whether the quantile schedule parameters were chosen independently of final performance or whether gains reflect post-hoc tuning.
Authors: The abstract is necessarily concise as a summary. The full manuscript details all datasets, experimental protocols, and hyperparameter selection (including the quantile schedule derivation from gradient statistics) in the experimental sections, with error bars reported throughout the results. The schedule parameters are computed from data statistics without reference to final performance. We will add a short clarifying sentence to the abstract on the independence of the schedule from post-hoc tuning. revision: partial
-
Referee: [Adaptive Schedule] Adaptive quantile schedule: The temperature schedule is explicitly data-dependent, which risks reducing to a fitted hyperparameter and introduces potential circularity with the performance metric; this directly affects both the claimed convergence and the reliability of the reported improvements over baselines.
Authors: The quantile schedule is computed at each step solely from the empirical distribution of per-parameter gradient magnitudes, without any dependence on the loss value or optimization of the final performance metric. This data-driven adaptation is the mechanism for handling heterogeneity and does not constitute post-hoc fitting or circularity. We will add an ablation study in the revision demonstrating robustness of the schedule across random seeds and initializations. revision: yes
Circularity Check
No significant circularity in claimed derivation
full rationale
The abstract presents SoftSignum as a smooth relaxation with an adaptive quantile temperature schedule, extends it to SoftMuon, and states a convergence proof for a generalized geometry-relaxation framework under strongly convex regularizers and Fenchel conjugates. No quoted equations or sections show a self-definitional loop, a fitted parameter renamed as prediction, or a load-bearing self-citation chain that reduces the central claim to its own inputs by construction. The adaptive schedule is described as a complement to the method rather than a statistical fit forced to match performance metrics. The derivation chain therefore remains independent of the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pp.\ 2623--2631, 2019
2019
-
[3]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Allal, L. B., Lozhkov, A., Bakouch, E., Bl \'a zquez, G. M., Penedo, G., Tunstall, L., Marafioti, A., Kydl \' c ek, H., Lajar \' n, A. P., Srivastav, V., et al. Smollm2: When smol goes big--data-centric training of a small language model. arXiv preprint arXiv:2502.02737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Amsel, N., Persson, D., Musco, C., and Gower, R. M. The polar express: Optimal matrix sign methods and their application to the muon algorithm. arXiv preprint arXiv:2505.16932, 2025. URL https://arxiv.org/abs/2505.16932
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
System card: Claude Opus 4.5
Anthropic . System card: Claude Opus 4.5 . Anthropic technical report, November 2025. URL https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf
2025
-
[6]
Graphland: Evaluating graph machine learning models on diverse industrial data
Bazhenov, G., Platonov, O., and Prokhorenkova, L. Graphland: Evaluating graph machine learning models on diverse industrial data. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[7]
and Teboulle, M
Beck, A. and Teboulle, M. Mirror descent and nonlinear projected subgradient methods for convex optimization. Operations Research Letters, 31 0 (3): 0 167--175, 2003
2003
-
[8]
Old Optimizer, New Norm: An Anthology
Bernstein, J. and Newhouse, L. Old optimizer, new norm: An anthology. In NeurIPS 2024 Workshop on Optimization for Machine Learning (OPT), 2024. URL https://arxiv.org/abs/2409.20325
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
and Newhouse, L
Bernstein, J. and Newhouse, L. Modular duality in deep learning. In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pp.\ 3920--3930. PMLR, 2025
2025
-
[10]
signsgd: Compressed optimisation for non-convex problems
Bernstein, J., Wang, Y.-X., Azizzadenesheli, K., and Anandkumar, A. signsgd: Compressed optimisation for non-convex problems. In International conference on machine learning, pp.\ 560--569. PMLR, 2018
2018
-
[11]
H., Hansen, S
Byrd, R. H., Hansen, S. L., Nocedal, J., and Singer, Y. A stochastic quasi-newton method for large-scale optimization. SIAM Journal on Optimization, 26 0 (2): 0 1008--1031, 2016
2016
-
[12]
Symbolic discovery of optimization algorithms
Chen, X., Liang, C., Huang, D., Real, E., Wang, K., Pham, H., Dong, X., Luong, T., Hsieh, C.-J., Lu, Y., et al. Symbolic discovery of optimization algorithms. Advances in neural information processing systems, 36: 0 49205--49233, 2023
2023
-
[13]
Adaptive subgradient methods for online learning and stochastic optimization
Duchi, J., Hazan, E., and Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. Journal of machine learning research, 12 0 (7), 2011
2011
-
[14]
and Lan, G
Ghadimi, S. and Lan, G. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM journal on optimization, 23 0 (4): 0 2341--2368, 2013
2013
-
[15]
Beyond convexity: Stochastic quasi-convex optimization
Hazan, E., Levy, K., and Shalev-Shwartz, S. Beyond convexity: Stochastic quasi-convex optimization. Advances in Neural Information Processing Systems, 28, 2015
2015
-
[16]
and Schmidhuber, J
Hochreiter, S. and Schmidhuber, J. Long short-term memory. Neural computation, 9 0 (8): 0 1735--1780, 1997
1997
-
[17]
LiMuon: Light and Fast Muon Optimizer for Large Models
Huang, F., Luo, Y., and Chen, S. Limuon: Light and fast muon optimizer for large models. arXiv preprint arXiv:2509.14562, 2025. URL https://arxiv.org/abs/2509.14562
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
On the relation between the sharpest directions of dnn loss and the sgd step length
Jastrzebski, S., Kenton, Z., Ballas, N., Fischer, A., Bengio, Y., and Storkey, A. On the relation between the sharpest directions of dnn loss and the sgd step length. In International Conference on Learning Representations, 2019
2019
-
[19]
Jiang, X., Semenov, A., and Stich, S. U. Enhancing llm training via spectral clipping. arXiv preprint arXiv:2603.14315, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Muon: An optimizer for hidden layers in neural networks, 2024
Jordan, K., Jin, Y., Boza, V., Jiacheng, Y., Cesista, F., Newhouse, L., and Bernstein, J. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon/
2024
-
[21]
Keskar, N. S. and Socher, R. Improving generalization performance by switching from adam to sgd. arXiv preprint arXiv:1712.07628, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Adam: A Method for Stochastic Optimization
Kingma, D. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Kornilov, N., Zmushko, P., Semenov, A., Ikonnikov, M., Gasnikov, A., and Beznosikov, A. Sign operator for coping with heavy-tailed noise in non-convex optimization: High probability bounds under (l\_0, l\_1) -smoothness. arXiv preprint arXiv:2502.07923, 2025
-
[24]
Learning multiple layers of features from tiny images
Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009
2009
-
[25]
v., Casas, A
Laurer, M., Atteveldt, W. v., Casas, A. S., and Welbers, K. Less Annotating , More Classifying – Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT - NLI . Preprint, June 2022. URL https://osf.io/74b8k. Publisher: Open Science Framework
2022
-
[26]
Lewis, A. S. Convex analysis on the hermitian matrices. SIAM Journal on Optimization, 6 0 (1): 0 164--177, 1996
1996
-
[27]
Muon is Scalable for LLM Training
Liu, J., Su, J., Yao, X., Jiang, Z., Lai, G., Du, Y., Qin, Y., Xu, W., Lu, E., Yan, J., Chen, Y., Zheng, H., Liu, Y., Liu, S., Yin, B., He, W., Zhu, H., Wang, Y., Wang, J., Dong, M., Zhang, Z., Kang, Y., Zhang, H., Xu, X., Zhang, Y., Wu, Y., Zhou, X., and Yang, Z. Muon is scalable for llm training, 2025 a . URL https://arxiv.org/abs/2502.16982
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
arXiv preprint arXiv:2506.15054 , year=
Liu, Q., Li, J., and Chen, L. Muon optimizes under spectral norm constraints. arXiv preprint arXiv:2506.15054, 2025 b . URL https://arxiv.org/abs/2506.15054
-
[29]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019
2019
-
[30]
and Martin, C
Mahoney, M. and Martin, C. Traditional and heavy tailed self regularization in neural network models. In International Conference on Machine Learning, pp.\ 4284--4293. PMLR, 2019
2019
-
[31]
Optimizing Rank for High-Fidelity Implicit Neural Representations
McGinnis, J., H \"o lzl, F. A., Shit, S., Bieder, F., Friedrich, P., M \"u hlau, M., Menze, B., Rueckert, D., and Wiestler, B. Optimizing rank for high-fidelity implicit neural representations. arXiv preprint arXiv:2512.14366, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Robust stochastic approximation approach to stochastic programming
Nemirovski, A., Juditsky, A., Lan, G., and Shapiro, A. Robust stochastic approximation approach to stochastic programming. SIAM Journal on Optimization, 19 0 (4): 0 1574--1609, 2009. doi:10.1137/070704277
-
[33]
Nemirovskij, A. S. and Yudin, D. B. Problem complexity and method efficiency in optimization. 1983
1983
-
[34]
Introductory Lectures on Convex Optimization: A Basic Course, volume 87 of Applied Optimization
Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course, volume 87 of Applied Optimization. Kluwer Academic Publishers, Boston, MA, 2004
2004
-
[35]
The fineweb datasets: Decanting the web for the finest text data at scale
Penedo, G., Kydl \' c ek, H., Lozhkov, A., Mitchell, M., Raffel, C., Von Werra, L., Wolf, T., et al. The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems, 37: 0 30811--30849, 2024
2024
-
[36]
Training deep learning models with norm-constrained lmos
Pethick, T., Xie, W., Antonakopoulos, K., Zhu, Z., Silveti-Falls, A., and Cevher, V. Training deep learning models with norm-constrained lmos. In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pp.\ 49069--49104. PMLR, 2025. URL https://proceedings.mlr.press/v267/pethick25a.html
2025
-
[37]
Generalized gradient norm clipping & non-euclidean (l\_0, l\_1) -smoothness
Pethick, T., Xie, W., Erdogan, M., Antonakopoulos, K., Silveti-Falls, A., and Cevher, V. Generalized gradient norm clipping & non-euclidean (l\_0, l\_1) -smoothness. Advances in Neural Information Processing Systems, 38: 0 21170--21208, 2026
2026
-
[38]
Platonov, O., Kuznedelev, D., Diskin, M., Babenko, A., and Prokhorenkova, L. A critical look at the evaluation of gnns under heterophily: Are we really making progress? arXiv preprint arXiv:2302.11640, 2023
-
[39]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21 0 (140): 0 1--67, 2020
2020
-
[40]
On the Convergence of Adam and Beyond
Reddi, S. J., Kale, S., and Kumar, S. On the convergence of adam and beyond. arXiv preprint arXiv:1904.09237, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[41]
Riabinin, A., Shulgin, E., Gruntkowska, K., and Richt \'a rik, P. Gluon: Making muon & scion great again! (bridging theory and practice of lmo-based optimizers for llms). arXiv preprint arXiv:2505.13416, 2025. URL https://arxiv.org/abs/2505.13416
-
[42]
and Monro, S
Robbins, H. and Monro, S. A stochastic approximation method. The annals of mathematical statistics, pp.\ 400--407, 1951
1951
-
[43]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Sagun, L., Evci, U., Guney, V. U., Dauphin, Y., and Bottou, L. Empirical analysis of the hessian of over-parametrized neural networks. arXiv preprint arXiv:1706.04454, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
Benchmarking optimizers for large language model pretraining
Semenov, A., Pagliardini, M., and Jaggi, M. Benchmarking optimizers for large language model pretraining. arXiv preprint arXiv:2509.01440, 2025
-
[45]
Masked label prediction: Unified message passing model for semi-supervised classification
Shi, Y., Huang, Z., Feng, S., Zhong, H., Wang, W., and Sun, Y. Masked label prediction: Unified message passing model for semi-supervised classification. arXiv preprint arXiv:2009.03509, 2020
-
[46]
Fantastic (small) retrievers and how to train them: mxbai-edge-colbert-v0 tech report
Takehi, R., Clavi \'e , B., Lee, S., and Shakir, A. Fantastic (small) retrievers and how to train them: mxbai-edge-colbert-v0 tech report. arXiv preprint arXiv:2510.14880, 2025
-
[47]
Team, K., Bai, Y., Bao, Y., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y., Chen, Y., Chen, Y., Chen, Z., Cui, J., Ding, H., Dong, M., Du, A., Du, C., Du, D., Du, Y., Fan, Y., Feng, Y., Fu, K., Gao, B., Gao, H., Gao, P., Gao, T., Gu, X., Guan, L., Guo, H., Guo, J., Hu, H., Hao, X., He, T., He, W., He, W., Hong, C., Hu, Y., Hu, Z., Huang, W., Huang, Z., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi \`e re, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[50]
Analyzing sharpness along gd trajectory: Progressive sharpening and edge of stability
Wang, Z., Li, Z., and Li, J. Analyzing sharpness along gd trajectory: Progressive sharpening and edge of stability. Advances in Neural Information Processing Systems, 35: 0 9983--9994, 2022
2022
-
[51]
Fantastic pretraining optimizers and where to find them
Wen, K., Hall, D., Ma, T., and Liang, P. Fantastic pretraining optimizers and where to find them. arXiv preprint arXiv:2509.02046, 2025
-
[52]
Provable benefit of sign descent: A minimal model under heavy-tailed class imbalance
Yadav, R., Xie, S., Wang, T., and Li, Z. Provable benefit of sign descent: A minimal model under heavy-tailed class imbalance. arXiv preprint arXiv:2512.00763, 2025
-
[53]
A Unified Analysis of Stochastic Momentum Methods for Deep Learning
Yan, Y., Yang, T., Li, Z., Lin, Q., and Yang, Y. A unified analysis of stochastic momentum methods for deep learning. arXiv preprint arXiv:1808.10396, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[54]
A decreasing scaling transition scheme from adam to sgd
Zeng, K., Liu, J., Jiang, Z., and Xu, D. A decreasing scaling transition scheme from adam to sgd. Advanced Theory and Simulations, 5 0 (7): 0 2100599, 2022
2022
-
[55]
P., Veit, A., Kim, S., Reddi, S., Kumar, S., and Sra, S
Zhang, J., Karimireddy, S. P., Veit, A., Kim, S., Reddi, S., Kumar, S., and Sra, S. Why are adaptive methods good for attention models? Advances in Neural Information Processing Systems, 33: 0 15383--15393, 2020
2020
-
[56]
Frugal: Memory-efficient optimization by reducing state overhead for scalable training
Zmushko, P., Beznosikov, A., Tak \'a c , M., and Horv \'a th, S. Frugal: Memory-efficient optimization by reducing state overhead for scalable training. arXiv preprint arXiv:2411.07837, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.