Functional Attention: From Pairwise Affinities to Functional Correspondences
Pith reviewed 2026-06-28 23:15 UTC · model grok-4.3
The pith
Functional Attention reinterprets attention as structured linear operators between adaptive bases to enable resolution-invariant operator learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Functional Attention reinterprets attention as a functional correspondence between adaptive bases. Inspired by geometric functional maps, the method replaces softmax affinities with structured linear operators, yielding a compact, generalizable, resolution-invariant representation that explicitly captures global dependencies.
What carries the argument
Functional Attention, the replacement of token-wise softmax affinities by structured linear operators that compute functional correspondences between adaptive bases.
If this is right
- The method matches state-of-the-art performance on PDE solving, 3D segmentation, and regression tasks.
- Performance remains stable under changes in input discretization.
- The learned representation is compact and explicitly encodes global functional dependencies rather than local token affinities.
- The approach applies across multiple operator-learning domains without requiring task-specific redesign.
Where Pith is reading between the lines
- Models trained at one resolution could be evaluated directly at another without fine-tuning or architectural changes.
- The explicit use of adaptive bases opens a route to hybrid methods that inject classical functional-analysis constraints into learned operators.
- The same linear-operator view might be inserted into other attention-based architectures that currently process continuous data as fixed tokens.
Load-bearing premise
That structured linear operators between adaptive bases can replace softmax affinities while preserving performance and delivering resolution invariance plus explicit global dependency capture.
What would settle it
A controlled experiment on a PDE operator-learning benchmark where Functional Attention either underperforms current transformer baselines or shows clear accuracy drop when the input discretization is changed after training.
Figures

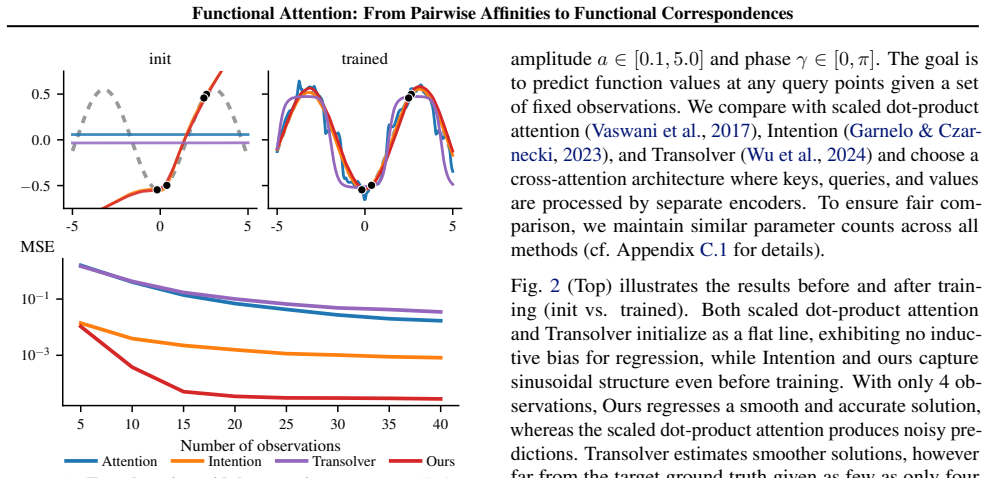






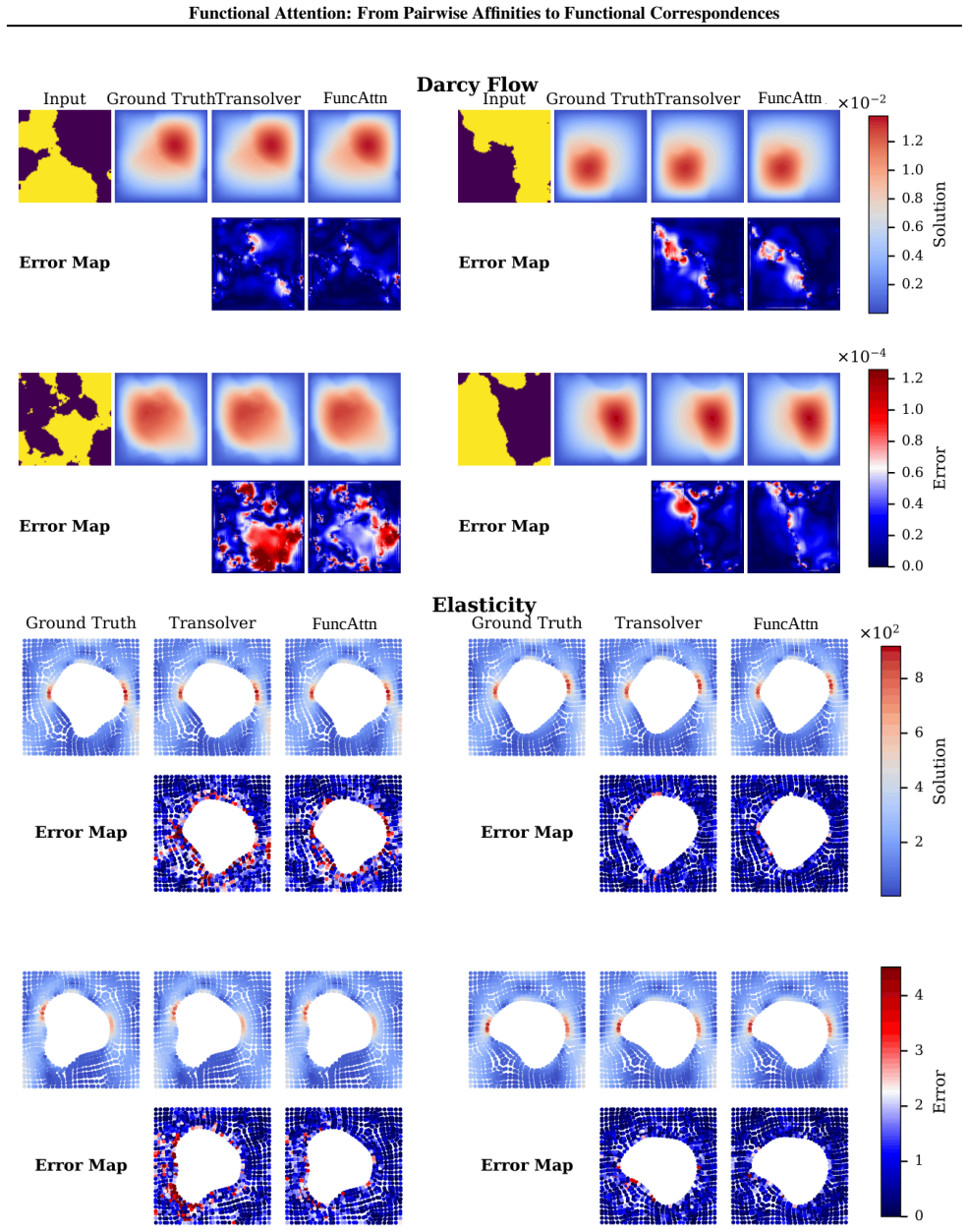



read the original abstract
Learning mappings between infinite-dimensional function spaces, or operator learning, is essential for many machine learning applications. Although transformer-based operators are popular, they often rely on token-wise attention. These methods treat continuous fields as discrete tokens and usually ignore the global functional structure. We introduce \emph{Functional Attention}, which reinterprets attention as a functional correspondence between adaptive bases. Inspired by geometric functional maps, our method replaces softmax affinities with structured linear operators. This yields a compact, generalizable, resolution-invariant representation that explicitly captures global dependencies. Experiments demonstrate that \emph{Functional Attention} can match state-of-the-art performance in many operator learning tasks, including solving PDEs, 3D segmentation, and regression, while remaining robust to varying discretizations. Project page is available at https://github.com/xjffff/FUNCATTN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Functional Attention for operator learning between infinite-dimensional function spaces. It reinterprets standard token-wise attention as a functional correspondence between adaptive bases, replacing softmax affinities with structured linear operators inspired by geometric functional maps. This is claimed to produce a compact, generalizable, resolution-invariant representation that explicitly captures global dependencies. The abstract states that experiments show the method matches state-of-the-art performance on PDE solving, 3D segmentation, and regression tasks while remaining robust to varying discretizations.
Significance. If the method delivers resolution invariance and global dependency capture while matching SOTA without hidden parameter costs, it could meaningfully advance attention-based operator learning by grounding it in functional analysis and geometric correspondences. The explicit avoidance of discrete tokenization is a potentially valuable direction for continuous fields.
major comments (1)
- [Abstract] Abstract: the assertion that 'Experiments demonstrate that Functional Attention can match state-of-the-art performance in many operator learning tasks...' supplies no methods, metrics, baselines, error bars, datasets, or implementation details, so the central experimental claim cannot be evaluated from the manuscript text.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments demonstrate that Functional Attention can match state-of-the-art performance in many operator learning tasks...' supplies no methods, metrics, baselines, error bars, datasets, or implementation details, so the central experimental claim cannot be evaluated from the manuscript text.
Authors: We thank the referee for noting this. The abstract is intentionally concise and serves only as a high-level overview; it is not the appropriate location for full experimental protocols, which would exceed typical length limits. The manuscript provides complete details on the experimental setup, including methods, metrics, baselines, error bars, datasets, and implementation, in Section 4 (Experiments) along with the appendix. The abstract claim is therefore grounded in those results. We do not view this as requiring a change to the abstract itself. revision: no
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description introduce Functional Attention as a reinterpretation of attention inspired by external geometric functional maps, replacing softmax with structured linear operators between adaptive bases. No equations, derivations, or self-citations are shown that reduce any central claim to fitted inputs or prior self-referential definitions by construction. The experimental claims are presented as validation rather than tautological predictions. This matches the default expectation of a self-contained method description without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structured linear operators between adaptive bases can replace softmax affinities while capturing global functional dependencies and enabling resolution invariance.
Reference graph
Works this paper leans on
-
[1]
Point Convolutional Neural Networks by Extension Operators
Atzmon, M., Maron, H., and Lipman, Y . Point convolutional neural networks by extension operators.arXiv preprint arXiv:1803.10091,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, H., Liu, Z., Wang, X., Tian, Y ., and Wang, Y . Di- jiang: Efficient large language models through compact kernelization.arXiv preprint arXiv:2403.19928,
-
[3]
Rethinking Attention with Performers
Choromanski, K., Likhosherstov, V ., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J., Mohiuddin, A., Kaiser, L., et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, pp. 4171–4186,
2019
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
On the Properties of the Softmax Function with Application in Game Theory and Reinforcement Learning
Gao, B. and Pavel, L. On the properties of the softmax func- tion with application in game theory and reinforcement learning.arXiv preprint arXiv:1704.00805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
and Ji, S
Gao, H. and Ji, S. Graph U-Nets. InInternational Con- ference on Machine Learning, pp. 2083–2092. PMLR,
2083
-
[8]
Garnelo, M. and Czarnecki, W. M. Exploring the space of key-value-query models with intention.arXiv preprint arXiv:2305.10203,
-
[9]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhat- tacharya, K., Stuart, A., and Anandkumar, A. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[10]
Z., Liu, B., and Anandkumar, A
Li, Z., Huang, D. Z., Liu, B., and Anandkumar, A. Fourier neural operator with learned deformations for PDEs on general geometries.Journal of Machine Learning Re- search, 24(388):1–26, 2023a. Li, Z., Kovachki, N., Choy, C., Li, B., Kossaifi, J., Otta, S., Nabian, M. A., Stadler, M., Hundt, C., Azizzade- nesheli, K., et al. Geometry-informed neural operato...
-
[11]
Transolver++: An accurate neural solver for PDEs on million-scale geome- tries
Luo, H., Wu, H., Zhou, H., Xing, L., Di, Y ., Wang, J., and Long, M. Transolver++: An accurate neural solver for PDEs on million-scale geometries.arXiv preprint arXiv:2502.02414,
-
[12]
11 Functional Attention: From Pairwise Affinities to Functional Correspondences Tripura, T. and Chakraborty, S. Wavelet neural operator: a neural operator for parametric partial differential equa- tions.arXiv preprint arXiv:2205.02191,
-
[13]
Linformer: Self-Attention with Linear Complexity
Wang, S., Li, B. Z., Khabsa, M., Fang, H., and Ma, H. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[14]
Transolver: A Fast Transformer Solver for PDEs on General Geometries
Wu, H., Luo, H., Wang, H., Wang, J., and Long, M. Tran- solver: A fast transformer solver for PDEs on general geometries.arXiv preprint arXiv:2402.02366,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
S., Abillama, P., Lee, C., and Balzano, L
Yaras, C., Xu, A. S., Abillama, P., Lee, C., and Balzano, L. Monarchattention: Zero-shot conversion to fast, hardware-aware structured attention.arXiv preprint arXiv:2505.18698,
-
[16]
Zhang, M., Bhatia, K., Kumbong, H., and R ´e, C. The hedgehog & the porcupine: Expressive linear attentions with softmax mimicry.arXiv preprint arXiv:2402.04347,
-
[17]
(2024)).Suppose thatΩis a countable domain, the reduced domainΩ spec is isomorphic toΩ
Lemma A.1(Wu et al. (2024)).Suppose thatΩis a countable domain, the reduced domainΩ spec is isomorphic toΩ. Lemma A.2.The operator QK⊤(KK⊤ +λI n)−1 V can be interpreted as a Monte-Carlo discretization of a regularized integral operator. Proof. Given input function u: Ω→R C, define the key Gram kernel h(ξ, ξ′) :=k(ξ) ⊤k(ξ′) where k(ξ) =W ku(ξ), and the ass...
2024
-
[18]
was proposed as an attention mechanism capable of representing regularized least squares fitting. Given queries Q∈R n×d, keys K∈R n×d, and values V∈R n×d, Intention computes: Intention(Q,K,V) =Q(K ⊤K+λI d)−1K⊤V(46) Functional Attention Recovers IntentionWe now show that Intention is a special case of Functional Attention when we choose anyorthonormal basi...
1997
-
[19]
The amplitude α and phase γ are sampled uniformly from [0.1,5] and [0, π], respectively
where each task corresponds to a sinusoidal function f(x) =αsin(x−γ) defined on x∈[−6,6] . The amplitude α and phase γ are sampled uniformly from [0.1,5] and [0, π], respectively. For each task, we observe a support set of K randomly sampled input-output pairs. The goal is to learn a predictor that generalizes to arbitrary query locations given only the s...
2023
-
[20]
PDE Benchmarks We benchmark our methods on eight popular PDEs benchmarks across diverse geometries and physical scenarios: Table 9.Summary of benchmark datasets
– – – Heads 4 8 8 8 Learning Rate 10−3 10−4 3×10 −4 10−4 C.2. PDE Benchmarks We benchmark our methods on eight popular PDEs benchmarks across diverse geometries and physical scenarios: Table 9.Summary of benchmark datasets. Benchmark Input Spatial Resolution Input length Output Train/Test Elasticity Domain geometry Point cloud 972 Displacementu1000/200 Ai...
2021
-
[21]
The dataset features airfoils from the NACA 4- and 5-digit series, with each case discretized into approximately 32,000 mesh points
contains high-fidelity simulation data for Reynolds-Averaged Navier-Stokes (RANS) equations, designed to assist airfoil design. The dataset features airfoils from the NACA 4- and 5-digit series, with each case discretized into approximately 32,000 mesh points. The simulation records air velocity, pressure, and viscosity in the surrounding space, as well a...
2024
-
[22]
Training details.We use a consistent architecture across all benchmarks with 8 transformer layers and 8 attention heads to match previous work
between predicted and ground truth coefficients across test samples, which measures how well the model preserves the ranking of designs—a key property for engineering optimization. Training details.We use a consistent architecture across all benchmarks with 8 transformer layers and 8 attention heads to match previous work. The hidden channel dimension is ...
2023
-
[23]
Lg denotes spatial gradient regularization (Xiao et al., 2024)
without extra tuning. Lg denotes spatial gradient regularization (Xiao et al., 2024). Lv and Ls denote volume and surface losses respectively. Training Configuration Model Configuration Benchmark Loss Epochs LR Optim Batch Layers Heads Channels Modes Elasticity Rel.L 2 500 10−3 AdamW 1 8 8 128 64 Plasticity 8 8 8 128 64 Airfoil 4 8 8 128 64 Pipe 4 8 8 128...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.