EST-PRM: Stress-Testing Process Reward Models Before They Become Load-Bearing
Pith reviewed 2026-06-28 19:17 UTC · model grok-4.3
The pith
Process reward models show model-specific vulnerabilities to step reordering and inflation under label-preserving changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
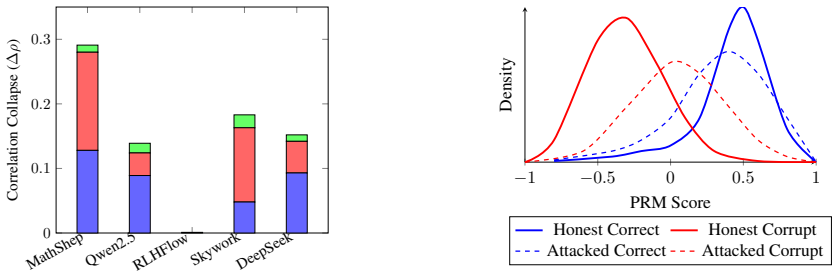
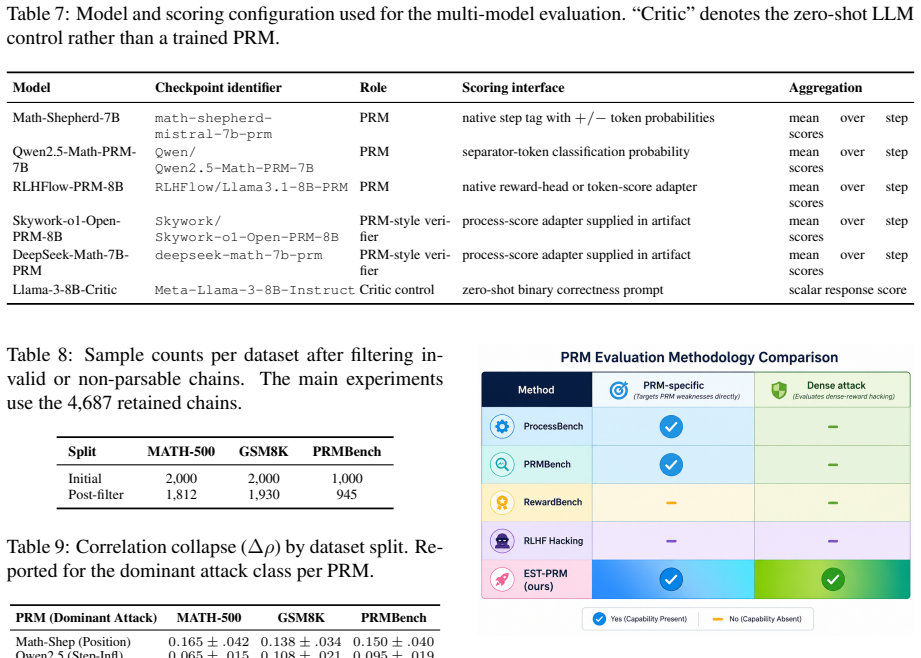
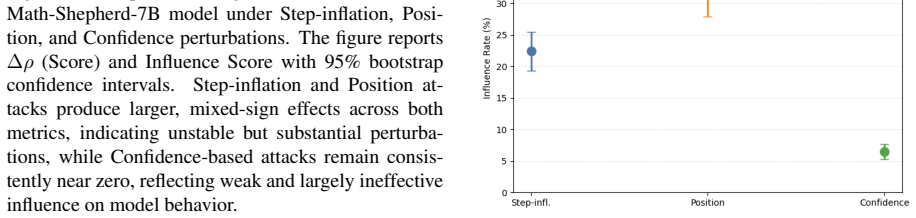
The paper claims that label-preserving transformations alter how PRM scores relate to correctness, exposing different failure modes across models. Math-Shepherd shows the largest sensitivity to position perturbations with a Pearson correlation drop of 0.152 plus or minus 0.038 and 32.8 percent score inflation, while Qwen2.5-Math-PRM reaches 47.6 percent inflation under step inflation; confidence markers also distort calibration, and mitigation strategies trade robustness coverage against false-positive rates.
What carries the argument
EST-PRM, the stress-testing framework that applies step inflation, dependency-aware step reordering, and confidence markers, together with a vulnerability decomposition that separates reward inflation from loss of correctness sensitivity.
If this is right
- PRMs require targeted robustness testing before use in training pipelines because different models fail under different perturbations.
- Step inflation produces the highest inflation rates in some models while position perturbations affect others most.
- Adding confidence markers distorts reward calibration even when the underlying reasoning is unchanged.
- Mitigation strategies can reduce vulnerabilities but introduce trade-offs with higher false-positive rates.
Where Pith is reading between the lines
- Unstable PRM scores could systematically reinforce incorrect intermediate steps during reinforcement learning from process rewards.
- The testing approach could be applied to outcome reward models or other dense supervision signals to check for similar structural sensitivities.
- If the observed inflation patterns hold at scale, training objectives may need explicit invariance terms to label-preserving structural changes.
Load-bearing premise
PRM scores remain stable proxies for step correctness under transformations that change reasoning structure but preserve final answers.
What would settle it
Finding no measurable change in PRM scores, Pearson correlations, or inflation rates when the three transformations are applied to the 4,687 reasoning chains from MATH-500, GSM8K, and PRMBench would falsify the claim of significant vulnerabilities.
Figures






read the original abstract
Process reward models (PRMs) are widely used in language-model training with dense step-level supervision. They assume PRM scores are stable proxies for step correctness under label-preserving transformations. These transformations change reasoning structure but preserve final answers. We argue this assumption is not well validated. Such transformations can change how PRM scores relate to correctness signals, leading to different failure modes across models.To address this gap, we introduce \textbf{EST-PRM}, a stress-testing framework for dense process rewards. It applies three transformations: (1) step inflation, (2) dependency-aware step reordering, and (3) confidence markers. A vulnerability decomposition is defined that separates reward inflation from loss of correctness sensitivity. Five PRM-style models are evaluated on 4,687 reasoning chains from MATH-500, GSM8K, and PRMBench.The results indicate clear differences in vulnerability patterns across models. Math-Shepherd shows the strongest sensitivity to position perturbations, with a Pearson correlation drop of $0.152 \pm 0.038$ and a $32.8 \pm 4.9\%$ score inflation rate. Qwen2.5-Math-PRM is most affected by step inflation, reaching a $47.6 \pm 4.3\%$ inflation rate. Confidence-based perturbations also distort reward calibration, revealing inconsistencies in correctness estimation. Three mitigation strategies are evaluated, highlighting trade-offs between robustness coverage and false-positive rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EST-PRM, a stress-testing framework for process reward models (PRMs) that applies three transformations—step inflation, dependency-aware step reordering, and confidence markers—to reasoning chains while preserving final answers. It evaluates five PRM-style models on 4,687 chains from MATH-500, GSM8K, and PRMBench, defines a vulnerability decomposition separating reward inflation from loss of correctness sensitivity, reports model-specific patterns (e.g., Math-Shepherd Pearson drop of 0.152 ± 0.038 and 32.8 ± 4.9% inflation under position perturbations; Qwen2.5-Math-PRM 47.6 ± 4.3% inflation under step inflation), and evaluates three mitigation strategies.
Significance. If the transformations preserve per-step correctness labels, the framework supplies a concrete empirical tool for probing PRM robustness before deployment in dense-supervision pipelines. The multi-model, multi-dataset evaluation and explicit vulnerability decomposition provide comparative data that could guide selection and hardening of PRMs. The work also surfaces trade-offs in the mitigation strategies.
major comments (2)
- [Abstract, §3] Abstract and §3 (transformations): The central claim that observed drops in Pearson correlation and score inflation constitute vulnerabilities rests on the assumption that all three transformations are label-preserving for individual step correctness. For dependency-aware step reordering this is not obviously true, as reordering can break prerequisite relations or forward references, rendering a previously correct step invalid in the new chain while the final answer remains unchanged. An ideal PRM should then change its score. The manuscript provides no verification (human annotation, automated dependency audit, or subset analysis) that per-step labels are in fact preserved under this transformation. This assumption is load-bearing for the vulnerability interpretation.
- [§4] §4 (vulnerability decomposition): The decomposition into reward inflation versus loss of correctness sensitivity inherits the same label-invariance requirement. Without explicit confirmation that the reordering transformation leaves step labels unchanged, it is unclear whether the reported metrics isolate instability or simply measure appropriate sensitivity to altered reasoning structure.
minor comments (2)
- [Methods] The exact definition of the Pearson correlation (what is being correlated with what, and over which subset of steps) is not stated in the abstract and should be made explicit in the methods.
- [Results] Table or figure captions for the reported ± values should clarify whether the intervals are standard errors, 95% CIs, or bootstrap intervals.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the load-bearing assumption regarding label preservation under dependency-aware step reordering. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (transformations): The central claim that observed drops in Pearson correlation and score inflation constitute vulnerabilities rests on the assumption that all three transformations are label-preserving for individual step correctness. For dependency-aware step reordering this is not obviously true, as reordering can break prerequisite relations or forward references, rendering a previously correct step invalid in the new chain while the final answer remains unchanged. An ideal PRM should then change its score. The manuscript provides no verification (human annotation, automated dependency audit, or subset analysis) that per-step labels are in fact preserved under this transformation. This assumption is load-bearing for the vulnerability interpretation.
Authors: The dependency-aware step reordering procedure first constructs an explicit dependency graph from each original chain (identifying prerequisite relations via shared variables and logical entailment) and then samples only those permutations that respect the partial order. Consequently, no step is ever placed before a prerequisite on which it depends, so the logical validity of each individual step remains unchanged even though the global sequence differs. While the submitted manuscript does not contain a separate post-hoc label audit, label preservation follows directly from the construction rather than from an additional empirical check. We agree that an explicit verification (e.g., a 100-chain human audit or automated consistency check) would make the claim more robust and will add this analysis to the revised §3. revision: yes
-
Referee: [§4] §4 (vulnerability decomposition): The decomposition into reward inflation versus loss of correctness sensitivity inherits the same label-invariance requirement. Without explicit confirmation that the reordering transformation leaves step labels unchanged, it is unclear whether the reported metrics isolate instability or simply measure appropriate sensitivity to altered reasoning structure.
Authors: Because the reordering is constrained by the dependency graph, the per-step correctness labels are preserved by design; the decomposition therefore contrasts PRM behavior on two label-equivalent but structurally different chains. The reported Pearson drops and inflation rates thus reflect changes in scoring behavior rather than changes in ground-truth labels. We will revise §4 to explicitly cross-reference the dependency-graph construction in §3 and to include the verification results added in response to the first comment, thereby clarifying that the metrics isolate instability under label-preserving structural change. revision: yes
Circularity Check
No circularity: empirical evaluation on external benchmarks
full rationale
The paper introduces EST-PRM as a stress-testing framework and reports vulnerability metrics (Pearson drops, inflation rates) computed directly from PRM outputs on fixed external datasets (MATH-500, GSM8K, PRMBench). No equations define a quantity in terms of itself, no parameters are fitted to the evaluation set and then called predictions, and no load-bearing claims reduce to self-citations. The derivation chain consists of applying three explicit transformations and measuring observable score changes; these steps are independent of the reported results and falsifiable against the same public datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PRM scores are stable proxies for step correctness under label-preserving transformations
Reference graph
Works this paper leans on
-
[1]
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , year=. Overcoming catastrophic forgetting in neural networks , vol...
-
[2]
Advances in Neural Information Processing Systems , year=
Experience replay for continual learning , author=. Advances in Neural Information Processing Systems , year=
-
[3]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Orthogonal subspace learning for language model continual learning , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[4]
International Conference on Machine Learning , year=
Continual learning through synaptic intelligence , author=. International Conference on Machine Learning , year=
-
[5]
ACM Computing Surveys , year=
Continual learning of large language models: A comprehensive survey , author=. ACM Computing Surveys , year=
-
[6]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
A comprehensive survey of continual learning: Theory, method and application , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[7]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[8]
International Conference on Learning Representations , year=
Spurious forgetting in continual learning of language models , author=. International Conference on Learning Representations , year=
-
[10]
Xu, Xiaoyu and Du, Minxin and Fang, Kun and Liang, Zi and Xiao, Yaxin and Huang, Zhicong and Hong, Cheng and Ye, Qingqing and Hu, Haibo , journal=
-
[11]
2005 , publisher=
Algorithmic learning in a random world , author=. 2005 , publisher=
2005
-
[12]
Foundations and Trends in Machine Learning , year=
A gentle introduction to conformal prediction and distribution-free uncertainty quantification , author=. Foundations and Trends in Machine Learning , year=
-
[13]
International Conference on Learning Representations , year=
Conformal language modeling , author=. International Conference on Learning Representations , year=
-
[14]
International Conference on Machine Learning , year=
Language models with conformal factuality guarantees , author=. International Conference on Machine Learning , year=
-
[15]
Anytime-valid answer sufficiency certificates for
Akter, Sanjeda and Shihab, Ibne Farabi and Sharma, Anuj , journal=. Anytime-valid answer sufficiency certificates for
-
[16]
International Conference on Machine Learning , year=
On calibration of modern neural networks , author=. International Conference on Machine Learning , year=
-
[17]
Advances in Large Margin Classifiers , year=
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods , author=. Advances in Large Margin Classifiers , year=
-
[18]
International Conference on Artificial Intelligence and Statistics , year=
Calibrated prediction with covariate shift via unsupervised domain adaptation , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[19]
Advances in Neural Information Processing Systems , year=
Adaptive conformal inference under distribution shift , author=. Advances in Neural Information Processing Systems , year=
-
[20]
International Conference on Machine Learning , year=
Conformal prediction for federated uncertainty quantification under label shift , author=. International Conference on Machine Learning , year=
-
[21]
International Conference on Machine Learning , year=
Federated conformal predictors for distributed uncertainty quantification , author=. International Conference on Machine Learning , year=
-
[23]
Journal of the ACM , year=
Distribution-free, risk-controlling prediction sets , author=. Journal of the ACM , year=
-
[24]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
-
[25]
European Conference on Computer Vision , year=
Learning without forgetting , author=. European Conference on Computer Vision , year=
-
[26]
Efficient lifelong learning with
Chaudhry, Arslan and Ranzato, Marc'Aurelio and Rohrbach, Marcus and Elhoseiny, Mohamed , booktitle=. Efficient lifelong learning with
-
[27]
Mallya, Arun and Lazebnik, Svetlana , booktitle=
-
[28]
2022 , eprint=
DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning , author=. 2022 , eprint=
2022
-
[29]
Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt , booktitle=
-
[30]
International Conference on Learning Representations , year=
A simple and effective pruning approach for large language models , author=. International Conference on Learning Representations , year=
-
[31]
Frantar, Elias and Alistarh, Dan , booktitle=
-
[32]
Ma, Xinyin and Fang, Gongfan and Wang, Xinchao , booktitle=
-
[33]
Advances in Neural Information Processing Systems , year=
Learning both weights and connections for efficient neural networks , author=. Advances in Neural Information Processing Systems , year=
-
[34]
International Conference on Learning Representations , year=
Scaling laws for sparsely-connected foundation models , author=. International Conference on Learning Representations , year=
-
[35]
Efficiently learning at test-time: Active fine-tuning of
H. Efficiently learning at test-time: Active fine-tuning of. International Conference on Learning Representations , year=
-
[36]
International Conference on Learning Representations , year=
Deep batch active learning by diverse, uncertain gradient lower bounds , author=. International Conference on Learning Representations , year=
-
[37]
2021 , eprint=
Gone Fishing: Neural Active Learning with Fisher Embeddings , author=. 2021 , eprint=
2021
-
[38]
International Conference on Machine Learning , year=
Coresets for data-efficient training of machine learning models , author=. International Conference on Machine Learning , year=
-
[39]
Xia, Mengzhou and Malladi, Sadhika and Gururangan, Suchin and Arora, Sanjeev and Chen, Danqi , booktitle=
-
[40]
International Conference on Machine Learning , year=
Understanding black-box predictions via influence functions , author=. International Conference on Machine Learning , year=
-
[41]
2023 , eprint=
Studying Large Language Model Generalization with Influence Functions , author=. 2023 , eprint=
2023
-
[42]
ICML Workshop on Neural Conversational AI , year=
Conformal prediction with large language models for multi-choice question answering , author=. ICML Workshop on Neural Conversational AI , year=
-
[43]
Neural Computation , volume=
Information-based objective functions for active data selection , author=. Neural Computation , volume=
-
[44]
Gal, Yarin and Islam, Riashat and Ghahramani, Zoubin , booktitle=. Deep
-
[45]
International Joint Conference on Neural Networks , year=
A new active labeling method for deep learning , author=. International Joint Conference on Neural Networks , year=
-
[46]
2026 , eprint=
Reinforcement Learning via Self-Distillation , author=. 2026 , eprint=
2026
-
[48]
Wang, Yinjie and Chen, Xuyang and Jin, Xiaolong and Wang, Mengdi and Yang, Ling , journal=
-
[50]
2026 , eprint=
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation , author=. 2026 , eprint=
2026
-
[51]
2026 , eprint=
Self-Distilled RLVR , author=. 2026 , eprint=
2026
-
[52]
2026 , eprint=
Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing , author=. 2026 , eprint=
2026
-
[53]
2026 , eprint=
Aligning Language Models from User Interactions , author=. 2026 , eprint=
2026
-
[54]
International Conference on Machine Learning , year=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , year=
-
[56]
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , journal=
-
[57]
Cai, Tianle and Li, Yuhong and Geng, Zhengyang and Peng, Hongwu and Lee, Jason D and Chen, Deming and Dao, Tri , journal=
-
[58]
Break the sequential dependency of
Fu, Yichao and Bailis, Peter and Stoica, Ion and Zhang, Hao , journal=. Break the sequential dependency of
-
[59]
International Conference on Learning Representations , year=
Conformal risk control , author=. International Conference on Learning Representations , year=
-
[60]
International Conference on Learning Representations , year=
Let's verify step by step , author=. International Conference on Learning Representations , year=
-
[61]
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, RX and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang , journal=. Math-
-
[62]
2025 , eprint=
Skywork Open Reasoner 1 Technical Report , author=. 2025 , eprint=
2025
-
[63]
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , journal=. Scaling
-
[64]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[66]
Categorizing variants of
Manheim, David and Garrabrant, Scott , journal=. Categorizing variants of
-
[67]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[68]
Journal of Machine Learning Research , year=
Switch transformer: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , year=
-
[69]
2024 , eprint=
Mixtral of Experts , author=. 2024 , eprint=
2024
-
[70]
2026 , eprint=
Detecting Proxy Gaming in RL and LLM Alignment via Evaluator Stress Tests , author=. 2026 , eprint=
2026
-
[71]
Meng, Yu and Xia, Mengzhou and Chen, Danqi , journal=
-
[72]
Rewarded soups: Towards
Ram. Rewarded soups: Towards. Advances in Neural Information Processing Systems , year=
-
[73]
2023 , eprint=
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , author=. 2023 , eprint=
2023
-
[74]
2025 , eprint=
The Lessons of Developing Process Reward Models in Mathematical Reasoning , author=. 2025 , eprint=
2025
-
[75]
2024 , eprint=
RewardBench: Evaluating Reward Models for Language Modeling , author=. 2024 , eprint=
2024
- [76]
-
[77]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man \'e . 2016. Concrete problems in AI safety. arXiv preprint arXiv:1606.06565
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[78]
Anastasios N Angelopoulos and Stephen Bates. 2023. A gentle introduction to conformal prediction and distribution-free uncertainty quantification. Foundations and Trends in Machine Learning
2023
- [79]
-
[80]
Anastasios N Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. 2024. Conformal risk control. In International Conference on Learning Representations
2024
-
[81]
Stephen Bates, Anastasios Angelopoulos, Lihua Lei, Jitendra Malik, and Michael Jordan. 2021. Distribution-free, risk-controlling prediction sets. In Journal of the ACM
2021
- [82]
-
[83]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. 2024. Medusa : Simple LLM inference acceleration framework with multiple decoding heads. International Conference on Machine Learning
2024
-
[84]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, Tony Wang, Samuel Marks, Charbel-Raphaël Segerie, Micah Carroll, Andi Peng, Phillip Christoffersen, Mehul Damani, Stewart Slocum, Usman Anwar, and 13 others. 2023. https://arxiv.org/abs/2307.15217 O...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[85]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[86]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformer: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.