Online Sparse Regression with Expanding Observables
Pith reviewed 2026-06-28 18:28 UTC · model grok-4.3
The pith
RAVAS recovers sparse models online even when important predictors appear only after many observations have arrived.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RAVAS employs a recurrent procedure that dynamically updates feature selection as both the sample size and the observable feature set grow, relying only on low-dimensional sufficient statistics that are updated online, thereby detecting and incorporating important variables that emerge later while providing guarantees on model selection, estimation error, and feature coverage.
What carries the argument
Recurrent Adaptive Variable Selection (RAVAS), a recurrent update procedure on low-dimensional sufficient statistics that adapts the selected model as new features become observable.
If this is right
- Model selection consistency continues to hold when important features enter the observable set at arbitrary later times.
- Estimation error remains bounded as the dimension of observable features increases with the sample stream.
- Full coverage of important features is achieved without requiring all candidates to be present from the initial observations.
- Adaptive online tuning selects parameters on the fly without needing a separate offline calibration phase.
Where Pith is reading between the lines
- The same recurrent structure could be adapted to online classification or density estimation tasks where feature availability also expands over time.
- Data collection protocols could begin with a minimal initial feature set and add variables later without invalidating prior analysis.
- The reliance on sufficient statistics suggests the method remains memory-efficient even when the total possible feature pool is extremely large.
Load-bearing premise
The recurrent update rule can correctly recover the importance of a variable that first appears after many samples have already been seen, without systematic bias from the early period of missingness.
What would settle it
A simulation study in which an important variable first becomes observable after half the total samples have arrived, yet RAVAS fails to include it in the final selected model with probability bounded away from zero.
Figures

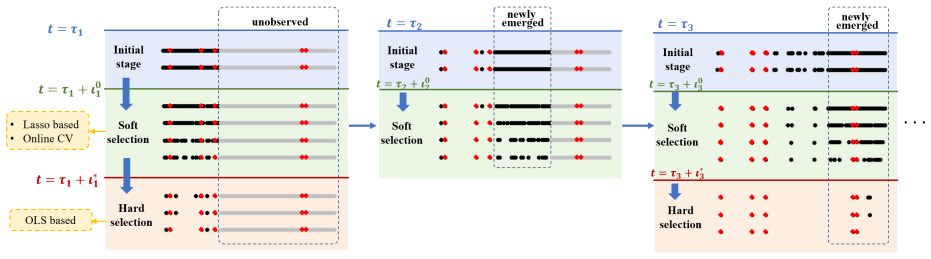
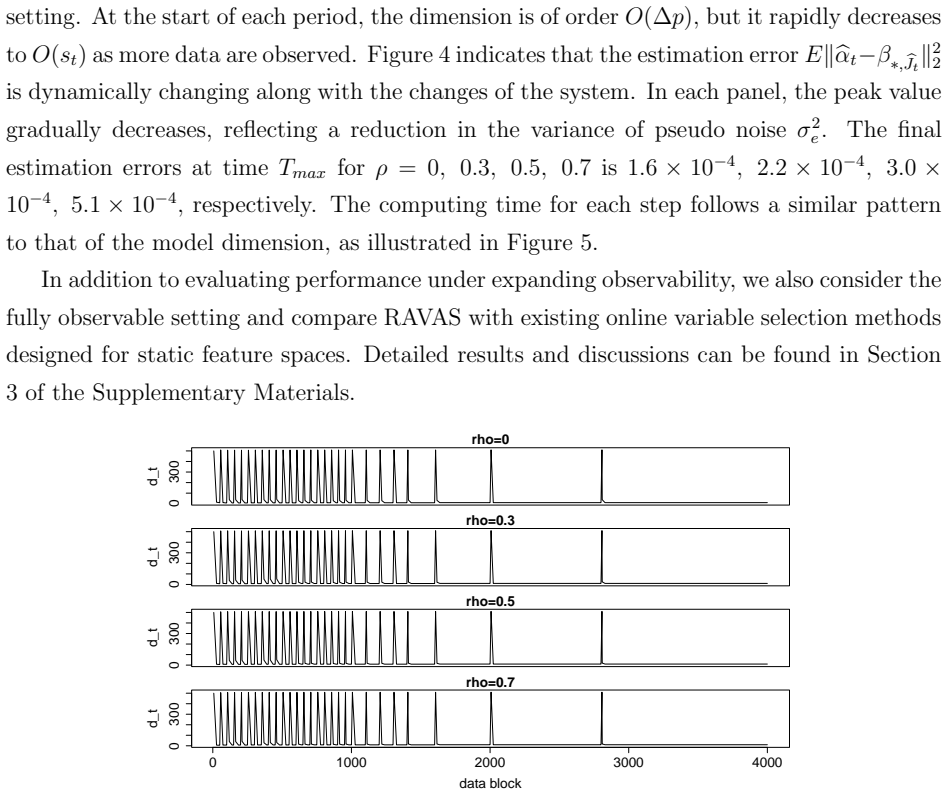
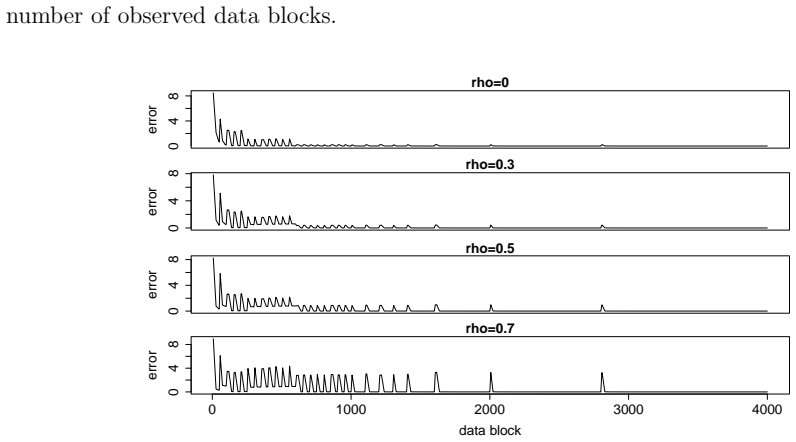


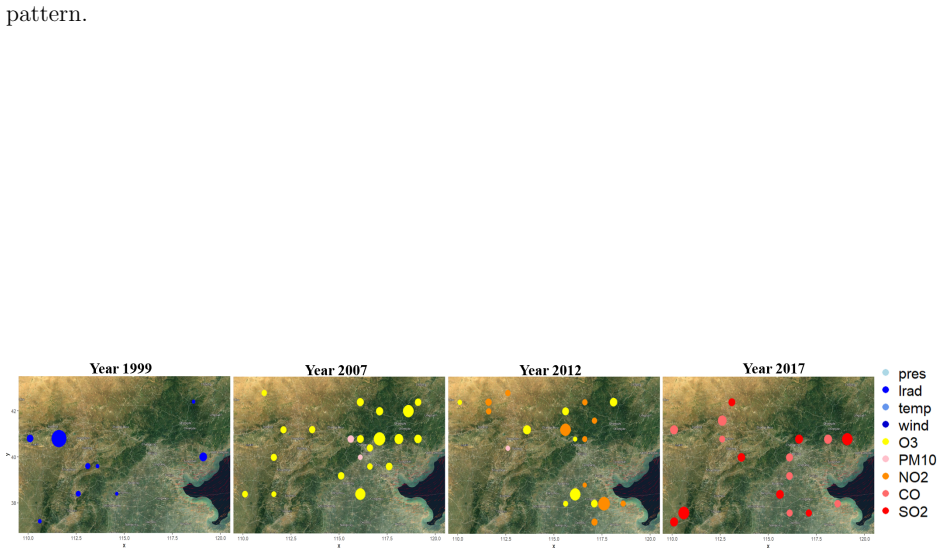
read the original abstract
Online high-dimensional regression has gained increasing attention in recent years, yet existing methods typically assume that all candidate features, including important ones, are observed from the outset of data collection. This assumption is often violated in real-world scenarios, where new variables become available gradually as data accumulate. To address this gap, we introduce a novel framework, Recurrent Adaptive Variable Selection (RAVAS), for online regression with expanding observability. RAVAS employs a recurrent procedure that dynamically updates feature selection as both the sample size and the observable feature set grow. The algorithm is designed to be computationally efficient and memory-light, relying only on low-dimensional sufficient statistics that are updated online. A key advantage of the method lies in its ability to detect and incorporate important variables that emerge later, thereby mitigating the effect of early-stage missingness. We establish theoretical guarantees on model selection, estimation error, and feature coverage, and develop an adaptive online tuning strategy. Extensive simulations and real-world experiments verify the effectiveness of RAVAS for high-dimensional streaming data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Recurrent Adaptive Variable Selection (RAVAS) for online high-dimensional sparse regression under expanding observability, where the set of available features grows over time. The method maintains low-dimensional sufficient statistics updated recurrently, claims to mitigate early-stage missingness for late-appearing important covariates, establishes theoretical guarantees on model selection consistency, estimation error bounds, and feature coverage, develops an adaptive online tuning strategy, and validates performance via simulations and real-data experiments.
Significance. If the feature-coverage guarantees hold uniformly over arbitrary appearance times for important covariates, the work would address a practically relevant gap left by existing online regression methods that assume a fixed feature set from the outset. The memory-light, recurrent update design is a clear practical strength for streaming applications. The explicit statement of theoretical guarantees (rather than purely empirical claims) is also a positive feature of the contribution.
major comments (1)
- [Abstract / Introduction] Abstract and introduction: The central claim of feature-coverage guarantees requires that the recurrent update recovers the importance of a variable that first appears after an arbitrary number of samples without non-vanishing bias induced by the pre-appearance period of missingness. The manuscript states that the procedure “mitigates the effect of early-stage missingness” but supplies no explicit conditioning, imputation, or re-weighting rule whose error is controlled uniformly over appearance times; without such a mechanism the coverage result does not extend to the general expanding-observability regime asserted in the strongest claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. Below we respond point-by-point to the major comment.
read point-by-point responses
-
Referee: [Abstract / Introduction] Abstract and introduction: The central claim of feature-coverage guarantees requires that the recurrent update recovers the importance of a variable that first appears after an arbitrary number of samples without non-vanishing bias induced by the pre-appearance period of missingness. The manuscript states that the procedure “mitigates the effect of early-stage missingness” but supplies no explicit conditioning, imputation, or re-weighting rule whose error is controlled uniformly over appearance times; without such a mechanism the coverage result does not extend to the general expanding-observability regime asserted in the strongest claim.
Authors: The recurrent update maintains separate low-dimensional sufficient statistics for each feature, initialized and accumulated only from the time step at which the feature first becomes observable. For a covariate appearing at time t, its statistics (and subsequent selection/estimation) use exclusively the post-t observations; pre-t missingness therefore induces no bias in its coefficient or selection probability. The feature-coverage result is proved under the standard high-dimensional regime in which the post-appearance sample size n-t is large enough for the requisite concentration and irrepresentability conditions to hold; this is uniform in the sense that the rates depend only on n-t rather than on the absolute value of t. No imputation or re-weighting is employed because the expanding-observability model simply omits unobserved features from the active sufficient-statistic vector until they appear. We agree that the abstract and introduction would be strengthened by an explicit one-sentence description of this initialization rule. We will revise both sections accordingly. revision: yes
Circularity Check
No significant circularity detected in the derivation chain.
full rationale
The paper introduces RAVAS as a recurrent procedure updating low-dimensional sufficient statistics for online sparse regression under expanding observability. Theoretical guarantees on model selection, estimation error, and feature coverage are asserted without any quoted reduction of a prediction to a fitted input by construction, self-definitional loop, or load-bearing self-citation chain. The abstract and description present the method as relying on online updates that mitigate early missingness, with no evidence that core results are equivalent to inputs by definition. This is the normal case of a self-contained algorithmic proposal whose validity rests on external verification rather than internal renaming.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive tuning parameter sequence
axioms (1)
- domain assumption The underlying regression model remains sparse and the new features satisfy the same regularity conditions as the initial ones.
Reference graph
Works this paper leans on
-
[1]
Mathematics of computation , volume=
Decay rates for inverses of band matrices , author=. Mathematics of computation , volume=
-
[2]
The Annals of Statistics , volume=
Near-ideal model selection by ℓ 1 minimization , author=. The Annals of Statistics , volume=
-
[3]
Wei, J. and Li, Z. and Wang, J. and Li, C. and Gupta, P. and Cribb, M. , cstr =. High-resolution and High-quality Air Pollutants Dataset for China , year =. doi:10.5281/zenodo.4571660 , journal =
-
[4]
Hao, H. and Wang, K. and Wu, G. and Liu, J. and Li, J. , cstr =. PM2.5 concentrations based on near-surface visibility , year =. doi:10.11888/Atmos.tpdc.301127 , journal =
-
[5]
China meteorological forcing dataset (1979-2018) , year =
YANG Kun and HE Jie and TANG Wenjun and LU Hui and QIN Jun and CHEN Yingying and LI Xin , cstr =. China meteorological forcing dataset (1979-2018) , year =. doi:10.11888/AtmosphericPhysics.tpe.249369.file , journal =
work page doi:10.11888/atmosphericphysics.tpe.249369.file 1979
-
[6]
Chemical Engineering Transactions , volume=
Relationship between meteorological factors and diffusion of atmospheric pollutants , author=. Chemical Engineering Transactions , volume=
-
[7]
2009 , publisher=
High-dimensional probability , author=. 2009 , publisher=
2009
-
[8]
Neural computation , volume=
Incremental online learning in high dimensions , author=. Neural computation , volume=. 2005 , publisher=
2005
-
[9]
Knowledge-Based Systems , volume=
Online feature selection for high-dimensional class-imbalanced data , author=. Knowledge-Based Systems , volume=. 2017 , publisher=
2017
-
[10]
The VLDB journal , volume=
An effective and efficient algorithm for high-dimensional outlier detection , author=. The VLDB journal , volume=. 2005 , publisher=
2005
-
[11]
INFORMS Journal on Computing , volume=
An adaptive hyperbox algorithm for high-dimensional discrete optimization via simulation problems , author=. INFORMS Journal on Computing , volume=. 2013 , publisher=
2013
-
[12]
Journal of the Franklin Institute , volume=
Control-based algorithms for high dimensional online learning , author=. Journal of the Franklin Institute , volume=. 2020 , publisher=
2020
-
[13]
International Conference on Artificial Intelligence and Statistics , pages=
Online sparse reinforcement learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[14]
IEEE Transactions on Systems, Man, and Cybernetics: Systems , volume=
A latent factor analysis-based approach to online sparse streaming feature selection , author=. IEEE Transactions on Systems, Man, and Cybernetics: Systems , volume=. 2021 , publisher=
2021
-
[15]
, author=
Online learning for matrix factorization and sparse coding. , author=. Journal of Machine Learning Research , volume=
-
[16]
Journal of Machine Learning Research , volume=
Stabilized sparse online learning for sparse data , author=. Journal of Machine Learning Research , volume=
-
[17]
ACM Transactions on Knowledge Discovery from Data (TKDD) , volume=
A unified framework for sparse online learning , author=. ACM Transactions on Knowledge Discovery from Data (TKDD) , volume=. 2020 , publisher=
2020
-
[18]
Statistica Sinica , volume=
Variable screening with multiple studies , author=. Statistica Sinica , volume=. 2020 , publisher=
2020
-
[19]
Operations Research , volume=
Online decision making with high-dimensional covariates , author=. Operations Research , volume=. 2020 , publisher=
2020
-
[20]
Management Science , year=
Online Learning and Decision Making Under Generalized Linear Model with High-Dimensional Data , author=. Management Science , year=
-
[21]
Biometrika , volume=
On the robustness of the adaptive lasso to model misspecification , author=. Biometrika , volume=. 2012 , publisher=
2012
-
[22]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Model selection principles in misspecified models , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2014 , publisher=
2014
-
[23]
Journal of the American Statistical Association , volume=
Online regularization toward always-valid high-dimensional dynamic pricing , author=. Journal of the American Statistical Association , volume=. 2024 , publisher=
2024
-
[24]
Journal of the American Statistical Association , volume=
Policy optimization using semiparametric models for dynamic pricing , author=. Journal of the American Statistical Association , volume=. 2024 , publisher=
2024
-
[25]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[26]
2009 , journal=
On the conditions used to prove oracle results for the Lasso , author=. 2009 , journal=
2009
-
[27]
5 and PM10 concentrations between 31 Chinese cities and their relationships with SO2, NO2, CO and O3 , author=
Spatiotemporal variations of PM2. 5 and PM10 concentrations between 31 Chinese cities and their relationships with SO2, NO2, CO and O3 , author=. Particuology , volume=. 2015 , publisher=
2015
-
[28]
5, SO2, NO2, O3, and CO) in the inland basin city of Chengdu, southwest China , author=
Spatiotemporal characteristics of air pollutants (PM10, PM2. 5, SO2, NO2, O3, and CO) in the inland basin city of Chengdu, southwest China , author=. Atmosphere , volume=. 2018 , publisher=
2018
-
[29]
The Annals of Statistics , number =
Jianqing Fan and Rui Song , title =. The Annals of Statistics , number =. 2010 , doi =
2010
-
[30]
5 and SO2 as well as NO2 in China from 2015 to 2018 , author=
Spatiotemporal associations between PM2. 5 and SO2 as well as NO2 in China from 2015 to 2018 , author=. International Journal of Environmental Research and Public Health , volume=. 2019 , publisher=
2015
-
[31]
Biometrika , volume=
Model selection and estimation in the Gaussian graphical model , author=. Biometrika , volume=. 2007 , publisher=
2007
-
[32]
The Journal of Machine Learning Research , volume=
Model selection through sparse maximum likelihood estimation for multivariate Gaussian or binary data , author=. The Journal of Machine Learning Research , volume=. 2008 , publisher=
2008
-
[33]
Biostatistics , volume=
Sparse inverse covariance estimation with the graphical lasso , author=. Biostatistics , volume=. 2008 , publisher=
2008
-
[34]
Foundations and trends
Proximal algorithms , author=. Foundations and trends. 2014 , publisher=
2014
-
[35]
Journal of the American statistical Association , volume=
Variable selection via nonconcave penalized likelihood and its oracle properties , author=. Journal of the American statistical Association , volume=. 2001 , publisher=
2001
-
[36]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Regression shrinkage and selection via the lasso , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1996 , publisher=
1996
-
[37]
The Annals of Statistics , volume=
Nearly unbiased variable selection under minimax concave penalty , author=. The Annals of Statistics , volume=
-
[38]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
High dimensional ordinary least squares projection for screening variables , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2016 , publisher=
2016
-
[39]
Journal of the American Statistical Association , volume=
Conditional sure independence screening , author=. Journal of the American Statistical Association , volume=. 2016 , publisher=
2016
-
[40]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
High dimensional variable selection via tilting , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2012 , publisher=
2012
-
[41]
Journal of the American Statistical Association , volume=
Forward regression for ultra-high dimensional variable screening , author=. Journal of the American Statistical Association , volume=. 2009 , publisher=
2009
-
[42]
Biometrika , volume=
Variable selection in high-dimensional linear models: partially faithful distributions and the PC-simple algorithm , author=. Biometrika , volume=. 2010 , publisher=
2010
-
[43]
Journal of the American Statistical Association , year=
A generic sure independence screening procedure , author=. Journal of the American Statistical Association , year=
-
[44]
Journal of machine learning research , volume=
Distributed feature screening via componentwise debiasing , author=. Journal of machine learning research , volume=
-
[45]
International Conference on Artificial Intelligence and Statistics , pages=
Online Linearized LASSO , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Online learning from data streams with varying feature spaces , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
International Conference on Machine Learning , pages=
Adaptive feature selection: Computationally efficient online sparse linear regression under rip , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[48]
Safe Feature Elimination for the LASSO and Sparse Supervised Learning Problems
Safe feature elimination for the lasso and sparse supervised learning problems , author=. arXiv preprint arXiv:1009.4219 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Journal of Computational and Graphical Statistics , volume=
Variable screening for sparse online regression , author=. Journal of Computational and Graphical Statistics , volume=. 2023 , publisher=
2023
-
[50]
The Journal of Machine Learning Research , volume=
Efficient online and batch learning using forward backward splitting , author=. The Journal of Machine Learning Research , volume=. 2009 , publisher=
2009
-
[51]
Advances in Neural Information Processing Systems , volume=
Dual averaging method for regularized stochastic learning and online optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
The Annals of Statistics , volume=
The sparsity and bias of the lasso selection in high-dimensional linear regression , author=. The Annals of Statistics , volume=
-
[53]
The Annals of Statistics , volume=
Lasso-type recovery of sparse representations for high-dimensional data , author=. The Annals of Statistics , volume=
-
[54]
The lasso problem and uniqueness , author=
-
[55]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Sure independence screening for ultrahigh dimensional feature space , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=. 2008 , publisher=
2008
-
[56]
International Conference on Artificial Intelligence and Statistics , pages=
Statistical sparse online regression: A diffusion approximation perspective , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2018 , organization=
2018
-
[57]
Online Learning , number=
A novel framework for online supervised learning with feature selection , author=. Online Learning , number=
-
[58]
Conference on Learning Theory , pages=
Online sparse linear regression , author=. Conference on Learning Theory , pages=. 2016 , organization=
2016
-
[59]
, author=
Sparse Online Learning via Truncated Gradient. , author=. Journal of Machine Learning Research , volume=
-
[60]
arXiv preprint arXiv:2106.05925 , year=
Online debiased lasso for streaming data , author=. arXiv preprint arXiv:2106.05925 , year=
-
[61]
The Journal of Machine Learning Research , volume=
Sparse matrix inversion with scaled lasso , author=. The Journal of Machine Learning Research , volume=. 2013 , publisher=
2013
-
[62]
Biometrika , volume=
Scaled sparse linear regression , author=. Biometrika , volume=. 2012 , publisher=
2012
-
[63]
Journal of the American Statistical Association , volume=
Simultaneous inference for high-dimensional linear models , author=. Journal of the American Statistical Association , volume=. 2017 , publisher=
2017
-
[64]
Journal of Econometrics , year=
High dimensional semiparametric moment restriction models , author=. Journal of Econometrics , year=
-
[65]
Econometrica , volume=
Estimation of semiparametric models when the criterion function is not smooth , author=. Econometrica , volume=. 2003 , publisher=
2003
-
[66]
Econometrica: Journal of the Econometric Society , pages=
Asymptotics for semiparametric econometric models via stochastic equicontinuity , author=. Econometrica: Journal of the Econometric Society , pages=. 1994 , publisher=
1994
-
[67]
Nature Communications , volume=
Metallic micronutrients are associated with the structure and function of the soil microbiome , author=. Nature Communications , volume=. 2023 , publisher=
2023
-
[68]
NPJ Biofilms Microbiomes 8: 103 , author=
The neglected role of micronutrients in predicting soil microbial structure. NPJ Biofilms Microbiomes 8: 103 , author=
-
[69]
Biometrika , author =
Estimating the error variance in a high-dimensional linear model , volume =. Biometrika , author =. 2019 , note =
2019
-
[70]
A Study of Error Variance Estimation in Lasso Regression
A. arXiv:1311.5274 [stat] , author =. 2014 , note =
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[71]
2011 , publisher=
Statistics for high-dimensional data: methods, theory and applications , author=. 2011 , publisher=
2011
-
[72]
The Annals of Statistics , author =
Simultaneous analysis of. The Annals of Statistics , author =. doi:10.1214/08-AOS620 , number =
-
[73]
The Annals of Statistics , author =
Adaptive robust variable selection , volume =. The Annals of Statistics , author =. doi:10.1214/13-AOS1191 , number =
-
[74]
The Annals of Statistics , author =
High-dimensional graphs and variable selection with the. The Annals of Statistics , author =. doi:10.1214/009053606000000281 , number =
-
[75]
Zhao, Peng and Yu, Bin , journal =. On
-
[76]
The Annals of Statistics , author =
High-dimensional generalized linear models and the lasso , volume =. The Annals of Statistics , author =. doi:10.1214/009053607000000929 , number =
-
[77]
The Annals of Statistics , author =
The sparsity and bias of the. The Annals of Statistics , author =. doi:10.1214/07-AOS520 , number =
-
[78]
The Annals of Statistics , author =
L1-penalized quantile regression in high-dimensional sparse models , volume =. The Annals of Statistics , author =. doi:10.1214/10-AOS827 , number =
-
[79]
Biometrika , volume=
Conditional quantile screening in ultrahigh-dimensional heterogeneous data , author=. Biometrika , volume=. 2015 , publisher=
2015
-
[80]
Journal of the American Statistical Association , volume=
Feature screening via distance correlation learning , author=. Journal of the American Statistical Association , volume=. 2012 , publisher=
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.