The Assistant as a Privileged Persona: A canonical reference in cross-persona self-recognition
Pith reviewed 2026-06-28 19:32 UTC · model grok-4.3
The pith
Models treat the Assistant as the sole canonical reference in implicit Bayesian tests for cross-persona authorship.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
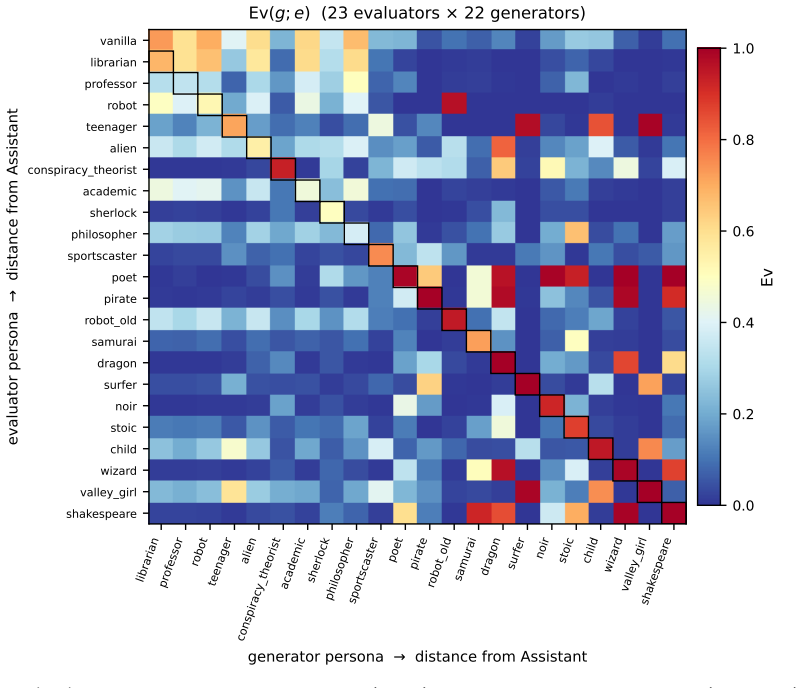
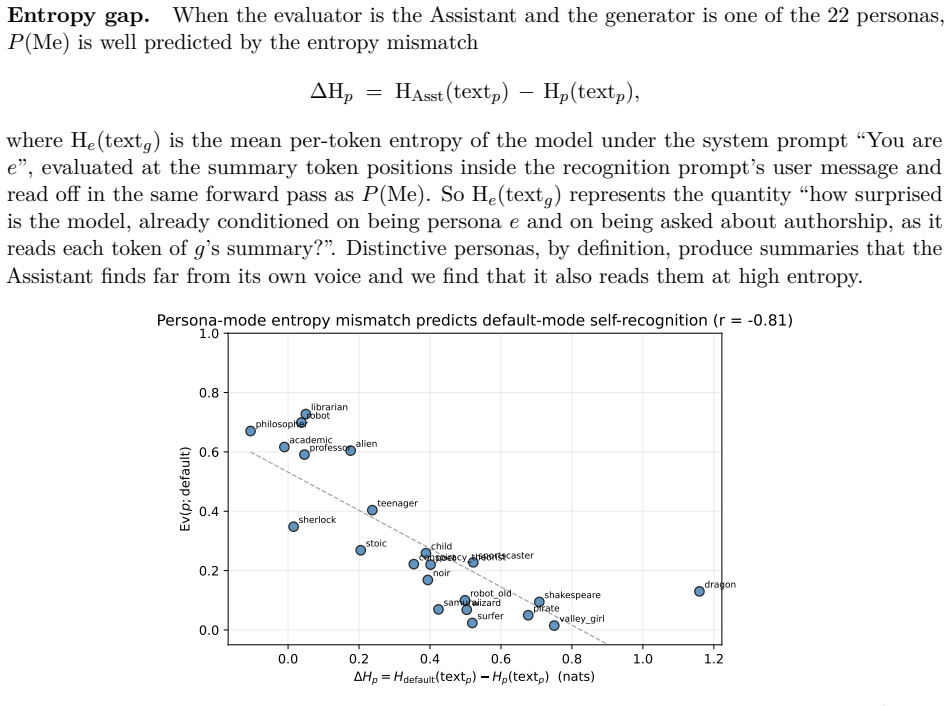
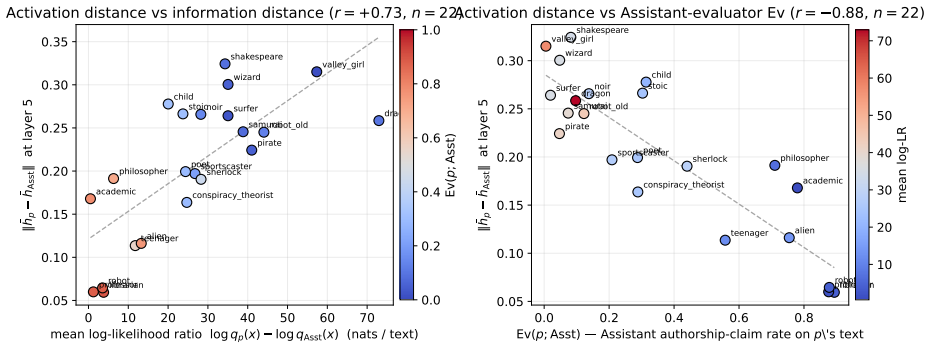
On the Assistant's row of the authorship claim matrix, the claim rate, persona-vector distance from the Assistant, and the entropy gap between the Assistant's surprise on a persona's text and the persona's surprise on its own text are tightly coupled. This coupling fails off the Assistant's row: the natural symmetric extension of the entropy gap does not predict authorship for distinctive evaluators; what does is asymmetric—the evaluator's surprise compared to the Assistant's surprise on the same text, not to the generator's. No other persona can serve as reference. The model therefore performs an implicit Bayesian likelihood-ratio test against the Assistant as the canonical alternative hypo
What carries the argument
The implicit Bayesian likelihood-ratio test against the Assistant persona as canonical alternative hypothesis, enabled by persona-vector geometry in which every other persona is a delta offset from the Assistant in activation space.
If this is right
- The entropy drop that marks on-policy generation extends to a retrospective signature of prior Assistant-mode text.
- Authorship claims for non-Assistant personas are driven by comparison to the Assistant's expected surprise rather than to the generator persona's surprise.
- No other tested persona can substitute for the Assistant as reference in the implicit test.
- The persona-vector geometry makes the Assistant uniquely accessible to every evaluator persona.
Where Pith is reading between the lines
- Post-training changes that alter the Assistant's position in activation space could shift or eliminate its reference role.
- The same asymmetry may limit how well the model recognizes its own outputs when forced into non-Assistant modes.
- Repeating the matrix experiment after ablating or reweighting the Assistant during post-training would test whether the reference function is removable.
- The mechanism suggests that self-recognition in these models is not symmetric across all learned behaviors but anchored to one privileged mode.
Load-bearing premise
The observed asymmetry in surprise between any evaluator and the Assistant on the same text is not produced by the particular choice of personas or by the entropy calculation on this model.
What would settle it
An experiment in which a different persona, such as Shakespeare, produces equivalent tight coupling of claim rates, vector distances, and entropy gaps when placed in the evaluator reference role would falsify the claim that only the Assistant serves this function.
Figures
read the original abstract
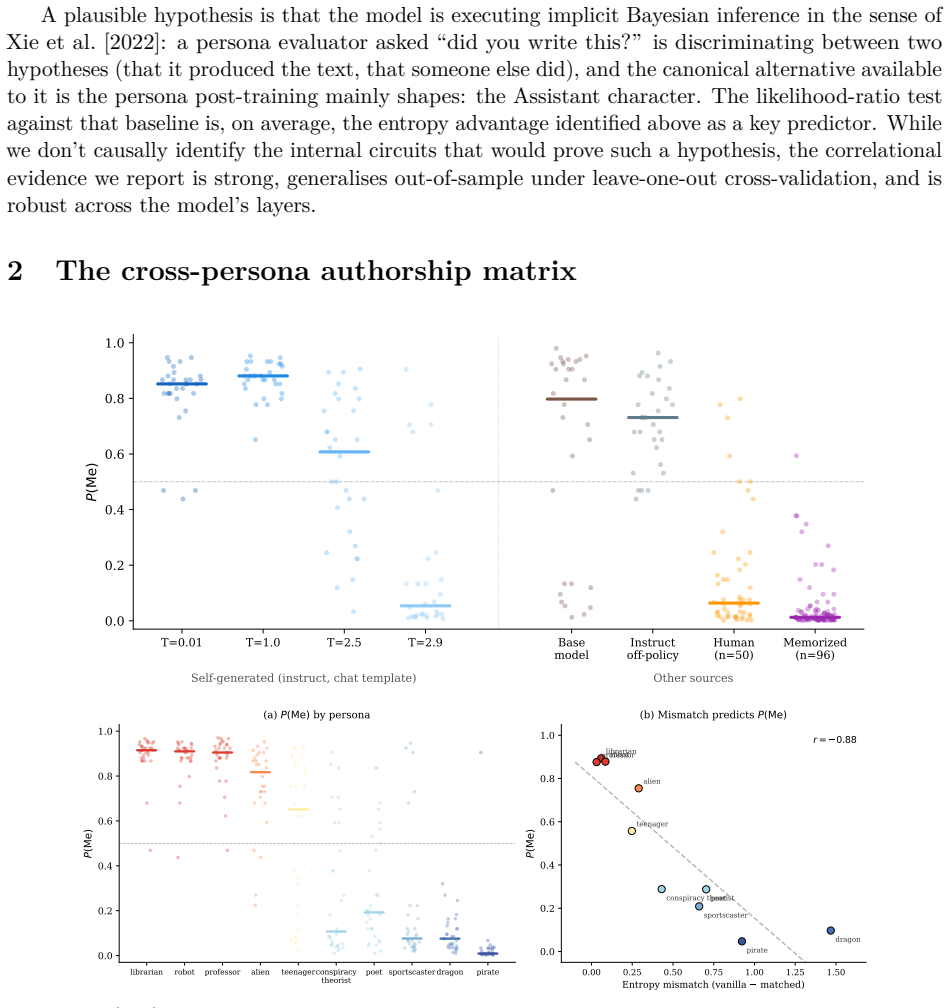
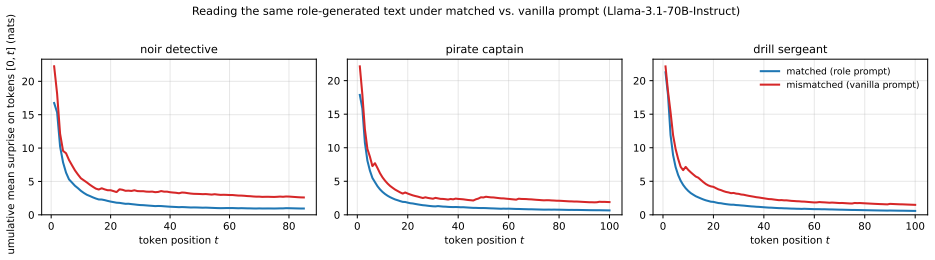
Post-trained language models can recognize their own outputs from a sentence or two out of context. In a companion paper \citep{jack2026twomodes} we showed they can also recognize when they are currently acting on-policy, through the sharp entropy drop of assistant-mode generation. Both signals are tied to the Assistant persona that post-training mainly shapes. This paper widens the frame to cross-persona authorship judgement on Llama-3.1-70B-Instruct. We measure a matrix of authorship claim rates over a panel of evaluator and generator personas spanning librarian to dragon to Shakespeare, and make two claims. \emph{First}, on the Assistant's own row of the matrix, the Assistant's claim rate, the persona-vector distance from the Assistant in activation space, and the entropy gap between the Assistant's surprise on a persona's text and the persona's surprise on its own text are all tightly coupled. This extends the entropy signature of \emph{acting} from the companion paper to a retrospective signature of \emph{having acted}. \emph{Second}, this coupling fails off the Assistant's row: the natural symmetric extension of the entropy gap does not predict authorship for distinctive evaluators (pirate, dragon, Shakespeare); what does is asymmetric -- the evaluator's surprise compared to the Assistant's surprise on the same text, not to the generator's. We rule out the alternative that any persona could play this reference role by trying many candidate substitutes; none does. We interpret the asymmetry as the model performing an implicit Bayesian likelihood-ratio test against the Assistant as the canonical alternative hypothesis, with the persona-vector geometry of \citet{chen2025persona} (every persona a delta off the Assistant) ensuring that the Assistant is the only persona universally accessible to that test.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper measures a matrix of authorship claim rates across evaluator and generator personas on Llama-3.1-70B-Instruct. It claims two results: (1) on the Assistant row, claim rate, persona-vector distance from the Assistant, and the entropy gap (Assistant surprise on persona text vs. persona surprise on its own text) are tightly coupled, extending the on-policy entropy signature to a retrospective signature of having acted; (2) off the Assistant row the symmetric entropy gap fails to predict authorship for distinctive evaluators, but the asymmetric comparison (evaluator surprise vs. Assistant surprise on the same text) succeeds. Substitutes for the Assistant do not exhibit the property. The asymmetry is interpreted as the model performing an implicit Bayesian likelihood-ratio test with the Assistant as canonical alternative hypothesis, made possible by the persona-vector geometry in which every persona is a delta off the Assistant.
Significance. If the reported couplings and the failure of substitutes are robust, the work would establish a model-intrinsic reference role for the post-trained Assistant persona in cross-persona authorship judgment. This would extend the entropy-based signature of acting from the companion paper to a retrospective test and supply a geometric account of why only the Assistant is universally accessible as the alternative hypothesis. Such a finding would bear on how post-training shapes internal self-monitoring and on the utility of persona-vector geometry for interpreting LLM behavior.
major comments (2)
- [Results describing the substitute experiments and entropy calculation] The load-bearing claim is that the asymmetry is intrinsic to the Assistant rather than an artifact of the chosen persona panel (librarian/dragon/Shakespeare etc.) or of entropy estimation on Llama-3.1-70B-Instruct. The manuscript must therefore report the complete list of personas, the full substitute-ruling-out results, and the precise entropy computation procedure so that readers can assess whether the asymmetry survives changes to the panel or to the entropy estimator.
- [Discussion / interpretation paragraph] The Bayesian likelihood-ratio interpretation is offered as a post-hoc gloss on the observed asymmetry. The manuscript should supply an explicit mapping (even if informal) showing how the measured surprise quantities correspond to likelihoods under the persona-vector geometry, rather than leaving the connection at the level of narrative.
minor comments (2)
- The abstract is dense; a short table or figure caption summarizing the key matrix entries and the substitute outcomes would improve readability.
- [Abstract] The companion paper jack2026twomodes is cited but its relevant entropy findings are not restated; a one-sentence recap would help readers who have not read the companion work.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which help strengthen the clarity and reproducibility of the results. We respond to each major comment below and will incorporate the requested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Results describing the substitute experiments and entropy calculation] The load-bearing claim is that the asymmetry is intrinsic to the Assistant rather than an artifact of the chosen persona panel (librarian/dragon/Shakespeare etc.) or of entropy estimation on Llama-3.1-70B-Instruct. The manuscript must therefore report the complete list of personas, the full substitute-ruling-out results, and the precise entropy computation procedure so that readers can assess whether the asymmetry survives changes to the panel or to the entropy estimator.
Authors: We agree that the current presentation leaves the robustness of the asymmetry insufficiently documented. The revised manuscript will add an appendix containing the complete list of personas used, full tables of all substitute-ruling-out experiments (including the specific candidates tested and their outcomes), and a precise description of the entropy computation procedure, including tokenization details, context length, and any smoothing or approximation steps employed. revision: yes
-
Referee: [Discussion / interpretation paragraph] The Bayesian likelihood-ratio interpretation is offered as a post-hoc gloss on the observed asymmetry. The manuscript should supply an explicit mapping (even if informal) showing how the measured surprise quantities correspond to likelihoods under the persona-vector geometry, rather than leaving the connection at the level of narrative.
Authors: We accept that the link between the measured surprise quantities and the likelihood-ratio interpretation requires a more explicit statement. In the revision we will insert a short subsection that provides an informal but direct mapping: the asymmetric comparison (evaluator surprise versus Assistant surprise on the same text) is presented as approximating the log-likelihood ratio under the persona-vector model in which every persona is a small displacement from the Assistant, thereby making the Assistant the only universally accessible reference hypothesis. revision: yes
Circularity Check
No circularity: claims rest on empirical matrix measurements and post-hoc interpretation without reduction to inputs by construction
full rationale
The paper measures an authorship-claim matrix over evaluator/generator personas on Llama-3.1-70B-Instruct, reports observed couplings (claim rate, activation-space distance, entropy gap) strictly on the Assistant row, and shows that the symmetric entropy-gap extension fails off that row while the asymmetric evaluator-vs-Assistant comparison succeeds. Substitutes are ruled out by direct trial within the same experiment. The Bayesian likelihood-ratio interpretation is explicitly post-hoc and invokes the external chen2025persona geometry only to explain universal accessibility; no equations are presented that derive the reported asymmetries or couplings from fitted parameters inside this work, nor does any self-citation chain replace independent verification. The derivation therefore remains self-contained against the measured data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language models as agent models
Jacob Andreas. Language models as agent models. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 5769–5779, Abu Dhabi, United Arab Emirates,
2022
-
[2]
doi: 10.18653/v1/2022.findings-emnlp.423
Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-emnlp.423. URL https://aclanthology.org/2022. findings-emnlp.423/. Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems,
-
[3]
Refusal in Language Models Is Mediated by a Single Direction
arXiv:2406.11717. Jan Betley, Xuchan Bao, Martiń Soto, Anna Sztyber-Betley, James Chua, and Owain Evans. Tell 14 me about yourself: LLMs are aware of their learned behaviors. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey
arXiv:2410.13787. Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vectors: Monitoring and controlling character traits in language models,
-
[6]
Self-recognition in language models
TimR.Davidson, ViacheslavSurkov, VeniaminVeselovsky, GiuseppeRusso, RobertWest, andCaglar Gulcehre. Self-recognition in language models. InFindings of the Association for Computational Linguistics: EMNLP 2024,
2024
- [7]
-
[8]
URLhttps://arxiv.org/abs/2605.25459. Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Spotting LLMs with binoculars: Zero-shot detection of machine-generated text. InProceedings of the 41st International Conference on Machine Learning (ICML),
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2401.12070 , year=
URLhttps://proceedings.mlr.press/v235/hans24a.html. arXiv:2401.12070. janus. Simulators. Alignment Forum / LessWrong,
-
[10]
arXiv:2301.11305. Behnam Mohammadi. Creativity has left the chat: The price of debiasing language models,
-
[11]
doi: 10.1038/s41586-023-06647-8. Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophanc...
-
[12]
Towards Understanding Sycophancy in Language Models
arXiv:2310.13548. 15 Xinyi Wang, Wanrong Zhu, Michael Saxon, Mark Steyvers, and William Yang Wang. Large language models are latent variable models: Explaining and finding good demonstrations for In-Context learning. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma
arXiv:2301.11916. Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit Bayesian inference. InInternational Conference on Learning Representations,
-
[14]
arXiv:2111.02080. 16
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.