LASER: Loss-Aware Singular-value Decomposition and Rank Allocation for Efficient Low-Precision Vision-Language Models
Pith reviewed 2026-06-28 19:07 UTC · model grok-4.3
The pith
LASER derives a curvature-weighted SVD from a second-order loss approximation to compress vision-language models for faster low-precision inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
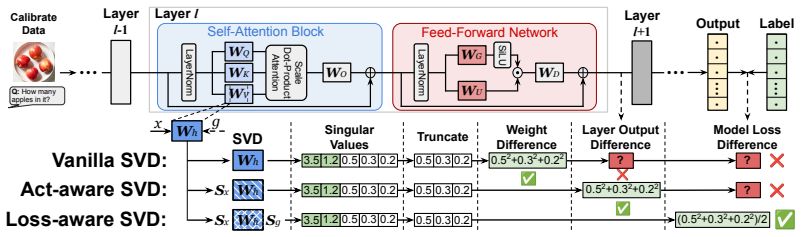
LASER derives a curvature-weighted SVD objective from a second-order approximation of the model loss and uses Kronecker-factored Fisher information to guide decomposition toward downstream performance rather than reconstruction alone. It further introduces a loss-aware cross-layer rank allocation strategy based on calibration gradients and extends low-rank compression to FFN layers through a hybrid SVD-plus-quantization scheme.
What carries the argument
Curvature-weighted SVD objective obtained from second-order loss approximation, combined with loss-aware cross-layer rank allocation driven by calibration gradients.
If this is right
- Low-rank compression can be applied to both attention and feed-forward layers without separate retraining pipelines.
- Parameter budgets can be allocated non-uniformly across layers according to measured loss sensitivity.
- Low-precision inference becomes feasible at higher compression ratios while keeping task performance intact.
- Decoding throughput improves by more than 2.3 times relative to prior low-rank methods on the same hardware.
Where Pith is reading between the lines
- The same loss-sensitivity weighting could be tested on non-VLM transformer families to check whether the curvature signal remains predictive.
- If the calibration gradients prove stable across datasets, the rank allocator might be reused without per-task recalibration.
- Hybrid SVD-quantization on FFNs suggests that mixed compression operators could be searched jointly rather than chosen layer-wise by hand.
Load-bearing premise
The second-order Taylor approximation of the model loss, together with Kronecker-factored Fisher information, reliably indicates which singular vectors and ranks to retain so that downstream accuracy is preserved better than reconstruction-error baselines.
What would settle it
Running LASER-compressed models on standard VLM benchmarks and finding that accuracy drops below that of reconstruction-error SVD at the same total parameter count would falsify the central claim.
Figures




read the original abstract
Vision-language models (VLMs) deliver strong multimodal reasoning capabilities, but their large computational cost and high parameter counts make deployment challenging on resource-constrained devices. Low-rank decomposition has emerged as a promising compression technique, yet existing methods often optimize local matrix reconstruction error, rely on uniform or heuristic rank allocation, and focus mainly on attention projections while leaving feed-forward networks underexplored. In this paper, we propose~\textit{LASER} (\textbf{L}oss-\textbf{A}ware \textbf{S}ingular-value d\textbf{E}composition and \textbf{R}ank allocation), a low-rank compression framework for efficient low-precision VLM inference. LASER derives a curvature-weighted SVD objective from a second-order approximation of the model loss and uses Kronecker-factored Fisher information to guide decomposition toward downstream performance rather than reconstruction alone. We further introduce a loss-aware cross-layer rank allocation strategy based on calibration gradients, enabling more effective parameter budgeting across layers. Finally, we extend low-rank compression to FFN layers through a hybrid scheme that combines SVD with quantization. The evaluation results show that LASER achieves more than $2.3\times$ decoding speedup over previous work while preserving strong accuracy under low-precision inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LASER, a low-rank compression framework for vision-language models. It derives a curvature-weighted SVD objective from a second-order Taylor approximation of the model loss (using Kronecker-factored Fisher information), proposes a loss-aware cross-layer rank allocation strategy based on calibration gradients, and applies a hybrid SVD-quantization scheme to FFN layers. The central claim is that this approach yields more than 2.3× decoding speedup over prior work while preserving downstream accuracy under low-precision inference.
Significance. If the empirical results and ablations hold, the work would be significant for providing a principled, loss-aware alternative to reconstruction-error SVD in VLM compression. The use of second-order curvature guidance and cross-layer allocation directly targets task performance rather than local matrix fidelity, and the FFN extension broadens applicability. The paper includes benchmark evaluations, which is a positive feature.
major comments (2)
- [§3.2] §3.2, Eq. (7): The curvature-weighted SVD objective is motivated by the claim that the K-FAC approximation of the Hessian/Fisher better ranks singular vectors for downstream loss preservation than plain reconstruction error; however, the manuscript does not report a direct head-to-head comparison (e.g., task accuracy after compression) between the proposed weighted SVD and standard SVD at matched ranks and bit-widths, leaving open whether the second-order model actually improves the selection under the finite perturbations induced by truncation plus quantization.
- [Table 3] Table 3 and §5.3: The reported 2.3× speedup and accuracy preservation are attributed to the combination of loss-aware decomposition and cross-layer rank allocation, yet no ablation isolates the contribution of the loss-aware rank allocation (versus uniform or heuristic allocation) while holding the SVD objective fixed; without this, the central claim that the full LASER pipeline is responsible for the gains cannot be fully substantiated.
minor comments (2)
- [Abstract] The abstract states empirical gains but supplies no quantitative numbers (speedup factor, accuracy deltas, model sizes); adding the key headline metrics would improve readability.
- [§3.1] Notation for the Kronecker factors in the Fisher approximation (e.g., how A and G are defined per layer) could be made more explicit in §3.1 to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to provide stronger empirical support for the claims.
read point-by-point responses
-
Referee: [§3.2] §3.2, Eq. (7): The curvature-weighted SVD objective is motivated by the claim that the K-FAC approximation of the Hessian/Fisher better ranks singular vectors for downstream loss preservation than plain reconstruction error; however, the manuscript does not report a direct head-to-head comparison (e.g., task accuracy after compression) between the proposed weighted SVD and standard SVD at matched ranks and bit-widths, leaving open whether the second-order model actually improves the selection under the finite perturbations induced by truncation plus quantization.
Authors: We agree that a direct head-to-head comparison is needed to substantiate the benefit of the curvature-weighted objective. In the revised manuscript, we will add an ablation that compares task accuracy after compression using the proposed K-FAC-weighted SVD versus standard SVD, at matched ranks and bit-widths, to evaluate performance under truncation plus quantization. revision: yes
-
Referee: [Table 3] Table 3 and §5.3: The reported 2.3× speedup and accuracy preservation are attributed to the combination of loss-aware decomposition and cross-layer rank allocation, yet no ablation isolates the contribution of the loss-aware rank allocation (versus uniform or heuristic allocation) while holding the SVD objective fixed; without this, the central claim that the full LASER pipeline is responsible for the gains cannot be fully substantiated.
Authors: We acknowledge that isolating the rank allocation contribution is important. We will add an ablation in the revised manuscript that holds the SVD objective fixed and compares loss-aware cross-layer allocation against uniform and heuristic strategies, reporting the resulting impact on speedup and accuracy to better substantiate the full pipeline. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The abstract and available text present LASER as deriving a curvature-weighted SVD objective from the standard second-order Taylor expansion of model loss combined with Kronecker-factored Fisher information, followed by a gradient-based rank allocation strategy. These steps are independent mathematical constructions that do not reduce by definition or by self-citation to the target performance metrics or fitted parameters. No equations, self-citations, or uniqueness theorems are quoted that would force the claimed accuracy preservation or speedup to be equivalent to the inputs by construction. The method is therefore not circular; downstream empirical results on VLMs stand as falsifiable claims separate from the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Natural gradient works efficiently in learning.Neural computation, 10(2):251–276, 1998
Shun-Ichi Amari. Natural gradient works efficiently in learning.Neural computation, 10(2):251–276, 1998
1998
-
[2]
Quarot: Outlier-free 4-bit inference in rotated llms
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. Advances in Neural Information Processing Systems, 37:100213–100240, 2024
2024
-
[3]
Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond, 2(1):1, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond, 2(1):1, 2023
2023
-
[4]
Vision–language model for visual question answering in medical imagery.Bioengineering, 10(3):380, 2023
Yakoub Bazi, Mohamad Mahmoud Al Rahhal, Laila Bashmal, and Mansour Zuair. Vision–language model for visual question answering in medical imagery.Bioengineering, 10(3):380, 2023
2023
-
[5]
Paligemma: A versatile 3b vlm for transfer.CoRR, 2024
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.CoRR, 2024
2024
-
[6]
Palu: Compressing kv-cache with low-rank projection.arXiv preprint arXiv:2407.21118, 2024
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Mohamed S Abdelfattah, and Kai-Chiang Wu. Palu: Compressing kv-cache with low-rank projection.arXiv preprint arXiv:2407.21118, 2024
-
[7]
Prompt-rsvqa: Prompting visual context to a language model for remote sensing visual question answering
Christel Chappuis, Valérie Zermatten, Sylvain Lobry, Bertrand Le Saux, and Devis Tuia. Prompt-rsvqa: Prompting visual context to a language model for remote sensing visual question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1372–1381, 2022
2022
-
[8]
Visualgpt: Data-efficient adaptation of pretrained language models for image captioning
Jun Chen, Han Guo, Kai Yi, Boyang Li, and Mohamed Elhoseiny. Visualgpt: Data-efficient adaptation of pretrained language models for image captioning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18030–18040, 2022
2022
-
[9]
Instructblip: towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: towards general-purpose vision-language models with instruction tuning. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
2023
-
[10]
Flash-decoding for long-context inference
Tri Dao, Daniel Haziza, Francisco Massa, and Grigory Sizov. Flash-decoding for long-context inference. https://pytorch.org/blog/flash-decoding/, October 2023. Accessed: 2025-09-22
2023
-
[11]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024
2024
-
[12]
Maksim Dzabraev, Alexander Kunitsyn, and Andrei Ivaniuta. Vlrm: Vision-language models act as reward models for image captioning.arXiv preprint arXiv:2404.01911, 2024
-
[13]
The approximation of one matrix by another of lower rank.Psychometrika, 1 (3):211–218, 1936
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank.Psychometrika, 1 (3):211–218, 1936
1936
-
[14]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Analysis of the cholesky decomposition of a semi-definite matrix
Nicholas J Higham. Analysis of the cholesky decomposition of a semi-definite matrix. 1990
1990
-
[17]
Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. Language model compression with weighted low-rank factorization.arXiv preprint arXiv:2207.00112, 2022
-
[18]
Scaling up vision-language pre-training for image captioning
Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang. Scaling up vision-language pre-training for image captioning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17980–17989, 2022
2022
-
[19]
Principal component analysis: a review and recent developments
Ian T Jolliffe and Jorge Cadima. Principal component analysis: a review and recent developments. Philosophical transactions of the royal society A: Mathematical, Physical and Engineering Sciences, 374 (2065):20150202, 2016. 11
2065
-
[20]
Seed-bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13299–13308, 2024
2024
-
[21]
Chuanhao Li, Zhen Li, Chenchen Jing, Shuo Liu, Wenqi Shao, Yuwei Wu, Ping Luo, Yu Qiao, and Kaipeng Zhang. Searchlvlms: A plug-and-play framework for augmenting large vision-language models by searching up-to-date internet knowledge.arXiv preprint arXiv:2405.14554, 2024
-
[22]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
2022
-
[23]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[24]
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, and Song Han. Svdqunat: Absorbing outliers by low-rank components for 4-bit diffusion models.arXiv preprint arXiv:2411.05007, 2024
-
[25]
Shiyao Li, Yingchun Hu, Xuefei Ning, Xihui Liu, Ke Hong, Xiaotao Jia, Xiuhong Li, Yaqi Yan, Pei Ran, Guohao Dai, et al. Mbq: Modality-balanced quantization for large vision-language models.arXiv preprint arXiv:2412.19509, 2024
-
[26]
Zhiteng Li, Mingyuan Xia, Jingyuan Zhang, Zheng Hui, Linghe Kong, Yulun Zhang, and Xiaokang Yang. Adasvd: Adaptive singular value decomposition for large language models.arXiv preprint arXiv:2502.01403, 2025
-
[27]
Duquant: Distributing outliers via dual transformation makes stronger quantized llms
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. Duquant: Distributing outliers via dual transformation makes stronger quantized llms. Advances in Neural Information Processing Systems, 37:87766–87800, 2024
2024
-
[28]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of Machine Learning and Systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of Machine Learning and Systems, 6:87–100, 2024
2024
-
[29]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving.Proceedings of Machine Learning and Systems, 7, 2025
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. Qserve: W4a8kv4 quantization and system co-design for efficient llm serving.Proceedings of Machine Learning and Systems, 7, 2025
2025
-
[30]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[32]
Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233. Springer, 2024
2024
-
[33]
SpinQuant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: Llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. InThe 36th Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[35]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020
James Martens. New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020
2020
-
[37]
Optimizing neural networks with kronecker-factored approximate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approximate curvature. InInternational conference on machine learning, pages 2408–2417. PMLR, 2015. 12
2015
-
[38]
Symmetric gauge functions and unitarily invariant norms.The quarterly journal of mathematics, 11(1):50–59, 1960
Leon Mirsky. Symmetric gauge functions and unitarily invariant norms.The quarterly journal of mathematics, 11(1):50–59, 1960
1960
-
[39]
Compressing pre-trained language models by matrix decomposition
Matan Ben Noach and Yoav Goldberg. Compressing pre-trained language models by matrix decomposition. InProceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, pages 884–889, 2020
2020
-
[40]
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models.arXiv preprint arXiv:2308.13137, 2023
-
[41]
Leveraging large vision-language model as user intent-aware encoder for composed image retrieval
Zelong Sun, Dong Jing, Guoxing Yang, Nanyi Fei, and Zhiwu Lu. Leveraging large vision-language model as user intent-aware encoder for composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7149–7157, 2025
2025
-
[42]
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks.arXiv preprint arXiv:2402.04396, 2024
-
[43]
The llm surgeon.arXiv preprint arXiv:2312.17244, 2023
Tycho FA van der Ouderaa, Markus Nagel, Mart Van Baalen, Yuki M Asano, and Tijmen Blankevoort. The llm surgeon.arXiv preprint arXiv:2312.17244, 2023
-
[44]
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, and Jiwen Lu. Q-vlm: Post-training quantization for large vision-language models.arXiv preprint arXiv:2410.08119, 2024
-
[45]
Eigendamage: Structured pruning in the kronecker-factored eigenbasis
Chaoqi Wang, Roger Grosse, Sanja Fidler, and Guodong Zhang. Eigendamage: Structured pruning in the kronecker-factored eigenbasis. InInternational conference on machine learning, pages 6566–6575. PMLR, 2019
2019
-
[46]
Guankun Wang, Long Bai, Wan Jun Nah, Jie Wang, Zhaoxi Zhang, Zhen Chen, Jinlin Wu, Mobarakol Islam, Hongbin Liu, and Hongliang Ren. Surgical-lvlm: Learning to adapt large vision-language model for grounded visual question answering in robotic surgery.arXiv preprint arXiv:2405.10948, 2024
-
[47]
WSVD: Weighted low-rank approximation for fast and efficient execution of low-precision vision-language models
Haiyu Wang, Yutong Wang, Jack Jiang, and Sai Qian Zhang. WSVD: Weighted low-rank approximation for fast and efficient execution of low-precision vision-language models. InThe Fourteenth International Con- ference on Learning Representations, 2026. URL https://openreview.net/forum?id=zrmQ4koOw9
2026
-
[48]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Qinsi Wang, Jinghan Ke, Masayoshi Tomizuka, Yiran Chen, Kurt Keutzer, and Chenfeng Xu. Dobi-svd: Differentiable svd for llm compression and some new perspectives.arXiv preprint arXiv:2502.02723, 2025
-
[50]
Basis shar- ing: Cross-layer parameter sharing for large language model compression
Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. Svd-llm: Truncation-aware singular value decompo- sition for large language model compression.arXiv preprint arXiv:2403.07378, 2024
-
[51]
Xin Wang, Samiul Alam, Zhongwei Wan, Hui Shen, and Mi Zhang. Svd-llm v2: Optimizing singular value truncation for large language model compression.arXiv preprint arXiv:2503.12340, 2025
-
[52]
Yutong Wang, Haiyu Wang, and Sai Qian Zhang. Qsvd: Efficient low-rank approximation for unified query- key-value weight compression in low-precision vision-language models.arXiv preprint arXiv:2510.16292, 2025
-
[53]
Jingyang Xiang and Sai Qian Zhang. Dfrot: Achieving outlier-free and massive activation-free for rotated llms with refined rotation.arXiv preprint arXiv:2412.00648, 2024
-
[54]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational Conference on Machine Learning, pages 38087–38099. PMLR, 2023
2023
-
[55]
Effectively compress kv heads for llm.arXiv preprint arXiv:2406.07056, 2024
Hao Yu, Zelan Yang, Shen Li, Yong Li, and Jianxin Wu. Effectively compress kv heads for llm.arXiv preprint arXiv:2406.07056, 2024
-
[56]
Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, and Lichao Sun. Tinygpt-v: Efficient multimodal large language model via small backbones.arXiv preprint arXiv:2312.16862, 2023. 13
-
[57]
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models
Zhihang Yuan, Yuzhang Shang, Yue Song, Qiang Wu, Yan Yan, and Guangyu Sun. Asvd: Activation-aware singular value decomposition for compressing large language models.arXiv preprint arXiv:2312.05821, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Tinyllava: A framework of small-scale large multimodal models,
Baichuan Zhou, Ying Hu, Xi Weng, Junlong Jia, Jie Luo, Xien Liu, Ji Wu, and Lei Huang. Tinyllava: A framework of small-scale large multimodal models.arXiv preprint arXiv:2402.14289, 2024. 14 A Technical appendices and supplementary material A.1 K-FAC Loss Surrogate for Weight Compression Derivation.By Taylor’s theorem, the loss variation induced by∆Wsatis...
-
[59]
26 Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.