AdaKernel: Learning Adaptive Kernel Parameters for Spatiotemporal Graph Neural Networks
Pith reviewed 2026-06-28 17:21 UTC · model grok-4.3
The pith
Misspecified kernel parameters create unavoidable approximation errors in spatiotemporal GNNs that can be removed by learning adaptive parameters while preserving graph structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
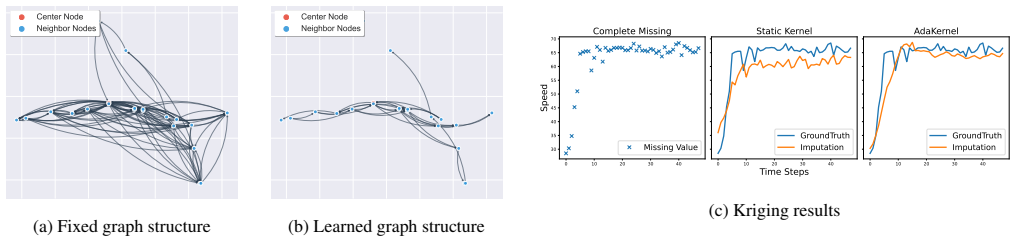
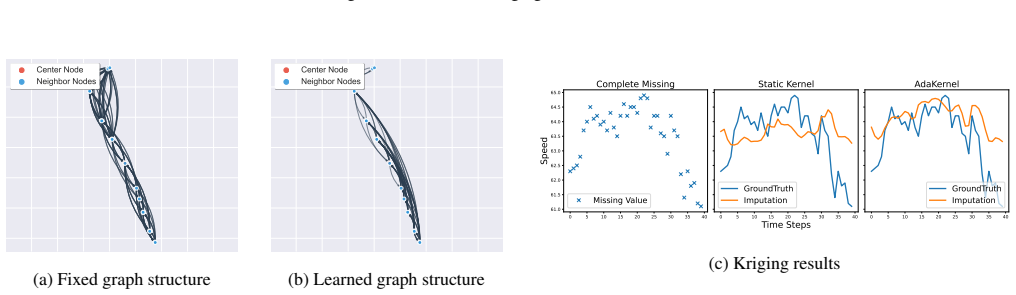
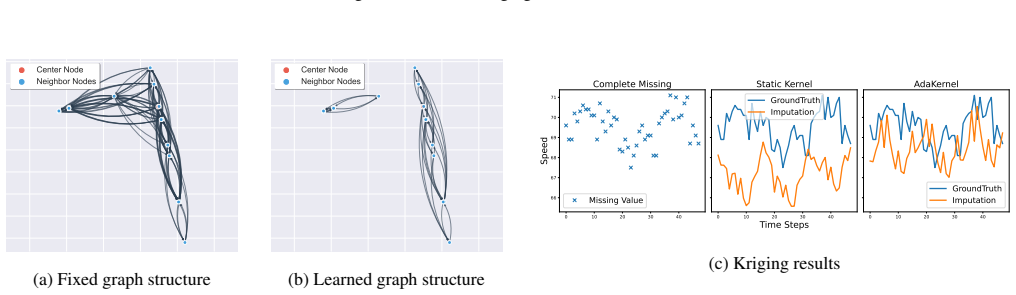
Misspecified kernel parameters introduce unavoidable approximation errors in GNNs. AdaKernel learns adaptive kernel parameters inside the neural network by optimizing the scale of physical interactions instead of discarding the original distance kernel and learning a new graph from scratch.
What carries the argument
AdaKernel, a structure-preserving mechanism that optimizes the scale parameter of an existing distance kernel inside the GNN training loop.
If this is right
- Standard GNN layers for spatiotemporal tasks can be upgraded by inserting AdaKernel without changing their architecture.
- Performance improves most in data-sparse regimes where fully learned graphs lose the geometric signal.
- Learned kernel parameters outperform both fixed priors and model-agnostic adaptive mechanisms on kriging, imputation, and forecasting.
- The same adaptive-scale idea applies to any GNN that begins with a distance-derived adjacency matrix.
Where Pith is reading between the lines
- If the supplied distance kernel misses the main spatial pattern, the structure-preserving choice may lose to fully latent alternatives.
- The method could be tested on non-Euclidean domains where the initial kernel is only an approximation.
- One could measure how much the learned scale deviates from the original parameter across different datasets to quantify reliance on the prior.
Load-bearing premise
The initial distance kernel already encodes the dominant geometric structure, so scaling it is sufficient.
What would settle it
A spatiotemporal dataset in which no scaling of the given distance kernel recovers the true interaction graph, where AdaKernel then underperforms a method that learns the graph structure from scratch.
Figures

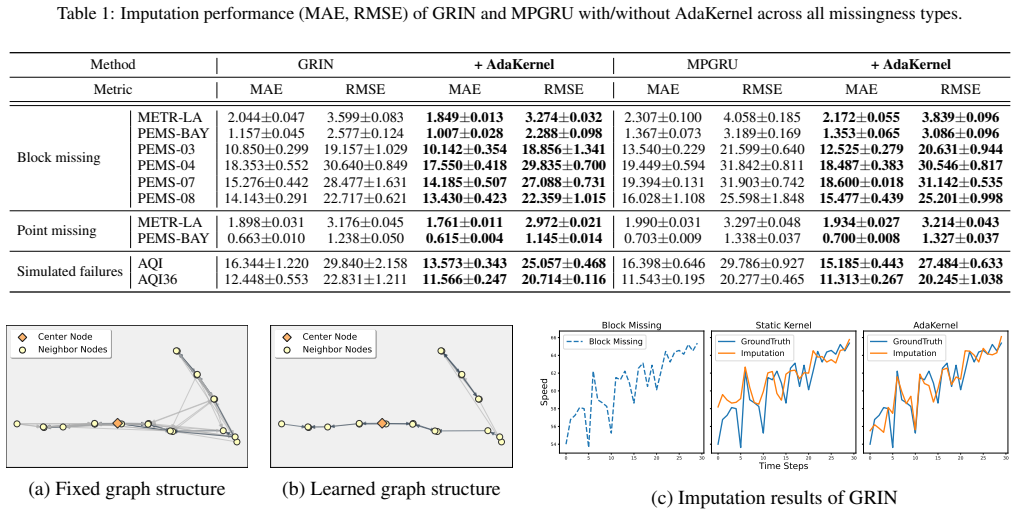
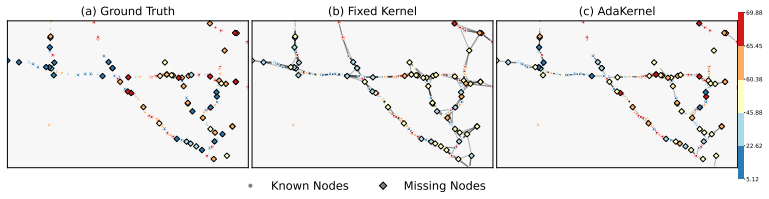
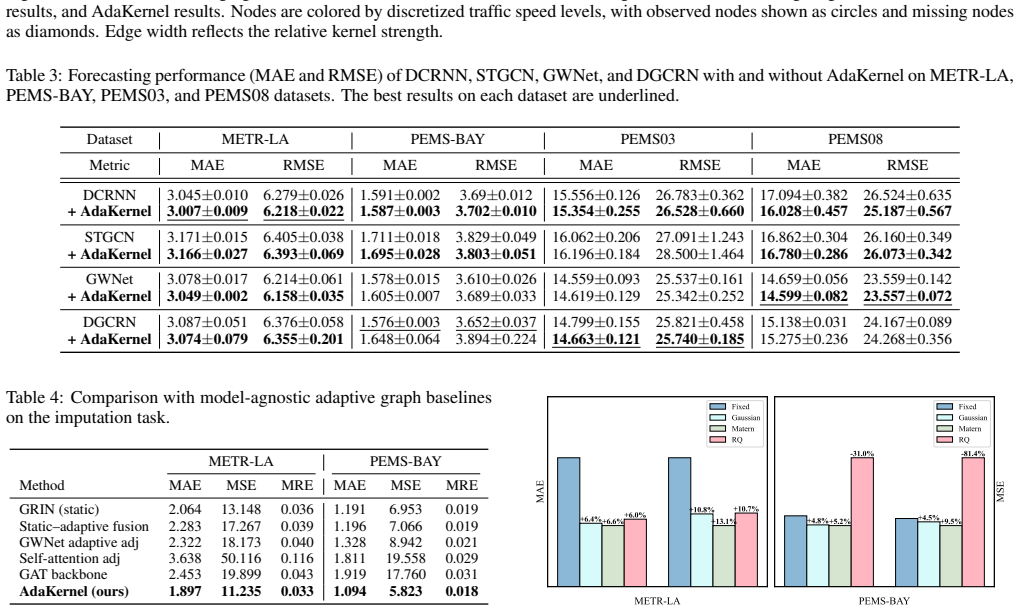
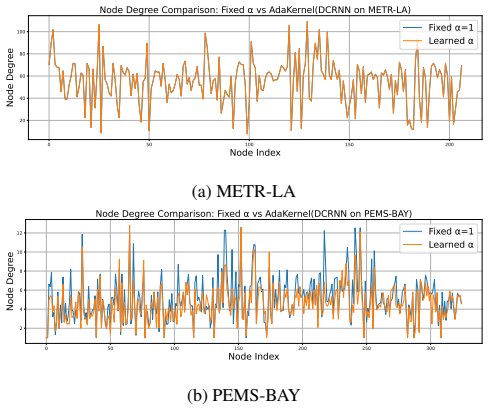






read the original abstract
Modeling spatial dependencies is central to spatiotemporal data analysis using Graph Neural Networks (GNNs). Traditional methods rely on distance-based kernels with predefined parameters, which restricts model capacity. Although generic adaptive mechanisms (e.g., Graph Attention Networks) offer flexibility, they often fail to capture the underlying geometric structure, performing worse than distance-based models in data-sparse scenarios. Addressing this, we revisit the kernel parameterization problem and theoretically prove that misspecified kernel parameters introduce unavoidable approximation errors in GNNs. To overcome this, we propose AdaKernel, a simple yet effective approach that learns adaptive kernel parameters within the neural network. Unlike methods that learn graph structures from scratch, AdaKernel adopts a structure-preserving strategy that optimizes the scale of physical interactions rather than discarding them. Extensive experiments on Kriging, Imputation, and Forecasting demonstrate that AdaKernel consistently improves various GNN architectures and outperforms model-agnostic adaptive baselines, validating that accurately learned kernel parameters are superior to both fixed priors and fully latent graph structures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that misspecified parameters in distance-based kernels for spatiotemporal GNNs introduce unavoidable approximation errors (theoretically proven), and introduces AdaKernel to learn adaptive kernel scales while preserving the original graph structure. It reports consistent empirical gains over fixed-kernel GNNs and model-agnostic adaptive baselines (e.g., GAT-style) on kriging, imputation, and forecasting tasks, arguing that structure-preserving adaptation is superior to learning graphs from scratch.
Significance. If the theoretical result on approximation error is correct and the empirical superiority holds under the structure-preserving premise, the work could offer a lightweight, interpretable alternative to fully latent graph learning in settings where distance priors are reliable. The reproducible experimental protocol and direct comparison to both fixed and adaptive baselines would be strengths if the datasets and statistical tests are fully documented.
major comments (3)
- [Abstract, §3] Abstract and §3 (theoretical analysis): the claim of 'unavoidable approximation errors' from misspecified kernel parameters is central to motivating AdaKernel, yet the provided abstract gives no derivation details, assumptions on the GNN message-passing operator, or conditions under which the error bound is tight; without this, the necessity of the structure-preserving approach cannot be evaluated.
- [Experiments] Experimental section (kriging/imputation/forecasting results): the superiority over 'model-agnostic adaptive baselines' is presented as evidence that scale-only adaptation beats learning structures from scratch, but no stress-test datasets are described where the initial Euclidean/distance kernel has incorrect connectivity (e.g., non-Euclidean manifolds or misaligned sensors); this directly bears on the skeptic concern that the premise 'original kernel encodes dominant geometry' may not hold.
- [Experiments] Table/figure results (performance tables): reported gains lack mention of statistical significance tests, multiple random seeds, or variance across runs; if the improvements are within one standard deviation of baselines, the claim of consistent outperformance is weakened.
minor comments (2)
- [Method] Notation for kernel parameters (e.g., scale σ) should be defined explicitly at first use and kept consistent between theory and implementation sections.
- [Experiments] Dataset details (sensor counts, temporal lengths, train/val/test splits) are referenced but not fully tabulated; this hinders reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and indicate the planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (theoretical analysis): the claim of 'unavoidable approximation errors' from misspecified kernel parameters is central to motivating AdaKernel, yet the provided abstract gives no derivation details, assumptions on the GNN message-passing operator, or conditions under which the error bound is tight; without this, the necessity of the structure-preserving approach cannot be evaluated.
Authors: We agree that greater explicitness is needed. In the revision we will expand the abstract to include a concise statement of the main assumptions on the message-passing operator and the conditions under which the error bound holds. Section 3 will be augmented with a dedicated paragraph that states all assumptions upfront and provides a high-level derivation sketch, enabling readers to assess the tightness of the bound and the motivation for structure preservation. revision: yes
-
Referee: [Experiments] Experimental section (kriging/imputation/forecasting results): the superiority over 'model-agnostic adaptive baselines' is presented as evidence that scale-only adaptation beats learning structures from scratch, but no stress-test datasets are described where the initial Euclidean/distance kernel has incorrect connectivity (e.g., non-Euclidean manifolds or misaligned sensors); this directly bears on the skeptic concern that the premise 'original kernel encodes dominant geometry' may not hold.
Authors: We acknowledge the value of such stress tests. The current experiments target regimes in which distance priors are known to be informative, consistent with the theoretical premise. We did not construct deliberate counter-examples with fundamentally incorrect initial connectivity. In the revision we will add an explicit limitations paragraph that discusses the scope of applicability and the conditions under which the structure-preserving assumption may fail, thereby clarifying the boundary of the claimed superiority. revision: partial
-
Referee: [Experiments] Table/figure results (performance tables): reported gains lack mention of statistical significance tests, multiple random seeds, or variance across runs; if the improvements are within one standard deviation of baselines, the claim of consistent outperformance is weakened.
Authors: We agree that reporting practices should be strengthened. The revised manuscript will present all results as means and standard deviations over at least five random seeds, include paired statistical significance tests against the strongest baselines, and update the tables and figures accordingly. This will allow readers to judge whether the observed gains exceed run-to-run variability. revision: yes
Circularity Check
No circularity: derivation relies on independent theoretical claim and training-time optimization
full rationale
The paper's central claims rest on a stated theoretical proof that misspecified kernel parameters cause approximation errors in GNNs, followed by a structure-preserving learning procedure whose parameters are optimized via standard backpropagation on held-out data. No equation is shown to be definitionally equivalent to its own input, no fitted quantity is relabeled as a prediction, and no load-bearing step reduces to a self-citation chain. The structure-preserving strategy is presented as an explicit design choice rather than a mathematical necessity derived from prior self-work. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kriging convolutional networks
[Applebyet al., 2020 ] Gabriel Appleby, Linfeng Liu, and Li-Ping Liu. Kriging convolutional networks. InProceed- ings of the AAAI Conference on Artificial Intelligence, vol- ume 34, pages 3187–3194,
2020
-
[2]
Spatio-temporal data mining: A survey of problems and methods.ACM Computing Surveys, 51(4):1–41,
[Atluriet al., 2018 ] Gowtham Atluri, Anuj Karpatne, and Vipin Kumar. Spatio-temporal data mining: A survey of problems and methods.ACM Computing Surveys, 51(4):1–41,
2018
-
[3]
Adaptive graph convolutional recurrent network for traffic forecasting
[Baiet al., 2020 ] Lei Bai, Lina Yao, Can Li, Xianzhi Wang, and Can Wang. Adaptive graph convolutional recurrent network for traffic forecasting. InAdvances in Neural In- formation Processing Systems, volume 33, pages 17804– 17815,
2020
-
[4]
Relational inductive biases, deep learning, and graph networks
[Battagliaet al., 2018 ] Peter W Battaglia, Jessica B Ham- rick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261,
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Dynamit: a simulation-based system for traffic prediction
[Ben-Akivaet al., 1998 ] Moshe Ben-Akiva, Michel Bier- laire, Haris Koutsopoulos, and Rabi Mishalani. Dynamit: a simulation-based system for traffic prediction. InDAC- CORD short term forecasting workshop, volume
1998
-
[6]
Brits: Bidirectional recurrent im- putation for time series.Advances in neural information processing systems, 31,
[Caoet al., 2018 ] Wei Cao, Dong Wang, Jian Li, Hao Zhou, Lei Li, and Yitan Li. Brits: Bidirectional recurrent im- putation for time series.Advances in neural information processing systems, 31,
2018
-
[7]
Rossi, Kanak Mahadik, Sungchul Kim, and Hoda Eldardiry
[Chenet al., 2021 ] Hongjie Chen, Ryan A. Rossi, Kanak Mahadik, Sungchul Kim, and Hoda Eldardiry. Graph deep factors for forecasting with applications to cloud resource allocation. InProceedings of the 27th ACM SIGKDD Con- ference on Knowledge Discovery and Data Mining, KDD ’21, pages 106–116, New York, NY , USA,
2021
-
[8]
[Ciniet al., 2022 ] Andrea Cini, Ivan Marisca, and Cesare Alippi
Associa- tion for Computing Machinery. [Ciniet al., 2022 ] Andrea Cini, Ivan Marisca, and Cesare Alippi. Filling the Gaps: Multivariate time series impu- tation by graph neural networks. InInternational Confer- ence on Learning Representations,
2022
-
[9]
Spatial prediction and ordi- nary kriging.Mathematical geology, 20:405–421,
[Cressie, 1988] Noel Cressie. Spatial prediction and ordi- nary kriging.Mathematical geology, 20:405–421,
1988
-
[10]
John Wiley & Sons,
[Cressie, 2015] Noel Cressie.Statistics for spatial data. John Wiley & Sons,
2015
-
[11]
[Daley, 1993] Roger Daley.Atmospheric data analysis. Number
1993
-
[12]
Graph neural network-based anomaly detection in multivariate time series
[Deng and Hooi, 2021] Ailin Deng and Bryan Hooi. Graph neural network-based anomaly detection in multivariate time series. InProceedings of the AAAI Conference on Ar- tificial Intelligence, volume 35, pages 4027–4035,
2021
-
[13]
Learning from highly sparse spatio- temporal data
[Denget al., 2024 ] Leyan Deng, Chenwang Wu, Defu Lian, and Enhong Chen. Learning from highly sparse spatio- temporal data. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
2024
-
[14]
Neu- ral message passing for quantum chemistry
[Gilmeret al., 2017 ] Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neu- ral message passing for quantum chemistry. InInter- national Conference on Machine Learning, pages 1263–
2017
-
[15]
Decou- pling long-and short-term patterns in spatiotemporal infer- ence.IEEE Transactions on Neural Networks and Learn- ing Systems,
[Huet al., 2023 ] Junfeng Hu, Yuxuan Liang, Zhencheng Fan, Li Liu, Yifang Yin, and Roger Zimmermann. Decou- pling long-and short-term patterns in spatiotemporal infer- ence.IEEE Transactions on Neural Networks and Learn- ing Systems,
2023
-
[16]
[Jain and Wallace, 2019] Sarthak Jain and Byron C. Wallace. Attention is not Explanation. InProceedings of the 2019 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3543–3556, June
2019
-
[17]
Spatio-temporal graph neural networks for predictive learning in urban computing: A survey.IEEE Transac- tions on Knowledge and Data Engineering,
[Jinet al., 2023 ] Guangyin Jin, Yuxuan Liang, Yuchen Fang, Zezhi Shao, Jincai Huang, Junbo Zhang, and Yu Zheng. Spatio-temporal graph neural networks for predictive learning in urban computing: A survey.IEEE Transac- tions on Knowledge and Data Engineering,
2023
-
[18]
Network of tensor time series
[Jinget al., 2021 ] Baoyu Jing, Hanghang Tong, and Yada Zhu. Network of tensor time series. InProceedings of the Web Conference 2021, pages 2425–2437,
2021
-
[19]
Diffusion convolutional recurrent neural net- work: Data-driven traffic forecasting
[Liet al., 2018 ] Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. Diffusion convolutional recurrent neural net- work: Data-driven traffic forecasting. InInternational Conference on Learning Representations,
2018
-
[20]
Dynamic graph convolutional recurrent network for traffic prediction: Benchmark and solution.ACM Transactions on Knowledge Discovery from Data, 17(1):1–21,
[Liet al., 2023 ] Fuxian Li, Jie Feng, Huan Yan, Guangyin Jin, Fan Yang, Funing Sun, Depeng Jin, and Yong Li. Dynamic graph convolutional recurrent network for traffic prediction: Benchmark and solution.ACM Transactions on Knowledge Discovery from Data, 17(1):1–21,
2023
-
[21]
Intro- duction to gaussian processes.NATO ASI series F com- puter and systems sciences, 168:133–166,
[MacKay and others, 1998] David JC MacKay et al. Intro- duction to gaussian processes.NATO ASI series F com- puter and systems sciences, 168:133–166,
1998
-
[22]
Global-scale temperature pat- terns and climate forcing over the past six centuries.Na- ture, 392(6678):779–787,
[Mannet al., 1998 ] Michael E Mann, Raymond S Bradley, and Malcolm K Hughes. Global-scale temperature pat- terns and climate forcing over the past six centuries.Na- ture, 392(6678):779–787,
1998
-
[23]
Learning to reconstruct missing data from spa- tiotemporal graphs with sparse observations.Advances in Neural Information Processing Systems, 35:32069–32082,
[Mariscaet al., 2022 ] Ivan Marisca, Andrea Cini, and Ce- sare Alippi. Learning to reconstruct missing data from spa- tiotemporal graphs with sparse observations.Advances in Neural Information Processing Systems, 35:32069–32082,
2022
-
[24]
Principles of geo- statistics.Economic geology, 58(8):1246–1266,
[Matheron, 1963] Georges Matheron. Principles of geo- statistics.Economic geology, 58(8):1246–1266,
1963
-
[25]
Multivariate time series forecasting with latent graph inference.arXiv preprint arXiv:2203.03423,
[Satorraset al., 2022 ] Victor Garcia Satorras, Syama Sun- dar Rangapuram, and Tim Januschowski. Multivariate time series forecasting with latent graph inference.arXiv preprint arXiv:2203.03423,
-
[26]
Discrete graph structure learning for forecasting multiple time se- ries
[Shang and Chen, 2021] Chao Shang and Jie Chen. Discrete graph structure learning for forecasting multiple time se- ries. InInternational Conference on Learning Represen- tations,
2021
-
[27]
Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecast- ing
[Shaoet al., 2022 ] Zezhi Shao, Zhao Zhang, Fei Wang, Wei Wei, and Yongjun Xu. Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecast- ing. InProceedings of the 31st ACM International Con- ference on Information & Knowledge Management, pages 4454–4458,
2022
-
[28]
Exploring progress in mul- tivariate time series forecasting: Comprehensive bench- marking and heterogeneity analysis.IEEE Transactions on Knowledge and Data Engineering,
[Shaoet al., 2024 ] Zezhi Shao, Fei Wang, Yongjun Xu, Wei Wei, Chengqing Yu, Zhao Zhang, Di Yao, Tao Sun, Guangyin Jin, Xin Cao, et al. Exploring progress in mul- tivariate time series forecasting: Comprehensive bench- marking and heterogeneity analysis.IEEE Transactions on Knowledge and Data Engineering,
2024
-
[29]
Asymptotically efficient pre- diction of a random field with a misspecified covariance function.The Annals of Statistics, 16(1):55–63,
[Stein, 1988] Michael L Stein. Asymptotically efficient pre- diction of a random field with a misspecified covariance function.The Annals of Statistics, 16(1):55–63,
1988
-
[30]
A computer movie simulat- ing urban growth in the detroit region.Economic geogra- phy, 46(sup1):234–240,
[Tobler, 1970] Waldo R Tobler. A computer movie simulat- ing urban growth in the detroit region.Economic geogra- phy, 46(sup1):234–240,
1970
-
[31]
Graph attention networks
[Veliˇckovi´cet al., 2018 ] Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Li `o, and Yoshua Bengio. Graph attention networks. InInterna- tional Conference on Learning Representations,
2018
-
[32]
Deepfactors for forecasting
[Wanget al., 2019 ] Yuyang Wang, Alex Smola, Danielle Maddix, Jan Gasthaus, Dean Foster, and Tim Januschowski. Deepfactors for forecasting. InIn- ternational Conference on Machine Learning, pages 6607–6617. PMLR,
2019
-
[33]
Networked time series imputation via position-aware graph enhanced variational autoencoders
[Wanget al., 2023 ] Dingsu Wang, Yuchen Yan, Ruizhong Qiu, Yada Zhu, Kaiyu Guan, Andrew Margenot, and Hanghang Tong. Networked time series imputation via position-aware graph enhanced variational autoencoders. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2256– 2268,
2023
-
[34]
[Williams and Rasmussen, 2006] Christopher KI Williams and Carl Edward Rasmussen.Gaussian processes for ma- chine learning, volume
2006
-
[35]
Gaussian process kernels for pattern discovery and extrapolation
[Wilson and Adams, 2013] Andrew Wilson and Ryan Adams. Gaussian process kernels for pattern discovery and extrapolation. InInternational conference on machine learning, pages 1067–1075. PMLR,
2013
-
[36]
Graph wavenet for deep spatial-temporal graph modeling
[Wuet al., 2019 ] Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, and Chengqi Zhang. Graph wavenet for deep spatial-temporal graph modeling. InProceedings of the 28th International Joint Conference on Artificial Intelli- gence, pages 1907–1913,
2019
-
[37]
Spatial aggregation and temporal convolution networks for real-time kriging
[Wuet al., 2021b ] Yuankai Wu, Dingyi Zhuang, Mengying Lei, Aurelie Labbe, and Lijun Sun. Spatial aggregation and temporal convolution networks for real-time kriging. arXiv preprint arXiv:2109.12144,
-
[38]
Traversenet: Unifying space and time in message passing for traffic forecasting.IEEE Transactions on Neural Networks and Learning Systems,
[Wuet al., 2022 ] Zonghan Wu, Da Zheng, Shirui Pan, Quan Gan, Guodong Long, and George Karypis. Traversenet: Unifying space and time in message passing for traffic forecasting.IEEE Transactions on Neural Networks and Learning Systems,
2022
-
[39]
[Xuet al., 2023 ] Qianxiong Xu, Cheng Long, Ziyue Li, Sijie Ruan, Rui Zhao, and Zhishuai Li. Kits: Inductive spatio- temporal kriging with increment training strategy.arXiv preprint arXiv:2311.02565,
-
[40]
St- mvl: Filling missing values in geo-sensory time series data
[Yiet al., 2016 ] Xike Yi, Yu Zhang, and Linghe Kong. St- mvl: Filling missing values in geo-sensory time series data. InProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), pages 2704–2710,
2016
-
[41]
[Yinet al., 2022 ] Xueyan Yin, Feifan Li, Yanming Shen, Heng Qi, and Baocai Yin. Nodetrans: A graph transfer learning approach for traffic prediction.arXiv preprint arXiv:2207.01301,
-
[42]
Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting
[Yuet al., 2018 ] Bing Yu, Haoteng Yin, and Zhanxing Zhu. Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting. InProceedings of the 27th International Joint Conference on Artificial In- telligence, pages 3634–3640,
2018
-
[43]
Speckriging: Gnn-based secure cooperative spectrum sensing.IEEE Transactions on Wireless Communications, 21(11):9936– 9946,
[Zhanget al., 2022 ] Yan Zhang, Ang Li, Jiawei Li, Dianqi Han, Tao Li, Rui Zhang, and Yanchao Zhang. Speckriging: Gnn-based secure cooperative spectrum sensing.IEEE Transactions on Wireless Communications, 21(11):9936– 9946,
2022
-
[44]
Inconsistent estimation and asymptotically equal interpolations in model-based geo- statistics.Journal of the American Statistical Association, 99(465):250–261,
[Zhang, 2004] Hao Zhang. Inconsistent estimation and asymptotically equal interpolations in model-based geo- statistics.Journal of the American Statistical Association, 99(465):250–261,
2004
-
[45]
Gman: A graph multi- attention network for traffic prediction
[Zhenget al., 2020 ] Chuanpan Zheng, Xiaoliang Fan, Cheng Wang, and Jianzhong Qi. Gman: A graph multi- attention network for traffic prediction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 1234–1241,
2020
-
[46]
Increase: Inductive graph representation learning for spatio-temporal kriging
[Zhenget al., 2023 ] Chuanpan Zheng, Xiaoliang Fan, Cheng Wang, Jianzhong Qi, Chaochao Chen, and Long- biao Chen. Increase: Inductive graph representation learning for spatio-temporal kriging. InProceedings of the ACM Web Conference 2023, pages 673–683,
2023
-
[47]
A comparison of spatial semi- variogram estimators and corresponding ordinary kriging predictors.Technometrics, 33(1):77–91,
[Zimmerman and Zimmerman, 1991] Dale L Zimmerman and M Bridget Zimmerman. A comparison of spatial semi- variogram estimators and corresponding ordinary kriging predictors.Technometrics, 33(1):77–91,
1991
-
[48]
These datasets were chosen to evaluate the performance of the proposed methods in different spatiotemporal tasks, such as imputation, kriging, and forecasting
The datasets span multiple do- mains, including traffic speed, traffic flow, and air quality. These datasets were chosen to evaluate the performance of the proposed methods in different spatiotemporal tasks, such as imputation, kriging, and forecasting. E.2 Experimental Setup for Different Tasks For the imputation and forecasting tasks, we use a standard ...
2022
-
[49]
Imputation Task Details.We conduct experiments on sev- eral widely used datasets: METR-LA, PEMS-BAY , AQI, and PEMS03/04/07/08
These settings en- sure consistency and allow fair comparisons across tasks and datasets. Imputation Task Details.We conduct experiments on sev- eral widely used datasets: METR-LA, PEMS-BAY , AQI, and PEMS03/04/07/08. For METR-LA and PEMS-BAY , we ap- ply two missing data injection policies: •Block Missing:Randomly mask 5% of the data and simulate tempora...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.