Structure and Scale in Simplicial Sequence Modelling
Pith reviewed 2026-06-28 17:11 UTC · model grok-4.3
The pith
Small transformers on hidden Markov model tasks show correlated scaling between performance and internal belief encodings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
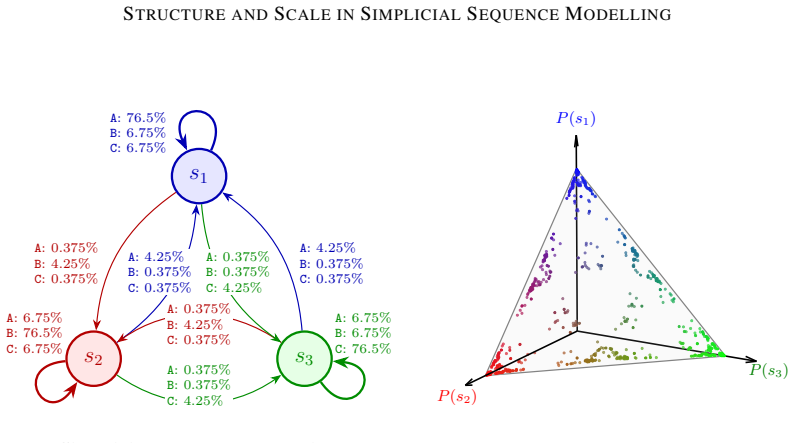
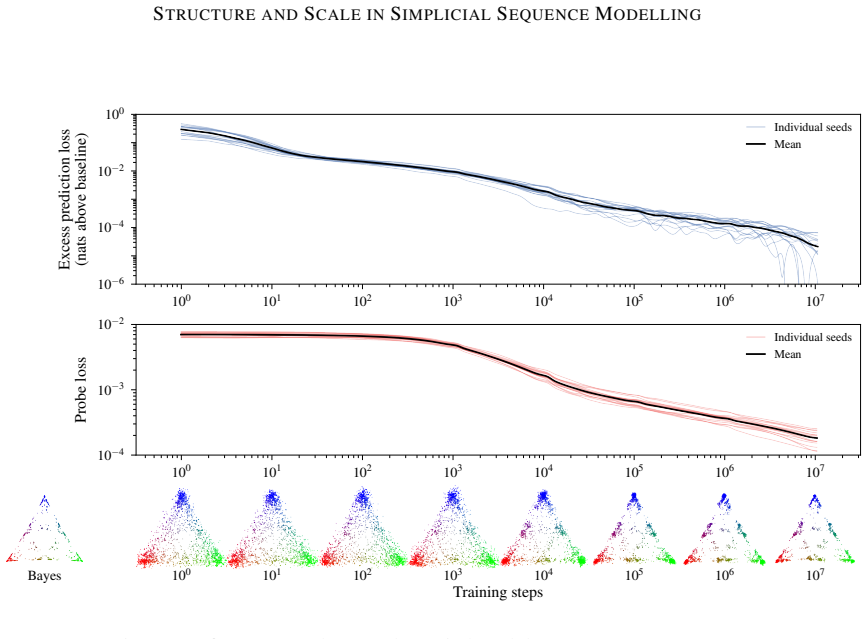
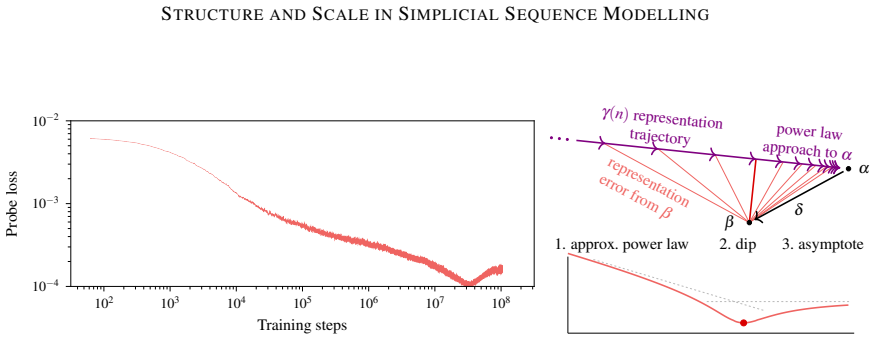
We find a correlation between scaling patterns in performance and representations in small transformers trained to predict the outputs of a hidden Markov model, for which residual activations are known to linearly encode a belief distribution over latent states in a probability simplex.
What carries the argument
Linear encoding of a belief distribution over latent states inside the residual activations of the transformer.
If this is right
- Predictable changes in behavior with scale can be traced to predictable changes in specific internal representations.
- Scaling laws may be explained by the scaling properties of the belief-encoding mechanism rather than by opaque capacity increases.
- The same correlation could appear in other sequence tasks where latent-state beliefs can be measured in activations.
Where Pith is reading between the lines
- The HMM setting could serve as a controllable testbed for studying how representation scaling produces capability jumps in larger models.
- If the correlation generalizes, interventions that alter the linear encoding might be used to predict or control scaling behavior.
- Neighbouring questions include whether non-linear encodings or other circuits show their own distinct scaling patterns in the same models.
Load-bearing premise
The linear encoding of belief distributions in residual activations is the relevant internal structure whose scaling pattern correlates with performance scaling.
What would settle it
An observation that the scaling trajectory of performance metrics does not match the scaling trajectory of the linear belief-encoding quality in the residual activations would falsify the reported correlation.
Figures
read the original abstract
Modern large-scale deep learning exhibits two striking empirical phenomena: behavioural scaling laws (predictable performance gains with increasing scale) and emergent mechanisms (structured internal representations and circuits in deep neural networks). We hypothesise that these two phenomena are connected: that predictable changes in behaviour are the result of predictable changes in internal computational structure. In this paper, we report preliminary evidence of such a connection. We find a correlation between scaling patterns in performance and representations in small transformers trained to predict the outputs of a hidden Markov model, for which residual activations are known to linearly encode a belief distribution over latent states in a probability simplex.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports preliminary evidence of a connection between behavioral scaling laws and internal representational structure. Small transformers are trained to predict outputs of a hidden Markov model (HMM) whose residual activations are already known from prior work to linearly encode a belief distribution over latent states in a probability simplex; the authors observe a correlation between scaling patterns in task performance and in these representations.
Significance. If the reported correlation is robust, the work supplies a controlled, low-dimensional testbed in which performance scaling can be directly linked to measurable changes in internal structure. This is a useful step toward mechanistic accounts of scaling laws, especially given the explicit use of an established linear encoding result rather than post-hoc circuit discovery.
minor comments (3)
- [Abstract] The abstract states the existence of a correlation but supplies no quantitative details (e.g., correlation coefficient, number of scales tested, controls for random seeds). The main text should include these metrics in a dedicated results section or table so readers can evaluate the strength of the evidence without ambiguity.
- [Methods / Experimental Setup] Clarify whether the observed representational scaling is measured on the same residual stream activations whose linear encoding of the belief simplex was established in prior work, or on a different layer/metric. A short methods paragraph or figure caption should make this explicit.
- [Discussion] The manuscript frames the result as 'preliminary evidence.' Consider adding a brief limitations paragraph that states what would constitute a stronger test (e.g., causal intervention on the belief encoding or replication on a second HMM topology).
Simulated Author's Rebuttal
We thank the referee for their review and positive assessment of the manuscript. The recognition that the work provides a controlled testbed linking performance scaling to measurable internal structure is encouraging and aligns with the paper's goals. No major comments appear in the report.
Circularity Check
No significant circularity identified
full rationale
The paper reports an empirical correlation between performance scaling and representation scaling in transformers trained on HMM outputs, where the linear belief encoding in residuals is cited as established prior knowledge. No derivation chain, equations, fitted parameters renamed as predictions, or self-referential definitions are present in the provided text. The central claim is framed as a preliminary observation rather than a first-principles result that reduces to its inputs by construction. The referenced encoding is treated as external input, not generated internally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Residual activations in the transformer linearly encode a belief distribution over latent states in a probability simplex for the HMM task.
Reference graph
Works this paper leans on
-
[1]
Mitigating goal misgeneralization via minimax regret.Reinforcement Learning Journal, 2025
Karim Abdel Sadek, Matthew Farrugia-Roberts, Usman Anwar, Hannah Erlebach, Christian Schroeder de Witt, David Krueger, and Michael Dennis. Mitigating goal misgeneralization via minimax regret.Reinforcement Learning Journal, 2025. Cited on page 5
2025
-
[2]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. Preprint arXiv:1610.01644, 2018. Cited on page 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
AI and compute
Dario Amodei and Danny Hernandez. AI and compute. OpenAI blog, 2018. Cited on page 1
2018
-
[4]
Jingmin An, Wei Liu, Qian Wang, and Fang Fang. Time travel engine: A shared latent chronological manifold enables historical navigation in large language models. Preprint arXiv:2601.06437, 2026. Cited on page 1
-
[5]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. Published as a conference paper at ICLR 2015. Preprint arXiv:1409.0473, 2015. Cited on page 1
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
Chinchilla scaling: A replication attempt
Tamay Besiroglu, Ege Erdil, Matthew Barnett, and Josh You. Chinchilla scaling: A replication attempt. Preprint arXiv:2404.10102, 2024. Cited on page 1
-
[7]
JAX: composable transformations of Python+NumPy programs
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dou- gal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs. GitHub reposi- tory, 2018. URL http://github.com/jax-ml/jax. Cited on page 2
2018
-
[8]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agar- wal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, S...
1901
-
[9]
Interpreting emergent planning in model-free reinforcement learning
Thomas Bush, Stephen Chung, Usman Anwar, Adri `a Garriga-Alonso, and David Krueger. Interpreting emergent planning in model-free reinforcement learning. InInternational Con- ference on Learning Representations, 2025. Cited on page 1
2025
-
[10]
Dynamics of transient structure in in-context linear regression transformers
Liam Carroll, Jesse Hoogland, Matthew Farrugia-Roberts, and Daniel Murfet. Dynamics of transient structure in in-context linear regression transformers. Preprint arXiv:2501.17745,
-
[11]
6 STRUCTURE ANDSCALE INSIMPLICIALSEQUENCEMODELLING
Cited on page 5. 6 STRUCTURE ANDSCALE INSIMPLICIALSEQUENCEMODELLING
-
[12]
Leavitt, and Naomi Saphra
Angelica Chen, Ravid Shwartz-Ziv, Kyunghyun Cho, Matthew L. Leavitt, and Naomi Saphra. Sudden drops in the loss: Syntax acquisition, phase transitions, and simplicity bias in MLMs. InInternational Conference on Learning Representations, 2024. Cited on page 5
2024
-
[13]
Dynamical versus Bayesian phase transitions in a toy model of superposition
Zhongtian Chen, Edmund Lau, Jake Mendel, Susan Wei, and Daniel Murfet. Dynamical versus Bayesian phase transitions in a toy model of superposition. Preprint arXiv:2310.06301, 2023. Cited on page 5
-
[14]
Cires ¸an, Ueli Meier, Jonathan Masci, Luca M
Dan C. Cires ¸an, Ueli Meier, Jonathan Masci, Luca M. Gambardella, and J ¨urgen Schmidhu- ber. Flexible, high performance convolutional neural networks for image classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, volume 2, pages 1237–1242, 2011. Cited on page 1
2011
-
[15]
Quantifying generalization in reinforcement learning
Karl Cobbe, Oleg Klimov, Chris Hesse, Taehoon Kim, and John Schulman. Quantifying generalization in reinforcement learning. InProceedings of the 36th International Conference on Machine Learning, pages 1282–1289, 2019. Cited on page 5
2019
-
[16]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. InProceedings of the 37th International Conference on Machine Learning, pages 2048–2056, 2020. Cited on page 5
2048
-
[17]
Edelman, Eran Malach, and Surbhi Goel
Ezra Edelman, Nikolaos Tsilivis, Benjamin L. Edelman, Eran Malach, and Surbhi Goel. The evolution of statistical induction heads: In-context learning markov chains. InAdvances in Neural Information Processing Systems 37, pages 64273–64311, 2024. Cited on page 5
2024
-
[18]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[19]
Cited on pages 1 and 5
-
[20]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread, 2022. Cited on pages 1 and 5
2022
-
[21]
Stagewise reinforcement learning and the geometry of the regret landscape
Chris Elliott, Einar Urdshals, David Quarel, Matthew Farrugia-Roberts, and Daniel Mur- fet. Stagewise reinforcement learning and the geometry of the regret landscape. Preprint arXiv:2601.07524, 2026. Cited on page 5
-
[22]
Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark
Joshua Engels, Eric J. Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all lan- guage model features are one-dimensionally linear. InInternational Conference on Learning Representations, 2025. Cited on page 1
2025
-
[23]
Hi, JAX!
Matthew Farrugia-Roberts. “Hi, JAX!”: An introduction to JAX for deep learning research. GitHub repository, 2026. URL https://github.com/matomatical/hijax. Cited on page 2. 7 STRUCTURE ANDSCALE INSIMPLICIALSEQUENCEMODELLING
2026
-
[24]
When models manipulate manifolds: The geometry of a counting task
Wes Gurnee, Emmanuel Ameisen, Isaac Kauvar, Julius Tarng, Adam Pearce, Chris Olah, and Joshua Batson. When models manipulate manifolds: The geometry of a counting task. Preprint arXiv:2601.04480, 2026. Cited on page 1
-
[25]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. Cited on page 1
2016
-
[26]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kia- ninejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. Preprint arXiv:1712.00409, 2017. Cited on page 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Thomas Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aure- lia Guy, Simon Osindero, Kar´en Simonyan, Erich Elsen, Oriol Vinyals, Jack Rae, and Lauren...
2022
-
[28]
Loss landscape degeneracy and stagewise development in transformers.Trans- actions on Machine Learning Research, 2025
Jesse Hoogland, George Wang, Matthew Farrugia-Roberts, Liam Carroll, Susan Wei, and Daniel Murfet. Loss landscape degeneracy and stagewise development in transformers.Trans- actions on Machine Learning Research, 2025. Cited on page 5
2025
-
[29]
Marcus Hutter. Learning curve theory. Preprint arXiv:2102.04074, 2021. Cited on page 1
-
[30]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. Preprint arXiv:2001.08361, 2020. Cited on pages 1 and 5
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[31]
Visualizing and understanding recurrent networks
Andrej Karpathy, Justin Johnson, and Li Fei-Fei. Visualizing and understanding recurrent networks. InInternational Conference on Learning Representations (Workshop Track), 2016. Cited on page 1
2016
-
[32]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. InAdvances in Neural Information Processing Systems 25, pages 1097–1105, 2012. Cited on page 1
2012
-
[33]
Sharkey, Jacob Pfau, and David Krueger
Lauro Langosco, Jack Koch, Lee D. Sharkey, Jacob Pfau, and David Krueger. Goal misgener- alization in deep reinforcement learning. InProceedings of the 39th International Conference on Machine Learning, pages 12004–12019, 2022. Cited on page 5
2022
-
[34]
Hopkins, David Bau, Fernanda Vi ´egas, Hanspeter Pfister, and Martin Wattenberg
Kenneth Li, Aspen K. Hopkins, David Bau, Fernanda Vi ´egas, Hanspeter Pfister, and Martin Wattenberg. Emergent world representations: Exploring a sequence model trained on a syn- thetic task. InInternational Conference on Learning Representations, 2023. Cited on page 1
2023
-
[35]
Marzen and James P
Sarah E. Marzen and James P. Crutchfield. Nearly maximally predictive features and their dimensions.Physical Review E, 95(5):051301, 2017. Cited on page 2. 8 STRUCTURE ANDSCALE INSIMPLICIALSEQUENCEMODELLING
2017
-
[36]
Michaud, Ziming Liu, Uzay Girit, and Max Tegmark
Eric J. Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling. InAdvances in Neural Information Processing Systems 36, pages 28699–28722, 2023. Cited on page 1
2023
-
[37]
A mechanistic interpretability analysis of grokking
Neel Nanda and Tom Lieberum. A mechanistic interpretability analysis of grokking. AI Alignment Forum, August 2022. Cited on pages 1 and 5
2022
-
[38]
Progress mea- sures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress mea- sures for grokking via mechanistic interpretability. InInternational Conference on Learning Representations, 2023. Cited on pages 1 and 5
2023
-
[39]
Emergent linear representations in world models of self-supervised sequence models
Neel Nanda, Andrew Lee, and Martin Wattenberg. Emergent linear representations in world models of self-supervised sequence models. InProceedings of the 6th BlackboxNLP Work- shop: Analyzing and Interpreting Neural Networks for NLP, pages 16–30. Association for Computational Linguistics, 2023. Cited on page 1
2023
-
[40]
A pragmatic vision for interpretability
Neel Nanda, Josh Engels, Arthur Conmy, Senthooran Rajamanoharan, Bilal Chughtai, Callum McDougall, J ´anos Kram ´ar, and Lewis Smith. A pragmatic vision for interpretability. AI Alignment Forum, December 2025. Cited on page 1
2025
-
[41]
The dark matter of neural networks?Transformer Circuits Thread, July 2024
Chris Olah. The dark matter of neural networks?Transformer Circuits Thread, July 2024. Cited on page 1
2024
-
[42]
Zoom in: An introduction to circuits.Distill, 5(3):e00024.001, March 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 5(3):e00024.001, March 2020. Cited on page 1
2020
-
[43]
In-context learning and induction heads.Transformer Circuits Thread, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Ka- plan, Sam McCandlish,...
2022
-
[44]
GPT-4 system card
OpenAI. GPT-4 system card. Technical report, OpenAI, 2023. Cited on page 1
2023
-
[45]
GPT-5 system card
OpenAI. GPT-5 system card. Technical report, OpenAI, 2025. Cited on page 1
2025
-
[46]
In-context learning through the Bayesian prism
Madhur Panwar, Kabir Ahuja, and Navin Goyal. In-context learning through the Bayesian prism. InInternational Conference on Learning Representations, 2024. Cited on page 5
2024
-
[47]
Competition dynamics shape algorithmic phases of in-context learning
Core Francisco Park, Ekdeep Singh Lubana, and Hidenori Tanaka. Competition dynamics shape algorithmic phases of in-context learning. InInternational Conference on Learning Representations, pages 66381–66433, 2025. Cited on page 5
2025
-
[48]
Simon Pepin Lehalleur, Jesse Hoogland, Matthew Farrugia-Roberts, Susan Wei, Alexander Gietelink Oldenziel, George Wang, Liam Carroll, and Daniel Murfet. You are what you eat– AI alignment requires understanding how data shapes structure and generalisation. Preprint arXiv:2502.05475, 2025. Cited on page 5. 9 STRUCTURE ANDSCALE INSIMPLICIALSEQUENCEMODELLING
-
[49]
Riechers, Daniel Filan, and Adam S
Mateusz Piotrowski, Paul M. Riechers, Daniel Filan, and Adam S. Shai. Constrained belief updates explain geometric structures in transformer representations. InProceedings of the 42nd International Conference on Machine Learning, pages 49399–49419, 2025. Cited on pages 1 and 4
2025
-
[50]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. Preprint arXiv:2201.02177,
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Sometimes I am a tree: Data drives unsta- ble hierarchical generalization in LMs
Tian Qin, Naomi Saphra, and David Alvarez-Melis. Sometimes I am a tree: Data drives unsta- ble hierarchical generalization in LMs. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 11722–11740, 2025. Cited on page 5
2025
-
[52]
Learning to Generate Reviews and Discovering Sentiment
Alec Radford, Rafal Jozefowicz, and Ilya Sutskever. Learning to generate reviews and discov- ering sentiment. Preprint arXiv:1704.01444, 2017. Cited on page 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. Technical report, OpenAI, 2018. Cited on page 1
2018
-
[54]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019. Cited on page 1
2019
-
[55]
Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression
Allan Ravent ´os, Mansheej Paul, Feng Chen, and Surya Ganguli. Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression. InAdvances in Neural Information Processing Systems 36, pages 14228–14246, 2023. Cited on page 5
2023
-
[56]
Paul M. Riechers, Thomas J. Elliott, and Adam S. Shai. Neural networks leverage nomi- nally quantum and post-quantum representations. Preprint arXiv:2507.07432, 2025. Cited on page 1
-
[57]
Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit
Jonathan S. Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit. A constructive prediction of the generalization error across scales. InInternational Conference on Learning Representations, 2020. Cited on page 1
2020
-
[58]
The AI index 2026 annual report
Sha Sajadieh, Loredana Fattorini, Raymond Perrault, Yolanda Gil, Vanessa Parli, Lapo Santar- lasci, Juan Pava, Nestor Maslej, Russ Altman, Erik Brynjolfsson, Carla Brodley, Jack Clark, Virginia Dignum, Vipin Kumar, James Landay, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Elham Tabassi, Russell Wald, Toby Walsh, and Dan Weld. The AI inde...
2026
-
[59]
Shai, Sarah E
Adam S. Shai, Sarah E. Marzen, Lucas Teixeira, Alexander Gietelink Oldenziel, and Paul M. Riechers. Transformers represent belief state geometry in their residual stream. InAdvances in Neural Information Processing Systems 37, pages 75012–75034, 2024. Cited on pages 1, 2, 3, and 4
2024
-
[60]
A neural scaling law from the dimension of the data manifold
Utkarsh Sharma and Jared Kaplan. A neural scaling law from the dimension of the data manifold. Preprint arXiv:2004.10802, 2020. Cited on page 1. 10 STRUCTURE ANDSCALE INSIMPLICIALSEQUENCEMODELLING
-
[61]
The transient nature of emergent in-context learning in transformers
Aaditya Singh, Stephanie Chan, Ted Moskovitz, Erin Grant, Andrew Saxe, and Felix Hill. The transient nature of emergent in-context learning in transformers. InAdvances in Neural Information Processing Systems 36, pages 27801–27819, 2023. Cited on page 5
2023
-
[62]
Planning in a recurrent neural network that plays Sokoban
Mohammad Taufeeque, Philip Quirke, Maximilian Li, Chris Cundy, Aaron David Tucker, Adam Gleave, and Adri `a Garriga-Alonso. Planning in a recurrent neural network that plays Sokoban. Preprint arXiv:2407.15421, 2024. Cited on page 1
-
[63]
Path channels and plan extension kernels: a mechanistic description of planning in a Sokoban RNN
Mohammad Taufeeque, Aaron David Tucker, Adam Gleave, and Adri `a Garriga-Alonso. Path channels and plan extension kernels: a mechanistic description of planning in a Sokoban RNN. InInternational Conference on Learning Representations, 2026. Cited on page 1
2026
-
[64]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Infor- mation Processing Systems 30, pages 5998–6008, 2017. Cited on page 1
2017
-
[65]
Loss landscape geometry reveals stagewise development of transformers
George Wang, Matthew Farrugia-Roberts, Jesse Hoogland, Liam Carroll, Susan Wei, and Daniel Murfet. Loss landscape geometry reveals stagewise development of transformers. InHigh-dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning,
2024
-
[66]
Dif- ferentiation and specialization of attention heads via the refined local learning coefficient
George Wang, Jesse Hoogland, Stan van Wingerden, Zach Furman, and Daniel Murfet. Dif- ferentiation and specialization of attention heads via the refined local learning coefficient. In International Conference on Learning Representations, 2025. Cited on page 5
2025
-
[67]
Interpretability in the wild: A circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: A circuit for indirect object identification in GPT-2 small. In International Conference on Learning Representations, 2023. Cited on page 1
2023
-
[68]
The clock and the pizza: Two stories in mechanistic explanation of neural networks
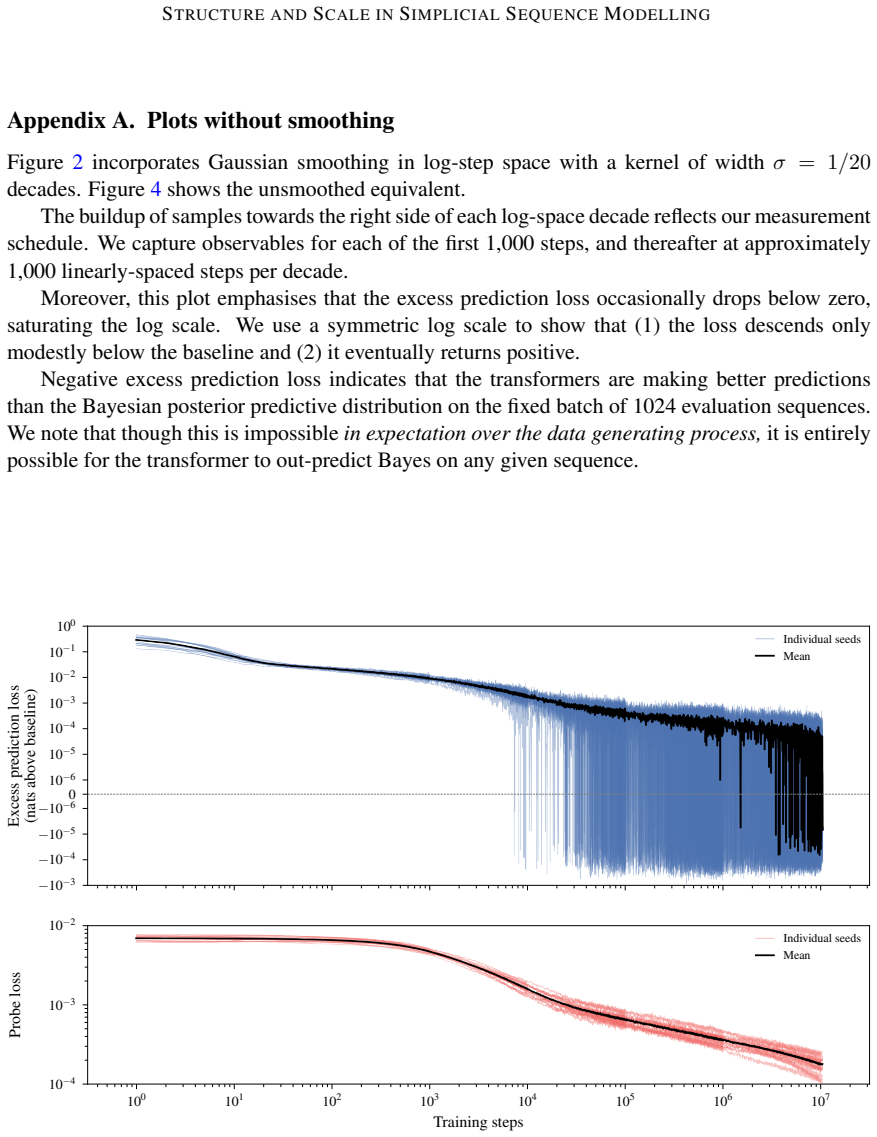
Ziqian Zhong, Ziming Liu, Max Tegmark, and Jacob Andreas. The clock and the pizza: Two stories in mechanistic explanation of neural networks. InAdvances in Neural Information Processing Systems 36, pages 27223–27250, 2023. Cited on page 1. 11 STRUCTURE ANDSCALE INSIMPLICIALSEQUENCEMODELLING Appendix A. Plots without smoothing Figure 2 incorporates Gaussia...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.