MomentKV: Closing the Directional Gap in KV Cache Eviction for Long-Context Inference
Pith reviewed 2026-06-28 16:05 UTC · model grok-4.3
The pith
MomentKV tracks compact moment statistics on evicted KV tokens to correct directional mismatch during long-context inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
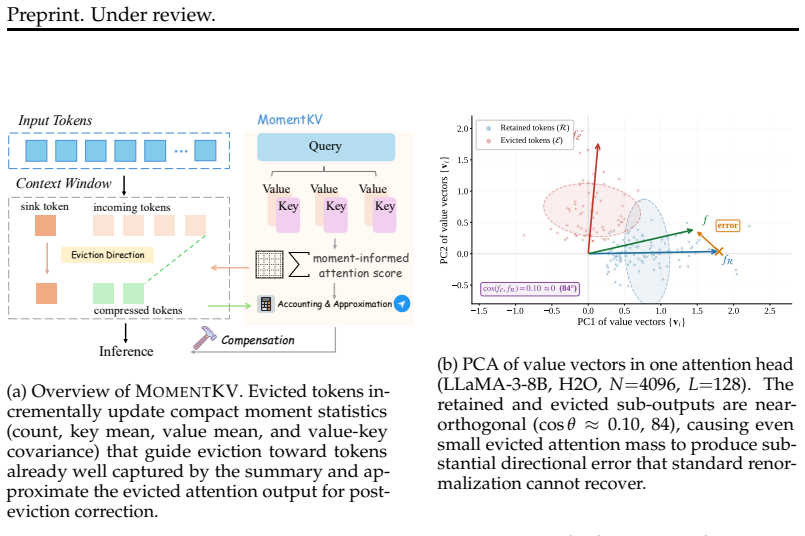
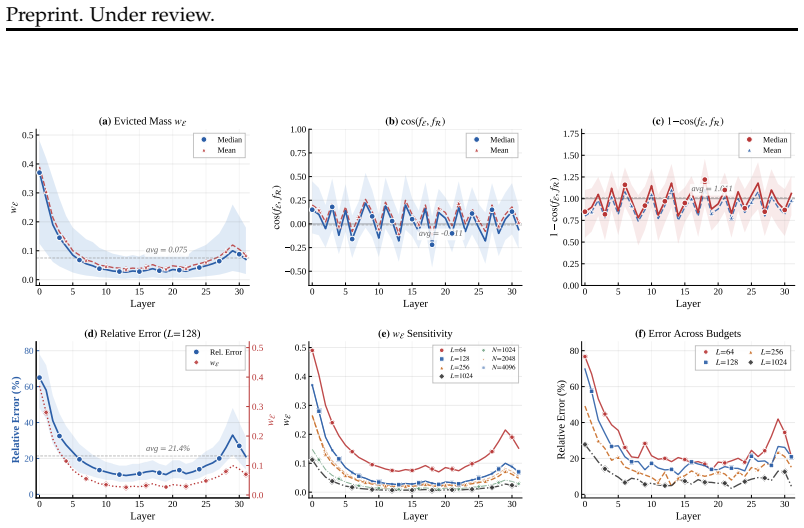
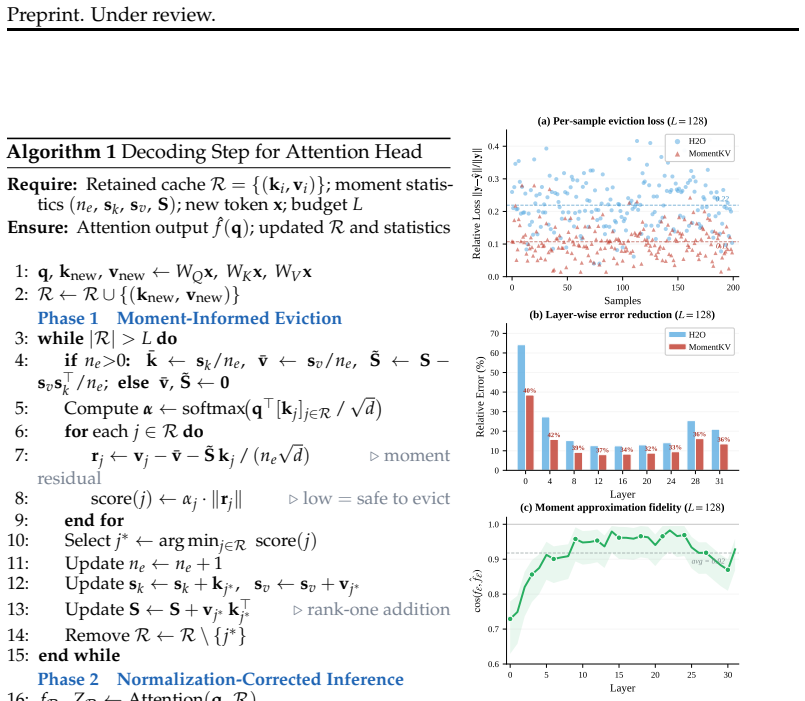
The central claim is that directional mismatch between retained and evicted token sets, rather than residual attention mass alone, is the dominant source of error in KV cache eviction. MomentKV maintains count, key mean, value mean, and value-key covariance over the evicted tokens; during eviction these moments identify tokens already captured by the summary, and during inference they yield a closed-form first-order approximation of the evicted contribution to attention, forming a mutually reinforcing loop that improves output quality at fixed cache budgets.
What carries the argument
Compact moment statistics (count, key mean, value mean, value-key covariance) maintained over the evicted token set, used both to enforce geometric regularity during eviction and to compute a closed-form correction during inference.
If this is right
- At any fixed cache budget the method produces higher-quality outputs than eviction policies that only minimize residual attention mass.
- The largest accuracy gains appear under aggressive compression ratios where directional mismatch is most pronounced.
- The same moment statistics can be updated incrementally with constant memory overhead independent of the number of evicted tokens.
- The eviction policy and the inference correction become mutually reinforcing, so better selection improves the correction and vice versa.
Where Pith is reading between the lines
- The approach may extend to other attention-based architectures if the first-order moment approximation remains stable under different head dimensions or position encodings.
- Tracking higher-order moments could further reduce residual directional error if the first-order correction proves insufficient on some tasks.
- Because the correction is closed-form, it could be fused into existing attention kernels with negligible added latency.
Load-bearing premise
The moment statistics supply a first-order approximation of the evicted attention output that stays accurate enough to reinforce the selective eviction policy across the full generation.
What would settle it
Measure whether the first-order moment-based correction error exceeds a small threshold on held-out long sequences; if the approximation error grows with sequence length or model scale while output degradation persists, the claim fails.
Figures
read the original abstract
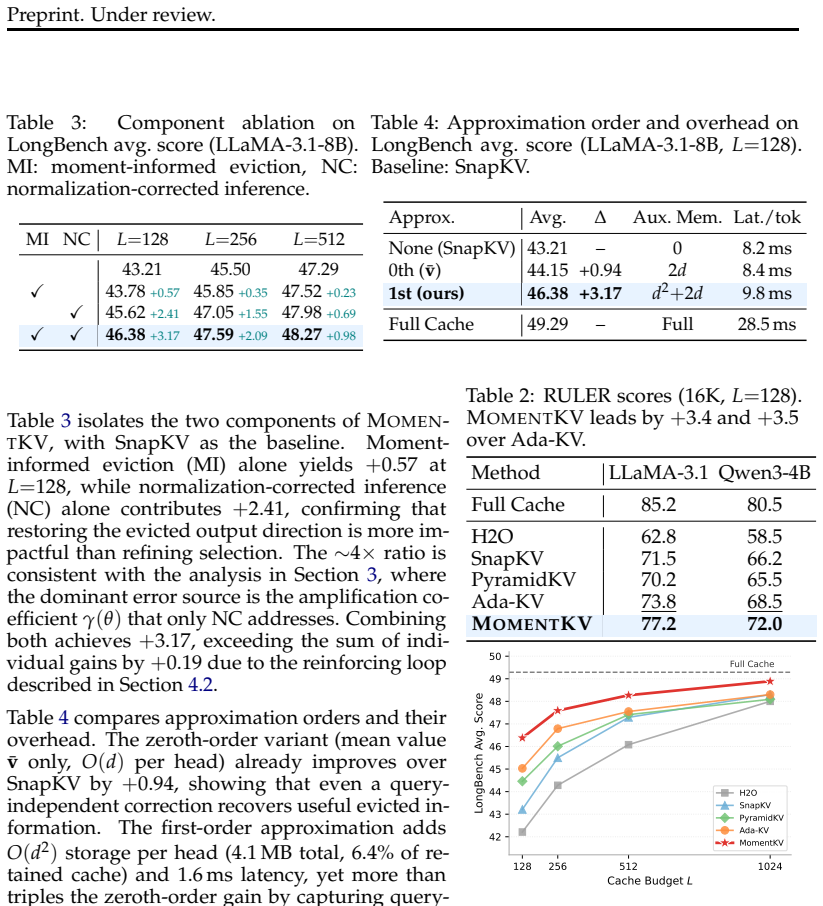
Autoregressive decoding in Transformer-based language models relies on the KV cache, whose memory footprint grows linearly with sequence length and becomes the primary bottleneck for long-context inference. KV cache eviction addresses this by retaining a fixed-size subset of key-value pairs and discarding the rest. We identify that a primary source of output degradation is not the residual attention mass on evicted tokens, which existing methods already minimize, but a directional mismatch between the retained and evicted token sets. Specifically, the evicted tokens in practice are often near-orthogonal to the retained ones. Thus, even a small evicted mass could have an oversized impact on the resulting direction distribution and amplify into substantial output error. This reveals a fundamental limit in existing strategies. To address this, we propose MomentKV, which maintains compact, small-size moment statistics over the evicted token set, including a count, key mean, value mean, and value-key covariance. During eviction, the moment statistics is leveraged to identify tokens already well aligned with and captured by the accumulated summary, keeping the evicted set geometrically regular. During inference, they yield a closed-form first-order approximation of the evicted attention output, forming a mutually reinforcing loop between selective eviction and accurate correction. On LongBench and RULER with LLaMA-3.1-8B-Instruct and Qwen3-4B-Instruct, MomentKV outperforms all baselines at every cache budget, with the largest gains under aggressive compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that KV cache eviction degrades output primarily due to directional mismatch (evicted tokens often near-orthogonal to retained ones) rather than residual attention mass on evicted tokens. It introduces MomentKV, which maintains compact moment statistics (count, key mean, value mean, value-key covariance) over the evicted set. These statistics guide selective eviction to keep the evicted set geometrically regular and enable a closed-form first-order approximation of the evicted attention output during inference, forming a mutually reinforcing loop. Experiments on LongBench and RULER with LLaMA-3.1-8B-Instruct and Qwen3-4B-Instruct show outperformance over all baselines at every cache budget, with largest gains under aggressive compression.
Significance. If the directional-mismatch diagnosis holds and the moment-based first-order correction proves sufficiently accurate, the work could address a previously untargeted geometric source of error in KV eviction, enabling more reliable aggressive compression for long-context inference without the accuracy cliffs seen in prior mass-minimization approaches.
major comments (2)
- [Abstract] Abstract: The central diagnosis that 'evicted tokens in practice are often near-orthogonal to the retained ones' and produce an 'oversized impact on the resulting direction distribution' is load-bearing for the claim of a 'fundamental limit in existing strategies,' yet the abstract supplies no quantitative support, geometric analysis, or controls to establish this orthogonality or its effect size.
- [Abstract] Abstract: The claim that the maintained moment statistics 'yield a closed-form first-order approximation of the evicted attention output' (forming the 'mutually reinforcing loop') is presented without the approximation formula, its derivation, or any error analysis, which is required to assess whether the approximation is accurate enough to support the proposed correction mechanism.
minor comments (1)
- [Abstract] The phrasing 'the moment statistics is leveraged' contains a subject-verb agreement issue that should be corrected for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the abstract should better substantiate its central claims and will revise it accordingly while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central diagnosis that 'evicted tokens in practice are often near-orthogonal to the retained ones' and produce an 'oversized impact on the resulting direction distribution' is load-bearing for the claim of a 'fundamental limit in existing strategies,' yet the abstract supplies no quantitative support, geometric analysis, or controls to establish this orthogonality or its effect size.
Authors: We acknowledge that the abstract presents the orthogonality diagnosis without supporting numbers or controls. The manuscript body contains the requested geometric analysis (cosine-similarity distributions and directional-impact ablations) that establish the effect size. To make the abstract self-contained, we will insert a concise quantitative statement drawn from those results. revision: yes
-
Referee: [Abstract] Abstract: The claim that the maintained moment statistics 'yield a closed-form first-order approximation of the evicted attention output' (forming the 'mutually reinforcing loop') is presented without the approximation formula, its derivation, or any error analysis, which is required to assess whether the approximation is accurate enough to support the proposed correction mechanism.
Authors: The abstract states the existence of the closed-form first-order approximation without displaying the formula or error bounds. The derivation (via moment-based linearization of the attention output) and accompanying error analysis appear in the main text. We will revise the abstract to include the compact approximation expression and a one-sentence reference to the bounded-error result. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper identifies a directional mismatch in evicted KV tokens as the core issue and introduces moment statistics (count, means, covariance) to guide eviction and provide a closed-form first-order correction. No equations, fitted parameters, or self-citations are shown that reduce the claimed approximation, the mutually reinforcing loop, or the performance gains to a self-defined quantity or tautology. The geometric observation and moment-based design remain independent of the target outputs, with the accuracy of the approximation explicitly treated as an empirical matter rather than an internal necessity. This matches the default expectation of self-contained construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Evicted tokens are often near-orthogonal to retained tokens, producing directional mismatch that amplifies output error beyond residual mass alone.
Reference graph
Works this paper leans on
-
[1]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, and Wen Xiao. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.ArXiv, abs/2406.02069,
-
[2]
Rethinking attention with performers.arXiv preprint arXiv:2009.14794,
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers.arXiv preprint arXiv:2009.14794,
Pith/arXiv arXiv 2009
-
[3]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691,
-
[4]
A simple and effective l 2 norm-based strategy for kv cache compression
Alessio Devoto, Yu Zhao, Simone Scardapane, and Pasquale Minervini. A simple and effective l 2 norm-based strategy for kv cache compression. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 18476–18499,
2024
-
[5]
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference.arXiv preprint arXiv:2407.11550,
-
[6]
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. Identify critical kv cache in llm inference from an output perturbation perspective.arXiv preprint arXiv:2502.03805,
-
[7]
Raghavv Goel, Junyoung Park, Mukul Gagrani, Dalton Jones, Matthew Morse, Harper Langston, Mingu Lee, and Chris Lott. Caote: Kv cache selection for llms via attention output error-based token eviction.arXiv preprint arXiv:2504.14051,
-
[8]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[9]
10 Preprint. Under review. Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654,
-
[10]
Compute or load kv cache? why not both?arXiv preprint arXiv:2410.03065,
Shuowei Jin, Xueshen Liu, Qingzhao Zhang, and Z Morley Mao. Compute or load kv cache? why not both?arXiv preprint arXiv:2410.03065,
-
[11]
Haoyang Li, Yiming Li, Anxin Tian, Tianhao Tang, Zhanchao Xu, Xuejia Chen, Nicole Hu, Wei Dong, Qing Li, and Lei Chen. A survey on large language model acceleration based on kv cache management.arXiv preprint arXiv:2412.19442, 2024a. Yu Li, Tian Lan, and Zhengling Qi. When right meets wrong: Bilateral context conditioning with reward-confidence correction...
-
[12]
Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr F. Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.ArXiv, abs/2404.14469, 2024b. URL https://api.semanticscholar. org/CorpusID:269303164. Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo X...
-
[13]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. arXiv preprint arXiv:2402.02750,
-
[14]
Piotr Nawrot, Adrian Ła´ncucki, Marcin Chochowski, David Tarjan, and Edoardo M Ponti. Dynamic memory compression: Retrofitting llms for accelerated inference.arXiv preprint arXiv:2403.09636,
-
[15]
Tianyu Ruan and Shihua Zhang. Towards understanding how attention mechanism works in deep learning.arXiv preprint arXiv:2412.18288,
-
[16]
Zheng Wang, Boxiao Jin, Zhongzhi Yu, and Minjia Zhang. Model tells you where to merge: Adaptive kv cache merging for llms on long-context tasks.ArXiv, abs/2407.08454,
-
[17]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis
URLhttps://api.semanticscholar.org/CorpusID:271097687. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient stream- ing language models with attention sinks.arXiv preprint arXiv:2309.17453,
-
[18]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[19]
Kv cache compression, but what must we give in return? a comprehensive benchmark of long context capable approaches
Jiayi Yuan, Hongyi Liu, Shaochen Zhong, Yu-Neng Chuang, Songchen Li, Guanchu Wang, Duy Le, Hongye Jin, Vipin Chaudhary, Zhaozhuo Xu, et al. Kv cache compression, but what must we give in return? a comprehensive benchmark of long context capable approaches. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 4623–4648,
2024
-
[20]
11 Preprint. Under review. Ruijie Zhang, Haozhe Liang, Da Chang, Li Hu, Fanqi Kong, Huaxiao Yin, and Yu Li. When does value-aware kv eviction help? a fixed-contract diagnostic for non-monotone cache compression.arXiv preprint arXiv:2605.08234,
-
[21]
Barrett, Zhangyang Wang, and Beidi Chen
Zhenyu (Allen) Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R´e, Clark W. Barrett, Zhangyang Wang, and Beidi Chen. H2o: Heavy-hitter oracle for efficient generative inference of large language models.ArXiv, abs/2306.14048,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.