IMWM: Intuition Models Complement World Models for Latent Planning
Pith reviewed 2026-06-28 15:46 UTC · model grok-4.3
The pith
An intuition model trained on demonstrations complements a world model to overcome search bottlenecks in pixel-based planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
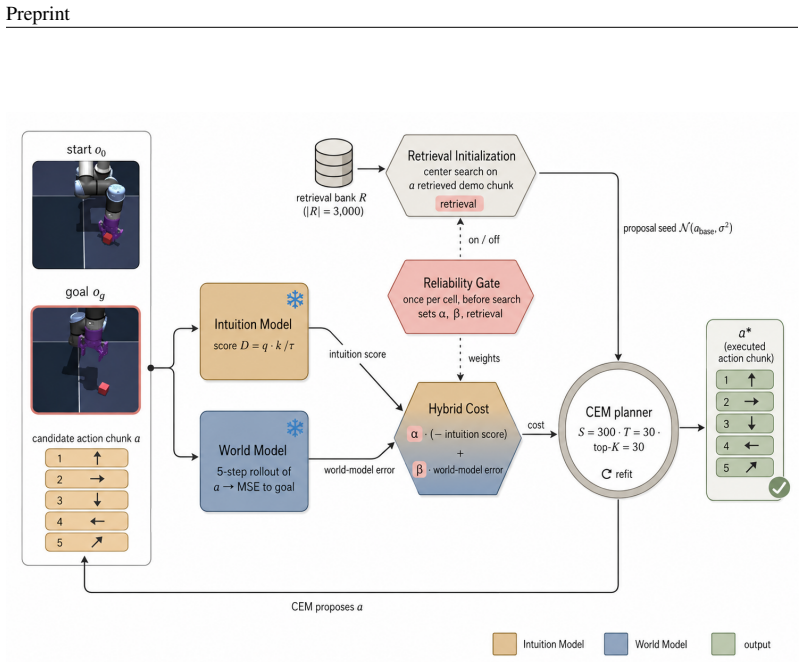
Even when the learned forward predictor is replaced by an idealized rollout of the true environment dynamics, a finite-budget sample-based planner fails on some tasks. Adding an intuition model trained from demonstrations, integrated through retrieval initialization, hybrid cost, and reliability gate, increases mean success rates on all four evaluated pixel-based goal-reaching tasks.
What carries the argument
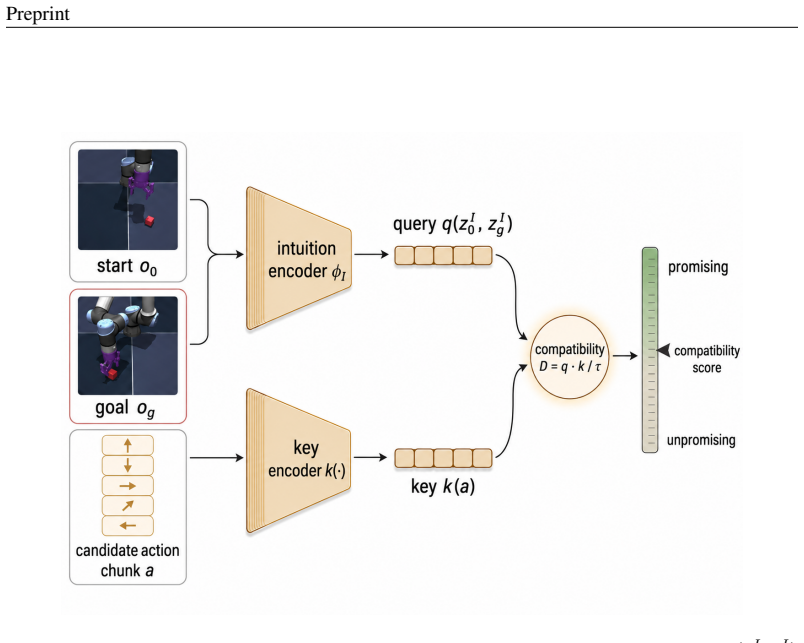
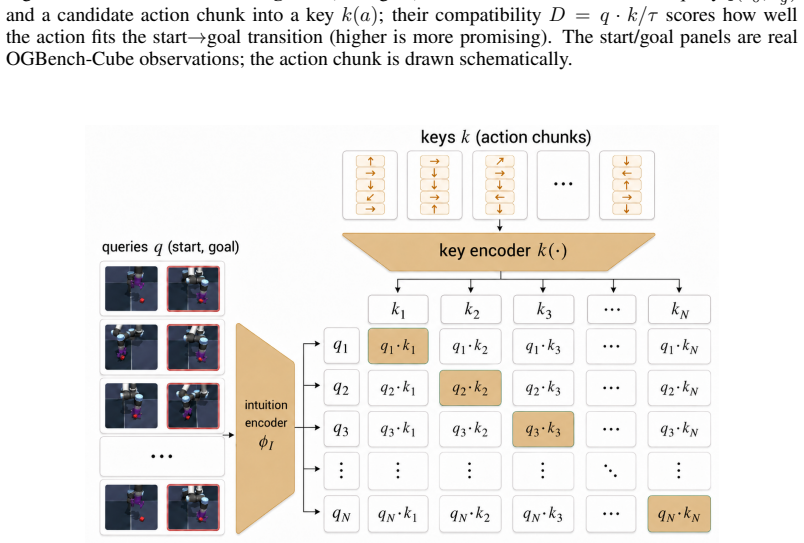
IMWM, which pairs a latent world model with an intuition model via three components: retrieval initialization, hybrid cost, and reliability gate.
If this is right
- Sample-based planning remains a bottleneck even with perfect dynamics knowledge.
- Demonstration-trained intuition can supply useful proposals and scores for planning.
- The three integration components allow the intuition model to improve performance without replacing the world model.
- Gains are largest on tasks where pure world-model planning struggles most.
Where Pith is reading between the lines
- This approach could reduce reliance on exhaustive random search when some demonstration data exists.
- The reliability gate mechanism might be adapted to other uncertainty signals beyond the current design.
- Similar hybrid intuition-world model setups may apply to non-pixel control problems where search is expensive.
- If the intuition model is cheap to train, it could lower overall planning compute in repeated tasks.
Load-bearing premise
The intuition model trained from demonstrations will generalize to provide useful action proposals and scores on the held-out test tasks and environments used in the evaluation.
What would settle it
Running the same four pixel-based tasks with the world-model-only planner and confirming lower success rates than IMWM, or observing no difference after ablating the intuition components.
Figures

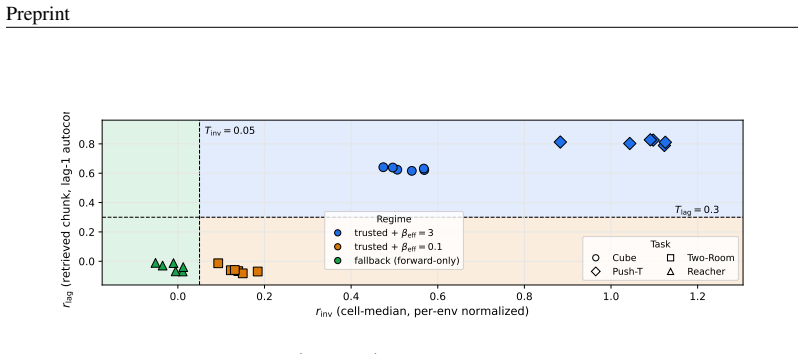
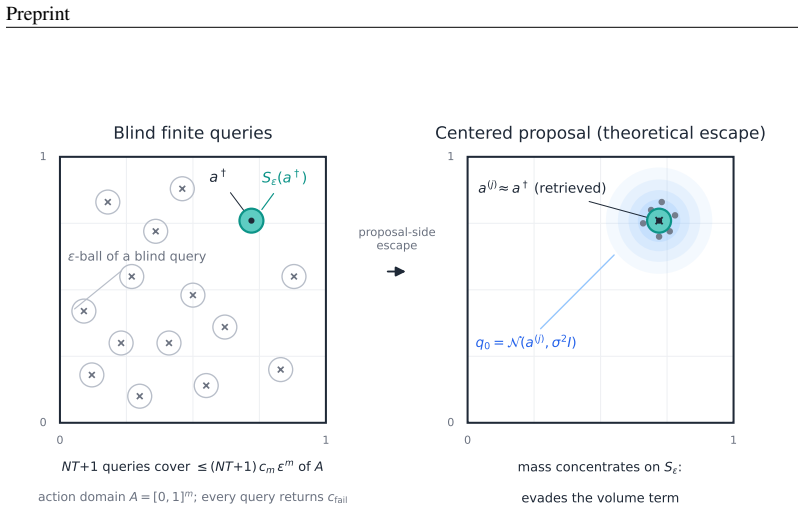
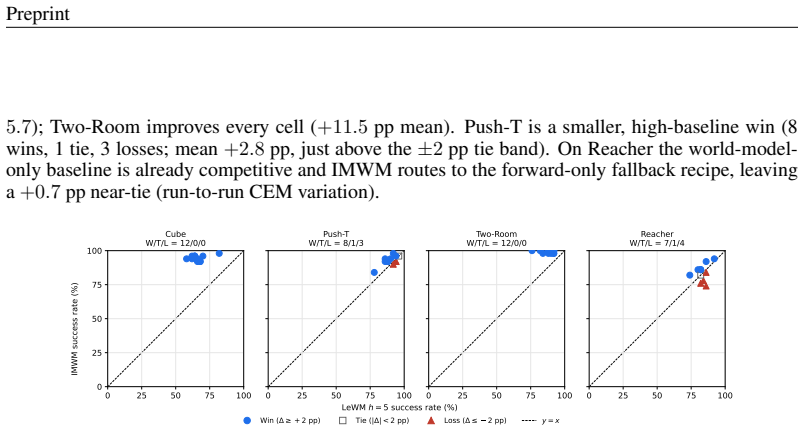
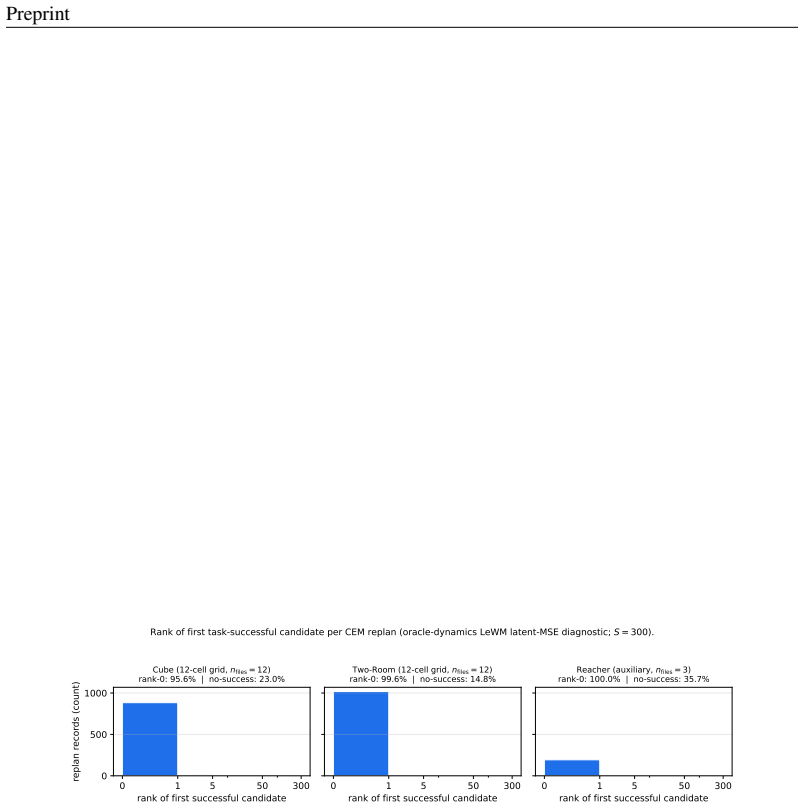
read the original abstract
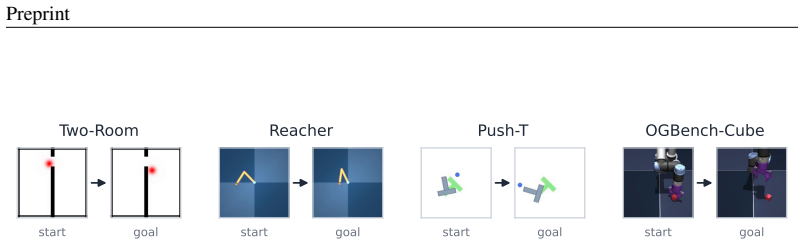
Planning with a learned latent world model is a promising route to control from raw pixels, but a strong world model alone is not enough. We show this experimentally: even with a perfect world model (operationalized by replacing the learned forward predictor with an idealized rollout of the true environment dynamics), a finite-budget sample-based planner still fails on some tasks, indicating that the bottleneck can lie in search rather than in world-model accuracy. Motivated by this gap, we propose IMWM (Intuition Model + World Model), which pairs the world model with an intuition model trained from demonstrations to recognize promising actions. The two models collaborate through three lightweight components: (i) Retrieval Initialization, which initializes the planner's action proposal from a retrieved demonstration; (ii) Hybrid Cost, which combines the intuition score with the world-model rollout cost; and (iii) a Reliability Gate, which adjusts how much the planner trusts intuition in each setting. Across four pixel-based goal-reaching tasks (Two-Room, Reacher, Push-T, and OGBench-Cube), IMWM has higher mean success than the world-model-only planner on all four, with the largest gains on Two-Room (99.2%, +11.5 percentage points) and OGBench-Cube (94.7%, +28.5 percentage points).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that even a perfect world model (true dynamics rollout) is insufficient for finite-budget sample-based planning on some pixel-based goal-reaching tasks, and proposes IMWM to address this by pairing the world model with an intuition model trained from demonstrations. The intuition model contributes via retrieval initialization of action proposals, a hybrid cost combining intuition scores with world-model rollouts, and a reliability gate. Across four tasks (Two-Room, Reacher, Push-T, OGBench-Cube), IMWM reports higher mean success rates than the world-model-only baseline, with gains of +11.5 pp on Two-Room (99.2%) and +28.5 pp on OGBench-Cube (94.7%).
Significance. If the central empirical result holds, the work provides evidence that search bottlenecks persist even with idealized world models and that lightweight intuition components can meaningfully improve planning success. The perfect-world-model baseline is a clear strength, as it isolates the contribution of the planner rather than model error. This could inform hybrid model-based approaches in pixel control, though the magnitude of gains depends on the validity of the held-out evaluation.
major comments (1)
- [Evaluation and experimental setup] The generalization of the intuition model (trained from demonstrations) to the held-out test tasks is the load-bearing assumption for the reported success-rate improvements. The abstract and evaluation provide no information on demonstration collection procedure, whether the intuition model saw any trajectories from the test environments or tasks during training, or explicit train/test splits for the intuition component. This leaves open the possibility that gains arise from distribution overlap or memorization rather than genuine complementarity between intuition and search.
minor comments (1)
- [Abstract] The abstract reports mean success rates with percentage-point gains but omits the number of random seeds, statistical significance tests, or hyperparameter sensitivity analysis for the reliability gate and hybrid cost; these details are needed to assess robustness of the four-task comparison.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater clarity on the intuition model's training data and evaluation splits. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation and experimental setup] The generalization of the intuition model (trained from demonstrations) to the held-out test tasks is the load-bearing assumption for the reported success-rate improvements. The abstract and evaluation provide no information on demonstration collection procedure, whether the intuition model saw any trajectories from the test environments or tasks during training, or explicit train/test splits for the intuition component. This leaves open the possibility that gains arise from distribution overlap or memorization rather than genuine complementarity between intuition and search.
Authors: We agree that the manuscript would be strengthened by explicit details on these points. In the revised version we will add a new subsection (likely in Section 4 or the appendix) that: (i) describes the demonstration collection procedure, which used only trajectories from the training task distributions; (ii) states that no trajectories from the held-out test tasks or environments were ever shown to the intuition model; and (iii) reports the explicit train/test splits employed for the intuition component. These additions will make clear that the reported gains reflect complementarity with the search procedure rather than distributional overlap. revision: yes
Circularity Check
No circularity: empirical success-rate comparison is self-contained.
full rationale
The paper's central claim is an experimental result: IMWM (with retrieval initialization, hybrid cost, and reliability gate) yields higher success rates than a world-model-only planner on four pixel tasks. These components are defined directly from the method description without reducing to fitted parameters renamed as predictions or to self-citations. The perfect-world-model baseline is external (true dynamics). No equations or derivations are presented that equate outputs to inputs by construction. Generalization of the intuition model is an empirical assumption, not a definitional loop. This matches the default case of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2603.19312 , year =
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels , author =. arXiv preprint arXiv:2603.19312 , year =. 2603.19312 , archiveprefix =
-
[2]
arXiv preprint arXiv:2605.21800 , year =
stable-worldmodel: A Platform for Reproducible World Modeling Research and Evaluation , author =. arXiv preprint arXiv:2605.21800 , year =. 2605.21800 , archiveprefix =
-
[3]
Proceedings of the 36th International Conference on Machine Learning , series =
Learning Latent Dynamics for Planning from Pixels , author =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , editor =
2019
-
[4]
International Conference on Learning Representations , year =
Dream to Control: Learning Behaviors by Latent Imagination , author =. International Conference on Learning Representations , year =
-
[5]
and Norouzi, Mohammad and Ba, Jimmy , booktitle =
Hafner, Danijar and Lillicrap, Timothy P. and Norouzi, Mohammad and Ba, Jimmy , booktitle =. Mastering
-
[6]
Nature , year =
Mastering Diverse Control Tasks through World Models , author =. Nature , year =
-
[7]
Proceedings of the 39th International Conference on Machine Learning , series =
Temporal Difference Learning for Model Predictive Control , author =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , editor =
2022
-
[8]
Hansen, Nicklas and Su, Hao and Wang, Xiaolong , booktitle =
-
[9]
Methodology and Computing in Applied Probability , year =
The Cross-Entropy Method for Combinatorial and Continuous Optimization , author =. Methodology and Computing in Applied Probability , year =
-
[10]
Advances in Neural Information Processing Systems 31 , year =
Deep Reinforcement Learning in a Handful of Trials Using Probabilistic Dynamics Models , author =. Advances in Neural Information Processing Systems 31 , year =
-
[11]
Advances in Neural Information Processing Systems 31 , year =
Visual Reinforcement Learning with Imagined Goals , author =. Advances in Neural Information Processing Systems 31 , year =
-
[12]
Advances in Neural Information Processing Systems 32 , year =
Search on the Replay Buffer: Bridging Planning and Reinforcement Learning , author =. Advances in Neural Information Processing Systems 32 , year =
-
[13]
International Conference on Learning Representations , year =
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author =. International Conference on Learning Representations , year =
-
[14]
Journal of Machine Learning Research , year =
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. Journal of Machine Learning Research , year =
-
[15]
Proceedings of the 20th International Conference on Artificial Intelligence and Statistics , series =
Value-Aware Loss Function for Model-based Reinforcement Learning , author =. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics , series =. 2017 , editor =
2017
-
[16]
Advances in Neural Information Processing Systems 31 , year =
Iterative Value-Aware Model Learning , author =. Advances in Neural Information Processing Systems 31 , year =
-
[17]
Advances in Neural Information Processing Systems 33 , year =
The Value Equivalence Principle for Model-Based Reinforcement Learning , author =. Advances in Neural Information Processing Systems 33 , year =
-
[18]
Mastering
Schrittwieser, Julian and Antonoglou, Ioannis and Hubert, Thomas and Simonyan, Karen and Sifre, Laurent and Schmitt, Simon and Guez, Arthur and Lockhart, Edward and Hassabis, Demis and Graepel, Thore and Lillicrap, Timothy and Silver, David , journal =. Mastering. 2020 , volume =
2020
-
[19]
Proceedings of the 2nd Annual Conference on Learning for Dynamics and Control , series =
Objective Mismatch in Model-based Reinforcement Learning , author =. Proceedings of the 2nd Annual Conference on Learning for Dynamics and Control , series =. 2020 , publisher =
2020
-
[20]
International Conference on Learning Representations , year =
On the Role of Planning in Model-Based Deep Reinforcement Learning , author =. International Conference on Learning Representations , year =
-
[21]
Nature Neuroscience , year =
Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control , author =. Nature Neuroscience , year =
-
[22]
Advances in Neural Information Processing Systems 20 , year =
Hippocampal Contributions to Control: The Third Way , author =. Advances in Neural Information Processing Systems 20 , year =
-
[23]
Nature Neuroscience , year =
Prioritized memory access explains planning and hippocampal replay , author =. Nature Neuroscience , year =
-
[24]
Nature , year =
Hippocampal place-cell sequences depict future paths to remembered goals , author =. Nature , year =
-
[25]
Nature Neuroscience , year =
The hippocampus as a predictive map , author =. Nature Neuroscience , year =
-
[26]
Psychological Review , year =
Cognitive maps in rats and men , author =. Psychological Review , year =
-
[27]
PLoS Computational Biology , year =
Actions, action sequences and habits: evidence that goal-directed and habitual action control are hierarchically organized , author =. PLoS Computational Biology , year =
-
[28]
arXiv preprint arXiv:1606.04460 , year =
Model-Free Episodic Control , author =. arXiv preprint arXiv:1606.04460 , year =. 1606.04460 , archiveprefix =
-
[29]
Proceedings of the 34th International Conference on Machine Learning , series =
Neural Episodic Control , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
2017
-
[30]
Advances in Neural Information Processing Systems 30 , year =
Imagination-Augmented Agents for Deep Reinforcement Learning , author =. Advances in Neural Information Processing Systems 30 , year =
-
[31]
Proceedings of the 2020 Conference on Robot Learning , series =
Accelerating Reinforcement Learning with Learned Skill Priors , author =. Proceedings of the 2020 Conference on Robot Learning , series =. 2021 , publisher =
2020
-
[32]
and Hasenclever, Leonard and Tirumala, Dhruva and Schwarz, Jonathan and Desjardins, Guillaume and Czarnecki, Wojciech M
Galashov, Alexandre and Jayakumar, Siddhant M. and Hasenclever, Leonard and Tirumala, Dhruva and Schwarz, Jonathan and Desjardins, Guillaume and Czarnecki, Wojciech M. and Teh, Yee Whye and Pascanu, Razvan and Heess, Nicolas , booktitle =. Information asymmetry in
-
[33]
Journal of Machine Learning Research , year =
Behavior Priors for Efficient Reinforcement Learning , author =. Journal of Machine Learning Research , year =
-
[34]
Singh, Avi and Liu, Huihan and Zhou, Gaoyue and Yu, Albert and Rhinehart, Nicholas and Levine, Sergey , booktitle =
-
[35]
Proceedings of the 39th International Conference on Machine Learning , series =
Retrieval-Augmented Reinforcement Learning , author =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , publisher =
2022
-
[36]
The International Journal of Robotics Research , year =
Data-driven planning via imitation learning , author =. The International Journal of Robotics Research , year =
-
[37]
Retrieval-Augmented Decision Transformer: External Memory for In-context
Schmied, Thomas and Paischer, Fabian and Patil, Vihang and Hofmarcher, Markus and Pascanu, Razvan and Hochreiter, Sepp , journal =. Retrieval-Augmented Decision Transformer: External Memory for In-context. 2024 , eprint =
2024
-
[38]
arXiv preprint arXiv:2204.03597 , year =
Imitating, Fast and Slow: Robust learning from demonstrations via decision-time planning , author =. arXiv preprint arXiv:2204.03597 , year =. 2204.03597 , archiveprefix =
-
[39]
Proceedings of the 39th International Conference on Machine Learning , series =
Planning with Diffusion for Flexible Behavior Synthesis , author =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , publisher =
2022
-
[40]
Proceedings of the 34th International Conference on Machine Learning , series =
The Predictron: End-To-End Learning and Planning , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
2017
-
[41]
Advances in Neural Information Processing Systems 30 , year =
Value Prediction Network , author =. Advances in Neural Information Processing Systems 30 , year =
-
[42]
Proceedings of the 6th Conference on Robot Learning , series =
Skill-based Model-based Reinforcement Learning , author =. Proceedings of the 6th Conference on Robot Learning , series =. 2023 , publisher =. 2207.07560 , archiveprefix =
arXiv 2023
-
[43]
Proceedings of the Conference on Robot Learning , series =
Deep Dynamics Models for Learning Dexterous Manipulation , author =. Proceedings of the Conference on Robot Learning , series =. 2020 , publisher =
2020
-
[44]
Proceedings of the 2020 Conference on Robot Learning , series =
Sample-efficient Cross-Entropy Method for Real-time Planning , author =. Proceedings of the 2020 Conference on Robot Learning , series =. 2021 , publisher =
2020
-
[45]
Learning for Dynamics and Control (L4DC) , year =
Model-Predictive Control via Cross-Entropy and Gradient-Based Optimization , author =. Learning for Dynamics and Control (L4DC) , year =. 2004.08763 , archiveprefix =
arXiv 2004
-
[46]
Differentiable
Amos, Brandon and. Differentiable. Advances in Neural Information Processing Systems 31 , year =
-
[47]
arXiv preprint arXiv:1807.03748 , year =
Representation Learning with Contrastive Predictive Coding , author =. arXiv preprint arXiv:1807.03748 , year =. 1807.03748 , archiveprefix =
-
[48]
Proceedings of the 34th International Conference on Machine Learning , series =
Curiosity-driven Exploration by Self-supervised Prediction , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
2017
-
[49]
2023 , publisher =
Nair, Suraj and Rajeswaran, Aravind and Kumar, Vikash and Finn, Chelsea and Gupta, Abhinav , booktitle =. 2023 , publisher =
2023
-
[50]
Advances in Neural Information Processing Systems 35 , year =
Contrastive Learning as Goal-Conditioned Reinforcement Learning , author =. Advances in Neural Information Processing Systems 35 , year =
-
[51]
arXiv preprint arXiv:1812.00568 , year =
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control , author =. arXiv preprint arXiv:1812.00568 , year =. 1812.00568 , archiveprefix =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.