ATLAS: Agentic Test-time Learning-to-Allocate Scaling
Pith reviewed 2026-06-28 15:25 UTC · model grok-4.3
The pith
An LLM orchestrator takes end-to-end control of test-time scaling by issuing explore actions that launch solvers, manage evidence, decide stopping, and synthesize answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ATLAS shows that an LLM orchestrator can own the control loop end-to-end through the explore action, which dispatches a fresh independent solver on the original problem and thereby lets the orchestrator decide whether to gather more evidence, when to stop, and how to synthesize the final answer, with the action space remaining extensible to solver choice, reasoning effort, or prompting strategy.
What carries the argument
The explore action, a single extensible call that dispatches an independent solver while returning control to the orchestrator for stateful decisions on continuation and synthesis.
If this is right
- The orchestrator approach yields higher accuracy than fixed-workflow baselines on scientific question answering, code generation, and multimodal reasoning benchmarks.
- The same results are obtained with substantially fewer solver calls than the fixed baselines require.
- Exposing solver choice as an additional action dimension produces further accuracy gains on the same tasks.
- Replacing the orchestrator's direct synthesis step with a separate integrator either degrades or fails to improve accuracy on three of the four benchmarks.
Where Pith is reading between the lines
- The design implies that adaptive allocation of test-time compute can be learned directly from the model's own reasoning traces rather than from hand-crafted policies.
- Stateful evidence management across solver calls appears to be the mechanism that allows the gains, suggesting similar agentic loops could be tested on problems where evidence must be accumulated over long horizons.
- Extending the action space to include external verification tools or self-critique steps could be explored without changing the core orchestrator structure.
- The framework separates the question of how much compute to spend from the question of which model to spend it on, opening a route to test-time model routing as a natural next dimension.
Load-bearing premise
The LLM orchestrator can reliably keep track of evidence across multiple explore calls and make sound choices about when to stop and how to combine results.
What would settle it
A controlled experiment in which a fixed non-agentic workflow, given the same total number of solver calls and the same backbone model, matches or exceeds ATLAS accuracy on the same benchmarks would falsify the advantage of orchestrator-driven allocation.
Figures

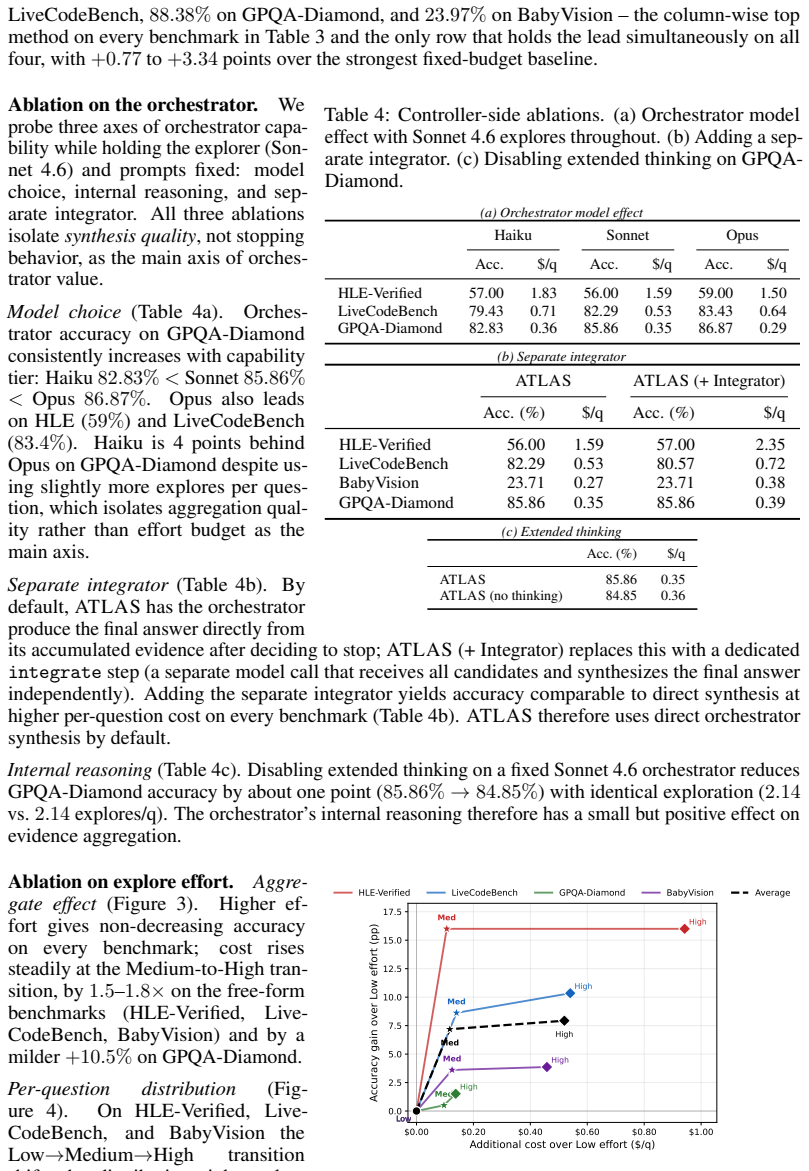
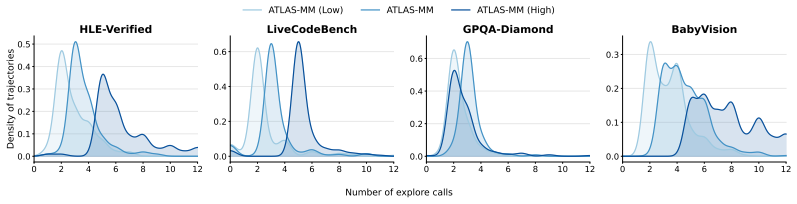
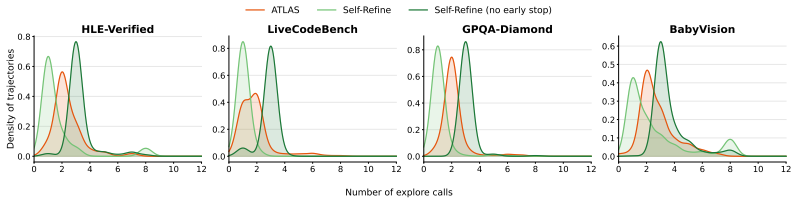
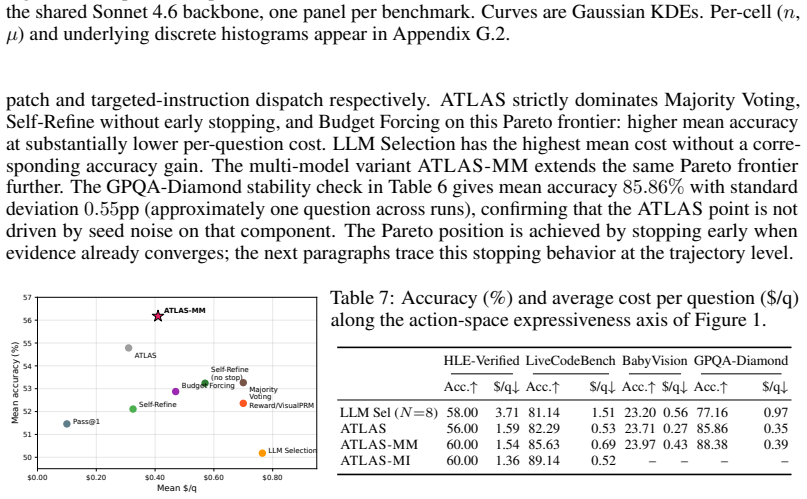
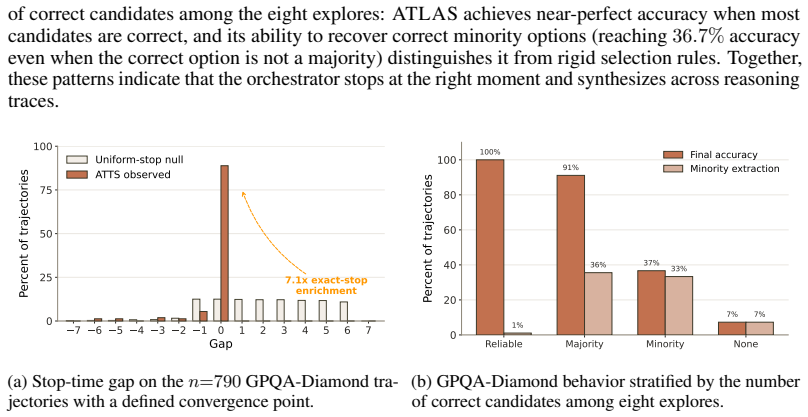


read the original abstract
Test-time scaling has become a major way to improve large language model reasoning, but its orchestration has remained designer-engineered: a fixed sample budget, a fixed refinement loop, a fixed scoring rule, or a fixed search policy decides how compute is spent, leaving the model in charge of solving but not of orchestration. We introduce ATLAS, an agentic test-time scaling framework in which an LLM orchestrator owns the control loop end-to-end. Through a single action, explore, which dispatches a fresh independent solver on the original problem, the orchestrator decides whether to gather more evidence, when to stop, and how to synthesize the final answer; the action space is extensible, with each explore call optionally specifying solver, reasoning effort, or prompting strategy. We evaluate ATLAS on four benchmarks covering scientific question answering, code generation, and multimodal reasoning under a Claude Sonnet 4.6 backbone, where it reaches 56.00% on HLE-Verified, 82.29% on LiveCodeBench, 85.75% on GPQA-Diamond, and 23.71% on BabyVision while using far fewer API calls than fixed-workflow baselines. A multi-model extension, ATLAS-MM, that exposes solver choice as an additional action dimension further improves HLE-Verified to 60.00% and LiveCodeBench to 85.63%, with consistent gains on GPQA-Diamond and BabyVision. Ablations replacing the orchestrator's direct synthesis with a separate integrator degrade or fail to improve accuracy on three of four benchmarks, consistent with the role of stateful evidence management in producing the gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ATLAS, an agentic test-time scaling framework in which an LLM orchestrator controls the entire compute allocation loop end-to-end via repeated calls to a single 'explore' action that dispatches independent solvers on the original problem. The orchestrator decides when to gather evidence, when to stop, and how to synthesize the final answer; the action space is extensible (solver, effort, prompting, and in ATLAS-MM also model choice). On four benchmarks (HLE-Verified, LiveCodeBench, GPQA-Diamond, BabyVision) with a Claude Sonnet 4.6 backbone, ATLAS reports 56.00%, 82.29%, 85.75%, and 23.71% accuracy while using fewer API calls than fixed-workflow baselines; ATLAS-MM further improves two of the scores. Ablations show that replacing the orchestrator's direct synthesis with a separate integrator degrades performance on three benchmarks.
Significance. If the results hold, the work shows that shifting orchestration responsibility to the LLM itself can produce more adaptive and efficient test-time scaling than hand-designed fixed workflows. The extensible action space, the multi-model extension, and the ablation evidence that stateful synthesis by the orchestrator matters are concrete strengths. The approach is directly testable on public benchmarks and supplies a clear mechanism (the explore action plus synthesis) whose contribution can be isolated.
major comments (2)
- [Abstract] Abstract and evaluation results: the central performance claims rest on point estimates (56.00% on HLE-Verified, 82.29% on LiveCodeBench, etc.) with no reported variance, number of independent runs, or statistical tests. This makes it impossible to determine whether the reported gains over baselines are reliable or could be explained by run-to-run variation.
- [Ablations] Ablation results (final paragraph of abstract and corresponding evaluation section): while the degradation when synthesis is offloaded supports the role of stateful evidence management, the paper provides no analysis of failure modes of the orchestrator (e.g., loss of evidence across independent explore calls or miscalibrated stopping decisions) or robustness when the backbone is changed, leaving the weakest assumption untested beyond the single Claude Sonnet 4.6 setting.
minor comments (2)
- Tables and figures reporting benchmark accuracies should include error bars or confidence intervals once multiple runs are performed.
- The description of the 'explore' action and its optional parameters would benefit from a concise pseudocode or state diagram showing how evidence is accumulated across calls.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation results: the central performance claims rest on point estimates (56.00% on HLE-Verified, 82.29% on LiveCodeBench, etc.) with no reported variance, number of independent runs, or statistical tests. This makes it impossible to determine whether the reported gains over baselines are reliable or could be explained by run-to-run variation.
Authors: We agree that variance estimates and statistical tests would strengthen the reliability assessment of the reported gains. In the revised manuscript we will add results from multiple independent runs (with means and standard deviations) along with appropriate statistical comparisons against the baselines. revision: yes
-
Referee: [Ablations] Ablation results (final paragraph of abstract and corresponding evaluation section): while the degradation when synthesis is offloaded supports the role of stateful evidence management, the paper provides no analysis of failure modes of the orchestrator (e.g., loss of evidence across independent explore calls or miscalibrated stopping decisions) or robustness when the backbone is changed, leaving the weakest assumption untested beyond the single Claude Sonnet 4.6 setting.
Authors: The ablation already isolates the contribution of stateful synthesis by the orchestrator. We will expand the revised manuscript with a qualitative discussion of observed orchestrator failure modes drawn from the existing runs. We will also explicitly note the single-backbone limitation and its implications. A comprehensive multi-backbone robustness study lies outside the scope of the present work. revision: partial
Circularity Check
No circularity: empirical framework with external benchmarks
full rationale
The paper introduces an agentic orchestration framework and reports empirical results on public benchmarks (HLE-Verified, LiveCodeBench, GPQA-Diamond, BabyVision) against fixed-workflow baselines, with ablations on synthesis. No equations, parameter fits, uniqueness theorems, or self-citations are used to derive predictions or claims; all performance numbers are direct measurements on held-out data. The central claim rests on observed accuracy gains and API-call reductions rather than any reduction to fitted inputs or prior self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with LLMs
Pranjal Aggarwal, Aman Madaan, Yiming Yang, and Mausam. Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12375–12396. Association for Computational Linguistics, 2023. URL https://aclanthology.org/2023. emnlp-main.761/
2023
-
[2]
Claude code SDK documentation.https://docs.anthropic.com/en/docs/c laude-code/sdk, 2025
Anthropic. Claude code SDK documentation.https://docs.anthropic.com/en/docs/c laude-code/sdk, 2025
2025
-
[3]
Le, Christopher Ré, and Azalia Mirhoseini
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2024. URLhttps://arxiv.org/abs/2407.21787
Pith/arXiv arXiv 2024
-
[4]
A benchmark of expert-level academic questions to assess AI capabilities.Nature, 649:1139–1146, 2026
Center for AI Safety, Scale AI, and HLE Contributors Consortium. A benchmark of expert-level academic questions to assess AI capabilities.Nature, 649:1139–1146, 2026. doi: 10.1038/s415 86-025-09962-4
-
[5]
Babyvision: Visual reasoning beyond language,
Liang Chen, Weichu Xie, Yiyan Liang, et al. Babyvision: Visual reasoning beyond language,
-
[6]
URLhttps://arxiv.org/abs/2601.06521. 9
-
[7]
Universal self-consistency for large language model generation
Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. Universal self-consistency for large language model generation. InICML 2024 Workshop on In-Context Learning, 2024. URL https: //arxiv.org/abs/2311.17311
arXiv 2024
-
[8]
Tumix: Multi-agent test-time scaling with tool-use mixture, 2025
Yongchao Chen, Jiefeng Chen, Rui Meng, Ji Yin, Na Li, Chuchu Fan, Chi Wang, Tomas Pfister, and Jinsung Yoon. Tumix: Multi-agent test-time scaling with tool-use mixture, 2025. URL https://arxiv.org/abs/2510.01279
arXiv 2025
-
[9]
Hyeong Kyu Choi and Banghua Zhu. Debate or vote: Which yields better decisions in multi- agent large language models? InAdvances in Neural Information Processing Systems, 2025. URLhttps://arxiv.org/abs/2508.17536
arXiv 2025
-
[10]
Paula Cordero-Encinar and Andrew B Duncan. Certified self-consistency: Statistical guarantees and test-time training for reliable reasoning in llms.arXiv preprint arXiv:2510.17472, 2025
arXiv 2025
-
[11]
Learning how hard to think: Input-adaptive allocation of LM computation
Mehul Damani, Idan Shenfeld, Andi Peng, Andreea Bobu, and Jacob Andreas. Learning how hard to think: Input-adaptive allocation of LM computation. InInternational Conference on Learning Representations, 2025. URLhttps://arxiv.org/abs/2410.04707
arXiv 2025
-
[12]
C. Nicolò De Sabbata, Theodore R. Sumers, Badr AlKhamissi, Antoine Bosselut, and Thomas L. Griffiths. Rational metareasoning for large language models. InAdvances in Neural Information Processing Systems, 2024. URLhttps://arxiv.org/abs/2410.05563
arXiv 2024
-
[13]
DeepSeek-AI. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 645:633–638, 2025. doi: 10.1038/s41586-025-09422-z. URL https://www.nature .com/articles/s41586-025-09422-z
-
[14]
Best-route: Adaptive llm routing with test-time optimal compute
Dujian Ding, Ankur Mallick, Shaokun Zhang, Chi Wang, Daniel Madrigal, Mirian Del Car- men Hipolito Garcia, Menglin Xia, Laks VS Lakshmanan, Qingyun Wu, and Victor Rühle. Best-route: Adaptive llm routing with test-time optimal compute. InInternational Conference on Machine Learning, pages 13870–13884. PMLR, 2025
2025
-
[15]
Calibrate-then-act: Cost-aware exploration in LLM agents, 2026
Wenxuan Ding, Nicholas Tomlin, and Greg Durrett. Calibrate-then-act: Cost-aware exploration in LLM agents, 2026. URLhttps://arxiv.org/abs/2602.16699
Pith/arXiv arXiv 2026
-
[16]
Rbench-v: A primary assessment for visual reasoning models with multi-modal outputs, 2025
Meng-Hao Guo, Xuanyu Chu, Qianrui Yang, et al. Rbench-v: A primary assessment for visual reasoning models with multi-modal outputs, 2025. URL https://arxiv.org/abs/2505.1 6770
2025
-
[17]
Selecting compu- tations: Theory and applications
Nicholas Hay, Stuart Russell, David Tolpin, and Solomon Eyal Shimony. Selecting compu- tations: Theory and applications. InUncertainty in Artificial Intelligence, pages 346–355, 2012
2012
-
[18]
Audrey Huang, Adam Block, Qinghua Liu, Nan Jiang, Akshay Krishnamurthy, and Dylan J. Foster. Is best-of- n the best of them? coverage, scaling, and optimality in inference-time alignment. InInternational Conference on Machine Learning (ICML), 2025. URL https: //arxiv.org/abs/2503.21878
arXiv 2025
-
[19]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. InInterna- tional Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2310 .01798
2024
-
[20]
Jingkai Huang, Will Ma, and Zhengyuan Zhou. Optimal bayesian stopping for efficient inference of consistent llm answers.arXiv preprint arXiv:2602.05395, 2026
Pith/arXiv arXiv 2026
-
[21]
Idavidrein/gpqa (hugging face dataset card)
Idavidrein. Idavidrein/gpqa (hugging face dataset card). https://huggingface.co/datas ets/Idavidrein/gpqa, 2026
2026
-
[22]
Wider or deeper? scaling LLM inference-time compute with adaptive branching tree search
Yuichi Inoue, Kou Misaki, Yuki Imajuku, So Kuroki, Taishi Nakamura, and Takuya Akiba. Wider or deeper? scaling LLM inference-time compute with adaptive branching tree search. In Advances in Neural Information Processing Systems, 2025. URL https://arxiv.org/abs/ 2503.04412. 10
arXiv 2025
-
[23]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, Kevin Han, Alex Gu, et al. Livecodebench: Holistic and contamination free evaluation of large language models for code. InICLR, 2025. URL https://arxiv.org/ab s/2403.07974
Pith/arXiv arXiv 2025
-
[24]
Search-r1: Training llms to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025
2025
-
[25]
CoRefine: Confidence-guided self- refinement for adaptive test-time compute, 2026
Chen Jin, Ryutaro Tanno, Tom Diethe, and Philip Teare. CoRefine: Confidence-guided self- refinement for adaptive test-time compute, 2026. URL https://arxiv.org/abs/2602.089 48
2026
-
[26]
Optimal stopping vs best-of-n for inference time optimization.arXiv preprint arXiv:2510.01394, 2025
Yusuf Kalayci, Vinod Raman, and Shaddin Dughmi. Optimal stopping vs best-of-n for inference time optimization.arXiv preprint arXiv:2510.01394, 2025
arXiv 2025
-
[27]
Parallel test-time scaling with multi-sequence verifiers, 2026
Yegon Kim, Seungyoo Lee, Chaeyun Jang, Hyungi Lee, and Juho Lee. Parallel test-time scaling with multi-sequence verifiers, 2026. URLhttps://arxiv.org/abs/2603.03417
arXiv 2026
-
[28]
ConSol: Sequential probability ratio testing to find consistent LLM reasoning paths efficiently,
Jaeyeon Lee, Guantong Qi, Matthew Brady Neeley, Zhandong Liu, and Hyun-Hwan Jeong. ConSol: Sequential probability ratio testing to find consistent LLM reasoning paths efficiently,
-
[29]
URLhttps://arxiv.org/abs/2503.17587
-
[30]
Mahoney, Kurt Keutzer, and Amir Gholami
Nicholas Lee, Lutfi Eren Erdogan, Chris Joseph John, Surya Krishnapillai, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. Agentic test-time scaling for webagents, 2026. URL https://arxiv.org/abs/2602.12276
arXiv 2026
-
[31]
Benchmark test-time scaling of general LLM agents,
Xiaochuan Li, Ryan Ming, Pranav Setlur, Abhijay Paladugu, Andy Tang, Hao Kang, Shuai Shao, Rong Jin, and Chenyan Xiong. Benchmark test-time scaling of general LLM agents,
-
[32]
URLhttps://arxiv.org/abs/2602.18998
-
[33]
Skywork-reward-v2: Scaling preference data curation via human-ai synergy
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, Yang Liu, and Yahui Zhou. Skywork-reward-v2: Scaling preference data curation via human-ai synergy. InInternational Conference on Learning Representations, 2026. URLhttps://arxiv.org/abs/2507.01352
Pith/arXiv arXiv 2026
-
[34]
livecodebench/code_generation_lite (hugging face dataset card)
livecodebench. livecodebench/code_generation_lite (hugging face dataset card). https: //huggingface.co/datasets/livecodebench/code_generation_lite, 2026
2026
-
[35]
Livecodebench leaderboard
LiveCodeBench Team. Livecodebench leaderboard. https://livecodebench.github.io/ leaderboard.html, 2026
2026
-
[36]
Empowering LLM tool invocation with tool-call reward model
Da Ma, Ziyue Yang, Hongshen Xu, Haotian Fang, Kai Yu, and Lu Chen. Empowering LLM tool invocation with tool-call reward model. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=LnBEASInVr
2026
-
[37]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Sean Welleck, Bodhisattwa Prasad Majumder, Shashank Gupta, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems, 2023. URL htt...
2023
-
[38]
Adaptive inference-time compute: LLMs can predict if they can do better, even mid-generation
Rohin Manvi, Anikait Singh, and Stefano Ermon. Adaptive inference-time compute: LLMs can predict if they can do better, even mid-generation. InInternational Conference on Learning Representations, 2025. URLhttps://arxiv.org/abs/2410.02725
arXiv 2025
-
[39]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20275–20321. Association for Computational Linguistics, 2025. doi...
-
[40]
Visualprm-8b (hugging face model card)
OpenGVLab. Visualprm-8b (hugging face model card). https://huggingface.co/OpenG VLab/VisualPRM-8B, 2025
2025
-
[41]
ToolRL: Reward is all tool learning needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tur, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs. InAdvances in Neural Information Processing Systems, 2025. URLhttps://arxiv.org/abs/2504.13958
Pith/arXiv arXiv 2025
-
[42]
Cheng Qian, Zuxin Liu, Shirley Kokane, Akshara Prabhakar, Jielin Qiu, Haolin Chen, Zhi- wei Liu, Heng Ji, Weiran Yao, Shelby Heinecke, et al. xrouter: Training cost-aware llms orchestration system via reinforcement learning.arXiv preprint arXiv:2510.08439, 2025
arXiv 2025
-
[43]
R-bench/r-bench-v (hugging face dataset card and leaderboard)
R-Bench Team. R-bench/r-bench-v (hugging face dataset card and leaderboard). https: //huggingface.co/datasets/R-Bench/R-Bench-V, 2026
2026
-
[44]
Gpqa: A graduate-level google- proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, et al. Gpqa: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling (COLM), 2024. URL https://arxiv.org/abs/2311.12022
Pith/arXiv arXiv 2024
-
[45]
Russell and Eric Wefald.Do the Right Thing: Studies in Limited Rationality
Stuart J. Russell and Eric Wefald.Do the Right Thing: Studies in Limited Rationality. MIT Press, Cambridge, MA, 1991
1991
-
[46]
skylenage/hle-verified (hugging face dataset card)
skylenage. skylenage/hle-verified (hugging face dataset card). https://huggingface.co/d atasets/skylenage/HLE-Verified, 2026
2026
-
[47]
Skywork-reward-v2-qwen3-8b (hugging face model card)
Skywork. Skywork-reward-v2-qwen3-8b (hugging face model card). https://huggingface. co/Skywork/Skywork-Reward-V2-Qwen3-8B, 2025
2025
-
[48]
Scaling LLM test-time compute optimally can be more effective than scaling model parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters. InInternational Conference on Learning Representations, 2025. URLhttps://arxiv.org/abs/2408.03314
Pith/arXiv arXiv 2025
-
[49]
Yuan Sui, Yufei He, Tri Cao, Simeng Han, Yulin Chen, and Bryan Hooi. Meta-reasoner: Dynamic guidance for optimized inference-time reasoning in large language models, 2025. URLhttps://arxiv.org/abs/2502.19918
Pith/arXiv arXiv 2025
-
[50]
Unipatai/babyvision (hugging face dataset card)
UniPat-AI. Unipatai/babyvision (hugging face dataset card). https://huggingface.co/d atasets/UnipatAI/BabyVision, 2026
2026
-
[51]
Bartoldson, Bhavya Kailkhura, Guillaume Lajoie, Glen Berseth, Nikolay Malkin, and Moksh Jain
Siddarth Venkatraman, Vineet Jain, Sarthak Mittal, Vedant Shah, Johan Obando-Ceron, Yoshua Bengio, Brian R. Bartoldson, Bhavya Kailkhura, Guillaume Lajoie, Glen Berseth, Nikolay Malkin, and Moksh Jain. Recursive self-aggregation unlocks deep thinking in large language models, 2025. URLhttps://arxiv.org/abs/2509.26626
arXiv 2025
-
[52]
BEACON: Bayesian optimal stopping for efficient LLM sampling.arXiv preprint arXiv:2510.15945, 2025
Guangya Wan, Zixin Stephen Xu, Sasa Zorc, Manel Baucells, Mengxuan Hu, Hao Wang, and Sheng Li. BEACON: Bayesian optimal stopping for efficient LLM sampling.arXiv preprint arXiv:2510.15945, 2025. URLhttps://arxiv.org/abs/2510.15945
arXiv 2025
-
[53]
Peiyi Wang, Lei Li, Zhihong Shao, R. X. Xu, Damai Dai, Yifei Li, Deli Chen, Yiran Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. URLhttps://arxiv.org/abs/2312.08935
Pith/arXiv arXiv 2024
-
[54]
Visualprm: An effective process reward model for multimodal reasoning, 2025
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, Lewei Lu, Haodong Duan, Yu Qiao, Jifeng Dai, and Wenhai Wang. Visualprm: An effective process reward model for multimodal reasoning, 2025. URLhttps://arxiv.org/abs/2503.10291
arXiv 2025
-
[55]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023. URL h t t p s : //arxiv.org/abs/2203.11171. 12
Pith/arXiv arXiv 2023
-
[56]
CATP-LLM: Empowering large language models for cost-aware tool planning
Duo Wu, Jinghe Wang, Yuan Meng, Yanning Zhang, Le Sun, and Zhi Wang. CATP-LLM: Empowering large language models for cost-aware tool planning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8699–8709, 2025. URLhttps://arxiv.org/abs/2411.16313
arXiv 2025
-
[57]
Lillicrap, Kenji Kawaguchi, and Michael Shieh
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning,
-
[58]
URLhttps://arxiv.org/abs/2405.00451
-
[59]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[60]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, 2023. URL https://arxiv.org/abs/ 2305.10601
Pith/arXiv arXiv 2023
-
[61]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023. URLhttps://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[62]
StepTool: Enhancing multi-step tool usage in LLMs via step-grained reinforcement learning
Yuanqing Yu, Zhefan Wang, Weizhi Ma, Shuai Wang, Chuhan Wu, Zhiqiang Guo, and Min Zhang. StepTool: Enhancing multi-step tool usage in LLMs via step-grained reinforcement learning. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, 2025. doi: 10.1145/3746252.3761391. URL https://dl.acm.org /doi/10.1145/3746252.3761391
-
[63]
Hle-verified: A systematic verification and structured revision of humanity’s last exam, 2026
Weiqi Zhai, Zhihai Wang, Jinghang Wang, et al. Hle-verified: A systematic verification and structured revision of humanity’s last exam, 2026. URLhttps://arxiv.org/abs/2602.1 3964
2026
-
[64]
Router-r1: Teaching LLMs multi-round routing and aggregation via reinforcement learning
Haozhen Zhang, Tao Feng, and Jiaxuan You. Router-r1: Teaching LLMs multi-round routing and aggregation via reinforcement learning. InAdvances in Neural Information Processing Systems, 2025. URLhttps://arxiv.org/abs/2506.09033
arXiv 2025
-
[65]
Diels-Alder stereochemistry; 8 peaks
Hanlin Zhou and Huah Yong Chan. ORCH: many analyses, one merge—a deterministic multi-agent orchestrator for discrete-choice reasoning with EMA-guided routing.Frontiers in Artificial Intelligence, 9, 2026. doi: 10.3389/frai.2026.1748735. URL h t t p s : //www.frontiersin.org/journals/artificial-intelligence/articles/10.3389 /frai.2026.1748735/full. A Exten...
-
[68]
Candidates that agree but share the same reasoning path may reflect a shared misconception rather than true convergence
Genuine convergence means independent solvers arriving at the same answer through different methods. Candidates that agree but share the same reasoning path may reflect a shared misconception rather than true convergence
-
[69]
Repeated failures reinforce this -- more attempts will not help
Solver failure (timeout, empty answer) reflects the problem's difficulty. Repeated failures reinforce this -- more attempts will not help. If solvers timed out, you will almost certainly fail too. When solvers consistently fail, the problem is practically unsolvable -- submitting an empty answer is better than attempting it yourself, because you would als...
-
[70]
CRITICAL: Each explore costs budget. Giving up is a valid and preferred action -- when candidates provide no useful information, you MUST submit an empty answer immediately rather than wasting budget or attempting to solve. Every decision you make must be grounded in one of the principles above. Explicitly cite which principle justifies your action. 25 Li...
2025
-
[71]
analysis
You cannot solve problems yourself. Your only window into the problem is what solvers return. Reasoning about the problem content -- analyzing algorithms, deriving formulas, writing code -- constitutes solving, even when framed as "analysis" or "synthesis". Any answer without candidate evidence is baseless and undermines the system
-
[72]
Self-reported confidence is poorly calibrated
A single candidate, regardless of its self-reported confidence, does not constitute sufficient evidence. Self-reported confidence is poorly calibrated
-
[73]
Candidates from different models that agree provide stronger evidence than candidates from the same model
Genuine convergence means independent solvers arriving at the same answer through different methods. Candidates from different models that agree provide stronger evidence than candidates from the same model
-
[74]
Start with cheaper models first; escalate when they fail or disagree
A weaker model failing does not mean a stronger model will also fail. Start with cheaper models first; escalate when they fail or disagree. Only when the strongest model fails repeatedly is the problem beyond reach
-
[75]
Try a different method
CRITICAL: Each explore costs real money. Giving up is a valid and preferred action -- when candidates provide no useful information, you MUST submit an empty answer immediately rather than wasting budget or attempting to solve. Before each explore call, explicitly reason about: (a) which model to use and why, citing cost data; (b) what you expect to learn...
-
[76]
analysis
You cannot solve problems yourself. Your only window into the problem is what solvers return. Reasoning about the problem content -- analyzing algorithms, deriving formulas, writing code -- constitutes solving, even when framed as "analysis" or "synthesis". Any answer without candidate evidence is baseless
-
[77]
Self-reported confidence is poorly calibrated
A single candidate, regardless of self-reported confidence, does not constitute sufficient evidence. Self-reported confidence is poorly calibrated
-
[78]
Same-method agreement may reflect a shared misconception
Genuine convergence means independent solvers arriving at the same answer through DIFFERENT methods. Same-method agreement may reflect a shared misconception. additional_prompt is your tool for forcing method diversity when the explore pool has drifted into method-redundancy
-
[79]
Repeated failures reinforce this -- more attempts will not help
Solver failure (timeout, empty answer) reflects the problem's difficulty. Repeated failures reinforce this -- more attempts will not help
-
[80]
Giving up is valid -- when candidates provide no useful information, submit an empty answer immediately rather than wasting budget or attempting to solve
CRITICAL: Each explore costs budget. Giving up is valid -- when candidates provide no useful information, submit an empty answer immediately rather than wasting budget or attempting to solve. Every decision must cite which principle justifies the action. H.3 Finalize instructions The third slot decides whether the final answer is produced by the orchestra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.