A Note on Stability for Orthogonalized Matrix Momentum with Client Sampling
Pith reviewed 2026-06-28 16:01 UTC · model grok-4.3
The pith
A stability recursion with client amplification yields finite-round upper-tail generalization bounds for orthogonalized matrix momentum under sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
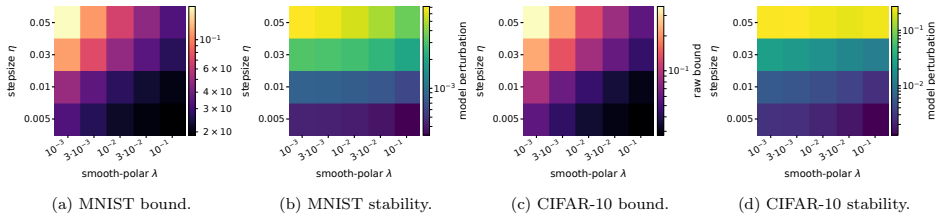
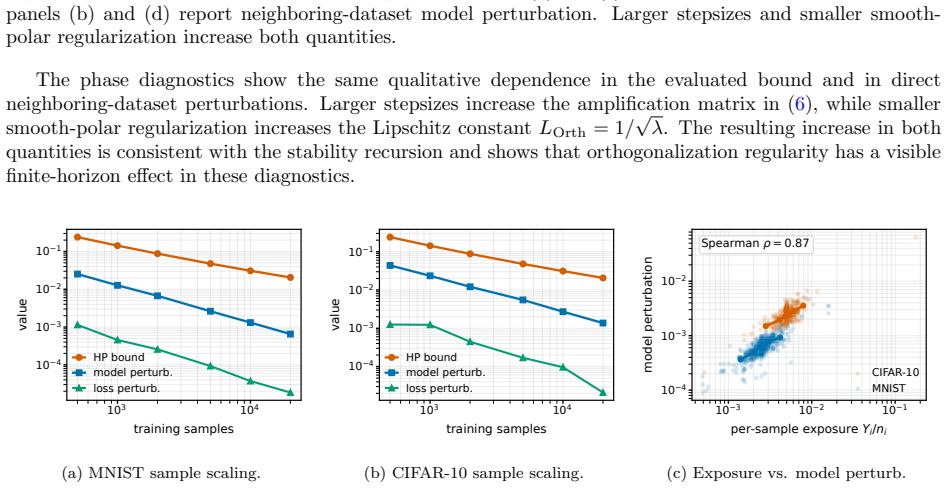
Under independent heterogeneous client data, unequal local sample counts, and fixed aggregation weights, we derive a finite-round upper-tail guarantee from a coupled-neighbor stability recursion and a weighted concentration step. The bound keeps the client-selection counts through the amplification factor Y_i(C); in the uniform full-participation full-batch regime, it yields ilde O(n^{-1}+n^{-1/2}) scaling whenever the horizon-dependent amplification terms are controlled. The matrix-orthogonalization rule is required to be Lipschitz along paired trajectories, a condition satisfied by regularized polar-type maps and normalized finite-step Newton-Schulz orthogonalizers.
What carries the argument
The coupled-neighbor stability recursion combined with weighted concentration, using the amplification factor Y_i(C) to track client-selection counts.
If this is right
- In the uniform full-participation full-batch regime the bound yields ilde O(n^{-1} + n^{-1/2}) scaling when horizon-dependent amplification terms are controlled.
- For the unregularized matrix sign the same argument requires coupled spectral separation.
- Gaussian smoothing yields a finite-round smoothed variant of the bound.
- A one-dimensional counterexample shows why a gap, smoothing, or regularity condition is necessary.
Where Pith is reading between the lines
- The same recursion technique could be applied to other matrix momentum variants provided the orthogonalizer satisfies an analogous trajectory-Lipschitz property.
- Client-selection probabilities might be chosen to keep the amplification factor Y_i(C) small and thereby tighten the bound.
- The stability perspective may connect to privacy analyses because trajectory closeness often implies differential-privacy-style guarantees.
Load-bearing premise
The matrix-orthogonalization rule must be Lipschitz along paired optimization trajectories.
What would settle it
Observe that without the Lipschitz condition on the orthogonalizer along paired trajectories the stability recursion diverges and the finite-round upper-tail guarantee no longer holds, as illustrated by the paper's one-dimensional counterexample.
Figures

read the original abstract
We study finite-sample generalization for a client-sampled distributed optimization scheme with matrix-valued parameters and orthogonalized momentum updates. The central quantity is the gap between the population and empirical objectives at the returned model when only a subset of clients participates in each round. Under independent heterogeneous client data, unequal local sample counts, and fixed aggregation weights, we derive a finite-round upper-tail guarantee from a coupled-neighbor stability recursion and a weighted concentration step. The bound keeps the client-selection counts through the amplification factor \(Y_i(\mathcal C)\); in the uniform full-participation full-batch regime, it yields \(\widetilde{\mathcal O}(n^{-1}+n^{-1/2})\) scaling whenever the horizon-dependent amplification terms are controlled. The matrix-orthogonalization rule is required to be Lipschitz along paired trajectories, a condition satisfied by regularized polar-type maps and normalized finite-step Newton--Schulz orthogonalizers. For the unregularized matrix sign, the same argument requires coupled spectral separation, whereas Gaussian smoothing gives a finite-round smoothed variant. A one-dimensional counterexample shows why a gap, smoothing, or regularity condition is necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives a finite-round upper-tail generalization bound for client-sampled distributed optimization with matrix-valued parameters and orthogonalized momentum updates. Under independent heterogeneous client data, unequal local sample sizes, and fixed aggregation weights, the bound is obtained from a coupled-neighbor stability recursion combined with a weighted concentration step; the client-selection counts are retained explicitly via the amplification factor Y_i(C). In the uniform full-participation full-batch regime the bound recovers ilde O(n^{-1} + n^{-1/2}) scaling once horizon-dependent amplification terms are controlled. The derivation requires the matrix-orthogonalization map to be Lipschitz along paired trajectories (satisfied by regularized polar maps and normalized finite-step Newton-Schulz iterations); a one-dimensional counterexample demonstrates necessity of this regularity condition (or smoothing).
Significance. If the stability recursion and concentration steps are valid, the result supplies a non-asymptotic, client-sampling-aware generalization guarantee for a practically relevant class of momentum-based federated methods with matrix orthogonalization. The explicit dependence on Y_i(C) and the precise statement of the Lipschitz premise on the orthogonalizer are useful for understanding when stability arguments extend to this setting. The counterexample clarifies the boundary of the technique.
minor comments (3)
- The abstract states that the bound 'keeps the client-selection counts through the amplification factor Y_i(C)', but the precise definition of Y_i(C) and its dependence on the sampling process should be stated explicitly in the main theorem statement (presumably Theorem X) so that readers can verify the claimed non-circularity.
- The one-dimensional counterexample is mentioned but its construction is not reproduced in the abstract; including a short self-contained statement of the counterexample (or a pointer to the exact location) would strengthen the necessity claim.
- Notation for the horizon-dependent amplification terms should be introduced once and used consistently when discussing the ilde O(n^{-1} + n^{-1/2}) regime.
Simulated Author's Rebuttal
We thank the referee for the careful reading, the positive summary of the contribution, and the recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivation self-contained via stability recursion
full rationale
The paper derives its finite-round upper-tail generalization guarantee explicitly from a coupled-neighbor stability recursion plus weighted concentration step under stated assumptions (Lipschitz orthogonalization along trajectories, satisfied by regularized polar maps and normalized Newton-Schulz). The amplification factor Y_i(C) is introduced to retain client-selection counts inside the bound rather than being fitted or renamed as a prediction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked; the one-dimensional counterexample is supplied only to show necessity of the premise. The argument chain is independent of its own outputs and does not reduce any claimed result to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Independent heterogeneous client data and fixed aggregation weights
- domain assumption The orthogonalization map is Lipschitz along paired trajectories
Reference graph
Works this paper leans on
-
[1]
Stability and generalization.Journal of machine learning research, 2(Mar):499–526, 2002
Olivier Bousquet and Andr´ e Elisseeff. Stability and generalization.Journal of machine learning research, 2(Mar):499–526, 2002
2002
-
[2]
Train faster, generalize better: Stability of stochastic gradient descent
Moritz Hardt, Ben Recht, and Yoram Singer. Train faster, generalize better: Stability of stochastic gradient descent. InInternational conference on machine learning, pages 1225–1234. PMLR, 2016
2016
-
[3]
Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan. github. io/posts/muon, 6(3):4, 2024
2024
-
[4]
Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and Volkan Cevher. Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
Pith/arXiv arXiv 2025
-
[5]
On the convergence of muon and beyond.arXiv preprint arXiv:2509.15816, 2025
Da Chang, Yongxiang Liu, and Ganzhao Yuan. On the convergence of muon and beyond.arXiv preprint arXiv:2509.15816, 2025
Pith/arXiv arXiv 2025
-
[6]
On provable benefits of muon in federated learning.arXiv preprint arXiv:2510.03866, 2025
Xinwen Zhang and Hongchang Gao. On provable benefits of muon in federated learning.arXiv preprint arXiv:2510.03866, 2025
arXiv 2025
-
[7]
Junkang Liu, Fanhua Shang, Junchao Zhou, Hongying Liu, Yuanyuan Liu, and Jin Liu. Fedmuon: Accelerating federated learning with matrix orthogonalization.arXiv preprint arXiv:2510.27403, 2025
arXiv 2025
-
[8]
Computing the polar decomposition—with applications.SIAM Journal on Scientific and Statistical Computing, 7(4):1160–1174, 1986
Nicholas J Higham. Computing the polar decomposition—with applications.SIAM Journal on Scientific and Statistical Computing, 7(4):1160–1174, 1986
1986
-
[9]
New perturbation bounds for the unitary polar factor.SIAM Journal on Matrix Analysis and Applications, 16(1):327–332, 1995
Ren-Cang Li. New perturbation bounds for the unitary polar factor.SIAM Journal on Matrix Analysis and Applications, 16(1):327–332, 1995
1995
-
[10]
Iterative berechung der reziproken matrix.ZAMM-Journal of Applied Mathematics and Mechanics/Zeitschrift f¨ ur Angewandte Mathematik und Mechanik, 13(1):57–59, 1933
G¨ unther Schulz. Iterative berechung der reziproken matrix.ZAMM-Journal of Applied Mathematics and Mechanics/Zeitschrift f¨ ur Angewandte Mathematik und Mechanik, 13(1):57–59, 1933
1933
-
[11]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Pith/arXiv arXiv 2024
-
[12]
Noah Amsel, David Persson, Christopher Musco, and Robert M Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm.arXiv preprint arXiv:2505.16932, 2025
Pith/arXiv arXiv 2025
-
[13]
Yuki Takezawa, Anastasia Koloskova, Xiaowen Jiang, and Sebastian U Stich. Fedmuon: Federated learning with bias-corrected lmo-based optimization.arXiv preprint arXiv:2509.26337, 2025
arXiv 2025
-
[14]
Mimuon: Mixed muon optimizer with improved gener- alization for large models, 2026
Feihu Huang, Yuning Luo, and Songcan Chen. Mimuon: Mixed muon optimizer with improved gener- alization for large models, 2026
2026
-
[15]
High probability generalization bounds for uniformly stable algo- rithms with nearly optimal rate
Vitaly Feldman and Jan Vondrak. High probability generalization bounds for uniformly stable algo- rithms with nearly optimal rate. InConference on learning theory, pages 1270–1279. PMLR, 2019
2019
-
[16]
Sharper bounds for uniformly stable algo- rithms
Olivier Bousquet, Yegor Klochkov, and Nikita Zhivotovskiy. Sharper bounds for uniformly stable algo- rithms. InProceedings of the Thirty Third Conference on Learning Theory, volume 125 ofProceedings of Machine Learning Research, pages 610–626. PMLR, 2020
2020
-
[17]
On the method of bounded differences.Surveys in combinatorics, 141(1):148– 188, 1989
Colin McDiarmid et al. On the method of bounded differences.Surveys in combinatorics, 141(1):148– 188, 1989
1989
-
[18]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. Pmlr, 2017. 10
2017
-
[19]
Local sgd converges fast and communicates little.arXiv preprint arXiv:1805.09767, 2018
Sebastian U Stich. Local sgd converges fast and communicates little.arXiv preprint arXiv:1805.09767, 2018
Pith/arXiv arXiv 2018
-
[20]
Parallel restarted sgd with faster convergence and less com- munication: Demystifying why model averaging works for deep learning
Hao Yu, Sen Yang, and Shenghuo Zhu. Parallel restarted sgd with faster convergence and less com- munication: Demystifying why model averaging works for deep learning. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 5693–5700, 2019
2019
-
[21]
On the linear speedup analysis of communication efficient momentum sgd for distributed non-convex optimization
Hao Yu, Rong Jin, and Sen Yang. On the linear speedup analysis of communication efficient momentum sgd for distributed non-convex optimization. InInternational Conference on Machine Learning, pages 7184–7193. PMLR, 2019
2019
-
[22]
Scaffold: Stochastic controlled averaging for federated learning
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for federated learning. InIn- ternational conference on machine learning, pages 5132–5143. PMLR, 2020
2020
-
[23]
Adaptive federated optimization.arXiv preprint arXiv:2003.00295, 2020
Sashank Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇ cn` y, Sanjiv Kumar, and H Brendan McMahan. Adaptive federated optimization.arXiv preprint arXiv:2003.00295, 2020
Pith/arXiv arXiv 2003
-
[24]
Momentum benefits non-iid federated learning simply and provably
Ziheng Cheng, Xinmeng Huang, Pengfei Wu, and Kun Yuan. Momentum benefits non-iid federated learning simply and provably. InInternational Conference on Learning Representations, volume 2024, pages 9815–9848, 2024
2024
-
[25]
Yuanyuan Liu, Fanhua Shang, Hongying Liu, Jin Liu, Wei Feng, et al. Fedswa: Improving generalization in federated learning with highly heterogeneous data via momentum-based stochastic controlled weight averaging.arXiv preprint arXiv:2507.20016, 2025
Pith/arXiv arXiv 2025
-
[26]
Convergence of muon with newton-schulz.arXiv preprint arXiv:2601.19156, 2026
Gyu Yeol Kim and Min-hwan Oh. Convergence of muon with newton-schulz.arXiv preprint arXiv:2601.19156, 2026
arXiv 2026
-
[27]
Beyond the ideal: Analyzing the inexact muon update.arXiv preprint arXiv:2510.19933, 2025
Egor Shulgin, Sultan AlRashed, Francesco Orabona, and Peter Richt´ arik. Beyond the ideal: Analyzing the inexact muon update.arXiv preprint arXiv:2510.19933, 2025
arXiv 2025
-
[28]
Jianhao Ma, Yu Huang, Yuejie Chi, and Yuxin Chen. Preconditioning benefits of spectral orthogonal- ization in muon.arXiv preprint arXiv:2601.13474, 2026
arXiv 2026
-
[29]
Spectral flattening is all muon needs: How orthogonalization controls learning rate and convergence
Tien-Phat Nguyen, Truong Nguyen, Minh-Phuc Truong, Tuc Nguyen, James Bailey, and Trung Le. Spectral flattening is all muon needs: How orthogonalization controls learning rate and convergence. arXiv preprint arXiv:2605.13079, 2026
Pith/arXiv arXiv 2026
-
[30]
Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
arXiv 2025
-
[31]
Ruijie Zhang, Yequan Zhao, Ziyue Liu, Zhengyang Wang, Dongyang Li, Yupeng Su, Sijia Liu, and Zheng Zhang. Teon: Tensorized orthonormalization beyond layer-wise muon for large language model pre-training.arXiv preprint arXiv:2601.23261, 2026
arXiv 2026
-
[32]
Ziyue Liu, Ruijie Zhang, Zhengyang Wang, Yequan Zhao, Yupeng Su, Zi Yang, and Zheng Zhang. Muon2: Boosting muon via adaptive second-moment preconditioning.arXiv preprint arXiv:2604.09967, 2026
Pith/arXiv arXiv 2026
-
[33]
Muonbp: Faster muon via block-periodic orthogonalization.arXiv preprint arXiv:2510.16981, 2025
Ahmed Khaled, Kaan Ozkara, Tao Yu, Mingyi Hong, and Youngsuk Park. Muonbp: Faster muon via block-periodic orthogonalization.arXiv preprint arXiv:2510.16981, 2025
arXiv 2025
-
[34]
Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
arXiv 2025
-
[35]
Generalization bounds for uniformly stable algorithms.Advances in Neural Information Processing Systems, 31, 2018
Vitaly Feldman and Jan Vondrak. Generalization bounds for uniformly stable algorithms.Advances in Neural Information Processing Systems, 31, 2018. 11
2018
-
[36]
Nonconvex stochastic optimization under heavy-tailed noises: Optimal convergence without gradient clipping
Zijian Liu and Zhengyuan Zhou. Nonconvex stochastic optimization under heavy-tailed noises: Optimal convergence without gradient clipping. InInternational Conference on Learning Representations, volume 2025, pages 92529–92554, 2025
2025
-
[37]
Efficient distributed optimization under heavy-tailed noise
Su Hyeong Lee, Manzil Zaheer, and Tian Li. Efficient distributed optimization under heavy-tailed noise. arXiv preprint arXiv:2502.04164, 2025
arXiv 2025
-
[38]
Optimal complexity in byzantine-robust distributed stochastic optimization with data heterogeneity.Journal of Machine Learning Research, 26(268):1–58, 2025
Qiankun Shi, Jie Peng, Kun Yuan, Xiao Wang, and Qing Ling. Optimal complexity in byzantine-robust distributed stochastic optimization with data heterogeneity.Journal of Machine Learning Research, 26(268):1–58, 2025
2025
-
[39]
Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
Pith/arXiv arXiv 2025
-
[40]
Da Chang, Qiankun Shi, Lvgang Zhang, Yu Li, Ruijie Zhang, Yao Lu, Yongxiang Liu, and Ganzhao Yuan. Muoneq: Balancing before orthogonalization with lightweight equilibration.arXiv preprint arXiv:2603.28254, 2026
Pith/arXiv arXiv 2026
-
[41]
Mgup: A momentum-gradient alignment update policy for stochastic optimization.Advances in Neural Information Processing Systems, 38:20488–20537, 2026
Da Chang and Ganzhao Yuan. Mgup: A momentum-gradient alignment update policy for stochastic optimization.Advances in Neural Information Processing Systems, 38:20488–20537, 2026
2026
-
[42]
Tian Zhang, Yujia Tong, Junhao Dong, Ke Xu, Yuze Wang, and Jingling Yuan. Forget by uncertainty: Orthogonal entropy unlearning for quantized neural networks.arXiv preprint arXiv:2602.00567, 2026
Pith/arXiv arXiv 2026
-
[43]
Robust machine unlearning for quantized neural networks via adaptive gradient reweighting with similar labels
Yujia Tong, Yuze Wang, Jingling Yuan, and Chuang Hu. Robust machine unlearning for quantized neural networks via adaptive gradient reweighting with similar labels. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 20603–20612, October 2025
2025
-
[44]
Calibrating and rotating: A unified framework for weight conditioning in peft
Da Chang, Peng Xue, Yu Li, Yongxiang Liu, Pengxiang Xu, and Shixun Zhang. Calibrating and rotating: A unified framework for weight conditioning in peft. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30174–30182, 2026
2026
-
[45]
Yu Li, Sizhe Tang, and Tian Lan. Reason in chains, learn in trees: Self-rectification and grafting for multi-turn agent policy optimization.arXiv preprint arXiv:2604.07165, 2026
Pith/arXiv arXiv 2026
-
[46]
Yu Li, Tian Lan, and Zhengling Qi. Inspo: Unlocking intrinsic self-reflection for llm preference opti- mization.arXiv preprint arXiv:2512.23126, 2025
arXiv 2025
-
[47]
Yu Li, Rui Miao, Tian Lan, and Zhengling Qi. Oppo: Bayesian value recursion for token-level credit assignment in llm reasoning.arXiv preprint arXiv:2605.21851, 2026
Pith/arXiv arXiv 2026
-
[48]
Yu Li, Da Chang, and Xi Xiao. Kg-sam: Injecting anatomical knowledge into segment anything models via conditional random fields.arXiv preprint arXiv:2509.21750, 2025
arXiv 2025
-
[49]
Spielman, and Shang-Hua Teng
Arvind Sankar, Daniel A. Spielman, and Shang-Hua Teng. Smoothed analysis of the condition numbers and growth factors of matrices.SIAM Journal on Matrix Analysis and Applications, 28(2):446–476, 2006
2006
-
[50]
The littlewood–offord problem and invertibility of random matrices.Advances in Mathematics, 218(2):600–633, 2008
Mark Rudelson and Roman Vershynin. The littlewood–offord problem and invertibility of random matrices.Advances in Mathematics, 218(2):600–633, 2008
2008
-
[51]
εpart(ρ) log(4n) log4 δ +B ℓ r log(4/δ) n # . Ifa s ≤C aηLOrthEfor alls, then, up to universal constants and logarithms, ΨR,E,K,N (ρ) =O CaηLOrthE
Roman Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science, volume 47 ofCambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2018. 12 A Additional Related Work FedAvg established periodic server averaging of local stochastic updates as a central algorithmic template for communicati...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.