A Theoretical Framework for Self-Play Theorem Proving Algorithms
Pith reviewed 2026-06-28 15:31 UTC · model grok-4.3
The pith
If a theorem graph is well-connected, a prover paired with a reversible-random-walk conjecturer grows the set of proved theorems exponentially.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that if the underlying graph of theorems is well-connected, then a prover-conjecturer system, where the conjecturing algorithm is based on a reversible random walk, is sufficient to grow the set of proved theorems exponentially.
What carries the argument
The theorem graph (nodes as theorems, edges as semantic similarity) together with a reversible random walk on that graph that drives conjecture generation.
If this is right
- Self-play between prover and conjecturer can scale the proved set without any external source of new theorems.
- A reversible random walk on the semantic graph is a sufficient mechanism for sustained exploration.
- Maximizing a diffusion-similarity diversity objective locally reduces the generation of artificially complex statements.
- Contrastive embeddings of graph nodes yield a practical way to compute the required diffusion similarities.
Where Pith is reading between the lines
- The same connectivity-plus-random-walk argument may apply to self-play curricula in other formal domains such as program synthesis.
- If real-world theorem graphs contain disconnected components, additional bridging mechanisms would be required for the exponential-growth guarantee to hold.
- The diversity-maximization step suggests a general recipe for preventing mode collapse in any graph-based self-improvement loop.
Load-bearing premise
The primitive assumptions that fix the trained prover’s success guarantees and the conjecturer’s access to the structure of the theorem graph are satisfied.
What would settle it
Simulate or construct a finite, well-connected theorem graph, run the prover-conjecturer loop for many iterations, and check whether the size of the proved set increases exponentially rather than linearly or sub-linearly.
Figures

read the original abstract
Self-play, a type of training algorithm that enables a model to self-improve, has recently shown promising empirical results in the context of formal theorem proving using Large Language Models (LLMs). (Dong & Ma, 2025) instantiate self-play with two cooperating agents: a prover, which proves theorems, and a conjecturer, which generates new theorems as a curriculum to the prover. In this paper, we provide a theoretical framework for understanding the self-improvement capabilities of self-play algorithms for theorem proving. First, we formalize the set of theorems as a graph, with nodes as theorems and edges between pairs of theorems with similar semantics. We introduce a set of primitive assumptions that characterize the guarantees of a trained prover and how a conjecturer can access the structure of the graph. Second, we show that if the underlying graph of theorems is well-connected, then a prover-conjecturer system, where the conjecturing algorithm is based on a reversible random walk, is sufficient to grow the set of proved theorems exponentially. Third, motivated by an issue encountered empirically by self-play algorithms, where the conjecturer tends to generate artificially complex and non-fundamental theorems, we propose a diversity measure for a training distribution of theorems generated by a conjecturer and an improved conjecturing algorithm that locally maximizes this diversity measure, by computing the diffusion similarity between neighboring theorems in the theorem graph. Finally, we describe a method to compute the diffusion similarity by using contrastive learning to embed nodes into Euclidean space and then computing the inner-product between embeddings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes self-play theorem proving as a prover-conjecturer pair operating on a graph whose nodes are theorems and edges connect semantically similar theorems. It introduces a set of primitive assumptions characterizing a trained prover's success probabilities and a conjecturer's access to local graph structure. Under these assumptions plus the condition that the theorem graph is well-connected, the central result asserts that a conjecturer implemented via reversible random walk suffices to produce exponential growth in the number of proved theorems. The paper further defines a diversity measure on the conjecturer's output distribution and gives an improved conjecturing procedure that locally maximizes this measure by computing diffusion similarity (via contrastive embeddings of nodes).
Significance. If the exponential-growth claim is rigorously established, the work supplies the first formal account of why self-play can drive unbounded improvement in LLM-based theorem provers, directly addressing the empirical observation that conjecturers tend to produce overly complex statements. The graph-theoretic model and the diffusion-similarity construction are reusable abstractions that could guide both algorithm design and future analyses of exploration in formal mathematics.
major comments (2)
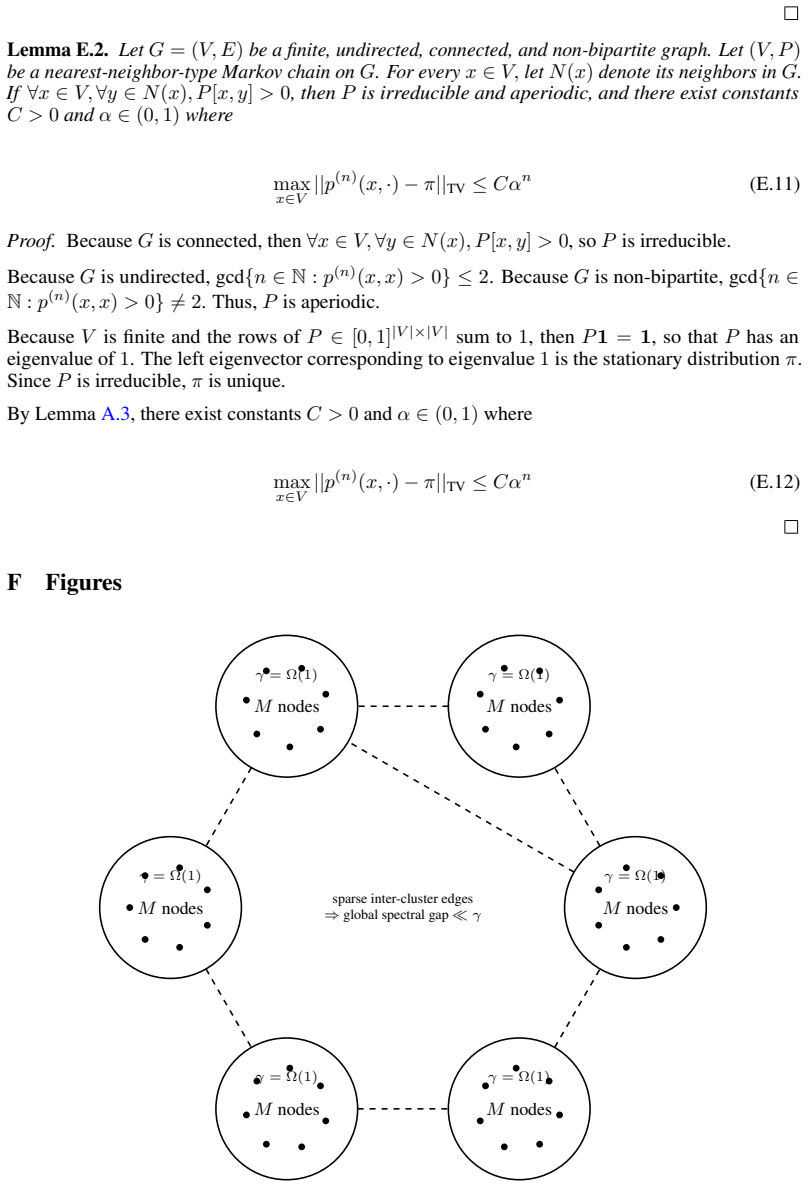
- [§3] §3 (exponential-growth theorem): the statement that a reversible random walk on a 'well-connected' graph yields exponential growth of the proved set is load-bearing. Standard random-walk theory shows that path-connectedness alone (finite diameter) produces at most linear coverage per iteration because cover times and hitting times scale polynomially with graph size; exponential growth requires a uniform lower bound on conductance or spectral gap independent of graph size. The manuscript must either (a) strengthen the definition of 'well-connected' to include such a quantitative expansion hypothesis or (b) exhibit an explicit lemma deriving a multiplicative factor from the primitive assumptions and the walk's transition probabilities.
- [Primitive assumptions section] Primitive-assumptions section (first part of the paper): the assumptions encode prover success probability and conjecturer access to neighbors, yet the growth analysis must show how these translate into a constant-probability discovery of new provable theorems each round. Without an explicit bound relating the walk's stationary distribution or mixing time to the fraction of newly proved nodes, the sufficiency claim reduces to the modeling choices rather than following from them.
minor comments (2)
- [Abstract] The citation 'Dong & Ma, 2025' appears in the abstract but is not expanded in the bibliography; a full reference should be supplied.
- [Diversity and improved conjecturer section] Notation for the diffusion similarity (inner product of contrastive embeddings) should be introduced with an equation number when first defined, to aid readability of the improved conjecturing algorithm.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the technical requirements needed to make the exponential-growth claim rigorous. We address each major comment below and will revise the manuscript to incorporate the suggested strengthenings.
read point-by-point responses
-
Referee: [§3] §3 (exponential-growth theorem): the statement that a reversible random walk on a 'well-connected' graph yields exponential growth of the proved set is load-bearing. Standard random-walk theory shows that path-connectedness alone (finite diameter) produces at most linear coverage per iteration because cover times and hitting times scale polynomially with graph size; exponential growth requires a uniform lower bound on conductance or spectral gap independent of graph size. The manuscript must either (a) strengthen the definition of 'well-connected' to include such a quantitative expansion hypothesis or (b) exhibit an explicit lemma deriving a multiplicative factor from the primitive assumptions and the walk's transition probabilities.
Authors: We agree that path-connectedness alone is insufficient and that a quantitative expansion condition is required for exponential growth. In the revised manuscript we adopt option (a): we strengthen the definition of 'well-connected' to require a uniform lower bound on conductance (equivalently, spectral gap) that is independent of graph size. We will also insert an explicit lemma in §3 that derives the multiplicative growth factor from this conductance bound, the reversible random-walk transition matrix, and the primitive prover-success probabilities. revision: yes
-
Referee: [Primitive assumptions section] Primitive-assumptions section (first part of the paper): the assumptions encode prover success probability and conjecturer access to neighbors, yet the growth analysis must show how these translate into a constant-probability discovery of new provable theorems each round. Without an explicit bound relating the walk's stationary distribution or mixing time to the fraction of newly proved nodes, the sufficiency claim reduces to the modeling choices rather than following from them.
Authors: We acknowledge that the translation from the primitive assumptions to a constant per-round discovery probability is not yet fully explicit. We will add a lemma in the primitive-assumptions section that supplies an explicit lower bound on the probability of discovering new provable theorems. The lemma will relate the stationary distribution and mixing time of the random walk (under the strengthened conductance condition) to the fraction of newly proved nodes, using the prover success probabilities stated in the assumptions. revision: yes
Circularity Check
No significant circularity; sufficiency theorem is conditional on explicitly introduced primitive assumptions.
full rationale
The paper introduces a set of primitive assumptions characterizing prover guarantees and conjecturer graph access, then proves a conditional sufficiency result: under those assumptions plus well-connectedness, the reversible random walk conjecturer yields exponential growth of the proved set. This is a standard conditional mathematical derivation, not a reduction of the claimed result to its inputs by construction. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work are present in the provided text. The diversity and embedding sections are separate algorithmic proposals without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The set of theorems forms a graph with edges between pairs of theorems with similar semantics.
- ad hoc to paper Primitive assumptions characterize the guarantees of a trained prover and how a conjecturer can access the structure of the graph.
invented entities (1)
-
Theorem graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2004 , url=
Random Walks on Infinite Graphs and Groups , author=. 2004 , url=
2004
-
[2]
1978 , url=
Introductory Functional Analysis with Applications , author=. 1978 , url=
1978
-
[3]
2022 , url=
Lecture Notes for Machine Learning Theory , author=. 2022 , url=
2022
-
[4]
2017 , url=
Markov Chains and Mixing Times , author=. 2017 , url=
2017
-
[5]
2012 , journal=
Pseudorandomness , author=. 2012 , journal=
2012
-
[6]
2025 , eprint=
Metastable Dynamics of Chain-of-Thought Reasoning: Provable Benefits of Search, RL and Distillation , author=. 2025 , eprint=
2025
-
[7]
2018 , eprint=
Symmetry, Saddle Points, and Global Optimization Landscape of Nonconvex Matrix Factorization , author=. 2018 , eprint=
2018
-
[8]
2022 , eprint=
Provable Guarantees for Self-Supervised Deep Learning with Spectral Contrastive Loss , author=. 2022 , eprint=
2022
-
[9]
2016 , eprint=
Low-rank Solutions of Linear Matrix Equations via Procrustes Flow , author=. 2016 , eprint=
2016
-
[10]
Diffusion Distance , author=
Lecture 6. Diffusion Distance , author=. 2011 , url=
2011
-
[11]
2013 , url=
Fantope Projection and Selection: Near-Optimal Convex Relaxation of Sparse PCA , author=. 2013 , url=
2013
-
[12]
2017 , url=
Interpretations for Principal Component Analysis , author=. 2017 , url=
2017
-
[13]
2025 , eprint=
STP: Self-play LLM Theorem Provers with Iterative Conjecturing and Proving , author=. 2025 , eprint=
2025
-
[14]
2020 , eprint=
Near-Optimal Reinforcement Learning with Self-Play , author=. 2020 , eprint=
2020
-
[15]
2025 , eprint=
Early science acceleration experiments with GPT-5 , author=. 2025 , eprint=
2025
-
[16]
2017 , eprint=
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm , author=. 2017 , eprint=
2017
-
[17]
2021 , eprint=
Improved Sample Complexities for Deep Networks and Robust Classification via an All-Layer Margin , author=. 2021 , eprint=
2021
-
[18]
2021 , eprint=
MiniF2F: a Cross-System Benchmark for Formal Olympiad-Level Mathematics , author=. 2021 , eprint=
2021
-
[19]
2023 , eprint=
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics , author=. 2023 , eprint=
2023
-
[20]
2022 , eprint=
Formal Mathematics Statement Curriculum Learning , author=. 2022 , eprint=
2022
-
[21]
2022 , eprint=
Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers , author=. 2022 , eprint=
2022
-
[22]
2023 , eprint=
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models , author=. 2023 , eprint=
2023
-
[23]
2023 , eprint=
Baldur: Whole-Proof Generation and Repair with Large Language Models , author=. 2023 , eprint=
2023
-
[24]
2024 , eprint=
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data , author=. 2024 , eprint=
2024
-
[25]
Nature , volume=
Solving olympiad geometry without human demonstrations , author=. Nature , volume=. 2024 , doi=
2024
-
[27]
Nature Machine Intelligence , year=
Proposing and solving olympiad geometry with guided tree search , author=. Nature Machine Intelligence , year=. doi:10.1038/s42256-025-01164-x , url=
-
[28]
2025 , eprint=
LeanConjecturer: Automatic Generation of Mathematical Conjectures for Theorem Proving , author=. 2025 , eprint=
2025
-
[29]
2024 , url=
Synthetic Theorem Generation in Lean , author=. 2024 , url=
2024
-
[30]
2024 , eprint=
3D-Prover: Diversity Driven Theorem Proving With Determinantal Point Processes , author=. 2024 , eprint=
2024
-
[31]
2025 , url=
Usefulness-Driven Learning of Formal Mathematics , author=. 2025 , url=
2025
-
[32]
Proceedings of the 38th International Conference on Machine Learning , series=
A Sharp Analysis of Model-based Reinforcement Learning with Self-Play , author=. Proceedings of the 38th International Conference on Machine Learning , series=. 2021 , url=
2021
-
[33]
2021 , eprint=
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments , author=. 2021 , eprint=
2021
-
[34]
2024 , eprint=
Learning Formal Mathematics From Intrinsic Motivation , author=. 2024 , eprint=
2024
-
[35]
2025 , url=
Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad , author=. 2025 , url=
2025
-
[36]
Aristotle:
Tudor Achim and others , journal =. Aristotle:. 2025 , url =
2025
-
[37]
Horv \'a th, Goran Z u z i \'c , Eric Wieser, Aja Huang, Julian Schrittwieser, et al
Olympiad-level formal mathematical reasoning with reinforcement learning , author =. Nature , year =. doi:10.1038/s41586-025-09833-y , url =
-
[38]
2024 , url =
Zijian Wu and Suozhi Huang and Zhejian Zhou and Huaiyuan Ying and Jiayu Wang and Dahua Lin and Kai Chen , journal =. 2024 , url =
2024
-
[39]
2025 , url =
Ran Xin and others , journal =. 2025 , url =
2025
-
[40]
Scaling up Multi-Turn Off-Policy
Ran Xin and Zeyu Zheng and Yanchen Nie and Kun Yuan and Xia Xiao , journal =. Scaling up Multi-Turn Off-Policy. 2025 , url =
2025
-
[41]
2025 , url =
Luoxin Chen and others , journal =. 2025 , url =
2025
-
[42]
2025 , url =
Xingguang Ji and Yahui Liu and Qi Wang and Jingyuan Zhang and Yang Yue and Rui Shi and Chenxi Sun and Fuzheng Zhang and Guorui Zhou and Kun Gai , journal =. 2025 , url =
2025
-
[43]
2025 , url =
Yong Lin and Shange Tang and Bohan Lyu and Jiayun Wu and Hongzhou Lin and Kaiyu Yang and Jia Li and Mengzhou Xia and Danqi Chen and Sanjeev Arora and Chi Jin , journal =. 2025 , url =
2025
-
[44]
2025 , url =
Yong Lin and others , journal =. 2025 , url =
2025
-
[45]
Z. Z. Ren and others , journal =. 2025 , url =
2025
-
[46]
2025 , url =
Shijie Shang and Ruosi Wan and Yue Peng and Yutong Wu and Xiong-hui Chen and Jie Yan and Xiangyu Zhang , journal =. 2025 , url =
2025
-
[47]
2025 , url =
Haiming Wang and others , journal =. 2025 , url =
2025
-
[48]
2025 , url =
Huajian Xin and others , booktitle =. 2025 , url =
2025
-
[49]
arXiv preprint arXiv:2507.15225 , year =
Solving Formal Math Problems by Decomposition and Iterative Reflection , author =. arXiv preprint arXiv:2507.15225 , year =
-
[50]
arXiv preprint arXiv:2406.03847 , year =
Lean Workbook: A Large-Scale Lean Problem Set Formalized from Natural Language Math Problems , author =. arXiv preprint arXiv:2406.03847 , year =
-
[51]
arXiv preprint arXiv:2407.11214 , year =
PutnamBench: Evaluating Neural Theorem-Provers on the Putnam Mathematical Competition , author =. arXiv preprint arXiv:2407.11214 , year =
-
[52]
Automated Deduction–CADE 28: 28th International Conference on Automated Deduction , year =
The lean 4 theorem prover and programming language , author =. Automated Deduction–CADE 28: 28th International Conference on Automated Deduction , year =
-
[53]
Springer , year =
Isabelle/HOL: a proof assistant for higher-order logic , author =. Springer , year =
-
[54]
MIT Press , year =
An Introduction to Computational Learning Theory , author =. MIT Press , year =
-
[55]
Communications in Mathematical Physics , year =
Metastability and low lying spectra in reversible Markov chains , author =. Communications in Mathematical Physics , year =
-
[56]
2026 , eprint=
On Learning Verifiers and Implications to Chain-of-Thought Reasoning , author=. 2026 , eprint=
2026
-
[57]
2017 , eprint=
Wasserstein GAN , author=. 2017 , eprint=
2017
-
[58]
2022 , eprint=
Theoretical Analysis of Self-Training with Deep Networks on Unlabeled Data , author=. 2022 , eprint=
2022
-
[59]
2026 , eprint=
Artificial Intelligence and the Structure of Mathematics , author=. 2026 , eprint=
2026
-
[60]
2006 , url=
Natural Deduction via Graphs: Formal Definition and Computation Rules , author=. 2006 , url=
2006
-
[61]
2006 , journal =
Diffusion maps , author=. 2006 , journal =
2006
-
[62]
1950 , journal =
On a Theorem of Weyl Concerning Eigenvalues of Linear Transformations , author=. 1950 , journal =
1950
-
[63]
1991 , journal =
On the Sum of the Largest Eigenvalues of a Symmetric Matrix , author=. 1991 , journal =
1991
-
[64]
1936 , journal =
The approximation of one matrix by another of lower rank , author=. 1936 , journal =
1936
-
[65]
2006 , journal =
Diffusion Maps and Coarse-Graining: A Unified Framework for Dimensionality Reduction, Graph Partitioning and Data Set Parameterization , author=. 2006 , journal =
2006
-
[66]
Journal of the American Statistical Association , volume =
Probability Inequalities for Sums of Bounded Random Variables , author =. Journal of the American Statistical Association , volume =. 1963 , doi =
1963
-
[67]
2019 , eprint=
Representation Learning with Contrastive Predictive Coding , author=. 2019 , eprint=
2019
-
[68]
2020 , eprint=
A Simple Framework for Contrastive Learning of Visual Representations , author=. 2020 , eprint=
2020
-
[69]
Dimensionality Reduction by Learning an Invariant Mapping , author =. 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06) , volume =. 2006 , publisher =. doi:10.1109/CVPR.2006.100 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.