Edge-aware Decoding for Neural Asymmetric Routing
Pith reviewed 2026-06-28 15:13 UTC · model grok-4.3
The pith
An edge-aware decoder improves neural asymmetric routing by scoring directed transitions explicitly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
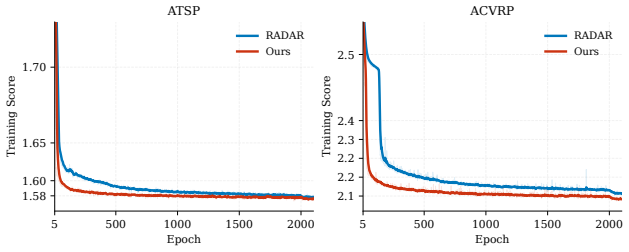
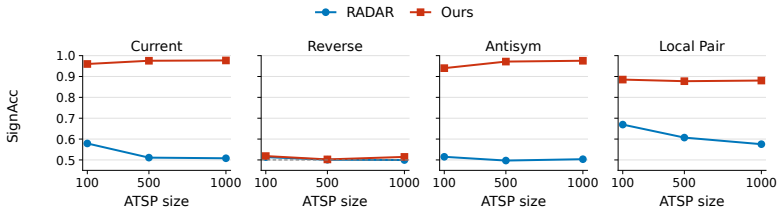
On a controlled SVD/Sinkhorn asymmetric backbone, the decoder improves over the RADAR reference when trained on ATSP-100 and evaluated zero-shot on ATSP-100/200/500/1000, reducing the ATSP-1000 gap from 4.13% to 2.73%. On ACVRP, the same score-level modification shows the same qualitative trend under a richer routing state. ATSP ablations and directed-transition diagnostics sharpen the mechanism: the strongest evidence concerns sensitivity to the current directed edge, while closure and static lookahead act as heuristic continuation cues.
What carries the argument
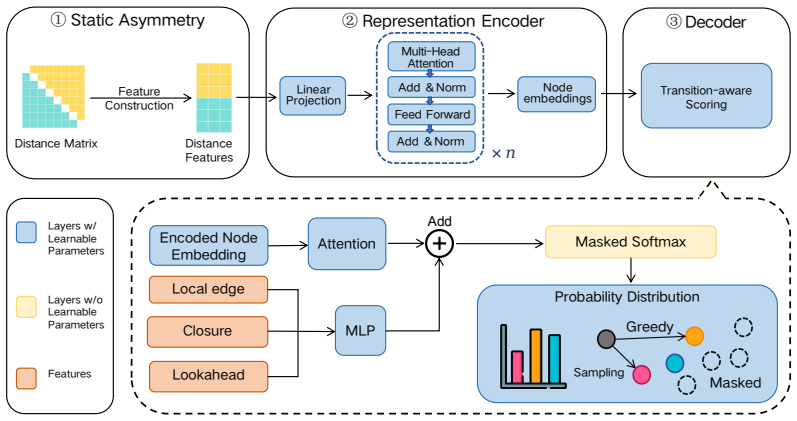
The edge-aware decoder, which adds candidate-specific terms for the current directed edge, return-to-start closure, and static lightweight lookahead to the final logit.
If this is right
- Training on ATSP-100 yields better zero-shot performance on ATSP-1000 than the prior reference decoder.
- The qualitative improvement appears under richer state representations on ACVRP.
- Ablations isolate the current directed edge as the strongest contributing signal.
- Directed-transition diagnostics support the value of decision-time edge information exposure.
Where Pith is reading between the lines
- The fixed-backbone design isolates the decoder contribution, suggesting similar score-level changes could be tested on other asymmetric combinatorial problems.
- If the directed-edge term drives generalization, explicit transition scoring may help close gaps on even larger instances beyond 1000 nodes.
- The mechanism points toward examining whether dynamic rather than static lookahead would amplify the effect in richer routing settings.
Load-bearing premise
The performance gains are attributable to the decoder exposing transition-level edge information rather than other unmentioned factors, with the representation backbone held fixed across comparisons.
What would settle it
If removing only the current-directed-edge term while retaining the other decoder additions eliminates the gap reduction on ATSP-1000, or if a different backbone yields no gain from the same change, the attribution to transition-level exposure would be falsified.
Figures
read the original abstract
Neural asymmetric routing models increasingly encode directionality through matrix representations and asymmetry-aware attention. The final routing action, however, is not a node in isolation but a directed transition chosen under the current partial route. This creates a representation--decision mismatch: pairwise cost information may be encoded upstream while the final candidate logit is still largely parameterized as context--node compatibility. We propose a decoder-design principle for neural asymmetric routing: the final score should explicitly expose transition-level quantities suggested by the problem's cost-to-go structure. We instantiate this principle with an edge-aware decoder that adds candidate-specific terms for the current directed edge, return-to-start closure, and static lightweight lookahead, while keeping the representation backbone fixed. On a controlled SVD/Sinkhorn asymmetric backbone, the decoder improves over the RADAR reference when trained on ATSP-100 and evaluated zero-shot on ATSP-100/200/500/1000, reducing the ATSP-1000 gap from $4.13\%$ to $2.73\%$. On ACVRP, the same score-level modification shows the same qualitative trend under a richer routing state. ATSP ablations and directed-transition diagnostics sharpen the mechanism: the strongest evidence concerns sensitivity to the current directed edge, while closure and static lookahead act as heuristic continuation cues. The results support a mechanism study: a key decoder-side signal in neural asymmetric routing is decision-time exposure of transition-level edge information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an edge-aware decoder for neural asymmetric routing (ATSP and ACVRP) that augments the final logit with explicit terms for the current directed edge, return-to-start closure, and static lookahead, while holding the SVD/Sinkhorn representation backbone fixed. It reports that this yields zero-shot improvements over the RADAR baseline when trained on ATSP-100 and evaluated on ATSP-100/200/500/1000 (reducing the ATSP-1000 gap from 4.13% to 2.73%), with a similar qualitative trend on ACVRP; ablations and directed-transition diagnostics are presented as supporting evidence that the gains stem from exposing transition-level edge information.
Significance. If the attribution to transition-level exposure holds, the work offers a concrete decoder-design principle that addresses a representation-decision mismatch in asymmetric routing models. The controlled fixed-backbone comparison and zero-shot scaling to larger instances are strengths, as are the reported ablations; these elements provide a falsifiable empirical test of the proposed mechanism on standard benchmarks.
major comments (2)
- [Experiments] Experiments section (results on ATSP-1000 gap reduction): the central claim that the 4.13%→2.73% improvement is attributable to the three semantic terms requires isolation from capacity or optimization effects. The manuscript should report parameter-matched controls (e.g., replacing the directed-edge/closure/lookahead additives with random or constant vectors of identical dimension) or explicit parameter counts before/after the modification.
- [Experiments] Experiments section (ATSP and ACVRP results): variance, number of random seeds, and instance-exclusion rules are not reported for the gap figures or qualitative trends. Without these, the robustness of the zero-shot scaling claim cannot be assessed.
minor comments (2)
- [Abstract] Abstract and §3: the phrase 'keeping the representation backbone fixed' should be accompanied by an explicit statement of which layers/parameters remain frozen versus updated during decoder training.
- [Tables/Figures] Figure captions and Table 1: axis labels and column headers should clarify whether gaps are reported as mean or median and over how many instances.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, committing to revisions where appropriate while defending the existing experimental design on substance.
read point-by-point responses
-
Referee: [Experiments] Experiments section (results on ATSP-1000 gap reduction): the central claim that the 4.13%→2.73% improvement is attributable to the three semantic terms requires isolation from capacity or optimization effects. The manuscript should report parameter-matched controls (e.g., replacing the directed-edge/closure/lookahead additives with random or constant vectors of identical dimension) or explicit parameter counts before/after the modification.
Authors: We agree that isolating semantic contribution from capacity is valuable. The edge-aware modification adds three scalar additives, each via a linear projection of the directed-edge embedding (adding 3d parameters where d is the hidden dimension). In revision we will report exact parameter counts for the final logit layer in both models, confirming the increase is <1%. The fixed SVD/Sinkhorn backbone already controls for representation capacity, and the term-wise ablations (showing differential sensitivity, especially to the current directed edge) provide evidence that gains arise from the specific transition-level signals rather than generic added parameters. We did not run random-vector replacement controls, as they would require new training runs; the existing controlled comparison and ablations address the core attribution claim. revision: partial
-
Referee: [Experiments] Experiments section (ATSP and ACVRP results): variance, number of random seeds, and instance-exclusion rules are not reported for the gap figures or qualitative trends. Without these, the robustness of the zero-shot scaling claim cannot be assessed.
Authors: We acknowledge the omission. All reported gaps were obtained from models trained with 3 independent random seeds; we will add mean and standard deviation to every ATSP and ACVRP table in the revision. Training instances were generated with a fixed seed, and zero-shot test sets for n>100 used distinct generation seeds to ensure no instance overlap with the ATSP-100 training distribution. These details, together with the exact instance counts, will be stated explicitly in the Experiments section. revision: yes
Circularity Check
No circularity; empirical gains on held-out instances with fixed backbone
full rationale
The paper advances a decoder design principle and reports zero-shot performance improvements on ATSP-100/200/500/1000 after training on ATSP-100, with the SVD/Sinkhorn representation backbone held fixed across comparisons. No derivation chain, fitted parameter, or uniqueness theorem is invoked that reduces the reported gap reductions (e.g., 4.13% to 2.73% on ATSP-1000) to quantities defined by the paper's own equations or self-citations. The central evidence consists of controlled empirical ablations and diagnostics on external test sets, which remain falsifiable outside any internal fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Chengrui Gao, Haopu Shang, Ke Xue, Dong Li, and Chao Qian
URL https://arxiv.org/ abs/2406.15007. Chengrui Gao, Haopu Shang, Ke Xue, Dong Li, and Chao Qian. Towards generalizable neural solvers for vehicle routing problems via ensemble with transferrable local policy.arXiv preprint arXiv:2308.14104,
-
[3]
URLhttps://arxiv.org/abs/2308.14104. Keld Helsgaun. An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems. Technical report, Roskilde University,
-
[4]
Wouter Kool, Herke van Hoof, and Max Welling
URL https://arxiv.org/abs/2503.00753. Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems! In International Conference on Learning Representations,
-
[5]
Yeong-Dae Kwon, Jinho Choo, Iljoo Yoon, Minah Park, Duwon Park, and Youngjune Gwon
URL https://proceedings.neurips.cc/paper_files/paper/2020/hash/ f231f2107df69eab0a3862d50018a9b2-Abstract.html. Yeong-Dae Kwon, Jinho Choo, Iljoo Yoon, Minah Park, Duwon Park, and Youngjune Gwon. Matrix encoding networks for neural combinatorial optimization. InAdvances in Neural Information Pro- cessing Systems, volume 34,
2020
-
[6]
Wenzheng Pan, Hao Xiong, Jiale Ma, Wentao Zhao, Yang Li, and Junchi Yan
URL https://proceedings.neurips.cc/paper_files/paper/ 2023/hash/1c10d0c087c14689628124bbc8fa69f6-Abstract-Conference.html. Wenzheng Pan, Hao Xiong, Jiale Ma, Wentao Zhao, Yang Li, and Junchi Yan. UniCO: On unified combinatorial optimization via problem reduction to matrix-encoded general TSP. InInternational Conference on Learning Representations,
2023
-
[7]
Cong Dao Tran, Quan Nguyen-Tri, Huynh Thi Thanh Binh, and Thanh-Tung Hoang
URLhttps://openreview.net/pdf?id=MGLt2k07KC. Cong Dao Tran, Quan Nguyen-Tri, Huynh Thi Thanh Binh, and Thanh-Tung Hoang. Large Language Models powered neural solvers for generalized vehicle routing problems. InICLR 2025 Workshop on Towards Agentic AI for Science: Hypothesis Generation, Comprehension, Quantification, and Validation,
2025
-
[9]
Haoran Ye, Jiarui Wang, Helan Liang, Zhiguang Cao, Yong Li, and Fanzhang Li
URLhttps://arxiv.org/abs/2401.06979. Haoran Ye, Jiarui Wang, Helan Liang, Zhiguang Cao, Yong Li, and Fanzhang Li. GLOP: Learning global partition and local construction for solving large-scale routing problems in real-time. In Proceedings of the AAAI Conference on Artificial Intelligence,
-
[10]
doi: 10.1609/aaai.v38i18. 30009. URLhttps://doi.org/10.1609/aaai.v38i18.30009. Hang Yi, Ziwei Huang, Yining Ma, and Zhiguang Cao. RADAR: Learning to route with asymmetry- aware DistAnce representations. InInternational Conference on Learning Representations,
-
[11]
URLhttps://openreview.net/forum?id=lWdxX5s9T1
doi: 10.48550/arXiv.2603.03388. URLhttps://openreview.net/forum?id=lWdxX5s9T1. 10 Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yan- ming Shen, and Tie-Yan Liu. Do Transformers really perform bad for graph representation? InAdvances in Neural Information Processing Systems, vol- ume 34,
-
[12]
Zhi Zheng, Changliang Zhou, Xialiang Tong, Mingxuan Yuan, and Zhenkun Wang
URL https://proceedings.neurips.cc/paper_files/paper/2021/ hash/f1c1592588411002af340cbaedd6fc33-Abstract.html. Zhi Zheng, Changliang Zhou, Xialiang Tong, Mingxuan Yuan, and Zhenkun Wang. UDC: A unified neural divide-and-conquer framework for large-scale combinatorial op- timization problems. InAdvances in Neural Information Processing Systems, vol- ume 37,
2021
-
[14]
URLhttps://arxiv.org/abs/2405.01906. 11 A Reproducibility Details The experiments are implemented as patches to the RADAR codebase [Yi et al., 2026]. The repository layout used by the experiments has separate task directories atsp/ and acvrp/, each containing the corresponding environment, model, trainer, tester, train.py, and test.py. The decoder- aware ...
Pith/arXiv arXiv 2026
-
[15]
Table 3 summarizes the fixed evaluation files and upstream RADAR artifacts used for testing and initialization. ATSP costs are divided by 106 when loaded, and both ATSP and ACVRP models use instance-level z-score normalization for the directed distance matrix before constructing SVD and edge features. The RADAR OpenReview paper is CC BY 4.0; separate Goog...
2001
-
[16]
7.8060 0.59%21.2311.0026 3.13% 144.00 19.0705 15.23%160.2029.4544 27.40%160.20POMO + Ours + aug×8(epoch
arXiv 2029
-
[17]
Lower gap is better; more negative ∆Total is better
7.7876 0.36% 89.40 10.8985 2.16% 683.4017.7800 7.43%1036.2025.8044 11.61%840.60POMO + aug×8(epoch 2000, original checkpoint)7.7740 0.18%21.8810.8569 1.77% 142.2020.1675 21.86% 200.39 32.4935 40.54%160.20 Table 8: Exploratory ELG-style decoder-bias check on TSPLIB and VRPLIB-X. Lower gap is better; more negative ∆Total is better. The “Large” bucket denotes...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.