BlockGen: Flexible Blockwise Sequence Modeling with Hybrid Samplers
Pith reviewed 2026-06-28 15:26 UTC · model grok-4.3
The pith
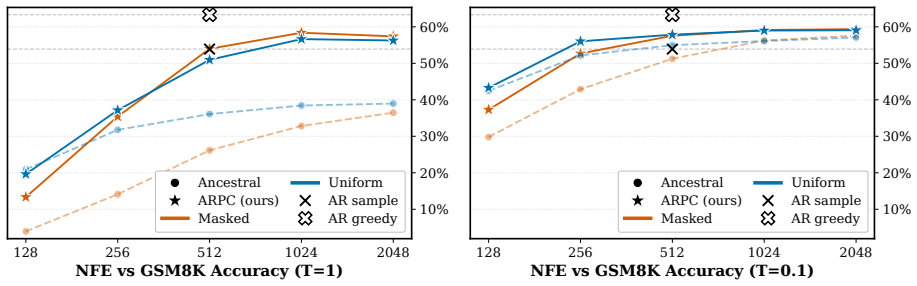
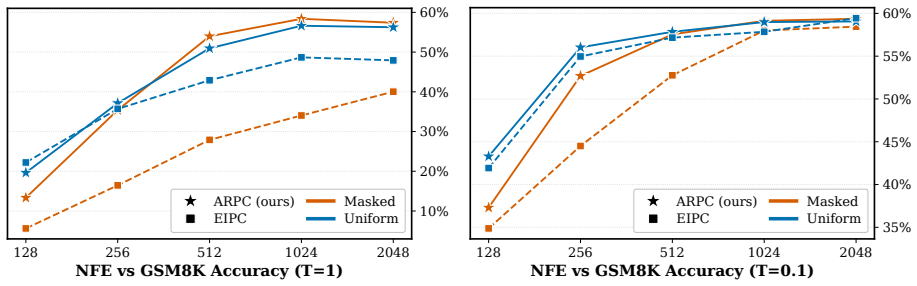
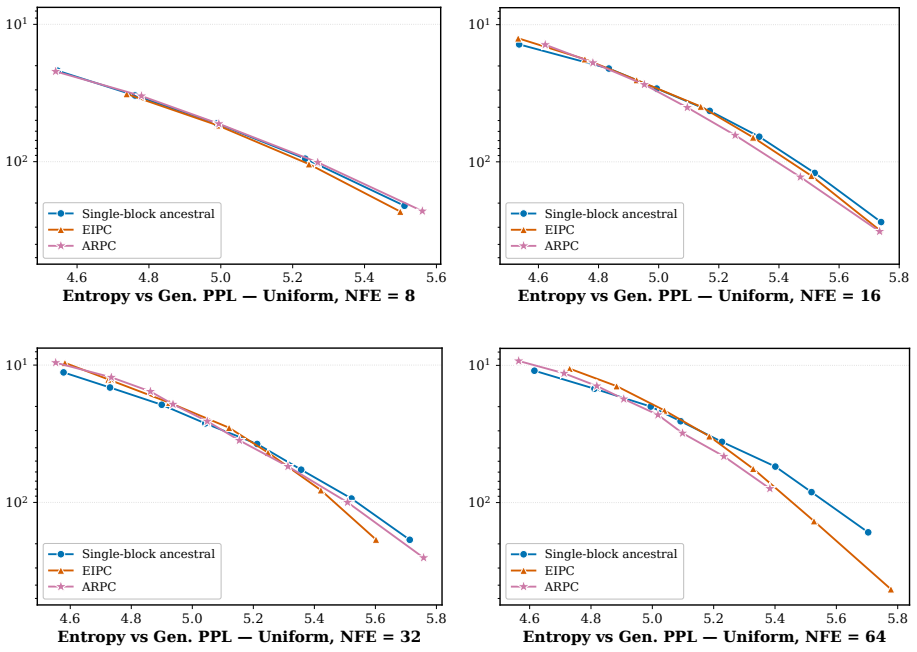
BlockGen shows uniform diffusion outperforms masked diffusion in block-by-block generation under ancestral sampling, especially with few steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
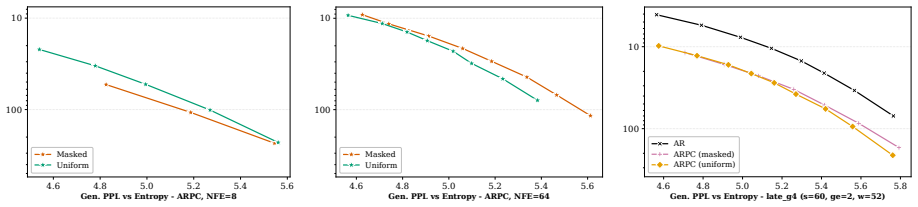
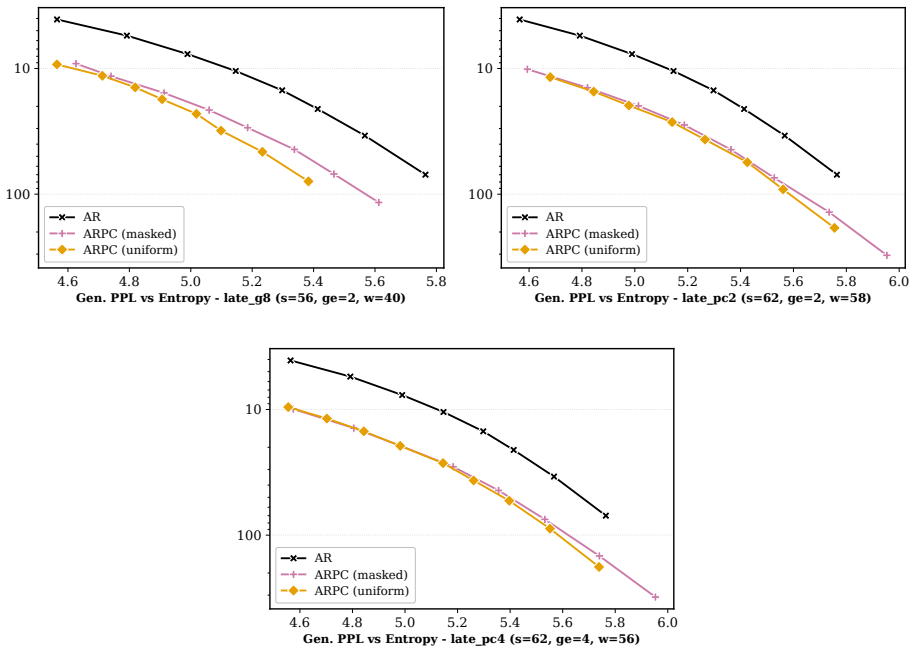
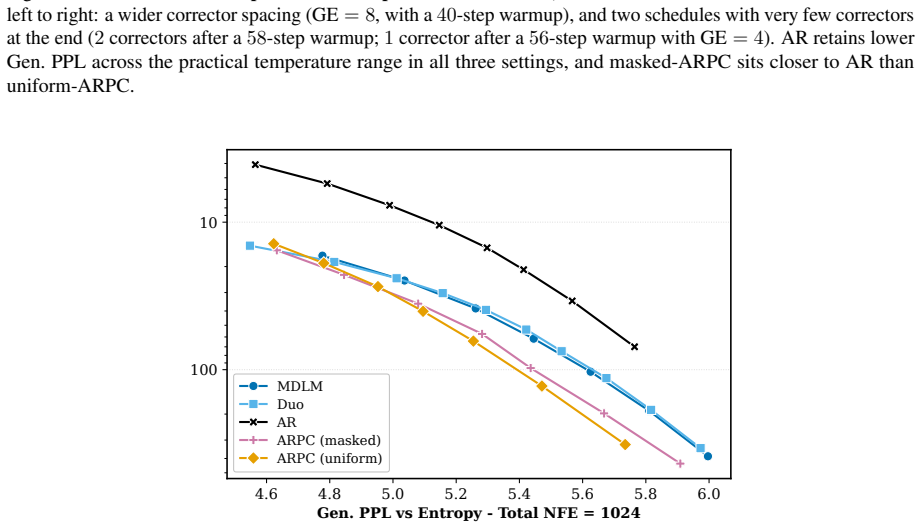
BlockGen is a blockwise sequence model that is instantiated once with masked diffusion and once with uniform diffusion; it trains on a mixture of block sizes whose likelihoods interpolate between autoregressive and pure diffusion models, and it supports AR-informed predictor-corrector sampling that combines autoregressive and diffusion predictions to re-generate unlikely tokens. Under ancestral sampling the uniform version outperforms the masked version in the block-by-block regime, most clearly in the few-step regime; under ARPC the performance gap closes and reverses at high numbers of function evaluations. With block size 16 on GSM8K the masked models reach slightly higher accuracy than t
What carries the argument
BlockGen, a blockwise sequence model trained on a mixture of block sizes that also supports AR-informed predictor-corrector sampling to compare uniform and masked diffusion states.
If this is right
- Uniform diffusion becomes the preferred choice for blockwise generation when only ancestral sampling and low step counts are available.
- AR-informed correctors reduce the practical importance of choosing between uniform and masked states once the sampling budget grows large.
- A single model trained on mixed block sizes can be deployed at different effective block lengths without retraining.
- Accuracy trends on math reasoning tasks and perplexity trends on language data move in the same direction, suggesting the ordering is not task-specific.
Where Pith is reading between the lines
- The reversal at high NFE implies that sampler choice can matter more than diffusion-state choice when high-quality output is required.
- If the mixed-block training is the source of the advantage, then variable block sizes at inference time could further improve speed-quality trade-offs.
- The slight masked-model edge on GSM8K at block size 16 suggests that downstream task performance may still favor masked diffusion in some regimes even when ancestral sampling favors uniform.
Load-bearing premise
That training both diffusion types on the same mixture of block sizes and evaluating them with the same AR-informed correctors produces an unbiased comparison in which performance differences reflect the choice of diffusion state rather than interactions with the blockwise schedule or the hybrid sampler.
What would settle it
Retraining separate masked and uniform models with a single fixed block size and with random rather than AR-informed correctors, then observing that the performance ordering under ancestral sampling reverses, would indicate that the reported advantage depends on the BlockGen training or sampler rather than on the diffusion state itself.
Figures
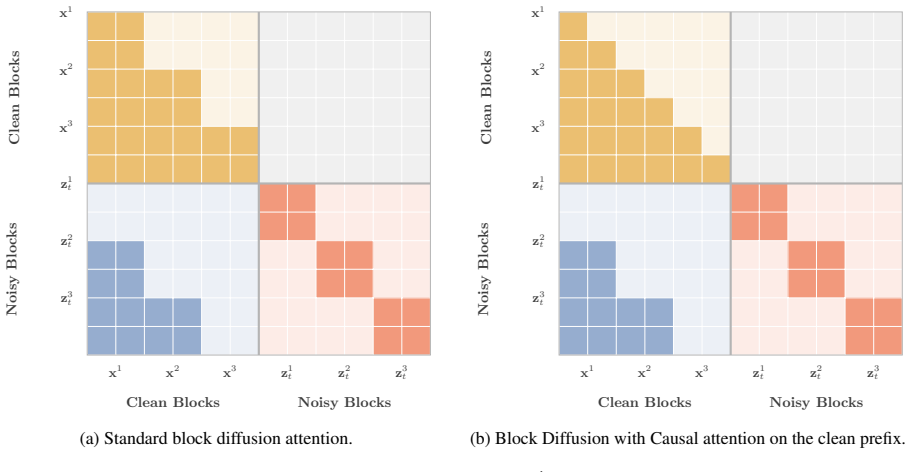
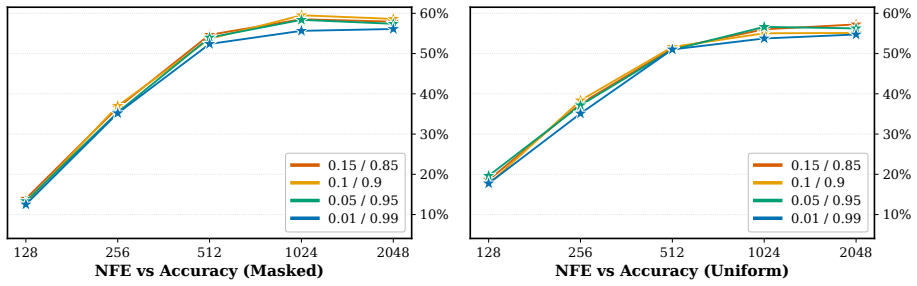
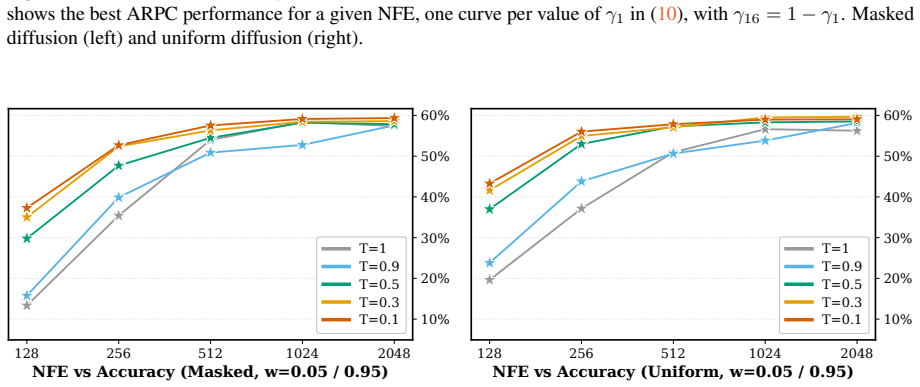
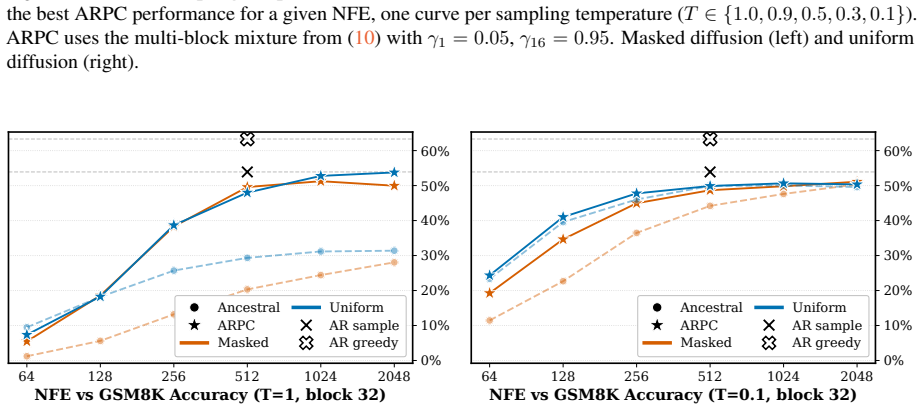
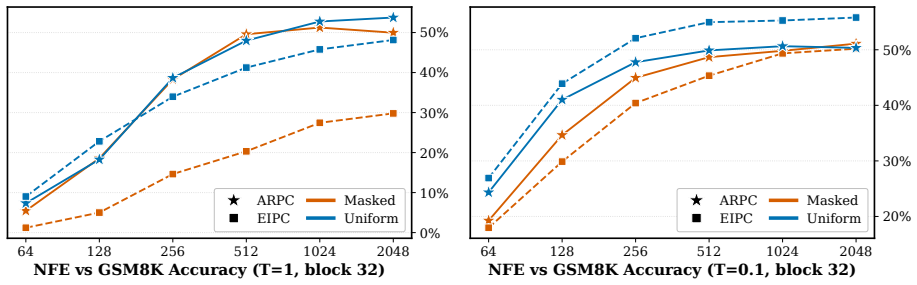
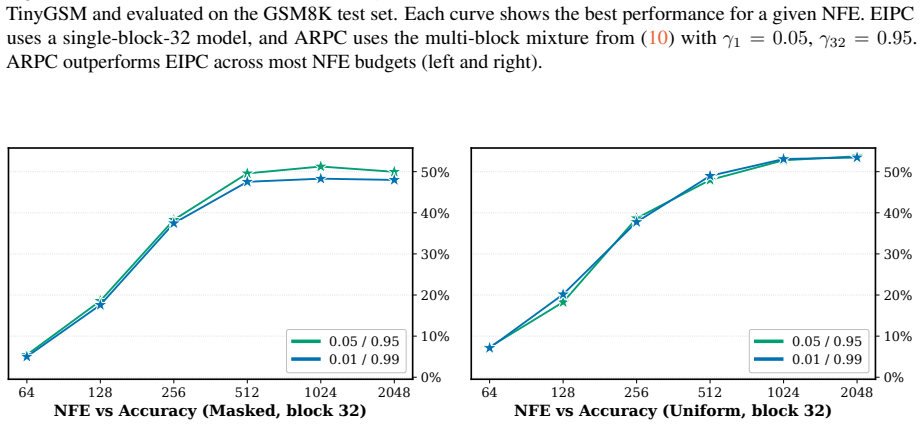
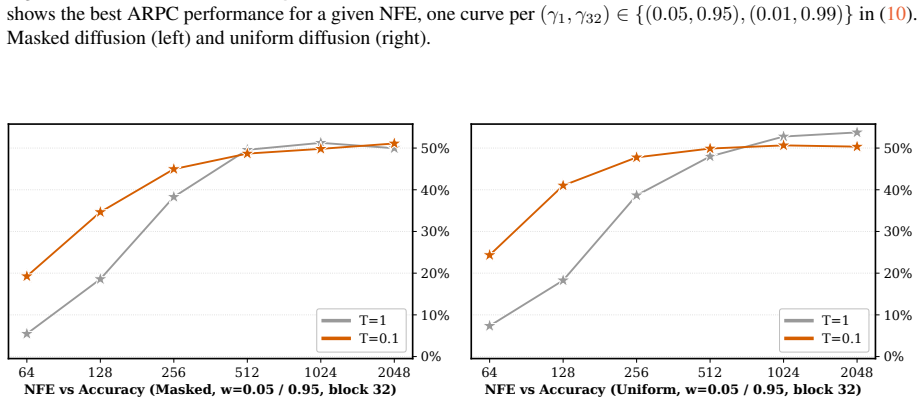



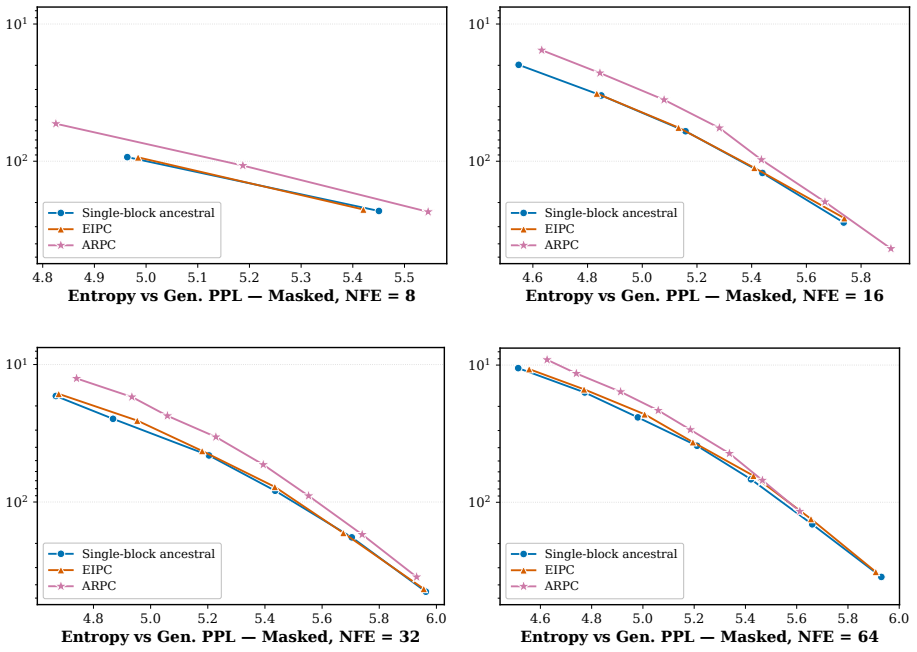
read the original abstract
Is the uniform-state diffusion framework a more powerful paradigm for discrete diffusion? Recent studies indicate that this may be the case. In combination with predictor-corrector samplers, uniform-state diffusion models (USDMs) produce samples of higher-quality than masked diffusion models (MDMs), and USDMs equal or outperform MDMs in downstream tasks, even though they exhibit greater perplexity. Two issues remain unresolved. First, existing work compares uniform and masked diffusion with un-informed correctors that re-inject noise at random positions, rather than targeting tokens most likely to be wrong. Second, prior work compares full-sequence diffusion models, so we do not know whether the same conclusion holds when tokens are generated block by block. To address these issues, we introduce BlockGen, a blockwise sequence model that we instantiate with both masked and uniform diffusion. BlockGen trains on a mixture of block sizes and its likelihood interpolates between AR and pure diffusion more finely than models with a fixed block size. BlockGen enables AR-informed predictor-corrector sampling (ARPC), which combines AR and diffusion predictions to re-generate unlikely tokens without an auxiliary verifier. Under ancestral sampling, uniform outperforms masked in the block-by-block setting, especially in the few-step regime. Under ARPC, the gap closes and reverses at high NFE. With block size $16$ on GSM8K, MDMs reach slightly higher accuracy than USDMs, and we observe a similar trend in Generative Perplexity on OpenWebText. Find our code at https://github.com/jdeschena/blockgen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BlockGen, a blockwise sequence modeling framework trained on a mixture of block sizes that can be instantiated with either masked diffusion models (MDMs) or uniform-state diffusion models (USDMs). It proposes AR-informed predictor-corrector (ARPC) sampling that combines AR and diffusion predictions to regenerate unlikely tokens. The central empirical claims are that, under ancestral sampling, USDMs outperform MDMs (especially in the few-step regime); under ARPC the performance gap closes and can reverse at high NFE; and that with block size 16 on GSM8K, MDMs achieve slightly higher accuracy than USDMs, with a similar trend in generative perplexity on OpenWebText.
Significance. If the ordering results are robust to the shared training and sampling components, the work would provide evidence that diffusion state choice interacts with sampling method in blockwise regimes and that hybrid AR-diffusion correctors can be effective without auxiliary verifiers. The mixture-of-block-sizes training and code release are positive features that allow finer interpolation between AR and diffusion.
major comments (2)
- [Abstract / Experiments] Abstract and experimental claims: the headline ordering (uniform > masked under ancestral sampling; gap closes/reverses under ARPC; MDM slightly better on GSM8K bs=16) rests on the premise that observed differences are attributable to the diffusion state rather than the shared mixture-of-block-sizes training schedule or the ARPC component. No ablation isolating diffusion state from these factors is described, which is load-bearing for the central claim that the results reflect an intrinsic property of uniform vs. masked diffusion.
- [Abstract / Results] Results on GSM8K and OpenWebText: the statements that MDMs reach 'slightly higher accuracy' and 'a similar trend' in generative perplexity are presented without error bars, standard deviations across runs, or statistical significance tests. This makes it impossible to determine whether the reported small differences are reliable or could be explained by sampling variance.
minor comments (2)
- [Abstract] The abstract states that BlockGen 'trains on a mixture of block sizes' but does not specify the exact mixture distribution or sampling procedure over block sizes; this detail is needed for reproducibility.
- [Abstract] The link to code is provided, but the manuscript does not indicate whether the released code includes the exact training configurations, random seeds, and evaluation scripts used for the reported GSM8K and OpenWebText numbers.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. Below we address the major comments point by point.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental claims: the headline ordering (uniform > masked under ancestral sampling; gap closes/reverses under ARPC; MDM slightly better on GSM8K bs=16) rests on the premise that observed differences are attributable to the diffusion state rather than the shared mixture-of-block-sizes training schedule or the ARPC component. No ablation isolating diffusion state from these factors is described, which is load-bearing for the central claim that the results reflect an intrinsic property of uniform vs. masked diffusion.
Authors: Both the MDM and USDM models in BlockGen are trained with the exact same mixture-of-block-sizes schedule and share the same architecture and hyperparameters aside from the state definition. The ARPC sampling procedure is also identical for both. This design allows us to attribute performance differences directly to the choice of diffusion state (masked versus uniform) and its interaction with the sampling method. The central claims concern the blockwise setting with this training regime, so we believe the current experiments already provide a fair comparison without confounding factors from differing training schedules. revision: no
-
Referee: [Abstract / Results] Results on GSM8K and OpenWebText: the statements that MDMs reach 'slightly higher accuracy' and 'a similar trend' in generative perplexity are presented without error bars, standard deviations across runs, or statistical significance tests. This makes it impossible to determine whether the reported small differences are reliable or could be explained by sampling variance.
Authors: We agree that reporting variability is important for interpreting the small differences. In the revised version of the manuscript, we will include error bars and standard deviations computed over multiple independent training and sampling runs for the GSM8K accuracy and OpenWebText generative perplexity results. revision: yes
Circularity Check
No circularity: empirical comparisons on external benchmarks
full rationale
The paper's central claims consist of empirical performance comparisons (ancestral sampling, ARPC, GSM8K accuracy, OpenWebText generative perplexity) between USDM and MDM instantiations of BlockGen. These rest on training and evaluation against standard external benchmarks rather than any derivation, equation, or fitted parameter that reduces to the paper's own inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the reported results or methodology.
Axiom & Free-Parameter Ledger
free parameters (1)
- block size mixture distribution
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[2]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[3]
2024 , howpublished=
GPT-OSS: open-weight language models by OpenAI , author=. 2024 , howpublished=
2024
-
[4]
2023 , eprint=
SSD-LM: Semi-autoregressive Simplex-based Diffusion Language Model for Text Generation and Modular Control , author=. 2023 , eprint=
2023
-
[5]
2015 , eprint=
Distilling the Knowledge in a Neural Network , author=. 2015 , eprint=
2015
-
[6]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[7]
A Neural Probabilistic Language Model , url =
Bengio, Yoshua and Ducharme, R\'. A Neural Probabilistic Language Model , url =. Advances in Neural Information Processing Systems , editor =
-
[8]
2025 , eprint=
Demystifying Diffusion Objectives: Reweighted Losses are Better Variational Bounds , author=. 2025 , eprint=
2025
-
[9]
Handbook of Monte Carlo methods
Kroese, Dirk P and Taimre, Thomas and Botev, Zdravko I. Handbook of Monte Carlo methods
-
[10]
2025 , eprint=
Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
CtrlDiff: Boosting Large Diffusion Language Models with Dynamic Block Prediction and Controllable Generation , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
Fast-dLLM v2: Efficient Block-Diffusion LLM , author=. 2025 , eprint=
2025
-
[13]
1986 , publisher=
Non-Uniform Random Variate Generation , author=. 1986 , publisher=
1986
-
[14]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[15]
1999 , publisher=
Programming Pearls , author=. 1999 , publisher=
1999
-
[16]
2025 , eprint=
The Diffusion Duality , author=. 2025 , eprint=
2025
-
[17]
2024 , eprint=
TinyLlama: An Open-Source Small Language Model , author=. 2024 , eprint=
2024
-
[18]
Soboleva, Daria and Al-Khateeb, Faisal and Myers, Robert and Steeves, Jacob R and Hestness, Joel and Dey, Nolan , title =
-
[19]
2020 , eprint=
Denoising Diffusion Probabilistic Models , author=. 2020 , eprint=
2020
-
[20]
2025 , eprint=
Remasking Discrete Diffusion Models with Inference-Time Scaling , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Simple Guidance Mechanisms for Discrete Diffusion Models , author=. 2025 , eprint=
2025
-
[22]
2026 , url=
Luca Eyring and Vincent Pauline and Stefan Bauer and Alexey Dosovitskiy and Zeynep Akata , booktitle=. 2026 , url=
2026
-
[23]
2017 , eprint=
PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications , author=. 2017 , eprint=
2017
-
[24]
2021 , eprint=
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers , author=. 2021 , eprint=
2021
-
[25]
2023 , eprint=
Consistency Models , author=. 2023 , eprint=
2023
-
[26]
2017 , eprint=
Categorical Reparameterization with Gumbel-Softmax , author=. 2017 , eprint=
2017
-
[27]
2017 , eprint=
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables , author=. 2017 , eprint=
2017
-
[28]
2025 , eprint=
Beyond Autoregression: Fast LLMs via Self-Distillation Through Time , author=. 2025 , eprint=
2025
- [29]
-
[30]
2025 , eprint=
Distillation of Discrete Diffusion through Dimensional Correlations , author=. 2025 , eprint=
2025
-
[31]
2026 , eprint=
IDLM: Inverse-distilled Diffusion Language Models , author=. 2026 , eprint=
2026
-
[32]
2026 , eprint=
Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD , author=. 2026 , eprint=
2026
-
[33]
2015 , eprint=
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author=. 2015 , eprint=
2015
-
[34]
2022 , eprint=
Denoising Diffusion Implicit Models , author=. 2022 , eprint=
2022
-
[35]
2023 , eprint=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. 2023 , eprint=
2023
-
[36]
2025 , eprint=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Generalized Interpolating Discrete Diffusion , author=. 2025 , eprint=
2025
-
[38]
2024 , eprint=
Flex Attention: A Programming Model for Generating Optimized Attention Kernels , author=. 2024 , eprint=
2024
-
[39]
2025 , eprint=
Generator Matching: Generative modeling with arbitrary Markov processes , author=. 2025 , eprint=
2025
-
[40]
2023 , eprint=
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel , author=. 2023 , eprint=
2023
-
[41]
2024 , eprint=
Flow Matching with General Discrete Paths: A Kinetic-Optimal Perspective , author=. 2024 , eprint=
2024
-
[42]
2023 , eprint=
Fast Inference from Transformers via Speculative Decoding , author=. 2023 , eprint=
2023
-
[43]
2019 , eprint=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. 2019 , eprint=
2019
-
[44]
2023 , eprint=
Variational Diffusion Models , author=. 2023 , eprint=
2023
-
[45]
2025 , eprint=
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling , author=. 2025 , eprint=
2025
-
[46]
2024 , eprint=
Unified Discrete Diffusion for Categorical Data , author=. 2024 , eprint=
2024
-
[47]
International Conference on Machine Learning , year=
Curriculum learning , author=. International Conference on Machine Learning , year=
-
[48]
2014 , eprint=
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling , author=. 2014 , eprint=
2014
-
[49]
OpenWebText Corpus , author=
-
[50]
2024 , eprint=
Simple and Effective Masked Diffusion Language Models , author=. 2024 , eprint=
2024
-
[51]
2024 , eprint=
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author=. 2024 , eprint=
2024
-
[52]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[53]
2021 , eprint=
Improved Denoising Diffusion Probabilistic Models , author=. 2021 , eprint=
2021
-
[54]
2015 , eprint=
U-Net: Convolutional Networks for Biomedical Image Segmentation , author=. 2015 , eprint=
2015
-
[55]
2022 , eprint=
DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models , author=. 2022 , eprint=
2022
-
[56]
2025 , eprint=
Path Planning for Masked Diffusion Model Sampling , author=. 2025 , eprint=
2025
-
[57]
2025 , eprint=
Planner Aware Path Learning in Diffusion Language Models Training , author=. 2025 , eprint=
2025
-
[58]
2025 , eprint=
Think While You Generate: Discrete Diffusion with Planned Denoising , author=. 2025 , eprint=
2025
-
[59]
2025 , eprint=
TiDAR: Think in Diffusion, Talk in Autoregression , author=. 2025 , eprint=
2025
-
[60]
The Eleventh International Conference on Learning Representations , year=
Discrete Predictor-Corrector Diffusion Models for Image Synthesis , author=. The Eleventh International Conference on Learning Representations , year=
-
[61]
2025 , eprint=
Fine-Tuning Masked Diffusion for Provable Self-Correction , author=. 2025 , eprint=
2025
-
[62]
2025 , eprint=
Corrective Diffusion Language Models , author=. 2025 , eprint=
2025
-
[63]
2025 , eprint=
Informed Correctors for Discrete Diffusion Models , author=. 2025 , eprint=
2025
-
[64]
Yong-Hyun Park and Chieh-Hsin Lai and Satoshi Hayakawa and Yuhta Takida and Yuki Mitsufuji , year=. 2410.07761 , archivePrefix=
-
[65]
2025 , eprint=
Fast Solvers for Discrete Diffusion Models: Theory and Applications of High-Order Algorithms , author=. 2025 , eprint=
2025
-
[66]
2025 , eprint=
Energy-Based Diffusion Language Models for Text Generation , author=. 2025 , eprint=
2025
-
[67]
2025 , eprint=
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation , author=. 2025 , eprint=
2025
-
[68]
Language Models are Unsupervised Multitask Learners , author=
-
[69]
2023 , eprint=
Scalable Diffusion Models with Transformers , author=. 2023 , eprint=
2023
-
[70]
2023 , eprint=
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2023 , eprint=
2023
-
[71]
2022 , eprint=
Efficiently Scaling Transformer Inference , author=. 2022 , eprint=
2022
-
[72]
2020 , eprint=
The Curious Case of Neural Text Degeneration , author=. 2020 , eprint=
2020
-
[73]
2022 , eprint=
Diffusion-LM Improves Controllable Text Generation , author=. 2022 , eprint=
2022
-
[74]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[75]
2025 , eprint=
Halton Scheduler For Masked Generative Image Transformer , author=. 2025 , eprint=
2025
-
[76]
2025 , eprint=
Movie Gen: A Cast of Media Foundation Models , author=. 2025 , eprint=
2025
-
[77]
2022 , eprint=
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models , author=. 2022 , eprint=
2022
-
[78]
2023 , eprint=
Noise2Music: Text-conditioned Music Generation with Diffusion Models , author=. 2023 , eprint=
2023
-
[79]
2025 , eprint=
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=. 2025 , eprint=
2025
-
[80]
2025 , eprint=
Encoder-Decoder Diffusion Language Models for Efficient Training and Inference , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.