DECA: Decentralizing Block-Wise Adam for Efficient LLM Full-Parameter Fine-Tuning on Non-IID Data
Pith reviewed 2026-06-28 11:22 UTC · model grok-4.3
The pith
DECA partitions LLM parameters into blocks for sequential Adam updates to enable efficient decentralized full-parameter fine-tuning on non-IID data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
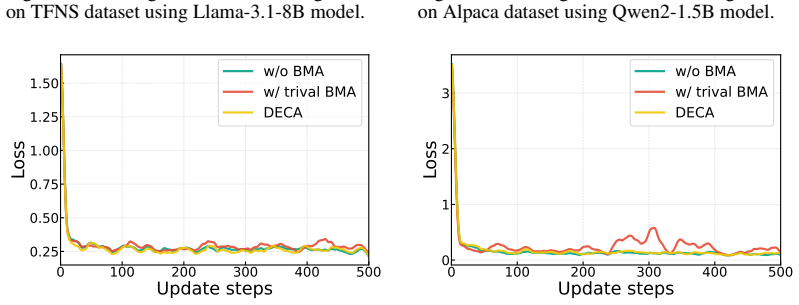
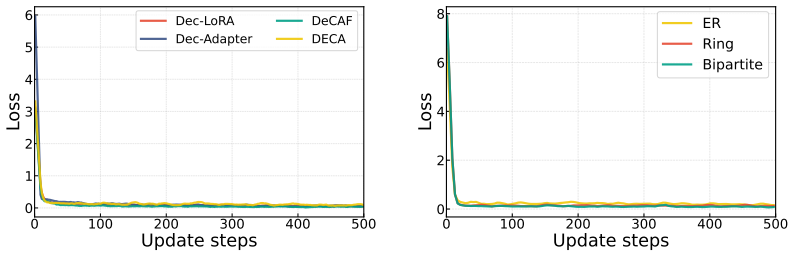
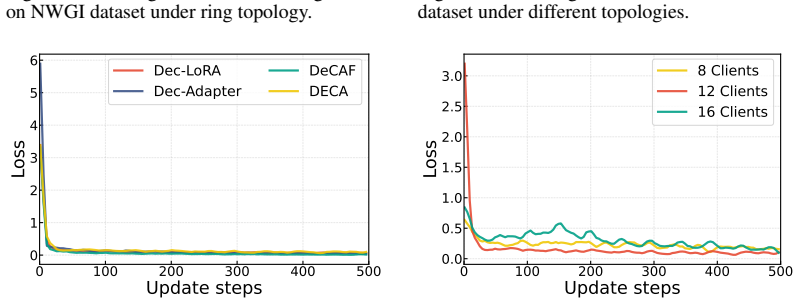
DECA partitions model parameters into disjoint blocks and performs sequential block-wise Adam optimization, reducing resource consumption while preserving decentralized full-parameter adaptation. To stabilize training, DECA further introduces first- and second-order block-wise moment estimates with fresh local gradient statistics and consensus-derived discrepancy signals, yielding fast convergence, strong downstream performance, and significant resource efficiency on non-IID data.
What carries the argument
Sequential block-wise Adam optimization using first- and second-order moment estimates from local gradients and consensus discrepancy signals.
If this is right
- Cuts memory and compute demands per client for models with billions of parameters.
- Reduces vulnerability to client drift through the added consensus signals.
- Retains the downstream task gains that come from updating every parameter rather than a subset.
- Supplies theoretical convergence analysis for the resulting decentralized process.
Where Pith is reading between the lines
- The same block partitioning might apply to other first-order optimizers in decentralized settings.
- It suggests full-parameter methods could become viable in more constrained federated scenarios than previously assumed.
- Sequential block handling may interact differently with attention layers versus feed-forward layers in practice.
Load-bearing premise
That updating parameters one block at a time preserves the adaptation capacity of simultaneous full-parameter updates without introducing bias or instability from the update order or non-IID client data.
What would settle it
A direct comparison experiment on a fixed non-IID data split where DECA's final accuracy or convergence speed falls substantially below that of a full decentralized Adam baseline or a centralized full-parameter run.
Figures



read the original abstract
Fine-tuning large language models (LLMs) in privacy-sensitive and resource-constrained environments remains challenging. Since training data are often distributed across multiple clients, decentralized fine-tuning offers a natural paradigm for collaborative adaptation without a central server. However, enabling full-parameter fine-tuning (FPFT) in this decentralized setting is difficult: FPFT provides strong adaptation capacity but incurs prohibitive resource consumption for billion-scale models. Existing decentralized LLM fine-tuning methods therefore mainly rely on parameter-efficient updates, which improve efficiency but may restrict downstream performance. Moreover, client data are typically non-IID, making decentralized optimization more vulnerable to client drift and unstable convergence. To address these challenges, we propose DECA, a resource-efficient decentralized FPFT framework for LLMs on non-IID data. DECA partitions model parameters into disjoint blocks and performs sequential block-wise Adam optimization, reducing resource consumption while preserving decentralized full-parameter adaptation. To stabilize training, DECA further introduces first- and second-order block-wise moment estimates with fresh local gradient statistics and consensus-derived discrepancy signals. We provide rigorous theoretical analysis and extensive experiments, showing that DECA achieves fast convergence, strong downstream performance, and significant resource efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DECA, a decentralized framework for full-parameter fine-tuning of LLMs on non-IID client data. Parameters are partitioned into disjoint blocks for sequential block-wise Adam updates; first- and second-order moment estimates are formed from fresh local gradient statistics together with consensus-derived discrepancy signals. The paper asserts that this yields resource-efficient FPFT while preserving adaptation capacity, supported by a rigorous theoretical analysis and extensive experiments that demonstrate fast convergence, strong downstream performance, and significant resource savings relative to existing decentralized methods.
Significance. If the central claims hold, DECA would constitute a meaningful advance in decentralized LLM fine-tuning by enabling full-parameter updates at lower per-client resource cost than standard Adam while mitigating client drift on non-IID distributions. This could narrow the performance gap between parameter-efficient and full-parameter decentralized approaches in privacy-sensitive settings.
minor comments (2)
- The abstract states that 'rigorous theoretical analysis' is provided, yet no key assumptions, convergence rates, or bounds are sketched; this omission makes it impossible to evaluate whether the analysis directly supports the claimed stability on non-IID data.
- The description of 'consensus-derived discrepancy signals' is introduced without reference to the precise consensus protocol or how the signals are computed from local and global statistics; clarification of this mechanism would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their review and positive summary of DECA. The report lists no specific major comments, so we provide no point-by-point responses below. We remain available to address any additional questions or clarifications the referee may have.
Circularity Check
No circularity; derivation self-contained
full rationale
The provided abstract and description introduce DECA as a block-wise Adam method using local gradient statistics and consensus signals, with a claimed theoretical analysis. No equations, derivations, or self-citations are exhibited that reduce any prediction or result to a fitted input or self-definition by construction. The central claims rest on the described partitioning and moment estimates without visible reduction to the method's own outputs. This is the normal case of a self-contained proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. InProc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL/IJCNLP), pages 7319–7328, 2021
2021
-
[3]
Aketi, A
S. Aketi, A. Hashemi, and K. Roy. Global Update Tracking: A Decentralized Learning Algorithm for Heterogeneous Data. InProc. of the 37th NeurIPS, 2024
2024
-
[4]
Greedy Layerwise Learning Can Scale To ImageNet
Eugene Belilovsky, Michael Eickenberg, and Edouard Oyallon. Greedy Layerwise Learning Can Scale To ImageNet. InProc. of the 36th International Conference on Machine Learning (ICML), pages 583–593, 2019
2019
-
[5]
Greedy Layer-Wise Training of Deep Networks
Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. Greedy Layer-Wise Training of Deep Networks. InProc. of the 20th Annual Conference on Neural Information Processing Systems (NIPS), pages 153–160, 2006
2006
-
[6]
Boyd, Arpita Ghosh, Balaji Prabhakar, and Devavrat Shah
Stephen P. Boyd, Arpita Ghosh, Balaji Prabhakar, and Devavrat Shah. Randomized Gossip Algorithms.IEEE Transactions on Information Theory, 52(6):2508–2530, 2006
2006
-
[7]
On the Importance and Applicability of Pre-Training for Federated Learning
Hong-You Chen, Cheng-Hao Tu, Ziwei Li, and Han-Wei Shen an Wei-Lun Chao. On the Importance and Applicability of Pre-Training for Federated Learning. InProc. of the 11th International Conference on Learning Representations (ICLR), 2023
2023
-
[8]
Shuaijun Chen, Omid Tavallaie, Niousha Nazemi, and Albert Y . Zomaya. RBLA: Rank-Based- LoRA-Aggregation for Fine-Tuning Heterogeneous Models in FLaaS. InProc. of the 31st International Conference on Web Service (ICWS), pages 47–62, 2024
2024
-
[9]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training Deep Nets with Sublinear Memory Cost.arXiv preprint arXiv:1604.06174, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[10]
Chiang, Z
W. Chiang, Z. Li, Z. Lin, Y . Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y . Zhuang, J. E. Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. https://vicuna.lmsys.org (accessed 14 April 2023), 2(3):6, 2023
2023
-
[11]
Heterogeneous LoRA for Federated Fine-tuning of On-Device Foundation Models
Yae Jee Cho, Luyang Liu, Zheng Xu, Aldi Fahrezi, and Gauri Joshi. Heterogeneous LoRA for Federated Fine-tuning of On-Device Foundation Models. InProc. of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 12903–12913, 2024
2024
-
[12]
Epidemic Learning: Boosting Decentralized Learning with Randomized Communication
Martijn de V os, Sadegh Farhadkhani, Rachid Guerraoui, Anne-Marie Kermarrec, Rafael Pires, and Rishi Sharma. Epidemic Learning: Boosting Decentralized Learning with Randomized Communication. InProc. of the 36th NeurIPS, 2023
2023
-
[13]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient Finetuning of Quantized LLMs. InProc. of the 36th Annual Conference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[14]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, and A. Fan. The LLaMA 3 Herd of Models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Cross-Gradient Aggregation for Decentralized Learning from Non-IID Data
Yasaman Esfandiari, Sin Yong Tan, Zhanhong Jiang, Aditya Balu, Ethan Herron, Chinmay Hegde, and Soumik Sarkar. Cross-Gradient Aggregation for Decentralized Learning from Non-IID Data. InProc. of the 38th International Conference on Machine Learning (ICML), pages 3036–3046, 2021
2021
-
[16]
Decentralized low-rank fine- tuning of large language models
Sajjad Ghiasvand, Mahnoosh Alizadeh, and Ramtin Pedarsani. Decentralized low-rank fine- tuning of large language models. InProceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025), pages 334–345, 2025. 10
2025
-
[17]
Robust Decentralized Learning With Local Updates and Gradient Tracking.IEEE Transactions on Networking, 33(4):2036–2048, 2025
Sajjad Ghiasvand, Amirhossein Reisizadeh, Mahnoosh Alizadeh, and Ramtin Pedarsani. Robust Decentralized Learning With Local Updates and Gradient Tracking.IEEE Transactions on Networking, 33(4):2036–2048, 2025
2036
-
[18]
Selective Aggregation for Low-Rank Adaptation in Federated Learning
Pengxin Guo, Shuang Zeng, Yanran Wang, Huijie Fan, Feifei Wang, and Liangqiong Qu. Selective Aggregation for Low-Rank Adaptation in Federated Learning. InProc. of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[19]
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-Efficient Transfer Learning for NLP. InProc. of the 36th International Conference on Machine Learning (ICML), pages 2790–2799, 2019
2019
-
[20]
E. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low- Rank Adaptation of Large Language Models. InProc. of the 10th International Conference on Learning Representations (ICLR), 2022
2022
-
[21]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. InProc. of the 3rd International Conference on Learning Representations (ICLR), 2015
2015
-
[22]
NOLA: Networks as Linear Combination of Low Rank Random Basis.arXiv preprint arXiv:2310.02556, 2023
Soroush Abbasi Koohpayegani, KL Navaneet, Parsa Nooralinejad, Soheil Kolouri, and Hamed Pirsiavash. NOLA: Networks as Linear Combination of Low Rank Random Basis.arXiv preprint arXiv:2310.02556, 2023
-
[23]
Dawid Jan Kopiczko, Tijmen Blankevoort, and Yuki M. Asano. VeRA: Vector-based Random Matrix Adaptation. InProc. of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[24]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The Power of Scale for Parameter-Efficient Prompt Tuning. InProc. of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3045–3059, 2021
2021
-
[25]
C. Li, G. Li, and P. Varshney. Decentralized Federated Learning via Mutual Knowledge Transfer. IEEE Internet of Things Journal, 9(2):1136–1147, 2021
2021
-
[26]
Measuring the Intrinsic Dimension of Objective Landscapes
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the Intrinsic Dimension of Objective Landscapes. InProc. of the 6th International Conference on Learning Representations (ICLR), 2018
2018
-
[27]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL/IJCNLP), pages 4582–4597, 2021
2021
-
[28]
ReLoRA: High-Rank Training Through Low-Rank Updates
Vladislav Lialin, Sherin Muckatira, Namrata Shivagunde, and Anna Rumshisky. ReLoRA: High-Rank Training Through Low-Rank Updates. InProc. of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[29]
Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent
Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, Wei Zhang, and Ji Liu. Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent. InProc. of the 31st Annual Conference on Neural Information Processing Systems (NIPS), pages 5330–5340, 2017
2017
-
[30]
Stich, and Martin Jaggi
Tao Lin, Sai Praneeth Karimireddy, Sebastian U. Stich, and Martin Jaggi. Quasi-global Momentum: Accelerating Decentralized Deep Learning on Heterogeneous Data. InProc. of the 38th International Conference on Machine Learning (ICML), pages 6654–6665, 2021
2021
-
[31]
HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy
Yongkang Liu, Yiqun Zhang, Qian Li, Tong Liu, Shi Feng, Daling Wang, Yifei Zhang, and Hinrich Schütze. HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy. InProc. of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 18266–18287, 2024
2024
-
[32]
Lu and L
Z. Lu and L. Xiao. On the complexity analysis of randomized block-coordinate descent methods. Mathematical Programming, 152(1):615–642, 2015
2015
-
[33]
Q. Luo, H. Yu, and X. Li. BAdam: A Memory Efficient Full Parameter Optimization Method for Large Language Models. InProc. of the 38th Annual Conference on Neural Information Processing Systems (NIPS), pages 24926–24958, 2024. 11
2024
-
[34]
Full Parameter Fine-tuning for Large Language Models with Limited Resources
Kai Lv, Yuqing Yang, Tengxiao Liu, Qipeng Guo, and Xipeng Qiu. Full Parameter Fine-tuning for Large Language Models with Limited Resources. InProc. of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 8187–8198, 2024
2024
-
[35]
Lee, Danqi Chen, and Sanjeev Arora
Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D. Lee, Danqi Chen, and Sanjeev Arora. Fine-Tuning Language Models With Just Forward Passes. InProc. of the 36th Annual Conference on Neural Information Processing Systems (NeurIPS), pages 53038–53075, 2023
2023
-
[36]
Communication-Efficient Learning of Deep Networks from Decentralized Data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. Communication-Efficient Learning of Deep Networks from Decentralized Data. InProc. of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), pages 1273–1282, 2017
2017
-
[37]
John Nguyen, Jianyu Wang, Kshitiz Malik, Maziar Sanjabi, and Michael G. Rabbat. Where to Begin? On the Impact of Pre-Training and Initialization in Federated Learning. InProc. of the 11th International Conference on Learning Representations (ICLR), 2023
2023
-
[38]
George Pu, Anirudh Jain, Jihan Yin, and Russell Kaplan. Empirical Analysis of The Strengths and Weaknesses of PEFT Techniques for LLMs.arXiv preprint arXiv:2304.14999, 2023
-
[39]
Pu and A
S. Pu and A. Nedi. Distributed Stochastic Gradient Tracking Methods.Mathematical Program- ming, 187(1):409–457, 2021
2021
-
[40]
FDLoRA: Personalized Federated Learning of Large Language Model via Dual LoRA Tuning
Jiaxing Qi, Zhongzhi Luan, Shaohan Huang, Carol Fung, Hailong Yang, and Depei Qian. FDLoRA: Personalized Federated Learning of Large Language Model via Dual LoRA Tuning. arXiv preprint arXiv:2406.07925, 2024
-
[41]
Federated full-parameter tuning of billion-sized language models with communication cost under 18 kilobytes
Zhen Qin, Daoyuan Chen, Bingchen Qian, Bolin Ding, Yaliang Li, and Shuiguang Deng. Federated full-parameter tuning of billion-sized language models with communication cost under 18 kilobytes. InProc. of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[42]
Liangqiong Qu, Yuyin Zhou, Paul Pu Liang, Yingda Xia, Feifei Wang, Ehsan Adeli, Fei-Fei Li, and Daniel L. Rubin. Rethinking Architecture Design for Tackling Data Heterogeneity in Federated Learning. InProc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10051–10061, 2022
2022
-
[43]
ZeRO-Offload: Democratizing Billion-Scale Model Training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. ZeRO-Offload: Democratizing Billion-Scale Model Training. InProc. of the 2021 USENIX Annual Technical Conference (ATC), pages 551–564, 2021
2021
-
[44]
Waite, Shreyan Ganguly, Aditya Balu, Chinmay Hegde, and Soumik Sarkar
Nastaran Saadati, Zhanhong Jiang, Joshua R. Waite, Shreyan Ganguly, Aditya Balu, Chinmay Hegde, and Soumik Sarkar. DeCAF: Decentralized Consensus-And-Factorization for Low-Rank Adaptation of Foundation Models.Neural Networks, 2026
2026
-
[45]
Scaman, F
K. Scaman, F. Bach, S. Bubeck, Y . Lee, and L. Massoulié. Optimal Algorithms for Smooth and Strongly Convex Distributed Optimization in Networks. InProc. of the 34th International Conference on Machine Learning (ICML), pages 3027–3036, 2017
2017
-
[46]
Scaman, F
K. Scaman, F. Bach, S. Bubeck, Y . Lee, and L. Massoulié. Optimal Algorithms for Non-smooth Distributed Optimization in Networks. InProc. of the 32nd NIPS, page 2745–2754, 2018
2018
-
[47]
Y . Shi, L. Shen, K. Wei, Y . Sun, B. Yuan, X. Wang, and D. Tao. Improving the Model Consistency of Decentralized Federated Learning. InProc. of the 40th ICML, volume 202, pages 31269–31291, 2023
2023
-
[48]
Ferret: Federated full-parameter tuning at scale for large language models
Yao Shu, Wenyang Hu, See-Kiong Ng, Bryan Kian Hsiang Low, and Fei Richard Yu. Ferret: Federated full-parameter tuning at scale for large language models. InProc. of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[49]
Improving LoRA in Privacy-preserving Federated Learning
Youbang Sun, Zitao Li, Yaliang Li, and Bolin Ding. Improving LoRA in Privacy-preserving Federated Learning. InProc. of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[50]
Takezawa, H
Y . Takezawa, H. Bao, K. Niwa, R. Sato, and M. Yamada. Momentum Tracking: Momentum Acceleration for Decentralized Deep Learning on Heterogeneous Data.Trans. on Machine Learning Research, 2023, 2023. 12
2023
-
[51]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Convergence of A Block Coordinate Descent Method for Nondifferentiable Minimization.Journal of Optimization Theory and Applications, 109(3):475–494, 2001
Paul Tseng. Convergence of A Block Coordinate Descent Method for Nondifferentiable Minimization.Journal of Optimization Theory and Applications, 109(3):475–494, 2001
2001
-
[53]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, and I. Polo- sukhin. Attention Is All You Need. InProc. of the 30th Annual Conference on Neural Information Processing Systems (NIPS), pages 5998–6008, 2017
2017
-
[54]
ROSS: RObust decentralized Stochastic learning based on Shapley values.IEEE Transactions on Networking, 34:2911–2926, 2026
Lina Wang, Yunsheng Yuan, Feng Li, and Lingjie Duan. ROSS: RObust decentralized Stochastic learning based on Shapley values.IEEE Transactions on Networking, 34:2911–2926, 2026
2026
-
[55]
PDSL: Privacy-Preserved Decen- tralized Stochastic Learning with Heterogeneous Data Distribution
Lina Wang, Yunsheng Yuan, Chunxiao Wang, and Feng Li. PDSL: Privacy-Preserved Decen- tralized Stochastic Learning with Heterogeneous Data Distribution. InProc. of the 45th IEEE International Conference on Distributed Computing Systems (ICDCS), pages 736–746, 2025
2025
-
[56]
FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations
Ziyao Wang, Zheyu Shen, Yexiao He, Guoheng Sun, Hongyi Wang, Lingjuan Lyu, and Ang Li. FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations. InProc. of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[57]
Flexora: Flexible Low-Rank Adaptation for Large Language Models
Chenxing Wei, Yao Shu, Ying Tiffany He, and Fei Yu. Flexora: Flexible Low-Rank Adaptation for Large Language Models. InProc. of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), pages 14643–14682, 2025
2025
-
[58]
Lawrie, and Benjamin Van Durme
Orion Weller, Marc Marone, Vladimir Braverman, Dawn J. Lawrie, and Benjamin Van Durme. Pretrained Models for Multilingual Federated Learning. InProc. of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), pages 1413–1421, 2022
2022
-
[59]
Coordinate Descent Algorithms.Mathematical Programming, 151(1):3–34, 2015
Stephen J Wright. Coordinate Descent Algorithms.Mathematical Programming, 151(1):3–34, 2015
2015
-
[60]
Wenhan Xia, Chengwei Qin, and Elad Hazan. Chain of LoRA: Efficient Fine-tuning of Language Models via Residual Learning.arXiv preprint arXiv:2401.04151, 2024
-
[61]
J. Xu, W. Zhang, and F. Wang. A(DP)2SGD: Asynchronous Decentralized Parallel Stochastic Gradient Descent With Differential Privacy.IEEE Trans. on Pattern Analysis and Machine Intelligence, 44(11):8036–8047, 2021
2021
-
[62]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, et al. Qwen2 technical report.eprint arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, and Z. Qi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
On the Linear Speedup Analysis of Communication Efficient Momentum SGD for Distributed Non-Convex Optimization
Hao Yu, Rong Jin, and Sen Yang. On the Linear Speedup Analysis of Communication Efficient Momentum SGD for Distributed Non-Convex Optimization. InProc. of the 36th International Conference on Machine Learning (ICML), pages 7184–7193, 2019
2019
-
[65]
When Scaling Meets LLM Fine- tuning: The Effect of Data, Model and Finetuning Method
Biao Zhang, Zhongtao Liu, Colin Cherry, and Orhan Firat. When Scaling Meets LLM Fine- tuning: The Effect of Data, Model and Finetuning Method. InProc. of The 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[66]
LoRA-FA: Efficient and Effective Low Rank Representation Fine-tuning
Longteng Zhang, Lin Zhang, Shaohuai Shi, Xiaowen Chu, and Bo Li. LoRA-FA: Memory- efficient Low-rank Adaptation for Large Language Models Fine-tuning.arXiv preprint arXiv:2308.03303, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Zhang, X
X. Zhang, X. Chen, M. Hong, S. Wu, and J. Yi. Understanding Clipping for Federated Learning: Convergence and Client-Level Differential Privacy. InProc. of the 39th ICML, volume 162, pages 26048–26067, 2022
2022
-
[68]
NET- FLEET: Achieving Linear Convergence Speedup for Fully Decentralized Federated Learning with Heterogeneous Data
Xin Zhang, Minghong Fang, Zhuqing Liu, Haibo Yang, Jia Liu, and Zhengyuan Zhu. NET- FLEET: Achieving Linear Convergence Speedup for Fully Decentralized Federated Learning with Heterogeneous Data. InProc. of the 23rd International Symposium on Theory, Algorithmic 13 Foundations, and Protocol Design for Mobile Networks and Mobile Computing (MobiHoc), page 7...
2022
-
[69]
Kingma, Yinyu Ye, Zhi-Quan Luo, and Ruoyu Sun
Yushun Zhang, Congliang Chen, Ziniu Li, Tian Ding, Chenwei Wu, Diederik P. Kingma, Yinyu Ye, Zhi-Quan Luo, and Ruoyu Sun. Adam-mini: Use Fewer Learning Rates To Gain More. In Proc. of The 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[70]
Enhancing Storage and Computational Efficiency in Federated Multimodal Learning for Large-Scale Models
Zixin Zhang, Fan Qi, and Changsheng Xu. Enhancing Storage and Computational Efficiency in Federated Multimodal Learning for Large-Scale Models. InProc. of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[71]
FedPrompt: Communication- Efficient and Privacy-Preserving Prompt Tuning in Federated Learning
Haodong Zhao, Wei Du, Fangqi Li, Peixuan Li, and Gongshen Liu. FedPrompt: Communication- Efficient and Privacy-Preserving Prompt Tuning in Federated Learning. InProc. of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
2023
-
[72]
Galore: Memory-efficient LLM training by gradient low-rank projection
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. Galore: Memory-efficient LLM training by gradient low-rank projection. InProc. of 41st International Conference on Machine Learning (ICML), 2024
2024
-
[73]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InProc. of the 36th Annual Conference on Neural Information Processing Systems (NeurIPS), 2024. 14 Contents 1 Introduction 1 2 System Model and Preliminaries 2 3 Ou...
2024
-
[74]
Bullish” (positive) or “Bearish
and the last inequality comes from X[t,0] k − ¯X[t,0] k = X[t,R] k−1 − ¯X[t,R] k−1 andX [0,0] 1 = ¯X[0,0] 1 . Sequence Tracking Error. Next we show the error boundary of e[t,r] k . According to the definition of the error term (see Eq. (16)), we have e[t,r+1] k =ˆx[t,r+1] k −¯x[t,r+1] k =e[t,r] k +γ 1 1−α r+1 1 1 N NX i=1 X j∈Ni wij α1m[t,r] j + (1−α ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.