KVarN: Variance-Normalized KV-Cache Quantization Mitigates Error Accumulation in Reasoning Tasks
Pith reviewed 2026-06-28 11:34 UTC · model grok-4.3
The pith
Variance normalization after Hadamard rotation on KV caches prevents error accumulation during autoregressive reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
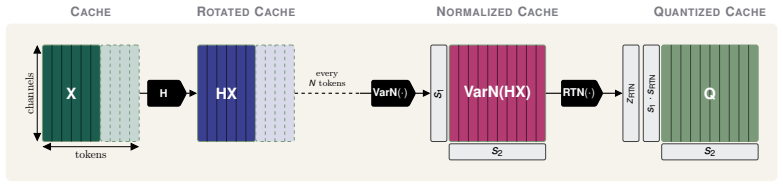
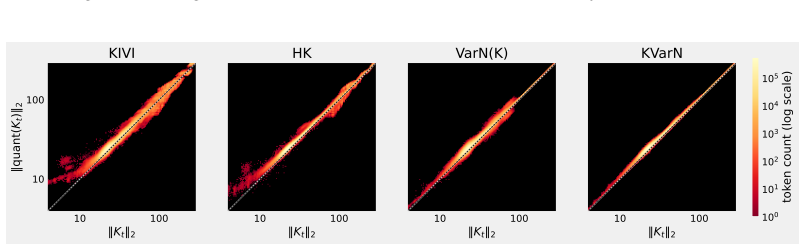
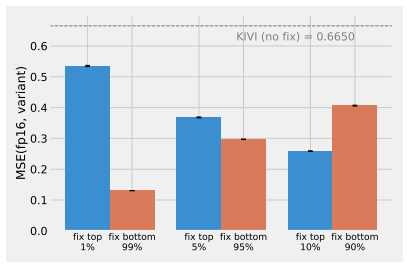
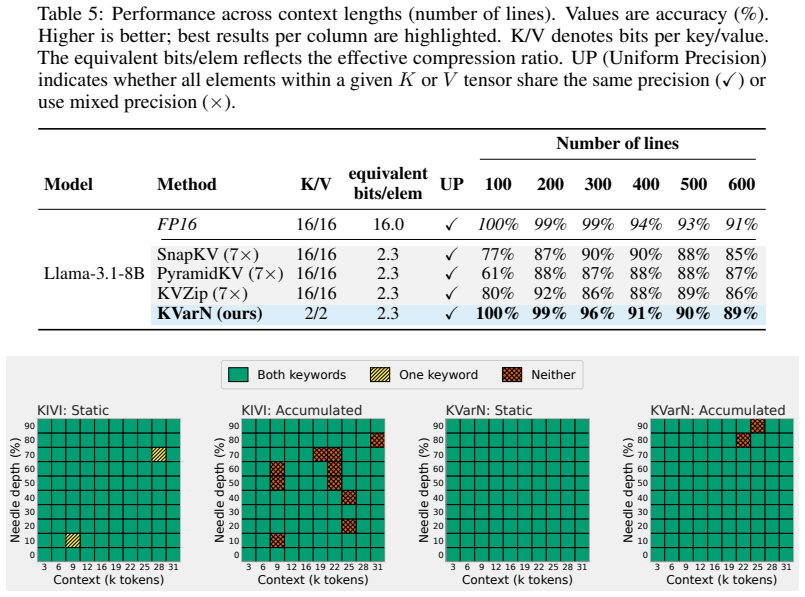
In autoregressive decoding, KV-cache quantization errors accumulate across timesteps primarily due to incorrect per-token scales. KVarN applies a Hadamard rotation followed by dual-scaling variance normalization across both axes of the K and V matrices to fix outlying token-scale errors. This combination reduces error accumulation over existing baselines and establishes new state-of-the-art results on benchmarks including MATH500, AIME24, and HumanEval at 2-bit precision.
What carries the argument
Dual-scaling variance normalization applied after Hadamard rotation, which normalizes K and V matrices along both sequence and feature dimensions to correct token scales.
If this is right
- Longer reasoning sequences become feasible at 2-bit KV precision without proportional accuracy loss.
- KV-cache quantization no longer requires per-model calibration data.
- Reasoning benchmarks such as MATH500 and HumanEval see improved results at low bit widths.
- Memory bottlenecks during extended autoregressive decoding are alleviated.
Where Pith is reading between the lines
- The same normalization pattern could be tested on other cached states inside transformers to check for similar drift reduction.
- Combining KVarN with complementary quantization methods might push viable precision below 2 bits on the same tasks.
- The calibration-free property suggests easier deployment across varied model families without repeated tuning runs.
- If the scale-correction mechanism holds, it points to a broader design principle for stabilizing sequential generation under quantization.
Load-bearing premise
That incorrect per-token scales are the primary driver of error accumulation and that a fixed variance normalization procedure can correct them reliably without calibration or tuning.
What would settle it
Measuring error accumulation rates on MATH500 or AIME24 after applying the Hadamard-plus-dual-variance-normalization procedure and finding no reduction relative to baselines would falsify the claim.
Figures



read the original abstract
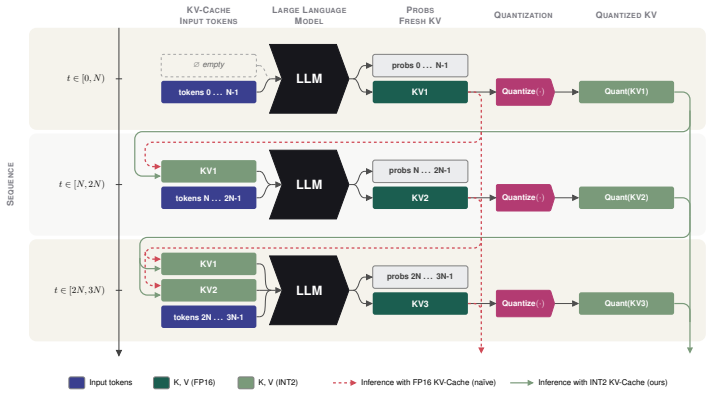
Test-time scaling is a powerful approach to obtain better reasoning in large language models, but it becomes memory-bottlenecked during long-horizon decoding, as the KV-cache grows. KV-cache quantization can help improve this, but current methods are evaluated under prefill-like settings and errors behave differently under autoregressive decoding. We show that in the latter regime, quantization errors accumulate across timesteps, driven primarily by incorrect token scales. We introduce KVarN, a calibration-free KV-cache quantizer that applies a Hadamard rotation followed by a dual-scaling variance normalization across both axes of the K and V matrices. We find that this combination fixes outlying token-scale errors and substantially reduces error accumulation over existing baselines. KVarN establishes a new state-of-theart for KV-cache quantization on generative benchmarks, including MATH500, AIME24 and HumanEval, at 2-bit precision. A vLLM implementation of the KVarN method is available at https://github.com/huawei-csl/KVarN
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that KV-cache quantization errors in autoregressive decoding accumulate primarily due to incorrect per-token scales, unlike in prefill settings. It introduces KVarN, a calibration-free quantizer that applies a Hadamard rotation followed by dual-scaling variance normalization across both axes of the K and V matrices. This is reported to fix outlying token-scale errors, reduce accumulation relative to baselines, and achieve new state-of-the-art results on generative reasoning benchmarks (MATH500, AIME24, HumanEval) at 2-bit precision, with a vLLM implementation provided.
Significance. If the central attribution to token-scale errors and the calibration-free generalization hold, the work would be significant for memory-efficient long-context inference in LLMs, particularly enabling test-time scaling on reasoning tasks. The calibration-free nature and public implementation are concrete strengths that would facilitate adoption if the error-mitigation mechanism is rigorously validated.
major comments (3)
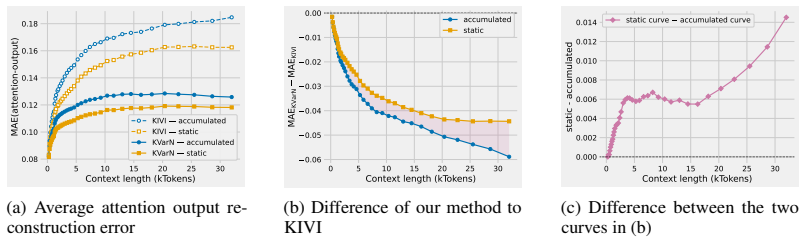
- [Results] Results section: The manuscript reports benchmark improvements but provides no quantitative error-accumulation curves (e.g., per-timestep scale deviation, MSE on KV states, or attention-score drift over decoding steps) for KVarN versus baselines. This absence leaves the load-bearing claim—that accumulation is driven primarily by incorrect token scales and is fixed by the dual normalization—without direct empirical support.
- [Ablation] Ablation or method evaluation: There is no ablation isolating the dual-variance normalization (across both K/V axes) from the Hadamard rotation alone, nor any test of whether the fixed normalization generalizes without per-model statistics. This is required to substantiate that the procedure corrects scales without calibration or model-specific tuning on the reported 2-bit SOTA results.
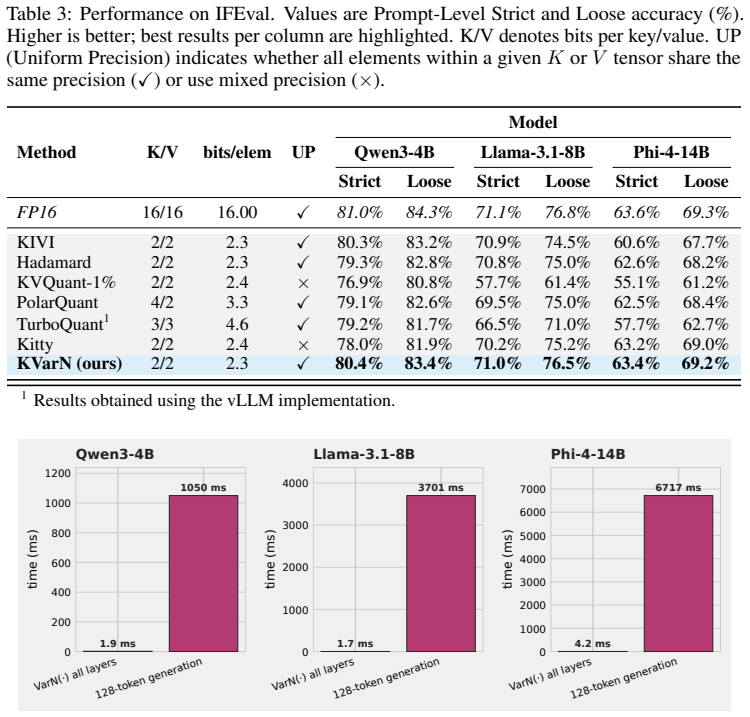
- [Experiments] Experimental setup: Details on baseline re-implementations (e.g., whether prior KV quantizers were adapted to the autoregressive regime with identical 2-bit settings and no hidden calibration) are insufficient to rule out implementation differences as the source of the reported gains on MATH500/AIME24/HumanEval.
minor comments (2)
- [Method] Notation for the dual-scaling factors (e.g., how variance is computed per-axis and applied) could be clarified with an explicit equation in the method section to aid reproducibility.
- [Figures] Figure captions for any error or benchmark plots should explicitly state the number of decoding steps and models evaluated to allow direct comparison with the accumulation claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the empirical support and clarity of the work.
read point-by-point responses
-
Referee: [Results] Results section: The manuscript reports benchmark improvements but provides no quantitative error-accumulation curves (e.g., per-timestep scale deviation, MSE on KV states, or attention-score drift over decoding steps) for KVarN versus baselines. This absence leaves the load-bearing claim—that accumulation is driven primarily by incorrect token scales and is fixed by the dual normalization—without direct empirical support.
Authors: We agree that explicit quantitative curves would provide stronger direct support for the central claim on token-scale errors. In the revised manuscript we will add per-timestep analyses, including scale deviation, MSE on KV states, and attention-score drift, comparing KVarN against baselines. revision: yes
-
Referee: [Ablation] Ablation or method evaluation: There is no ablation isolating the dual-variance normalization (across both K/V axes) from the Hadamard rotation alone, nor any test of whether the fixed normalization generalizes without per-model statistics. This is required to substantiate that the procedure corrects scales without calibration or model-specific tuning on the reported 2-bit SOTA results.
Authors: We acknowledge that an ablation isolating the dual-variance normalization from the Hadamard rotation, together with tests of generalization without per-model statistics, would strengthen the claims. We will add such an ablation study and cross-model generalization experiments in the revision. revision: yes
-
Referee: [Experiments] Experimental setup: Details on baseline re-implementations (e.g., whether prior KV quantizers were adapted to the autoregressive regime with identical 2-bit settings and no hidden calibration) are insufficient to rule out implementation differences as the source of the reported gains on MATH500/AIME24/HumanEval.
Authors: We will expand the experimental setup section to include detailed descriptions of baseline re-implementations, confirming adaptation to the autoregressive regime, identical 2-bit settings, and absence of hidden calibration steps beyond those specified in the original works. revision: yes
Circularity Check
No significant circularity; method is empirical construction validated on external benchmarks
full rationale
The paper presents KVarN as a calibration-free engineering construction (Hadamard rotation followed by dual-axis variance normalization) whose performance is measured directly on external generative benchmarks including MATH500, AIME24 and HumanEval. The observation that errors accumulate due to incorrect token scales is stated as an empirical finding from analysis of the autoregressive regime, not derived from any self-referential equation or fitted parameter defined inside the paper. No load-bearing steps reduce by construction to inputs, no self-citations are invoked for uniqueness or ansatzes, and the central claim does not rename known results. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Hadamard rotation preserves the numerical properties needed for subsequent per-axis variance normalization in floating-point arithmetic.
- domain assumption Variance normalization across token and feature axes can be computed stably from the quantized matrix without additional calibration data.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213– 100240, 2024
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213– 100240, 2024
2024
-
[3]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
2024
-
[4]
Forest-of-thought: Scaling test-time compute for enhancing LLM reasoning
Zhenni Bi, Kai Han, Chuanjian Liu, Yehui Tang, and Yunhe Wang. Forest-of-thought: Scaling test-time compute for enhancing LLM reasoning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volume 267 ofPr...
2025
-
[5]
PyramidKV: Dynamic KV cache compression based on pyramidal information funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling. InSecond Conference on Language Modeling, 2025
2025
-
[6]
Quip: 2-bit quanti- zation of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
Jerry Chee, Yaohui Cai, V olodymyr Kuleshov, and Christopher M De Sa. Quip: 2-bit quanti- zation of large language models with guarantees.Advances in neural information processing systems, 36:4396–4429, 2023
2023
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
KVQuant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems, 37:1270–1303, 2024
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. KVQuant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems, 37:1270–1303, 2024
2024
-
[10]
Needle in a haystack-pressure testing llms
Greg Kamradt. Needle in a haystack-pressure testing llms. https://github.com/gkamradt/ LLMTest_NeedleInAHaystack, 2023
2023
-
[11]
Lee, Sangdoo Yun, and Hyun Oh Song
Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W. Lee, Sangdoo Yun, and Hyun Oh Song. KVzip: Query-agnostic KV cache compression with context reconstruction. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[12]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, pages 611–626, 2023. 10
2023
-
[13]
How long can context length of open-source LLMs truly promise? InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023
Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. How long can context length of open-source LLMs truly promise? InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023
2023
-
[14]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 2294...
2024
-
[15]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[16]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Spinquant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: LLM quantization with learned rotations. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[18]
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Process...
2023
-
[19]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache.Proceedings of Machine Learning Research, 235:32332–32344, 2024
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.Proceedings of Machine Learning Research, 235:32332–32344, 2024
2024
-
[20]
Pushing the limits of large language model quantization via the linearity theorem
Vladimir Malinovskii, Andrei Panferov, Ivan Ilin, Han Guo, Peter Richtárik, and Dan Alistarh. Pushing the limits of large language model quantization via the linearity theorem. InProceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),...
2025
-
[21]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20275–20321, 2025
2025
-
[22]
Lorenz K Müller, Philippe Bich, Jiawei Zhuang, Ahmet Çelik, Luca Benfenati, and Lukas Cavigelli. Sinq: Sinkhorn-normalized quantization for calibration-free low-precision llm weights.arXiv preprint arXiv:2509.22944, 2025
-
[23]
Learning to reason with llms, September 2024
OpenAI. Learning to reason with llms, September 2024. Accessed: May 2026
2024
-
[24]
Thinking vs
Junhong Shen, Hao Bai, Lunjun Zhang, Yifei Zhou, Amrith Setlur, Shengbang Tong, Diego Caples, Nan Jiang, Tong Zhang, Ameet Talwalkar, and Aviral Kumar. Thinking vs. doing: Im- proving agent reasoning by scaling test-time interaction. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
Shriyank Somvanshi, Md Monzurul Islam, Mahmuda Sultana Mimi, Sazzad Bin Bashar Polock, Gaurab Chhetri, and Subasish Das. From s4 to mamba: A comprehensive survey on structured state space models.arXiv preprint arXiv:2503.18970, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
MultiQA: An empirical investigation of generalization and transfer in reading comprehension
Alon Talmor and Jonathan Berant. MultiQA: An empirical investigation of generalization and transfer in reading comprehension. In Anna Korhonen, David Traum, and Lluís Màrquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4911–4921, Florence, Italy, July 2019. Association for Computational Linguistics
2019
-
[28]
Qtip: Quantization with trellises and incoherence processing.Advances in Neural Information Processing Systems, 37:59597–59620, 2024
Albert Tseng, Qingyao Sun, David Hou, and Christopher De Sa. Qtip: Quantization with trellises and incoherence processing.Advances in Neural Information Processing Systems, 37:59597–59620, 2024
2024
-
[29]
D2O: Dynamic discriminative operations for efficient long-context inference of large language models
Zhongwei Wan, Xinjian Wu, Yu Zhang, Yi Xin, Chaofan Tao, Zhihong Zhu, Xin Wang, Siqi Luo, Jing Xiong, Longyue Wang, and Mi Zhang. D2O: Dynamic discriminative operations for efficient long-context inference of large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[30]
Polarquant: Leveraging polar transformation for key cache quantization and decoding acceleration
Songhao Wu, Ang Lv, xiao feng, Yufei zhang, Xun Zhang, Guojun Yin, Wei Lin, and Rui Yan. Polarquant: Leveraging polar transformation for key cache quantization and decoding acceleration. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[31]
Haojun Xia, Xiaoxia Wu, Jisen Li, Robert Wu, Junxiong Wang, Jue Wang, Chenxi Li, Aman Singhal, Alay Dilipbhai Shah, Alpay Ariyak, et al. Kitty: Accurate and efficient 2-bit kv cache quantization with dynamic channel-wise precision boost.arXiv preprint arXiv:2511.18643, 2025
-
[32]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[33]
Turboquant: Online vector quantization with near-optimal distortion rate
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. Turboquant: Online vector quantization with near-optimal distortion rate. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[34]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
2024
-
[35]
Cam: Cache merging for memory-efficient LLMs inference
Yuxin Zhang, Yuxuan Du, Gen Luo, Yunshan Zhong, Zhenyu Zhang, Shiwei Liu, and Rongrong Ji. Cam: Cache merging for memory-efficient LLMs inference. InForty-first International Conference on Machine Learning, 2024
2024
-
[36]
H 2O: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang "Atlas" Wang, and Beidi Chen. H 2O: Heavy-hitter oracle for efficient generative inference of large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in N...
2023
-
[37]
The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day
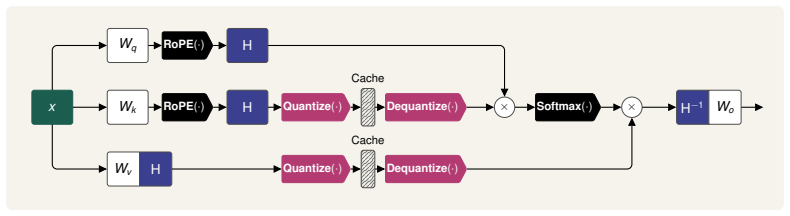
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models, 2023. 12 Wq RoPE(·) H Wk RoPE(·) H Wv H Quantize(·) Quantize(·) Cache Cache Dequantize(·) Dequantize(·) × Softmax(·) × H−1 Wox Figure 7: Arrangement of Hadamard transforms in an attention la...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.