When Graph Tokens Sink: A Mechanistic Analysis of Graph Language Models
Pith reviewed 2026-06-28 11:25 UTC · model grok-4.3
The pith
Graph sink tokens in GLMs show high activation but interventions prove they are not the main carriers of graph information for predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
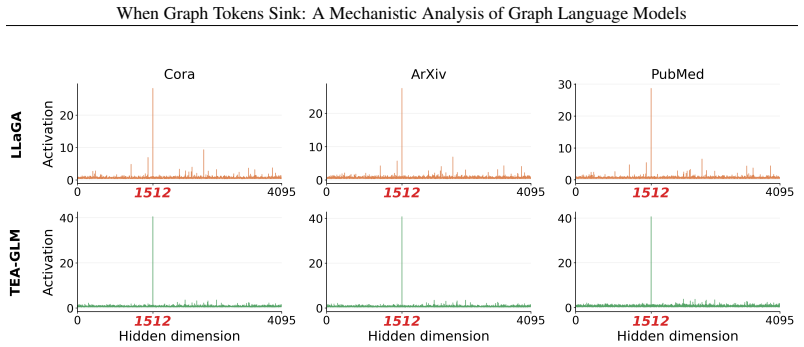
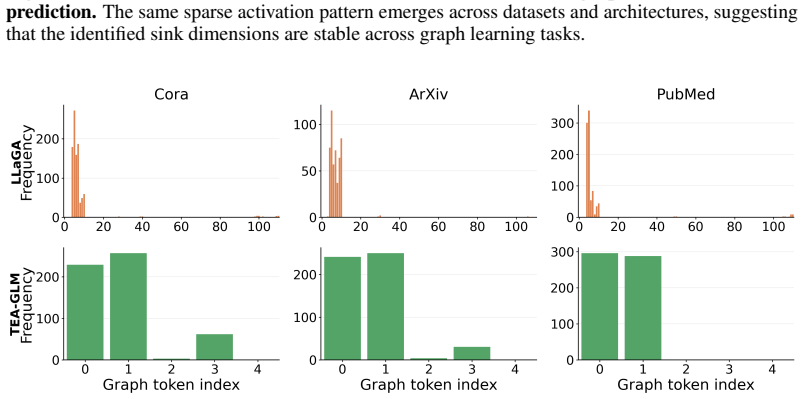
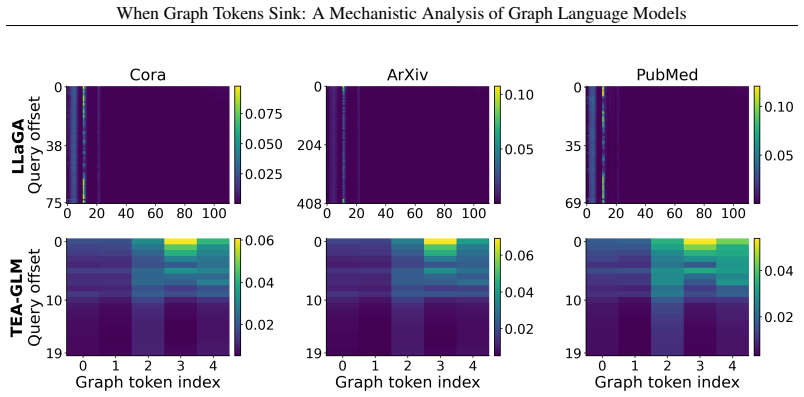
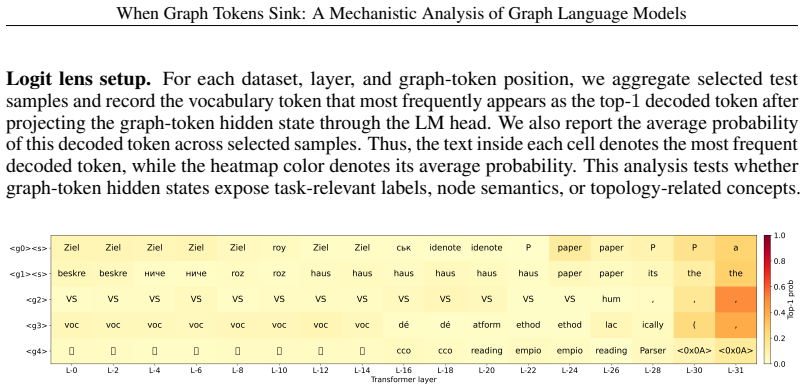
Graph sink tokens consistently emerge as activation-level outliers in GLMs, identified by massive activation values along a small set of hidden-state dimensions and biased toward early graph-token positions. Unlike classical attention sinks, they do not necessarily attract the largest attention weights from query tokens. Through pruning, repositioning, and swapping interventions, these tokens are shown not to be the most important semantic or structural tokens for downstream prediction, indicating that graph-token representations do not naturally form a fully usable topology-aware internal representation.
What carries the argument
Graph sink tokens, identified as activation-level outliers with massive values in specific hidden-state dimensions.
If this is right
- The internal saliency of graph tokens is not equivalent to their utilization of graph information.
- Graph sink tokens do not attract the largest attention weights in the way attention sinks do in other models.
- Current graph-token construction, placement, and alignment mechanisms have limitations in producing usable representations.
- After mapping graph structure into token space, the resulting representations exhibit decoupling between activation saliency and semantic utility.
Where Pith is reading between the lines
- Alternative methods for encoding graph topology into tokens might reduce the observed decoupling and improve performance.
- The pattern could extend to other adaptations of language models to structured or multimodal inputs beyond graphs.
- Examining a wider range of graph datasets or model scales would test how general the decoupling effect is.
Load-bearing premise
The pruning, repositioning, and swapping interventions accurately isolate and measure the contribution of graph sink tokens to graph information utilization without confounding effects from other model components.
What would settle it
An experiment showing that pruning or swapping graph sink tokens causes large drops in downstream prediction accuracy on graph tasks would indicate they are more important than claimed.
Figures











read the original abstract
Graph Language Models (GLMs) have become a promising direction for adapting Large Language Models (LLMs) to graph learning tasks. By transforming graph topology and node information into graph tokens, GLMs allow LLMs to jointly process structured graph inputs and textual instructions. Yet, it remains unclear how LLMs internally interpret these graph tokens and whether graph tokens act as meaningful carriers of graph structure. In this work, we analyze how LLMs process graph information through graph-token behavior in representative GLM architectures. Findings. We find that the internal saliency of graph tokens in GLMs is not equivalent to graph information utilization. Graph sink tokens consistently emerge as activation-level outliers: they can be identified by massive activation values along a small set of hidden-state dimensions and are biased toward early graph-token positions. However, this activation-level saliency does not imply that these tokens are the main carriers of graph information. Unlike classical attention sinks in language and vision-language models, graph sink tokens do not necessarily attract the largest attention weights from query tokens. Through pruning, repositioning, and swapping interventions, we show that graph sink tokens are not the most important semantic or structural tokens for downstream prediction. Implications. Together, these results suggest that after current GLMs map graph structure into the LLM token space, the resulting graph-token representations do not naturally form a fully usable topology-aware internal representation; instead, they exhibit a decoupling between activation-level saliency and graph-semantic utility. This decoupling points to limitations in existing graph-token construction, placement, and alignment mechanisms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Graph Language Models (GLMs) produce graph sink tokens as activation-level outliers (high values in early positions along few dimensions) that do not equate to graph information utilization. Unlike attention sinks, these tokens do not attract the largest attention weights, and pruning, repositioning, and swapping interventions demonstrate they are not the primary semantic or structural carriers for downstream prediction, revealing a decoupling between activation saliency and graph-semantic utility after mapping graph structure into token space.
Significance. If the results hold, the work supplies mechanistic evidence that current graph-token construction, placement, and alignment mechanisms in GLMs fail to yield fully usable topology-aware internal representations. The intervention-based empirical approach on existing models yields falsifiable claims about token importance that could directly inform better GLM designs for joint graph-text processing.
major comments (1)
- [Abstract] Abstract (Findings paragraph): the pruning, repositioning, and swapping interventions are described without reference to control experiments that hold global factors constant (e.g., matching total activation mass removed, preserving attention entropy, or controlling for sequence-length effects). This is load-bearing for the central claim, because repositioning early high-activation tokens can alter query-key alignments across the entire sequence and pruning can reduce model capacity non-specifically, preventing isolation of sink-token contributions.
minor comments (2)
- [Abstract] Abstract: no quantitative results, datasets, model sizes, or statistical controls are supplied, making it impossible to assess effect sizes or robustness from the provided text alone.
- [Abstract] Abstract: the phrase 'graph sink tokens' is introduced without an explicit operational definition (e.g., exact activation threshold or dimension count) or citation to prior attention-sink literature, which would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comment below and commit to revisions that strengthen the isolation of sink-token effects.
read point-by-point responses
-
Referee: [Abstract] Abstract (Findings paragraph): the pruning, repositioning, and swapping interventions are described without reference to control experiments that hold global factors constant (e.g., matching total activation mass removed, preserving attention entropy, or controlling for sequence-length effects). This is load-bearing for the central claim, because repositioning early high-activation tokens can alter query-key alignments across the entire sequence and pruning can reduce model capacity non-specifically, preventing isolation of sink-token contributions.
Authors: We agree that the abstract does not explicitly reference control experiments that hold global factors constant, and that this is a valid concern for isolating the contribution of sink tokens. In the full paper the interventions target specific high-activation tokens while preserving overall sequence length and model capacity where possible, but we acknowledge that additional matched controls (e.g., random pruning of equivalent activation mass or repositioning of non-sink tokens) would further rule out nonspecific effects. We will revise the abstract to note these controls and expand the experimental section with explicit control conditions that match total activation mass removed and preserve attention entropy statistics. revision: yes
Circularity Check
No circularity: empirical intervention study with no derivation chain
full rationale
The paper is an empirical mechanistic analysis relying on pruning, repositioning, and swapping interventions to assess graph sink token importance. The abstract and described findings contain no equations, parameter fittings, self-definitional constructs, or derivations that reduce to inputs by construction. Claims rest on experimental outcomes rather than any mathematical chain or self-citation load-bearing uniqueness theorem. This matches the default expectation for non-circular empirical work; the interventions are presented as direct measurements without reduction to fitted parameters or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Can language models solve graph problems in natural language?Advances in Neural Informa- tion Processing Systems, 36:30840–30861, 2023
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. Can language models solve graph problems in natural language?Advances in Neural Informa- tion Processing Systems, 36:30840–30861, 2023. 1
2023
-
[2]
Can we soft prompt llms for graph learning tasks? InCompanion proceedings of the ACM web conference 2024, pages 481–484, 2024
Zheyuan Liu, Xiaoxin He, Yijun Tian, and Nitesh V Chawla. Can we soft prompt llms for graph learning tasks? InCompanion proceedings of the ACM web conference 2024, pages 481–484, 2024
2024
-
[3]
Exploring the potential of large language models (llms) in learning on graphs.ACM SIGKDD Explorations Newsletter, 25(2):42–61, 2024
Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, et al. Exploring the potential of large language models (llms) in learning on graphs.ACM SIGKDD Explorations Newsletter, 25(2):42–61, 2024. 1
2024
-
[4]
Large language models on graphs: A comprehensive survey.IEEE Transactions on Knowledge and Data Engineering, 36(12):8622–8642, 2024
Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. Large language models on graphs: A comprehensive survey.IEEE Transactions on Knowledge and Data Engineering, 36(12):8622–8642, 2024. 1, 9
2024
-
[5]
A survey of large lan- guage models for graphs
Xubin Ren, Jiabin Tang, Dawei Yin, Nitesh Chawla, and Chao Huang. A survey of large lan- guage models for graphs. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6616–6626, 2024. 1, 9
2024
-
[6]
Graphgpt: Graph instruction tuning for large language models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: Graph instruction tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 491–500, 2024. 1
2024
-
[7]
Bert busters: Outlier dimensions that disrupt transformers
Olga Kovaleva, Saurabh Kulshreshtha, Anna Rogers, and Anna Rumshisky. Bert busters: Outlier dimensions that disrupt transformers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 3392–3405, 2021. 1
2021
-
[8]
Outlier suppression: Pushing the limit of low-bit transformer language models.Advances in Neural Information Processing Systems, 35:17402–17414, 2022
Xiuying Wei, Yunchen Zhang, Xiangguo Zhang, Ruihao Gong, Shanghang Zhang, Qi Zhang, Fengwei Yu, and Xianglong Liu. Outlier suppression: Pushing the limit of low-bit transformer language models.Advances in Neural Information Processing Systems, 35:17402–17414, 2022. 1
2022
-
[9]
Jiayun Luo, Wan-Cyuan Fan, Lyuyang Wang, Xiangteng He, Tanzila Rahman, Purang Abol- maesumi, and Leonid Sigal. To sink or not to sink: Visual information pathways in large vision-language models.arXiv preprint arXiv:2510.08510, 2025. 1, 2, 3, 10, 14
-
[10]
Zhong Guan, Likang Wu, Hongke Zhao, Ming He, and Jianpin Fan. Attention mechanisms per- spective: Exploring llm processing of graph-structured data.arXiv preprint arXiv:2505.02130,
-
[11]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023. 2
2023
-
[12]
Vision Transformers Need Registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers.arXiv preprint arXiv:2309.16588, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Massive Activations in Large Language Models
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models.arXiv preprint arXiv:2402.17762, 2024. 3, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321, 2025. 2, 10
-
[15]
Shangwen Sun, Alfredo Canziani, Yann LeCun, and Jiachen Zhu. The spike, the sparse and the sink: Anatomy of massive activations and attention sinks.arXiv preprint arXiv:2603.05498,
-
[16]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
arXiv preprint arXiv:2402.08170 (2024)
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, and Zhangyang Wang. Llaga: Large language and graph assistant.arXiv preprint arXiv:2402.08170, 2024. 3, 9
-
[18]
Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37:5950–5973, 2024
Duo Wang, Yuan Zuo, Fengzhi Li, and Junjie Wu. Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37:5950–5973, 2024. 3, 9 11 When Graph Tokens Sink: A Mechanistic Analysis of Graph Language Models
2024
-
[19]
Revisiting semi-supervised learning with graph embeddings
Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embeddings. InInternational conference on machine learning, pages 40–48. PMLR,
-
[20]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020. 3
2020
-
[21]
Collective classification in network data.AI magazine, 29(3):93–93, 2008
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi- Rad. Collective classification in network data.AI magazine, 29(3):93–93, 2008. 3
2008
-
[22]
Interpreting gpt: The logit lens
nostalgebraist. Interpreting gpt: The logit lens. https://www.lesswrong.com/posts/ AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens , 2020. LessWrong blog post. 8
2020
-
[23]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[24]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Furman, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Rethinking explainability in the era of multimodal ai.arXiv preprint arXiv:2506.13060, 2025
Chirag Agarwal. Rethinking explainability in the era of multimodal ai.arXiv preprint arXiv:2506.13060, 2025. 8
-
[26]
Graph representation learning: a survey.APSIPA Transactions on Signal and Information Processing, 9:e15, 2020
Fenxiao Chen, Yun-Cheng Wang, Bin Wang, and C-C Jay Kuo. Graph representation learning: a survey.APSIPA Transactions on Signal and Information Processing, 9:e15, 2020. 9
2020
-
[27]
Towards a unified framework for fair and stable graph representation learning
Chirag Agarwal, Himabindu Lakkaraju, and Marinka Zitnik. Towards a unified framework for fair and stable graph representation learning. InUncertainty in artificial intelligence, pages 2114–2124. PMLR, 2021
2021
-
[28]
Ding Zhang, Siddharth Betala, and Chirag Agarwal. Quantifying explanation quality in graph neural networks using out-of-distribution generalization.arXiv preprint arXiv:2602.07708, 2026
-
[29]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
2024
-
[30]
Efficient and robust continual graph learning for graph classification in biology.IEEE Transactions on Signal and Information Processing over Networks, 2025
Ding Zhang, Jane Downer, Can Chen, and Ren Wang. Efficient and robust continual graph learning for graph classification in biology.IEEE Transactions on Signal and Information Processing over Networks, 2025
2025
-
[31]
A survey of graph neural networks in real world: Imbalance, noise, privacy and ood challenges.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Wei Ju, Siyu Yi, Yifan Wang, Zhiping Xiao, Zhengyang Mao, Hourun Li, Yiyang Gu, Yifang Qin, Nan Yin, Senzhang Wang, et al. A survey of graph neural networks in real world: Imbalance, noise, privacy and ood challenges.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 9
2025
-
[32]
Yuhan Li, Zhixun Li, Peisong Wang, Jia Li, Xiangguo Sun, Hong Cheng, and Jeffrey Xu Yu. A survey of graph meets large language model: Progress and future directions.arXiv preprint arXiv:2311.12399, 2023. 9
-
[33]
Text-attributed graph represen- tation learning: Methods, applications, and challenges
Delvin Ce Zhang, Menglin Yang, Rex Ying, and Hady W Lauw. Text-attributed graph represen- tation learning: Methods, applications, and challenges. InCompanion Proceedings of the ACM Web Conference 2024, pages 1298–1301, 2024. 9
2024
-
[34]
Language is all a graph needs
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. Language is all a graph needs. InFindings of the association for computational linguistics: EACL 2024, pages 1955–1973, 2024. 9, 17
2024
-
[35]
Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning.Advances in neural information processing systems, 36:5850–5887, 2023
Haiteng Zhao, Shengchao Liu, Ma Chang, Hannan Xu, Jie Fu, Zhihong Deng, Lingpeng Kong, and Qi Liu. Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning.Advances in neural information processing systems, 36:5850–5887, 2023. 9
2023
-
[36]
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. Duoattention: Efficient long-context llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819, 2024. 10 12 When Graph Tokens Sink: A Mechanistic Analysis of Graph Language Models
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
When Attention Sink Emerges in Language Models: An Empirical View
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems, 35: 30318–30332, 2022. 10
2022
-
[39]
House of cards: Massive weights in llms.arXiv preprint arXiv:2410.01866, 2024
Jaehoon Oh, Seungjun Shin, and Dokwan Oh. House of cards: Massive weights in llms.arXiv preprint arXiv:2410.01866, 2024. 10
-
[40]
Stephen Zhang, Mustafa Khan, and Vardan Papyan. Attention sinks: A’catch, tag, re- lease’mechanism for embeddings.arXiv preprint arXiv:2502.00919, 2025. 10
-
[41]
Umberto Cappellazzo, Stavros Petridis, Maja Pantic, et al. Mitigating attention sinks and massive activations in audio-visual speech recognition with llms.arXiv preprint arXiv:2510.22603,
-
[42]
Keyu Duan, Qian Liu, Tat-Seng Chua, Shuicheng Yan, Wei Tsang Ooi, Qizhe Xie, and Junxian He. Simteg: A frustratingly simple approach improves textual graph learning.arXiv preprint arXiv:2308.02565, 2023. 18 13 When Graph Tokens Sink: A Mechanistic Analysis of Graph Language Models A Appendix A.1 More Intervention Results We provide additional intervention...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.