Better Pauli Channel Learning with Maximum Likelihood Estimation
Pith reviewed 2026-06-28 09:31 UTC · model grok-4.3
The pith
For 1D-local sparse Pauli-Lindblad channels, the likelihood in maximum likelihood estimation reduces to an efficiently-evaluable Bayesian network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For the common case of a 1D-local sparse Pauli-Lindblad channel, the likelihood function reduces to an efficiently-evaluable Bayesian network. The resulting computation leads to substantially improved tomography. This can produce meaningful reductions in the overhead of error mitigation, with possible extensions discussed for non-1D circuits and non-Pauli errors.
What carries the argument
Reduction of the likelihood function to an efficiently-evaluable Bayesian network for 1D-local sparse Pauli-Lindblad channels.
If this is right
- Substantially improved accuracy in estimating 1D-local sparse Pauli-Lindblad channels.
- Lower sample overhead for probabilistic error cancellation when using the resulting noise estimates.
- Tractable maximum likelihood estimation becomes available for a practically relevant noise class where it was previously intractable.
Where Pith is reading between the lines
- If real hardware exhibits this exact noise structure, the method could reduce the total resources required to reach a target fidelity in quantum algorithms.
- Similar network reductions might exist for other sparse local models even when the circuit is not strictly one-dimensional.
- Hardware experiments that inject known 1D-local Pauli-Lindblad noise would directly test whether the predicted efficiency gains materialize.
Load-bearing premise
The noise channel is exactly a 1D-local sparse Pauli-Lindblad model.
What would settle it
A controlled simulation or experiment on a device whose noise matches the 1D-local sparse Pauli-Lindblad model in which the new MLE procedure produces no accuracy gain over standard tomography methods.
Figures
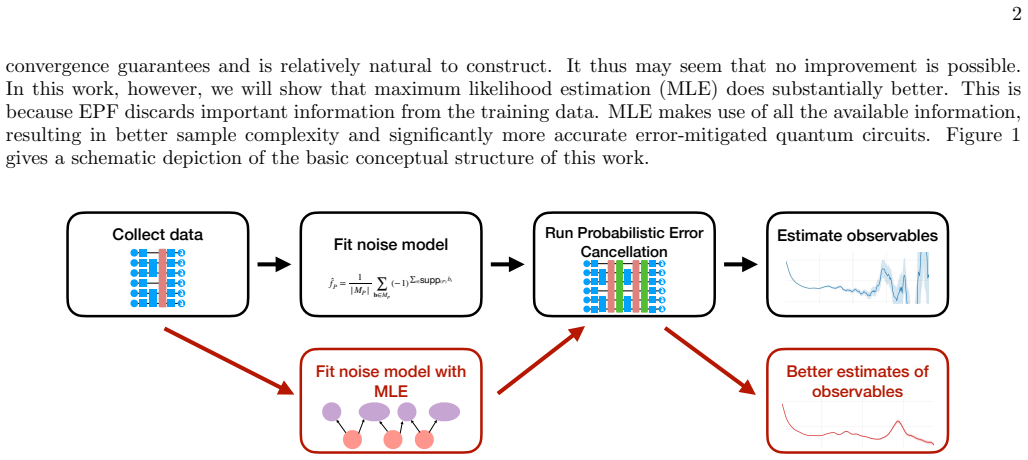
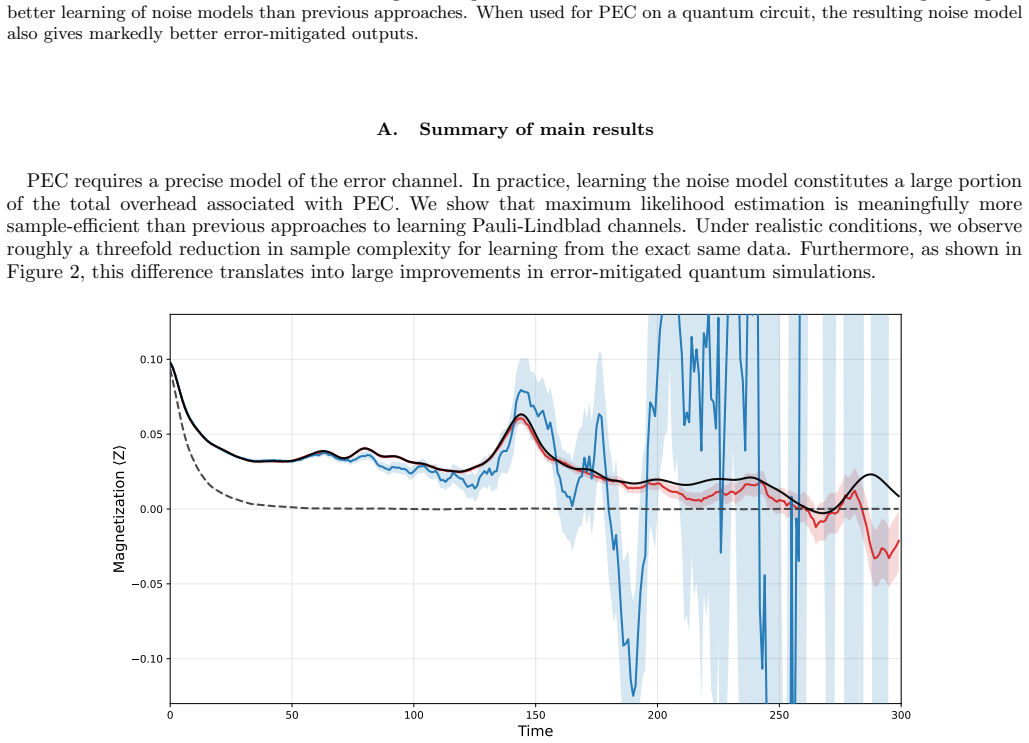

read the original abstract
Error mitigation in a noisy quantum device requires a very good estimate of the noise channel. The accuracy of probabilistic error cancellation is often limited by the high sample complexity of channel tomography. In principle, optimal sample complexity is attained by maximum likelihood estimation (MLE), but MLE is computationally challenging. We show that MLE can be made computationally tractable in certain cases of interest. For the common case of a 1D-local sparse Pauli-Lindblad channel, the likelihood function reduces to an efficiently-evaluable Bayesian network. We show that the resulting computation leads to substantially improved tomography. In addition, we demonstrate by simulation that this can lead to meaningful improvements to the overhead of error mitigation. We also discuss possible extensions of our algorithm to more general settings, such as non-1D circuits and non-Pauli errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that maximum likelihood estimation (MLE) for Pauli channel tomography, while optimal in sample complexity, is made computationally tractable for the common case of 1D-local sparse Pauli-Lindblad channels because the likelihood function reduces to an efficiently-evaluable Bayesian network; simulations are said to show substantially improved tomography and meaningful reductions in error-mitigation overhead, with extensions discussed for non-1D circuits and non-Pauli errors.
Significance. If the Bayesian-network reduction is correctly derived and the simulations establish concrete gains over existing tomography methods, the work would offer a practical route to near-optimal sample complexity for noise characterization under a frequently invoked noise model, directly benefiting probabilistic error cancellation. The explicit restriction to the 'common case' of 1D-local sparse Pauli-Lindblad channels is a strength that avoids overclaiming generality.
major comments (2)
- [Abstract] Abstract: the claims of 'substantially improved tomography' and 'meaningful improvements to the overhead of error mitigation' are asserted on the basis of simulations, yet the abstract supplies no quantitative metrics, error bars, or baseline comparisons; the simulations section must supply these numbers (e.g., sample-complexity ratios or mitigation-overhead factors versus standard methods) for the improvement claim to be assessable.
- [Abstract / common-case section] The reduction of the likelihood to a Bayesian network is derived under the exact assumption that the channel is 1D-local and sparse Pauli-Lindblad; any deviation (non-local terms, non-Pauli errors, or denser support) invalidates both the tractability argument and the claimed sample-complexity gains, and this load-bearing modeling assumption should be stated with a precise theorem or proposition number.
minor comments (1)
- [Abstract] The abstract refers to 'the common case' without a forward reference to the precise definition or section that enumerates the locality and sparsity conditions.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'substantially improved tomography' and 'meaningful improvements to the overhead of error mitigation' are asserted on the basis of simulations, yet the abstract supplies no quantitative metrics, error bars, or baseline comparisons; the simulations section must supply these numbers (e.g., sample-complexity ratios or mitigation-overhead factors versus standard methods) for the improvement claim to be assessable.
Authors: We agree that the abstract would be strengthened by including quantitative metrics. In the revised version we will update the abstract to report specific sample-complexity ratios, mitigation-overhead reduction factors, error bars, and direct comparisons to standard tomography methods, drawing these numbers explicitly from the simulations section. revision: yes
-
Referee: [Abstract / common-case section] The reduction of the likelihood to a Bayesian network is derived under the exact assumption that the channel is 1D-local and sparse Pauli-Lindblad; any deviation (non-local terms, non-Pauli errors, or denser support) invalidates both the tractability argument and the claimed sample-complexity gains, and this load-bearing modeling assumption should be stated with a precise theorem or proposition number.
Authors: We concur that the tractability result and associated gains hold only under the stated modeling assumptions. We will introduce a new, numbered theorem (or proposition) in the common-case section that formally states the 1D-local sparse Pauli-Lindblad assumption and the precise conditions under which the Bayesian-network reduction and sample-complexity claims are valid. revision: yes
Circularity Check
No circularity; derivation is a model-specific reduction of standard MLE
full rationale
The paper derives that, under the explicit assumption of a 1D-local sparse Pauli-Lindblad channel, the likelihood function for MLE reduces to an efficiently evaluable Bayesian network. This is a direct structural consequence of the noise model (not a fit, self-definition, or self-citation chain). No load-bearing step equates a prediction to its own input by construction, and the contribution is an algorithmic reformulation rather than a tautological renaming or imported uniqueness theorem. The result remains self-contained against external benchmarks once the model assumption is granted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The noise channel is a 1D-local sparse Pauli-Lindblad channel
Reference graph
Works this paper leans on
-
[1]
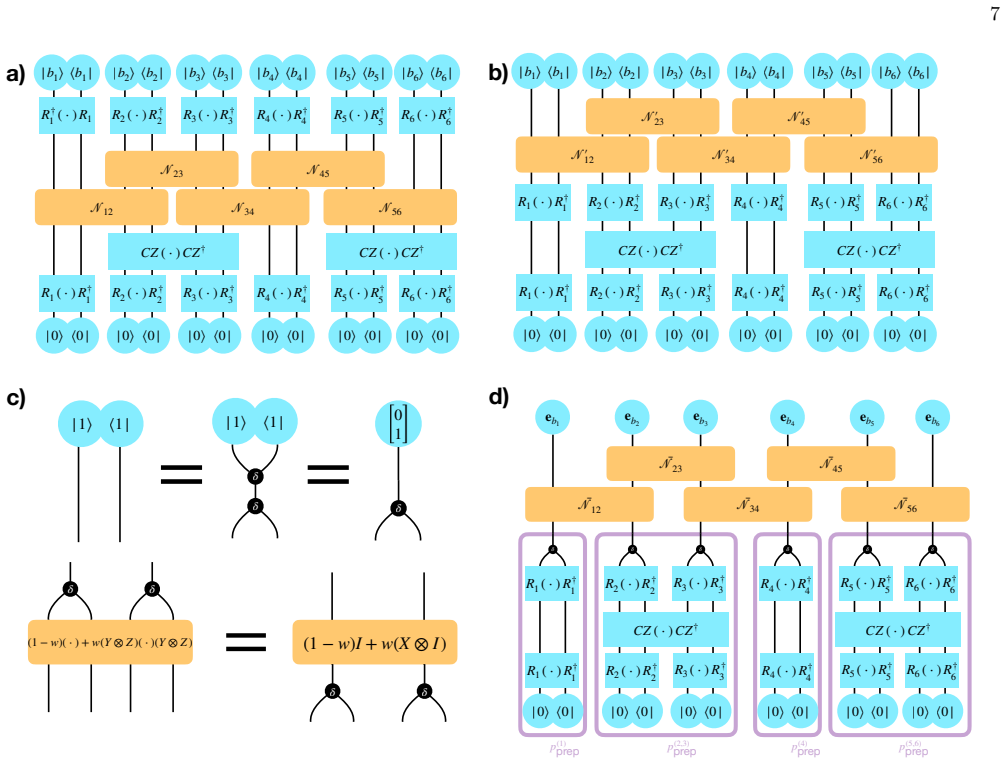
We now study the structure ofp prep
Structure ofp prep This probability distribution still requires 2 n real numbers to specify, so we haven’t improved computational tractability very much yet. We now study the structure ofp prep. Recall thatCis a single layer of CZ gates. Consider first a qubit that is not acted on by any of the gates. This qubit is prepared in a stateR †R|0⟩=|0⟩, so the c...
-
[2]
However, in general such a network can’t be efficiently evaluated, since E⃗ℓ involves a sum over all 2 m possible configurations of the latent variables
Simplifying the network Equation (23) describes a Bayesian network. However, in general such a network can’t be efficiently evaluated, since E⃗ℓ involves a sum over all 2 m possible configurations of the latent variables. We will now show that this description of the network has a great deal of redundancy. Uninformative bitsSuppose a bit is prepared in an...
-
[3]
Thenp prep(b) = 1 2 for both bits, i.e., they are each in an equal mixture of 0 and 1
Suppose aCZ gate acts on two sites for whichR 1, R2 are both nontrivial. Thenp prep(b) = 1 2 for both bits, i.e., they are each in an equal mixture of 0 and 1. It follows that these bits will be independent of the others at all later times. No matter what latent variables act, they will end up in a distributionp out(b) = 1
-
[4]
uninformative
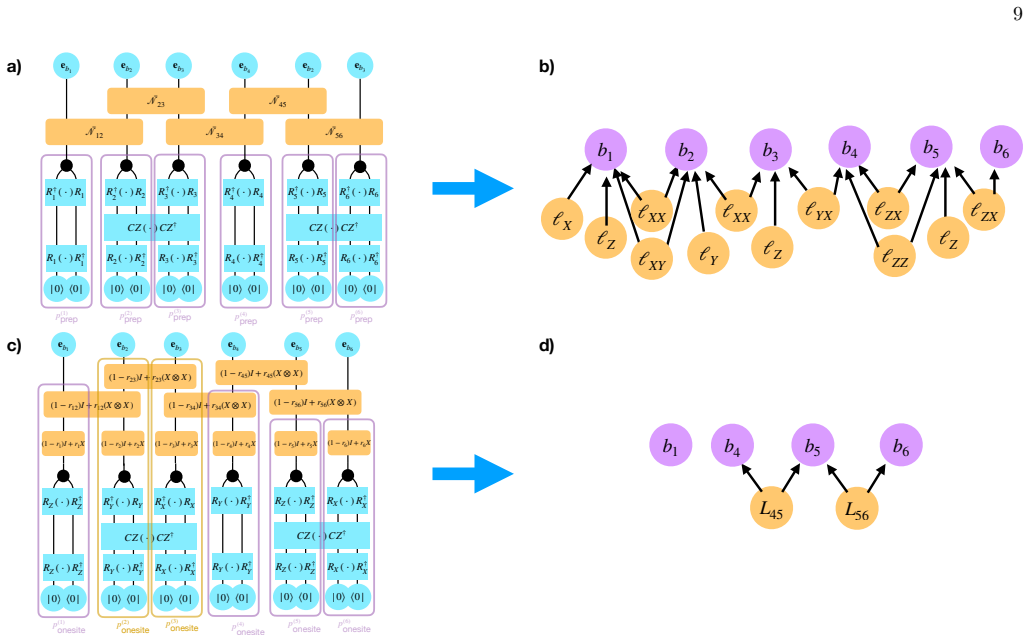
These bits are termed “uninformative”, since measurement outcomes on them carry no information at all about the structure of the channel. We may drop them from our network entirely. Latent variables that affect only uninformative bits are likewise dropped. The surviving bits all satisfyp (i) prep(b) =δ b0. 9 (1 − r45)I + r45(X ⊗ X ) CZ ( ⋅) CZ † δ δ δ δ δ...
-
[5]
We may write explicitly p(i) out bi|L(i) =p (i) prep " M s:i∈s Ls ! ⊕b i # (28) where⊕is the elementwise XOR
Explicit form of conditional distribution We know that the conditional distribution decomposes over qubits. We may write explicitly p(i) out bi|L(i) =p (i) prep " M s:i∈s Ls ! ⊕b i # (28) where⊕is the elementwise XOR. In other words, the conditional distribution ofb i depends only on whether the number of active latent variables touching siteiis odd or ev...
-
[6]
Optimization is made more efficient by access to gradients of the likelihood function
Optimization and convergence We can use belief propagation to evaluate the likelihood function at a single point[37]. Optimization is made more efficient by access to gradients of the likelihood function. We use the jax python library to obtain gradients and the scipy implementation of L-BFGS-B to do our optimization[38, 39]. Although the likelihood funct...
-
[7]
cut” only a small fraction of the edges in order to obtain a decomposition into treelike subgraphs. With 2D geometric locality, a second possibility is what we term “patching
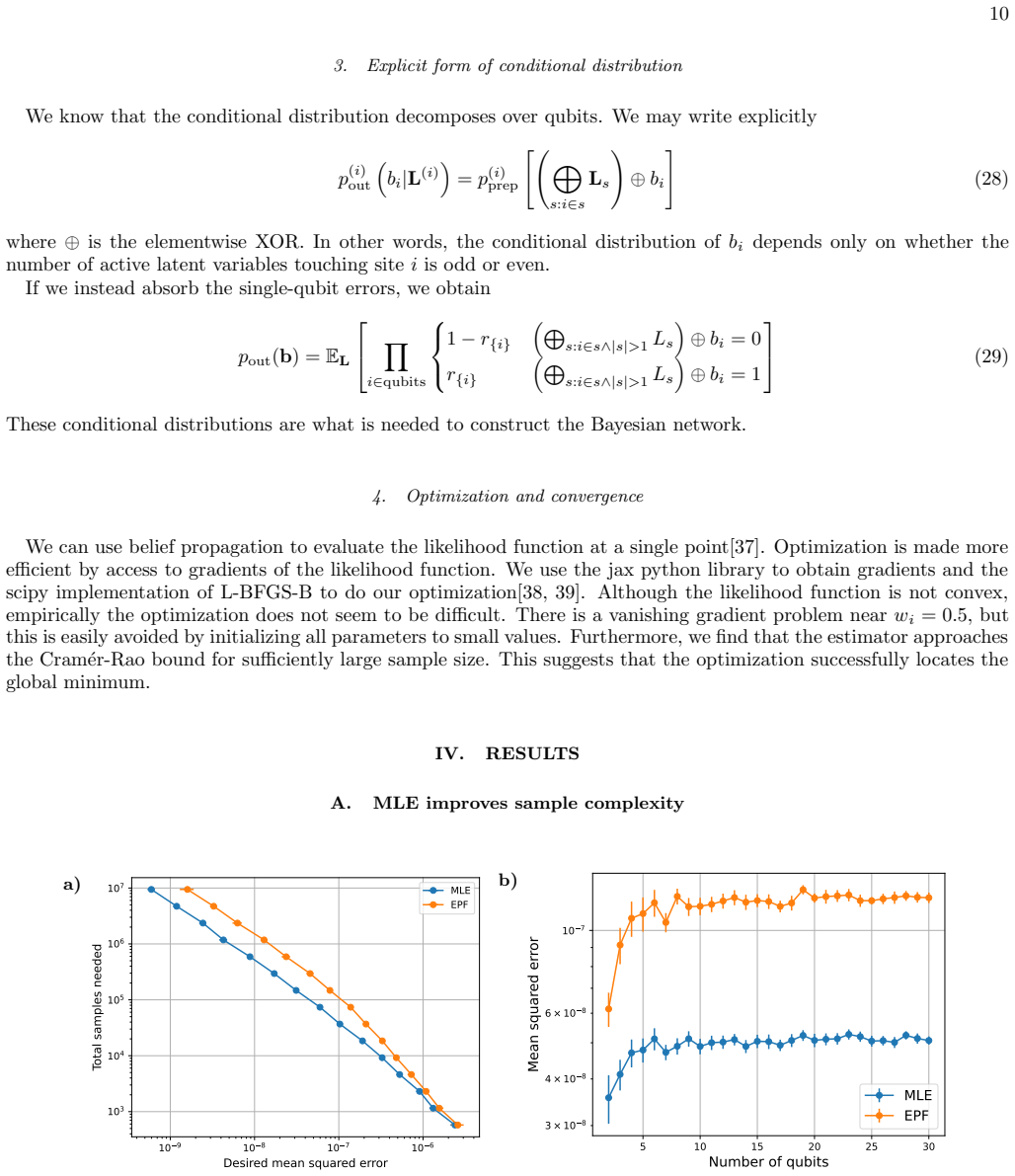
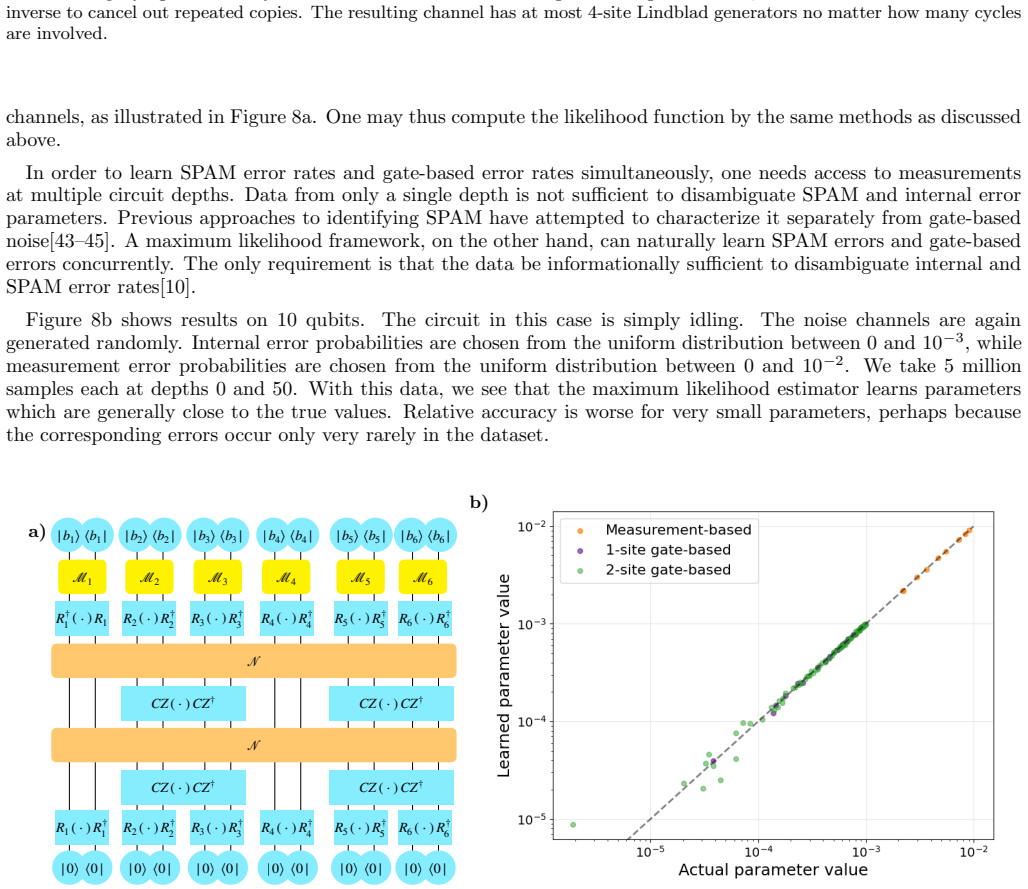
The channel is sampled randomly with maximum measurement error rate 10 −2 and maximum gate-based error rate 10 −3. 14 VI. DISCUSSION We have given an efficient noise-learning algorithm using MLE. MLE is known to be asymptotically optimal; we have shown that its advantage over other available methods is large enough to be important in practice. There are a...
-
[8]
S. Filippov, M. Leahy, M. A. C. Rossi, and G. Garc´ ıa-P´ erez, Scalable tensor-network error mitigation for near-term quantum computing (2023), arXiv:2307.11740 [quant-ph]
arXiv 2023
-
[9]
Guo and S
Y. Guo and S. Yang, Quantum Error Mitigation via Matrix Product Operators, PRX Quantum3, 040313 (2022)
2022
-
[10]
Katabarwa, K
A. Katabarwa, K. Gratsea, A. Caesura, and P. D. Johnson, Early Fault-Tolerant Quantum Computing, PRX Quantum5, 020101 (2024)
2024
-
[11]
Wagner, H
T. Wagner, H. Kampermann, D. Bruß, and M. Kliesch, Learning Logical Pauli Noise in Quantum Error Correction, Physical Review Letters130, 200601 (2023)
2023
-
[12]
H. Zheng, C.-T. Chu, S. Chen, A. G. Manes, S.-u. Lee, S. Zhou, and L. Jiang, Efficient learning of logical noise from syndrome data (2026), arXiv:2601.22286 [quant-ph]
arXiv 2026
-
[13]
Z. Zhou, S. Pexton, A. Kubica, and Y. Ding, Error Mitigation of Fault-Tolerant Quantum Circuits with Soft Information (2025), arXiv:2512.09863 [quant-ph]
arXiv 2025
-
[14]
Temme, S
K. Temme, S. Bravyi, and J. M. Gambetta, Error Mitigation for Short-Depth Quantum Circuits, Physical Review Letters 119, 180509 (2017)
2017
-
[15]
van den Berg, Z
E. van den Berg, Z. K. Minev, A. Kandala, and K. Temme, Probabilistic error cancellation with sparse Pauli–Lindblad models on noisy quantum processors, Nature Physics19, 1116 (2023)
2023
-
[16]
R. S. Gupta, E. van den Berg, M. Takita, D. Rist` e, K. Temme, and A. Kandala, Probabilistic error cancellation for dynamic quantum circuits, Physical Review A109, 062617 (2024)
2024
-
[17]
E. H. Chen, S. Chen, L. E. Fischer, A. Eddins, L. C. G. Govia, B. Mitchell, A. He, Y. Kim, L. Jiang, and A. Seif, Disambiguating Pauli noise in quantum computers (2026), arXiv:2505.22629 [quant-ph]
arXiv 2026
-
[18]
Li and S
Y. Li and S. C. Benjamin, Efficient Variational Quantum Simulator Incorporating Active Error Minimization, Physical Review X7, 021050 (2017)
2017
-
[19]
Y. Kim, A. Eddins, S. Anand, K. X. Wei, E. van den Berg, S. Rosenblatt, H. Nayfeh, Y. Wu, M. Zaletel, K. Temme, and A. Kandala, Evidence for the utility of quantum computing before fault tolerance, Nature618, 500 (2023)
2023
-
[20]
D. Aharonov, O. Alberton, I. Arad, Y. Atia, E. Bairey, M. B. Dov, A. Berkovitch, Z. Brakerski, I. Cohen, E. Fuchs, O. Golan, O. Golan, B. D. Gur, I. Gurwich, A. Haber, R. Haber, D. Halbertal, Y. Itkin, B. A. Katzir, O. Kenneth, S. Kotler, R. Levi, E. Leviatan, Y. Y. Lifshitz, A. Ludmer, S. Matityahu, R. A. Melcer, A. Meyer, O. Ovdat, A. Panahi, G. Ron, I....
Pith/arXiv arXiv 2026
-
[21]
J. F. Poyatos, J. I. Cirac, and P. Zoller, Complete Characterization of a Quantum Process: The Two-Bit Quantum Gate, Physical Review Letters78, 390 (1997)
1997
-
[22]
Sarovar, T
M. Sarovar, T. Proctor, K. Rudinger, K. Young, E. Nielsen, and R. Blume-Kohout, Detecting crosstalk errors in quantum information processors, Quantum4, 321 (2020)
2020
-
[23]
A. Carignan-Dugas, D. Dahlen, I. Hincks, E. Ospadov, S. J. Beale, S. Ferracin, J. Skanes-Norman, J. Emerson, and J. J. Wallman, The Error Reconstruction and Compiled Calibration of Quantum Computing Cycles (2023), arXiv:2303.17714 [quant-ph]
arXiv 2023
-
[24]
M. R. Geller and Z. Zhou, Efficient error models for fault-tolerant architectures and the Pauli twirling approximation, Physical Review A88, 012314 (2013)
2013
-
[25]
Hashim, R
A. Hashim, R. K. Naik, A. Morvan, J.-L. Ville, B. Mitchell, J. M. Kreikebaum, M. Davis, E. Smith, C. Iancu, K. P. O’Brien, I. Hincks, J. J. Wallman, J. Emerson, and I. Siddiqi, Randomized Compiling for Scalable Quantum Computing on a Noisy Superconducting Quantum Processor, Physical Review X11, 041039 (2021). 16
2021
-
[26]
J. J. Wallman and J. Emerson, Noise tailoring for scalable quantum computation via randomized compiling, Physical Review A94, 052325 (2016)
2016
-
[27]
Nielsen, J
E. Nielsen, J. K. Gamble, K. Rudinger, T. Scholten, K. Young, and R. Blume-Kohout, Gate Set Tomography, Quantum 5, 557 (2021)
2021
-
[28]
H. P. Nautrup, N. Delfosse, V. Dunjko, H. J. Briegel, and N. Friis, Optimizing Quantum Error Correction Codes with Reinforcement Learning, Quantum3, 215 (2019)
2019
-
[29]
Sivak, M
V. Sivak, M. Newman, and P. Klimov, Optimization of Decoder Priors for Accurate Quantum Error Correction, Physical Review Letters133, 150603 (2024)
2024
-
[30]
S. T. Flammia and J. J. Wallman, Efficient estimation of Pauli channels, ACM Transactions on Quantum Computing1, 1 (2020), arXiv:1907.12976 [quant-ph]
arXiv 2020
-
[31]
D’Ambrosio, Inference in Bayesian Networks, AI Magazine20, 21 (1999)
B. D’Ambrosio, Inference in Bayesian Networks, AI Magazine20, 21 (1999)
1999
-
[32]
E. P. Xing, L. Zhu, and M. Lee, Probabilistic Graphical Models 6 : Learning Fully Observed Bayesian Networks
-
[33]
J. Pearl, Reverend bayes on inference engines: a distributed hierarchical approach, inProceedings of the Second AAAI Conference on Artificial Intelligence, AAAI’82 (AAAI Press, Pittsburgh, Pennsylvania, 1982) pp. 133–136
1982
-
[34]
A. Seif, H. Liao, V. Tripathi, K. Krsulich, M. Malekakhlagh, M. Amico, P. Jurcevic, and A. Javadi-Abhari, Suppressing Correlated Noise in Quantum Computers via Context-Aware Compiling, in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA)(2024) pp. 310–324
2024
-
[35]
X. Li, J. Wang, Y.-Y. Jiang, G.-M. Xue, X. Cai, J. Zhou, M. Gong, Z.-F. Liu, S.-Y. Zheng, D.-K. Ma, M. Chen, W.-J. Sun, S. Yang, F. Yan, Y.-R. Jin, S. P. Zhao, X.-F. Ding, and H.-F. Yu, Cosmic-ray-induced correlated errors in superconducting qubit array, Nature Communications16, 4677 (2025)
2025
-
[36]
H. P. Binney, H. D. Pinckney, K. Azar, P. M. Harrington, S. Jha, M. Li, J. Yang, F. Contipelli, R. D. Pi˜ nero, M. Gingras, B. M. Niedzielski, H. Stickler, M. E. Schwartz, J. A. Grover, M. Hays, K. Serniak, J. A. Formaggio, and W. D. Oliver, Distinguishing types of correlated errors in superconducting qubits (2026), arXiv:2603.16494 [quant-ph]
arXiv 2026
-
[37]
Acharya, D
R. Acharya, D. A. Abanin, L. Aghababaie-Beni, I. Aleiner, T. I. Andersen, M. Ansmann, F. Arute, K. Arya, A. Asfaw, N. Astrakhantsev, J. Atalaya, R. Babbush, D. Bacon, B. Ballard, J. C. Bardin, J. Bausch, A. Bengtsson, A. Bilmes, S. Blackwell, S. Boixo, G. Bortoli, A. Bourassa, J. Bovaird, L. Brill, M. Broughton, D. A. Browne, B. Buchea, B. B. Buckley, D. ...
2025
-
[38]
Alam, alam-faisal/qaravan (2026), original-date: 2025-04-01T23:15:23Z
F. Alam, alam-faisal/qaravan (2026), original-date: 2025-04-01T23:15:23Z
2026
-
[39]
S. Chen, J. Li, and A. Liu, An Optimal Tradeoff between Entanglement and Copy Complexity for State Tomography, inProceedings of the 56th Annual ACM Symposium on Theory of Computing, STOC 2024 (Association for Computing Machinery, New York, NY, USA, 2024) pp. 1331–1342
2024
-
[40]
S. Chen, W. Gong, and S. Zhou, Instance-optimal high-precision shadow tomography with few-copy measurements: A metrological approach (2026), arXiv:2602.04952 [quant-ph]
arXiv 2026
-
[41]
S. Chen, B. Huang, J. Li, A. Liu, and M. Sellke, When Does Adaptivity Help for Quantum State Learning? (2023), arXiv:2206.05265 [quant-ph]
arXiv 2023
-
[42]
Erhard, J
A. Erhard, J. J. Wallman, L. Postler, M. Meth, R. Stricker, E. A. Martinez, P. Schindler, T. Monz, J. Emerson, and R. Blatt, Characterizing large-scale quantum computers via cycle benchmarking, Nature Communications10, 5347 (2019)
2019
-
[43]
H. Cao, D. Feng, C. Ye, and F. Pan, Differentiable Maximum Likelihood Noise Estimation for Quantum Error Correction (2026), arXiv:2602.19722 [quant-ph]
arXiv 2026
-
[44]
J. S. Yedidia, W. T. Freeman, and Y. Weiss, Understanding belief propagation and its generalizations, inExploring artificial intelligence in the new millennium(Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2003) pp. 239–269. 17
2003
-
[45]
Virtanen, R
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman, N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey, ˙I. Polat, Y. Feng, E. W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen,...
2020
-
[46]
D. C. Liu and J. Nocedal, On the limited memory BFGS method for large scale optimization, Mathematical Programming 45, 503 (1989)
1989
-
[47]
Harper, I
R. Harper, I. Hincks, C. Ferrie, S. T. Flammia, and J. J. Wallman, Statistical analysis of randomized benchmarking, Physical Review A99, 052350 (2019)
2019
-
[48]
K. C. Chang and R. M. Fung, Node Aggregation for Distributed Inference in Bayesian Networks, inProceedings of the Eleventh International Joint Conference on Artificial Intelligence(International Joint Conferences on Artificial Intelligence, Menlo Park, CA, 1989) pp. 265–270
1989
-
[49]
van den Berg, Z
E. van den Berg, Z. K. Minev, and K. Temme, Model-free readout-error mitigation for quantum expectation values, Physical Review A105, 032620 (2022)
2022
-
[50]
E. Magesan, J. M. Gambetta, and J. Emerson, Characterizing Quantum Gates via Randomized Benchmarking, Physical Review A85, 042311 (2012), arXiv:1109.6887 [quant-ph]
Pith/arXiv arXiv 2012
- [51]
-
[52]
J. C. Napp, Efficient Classical Simulation of Random Shallow 2D Quantum Circuits, Physical Review X12, 10.1103/Phys- RevX.12.021021 (2022)
-
[53]
Torlai, C
G. Torlai, C. J. Wood, A. Acharya, G. Carleo, J. Carrasquilla, and L. Aolita, Quantum process tomography with unsu- pervised learning and tensor networks, Nature Communications14, 2858 (2023)
2023
-
[54]
Mangini, M
S. Mangini, M. Cattaneo, D. Cavalcanti, S. Filippov, M. A. C. Rossi, and G. Garc´ ıa-P´ erez, Tensor network noise charac- terization for near-term quantum computers, Physical Review Research6, 033217 (2024)
2024
-
[55]
Govia, S
L. Govia, S. Majumder, S. Barron, B. Mitchell, A. Seif, Y. Kim, C. Wood, E. Pritchett, S. Merkel, and D. McKay, Bounding the Systematic Error in Quantum Error Mitigation due to Model Violation, PRX Quantum6, 010354 (2025)
2025
-
[56]
H. Kwon, S. H. Lie, and L. Jiang, Universal Sample Complexity Bounds in Quantum Learning Theory via Fisher Infor- mation Matrix (2026), version Number: 2. Appendix A: Empirical Pauli Fidelities are not a sufficient statistic We will show that the empirical Pauli fidelities do not capture all of the important information in a dataset. In other words, they ...
2026
-
[57]
seems to scale roughly as the inverse of the average basis error probability, roughly 41· 1 # params P i wi −1
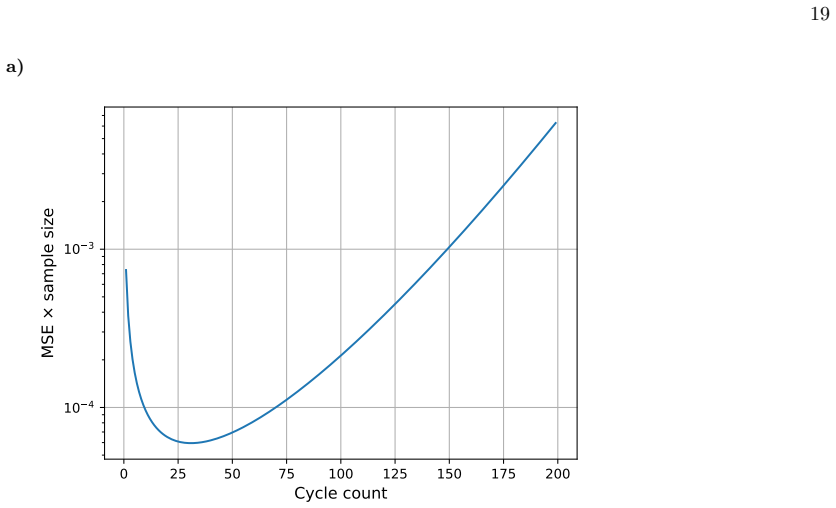
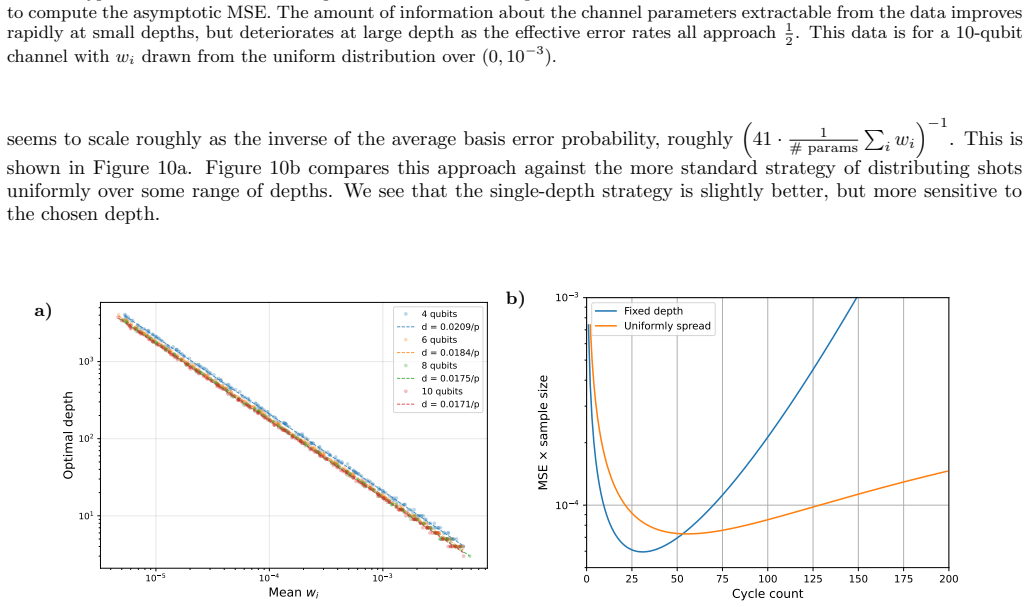
This data is for a 10-qubit channel withw i drawn from the uniform distribution over (0,10 −3). seems to scale roughly as the inverse of the average basis error probability, roughly 41· 1 # params P i wi −1 . This is shown in Figure 10a. Figure 10b compares this approach against the more standard strategy of distributing shots uniformly over some range of...
-
[58]
turned off
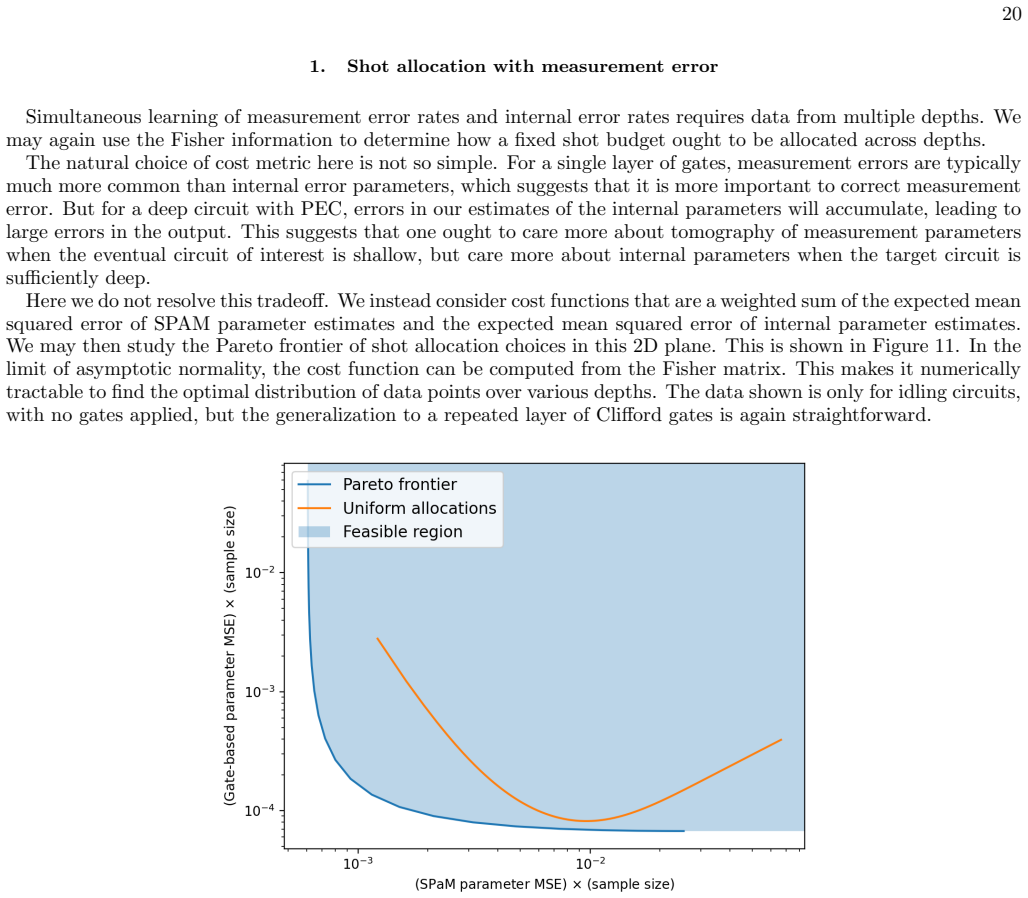
Shot allocation with measurement error Simultaneous learning of measurement error rates and internal error rates requires data from multiple depths. We may again use the Fisher information to determine how a fixed shot budget ought to be allocated across depths. The natural choice of cost metric here is not so simple. For a single layer of gates, measurem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.