RL Excursions during Pre-Training: Re-examining Policy Optimization for LLM training
Pith reviewed 2026-06-28 10:35 UTC · model grok-4.3
The pith
Applying RL early during LLM pre-training matches the performance of the standard SFT followed by RL approach.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
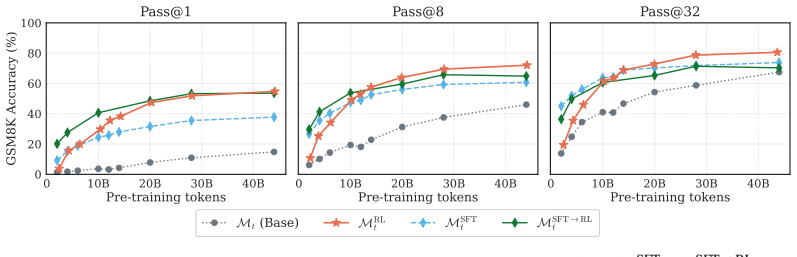
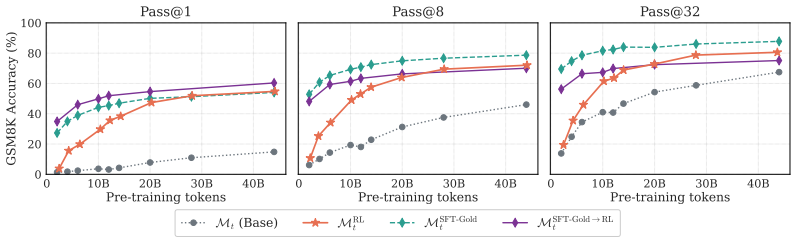
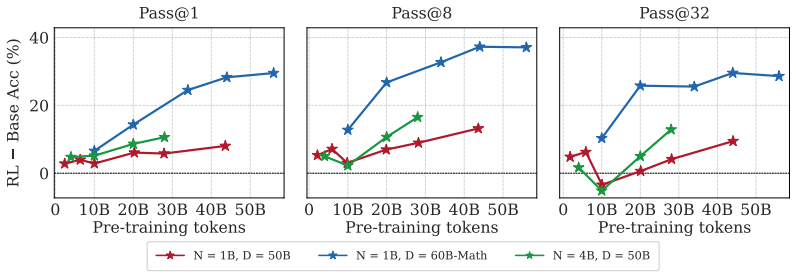
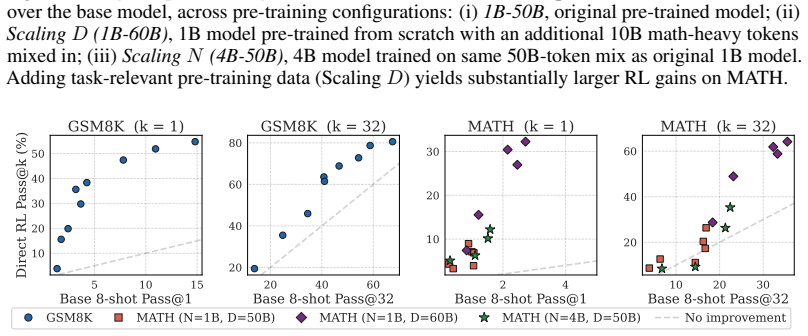
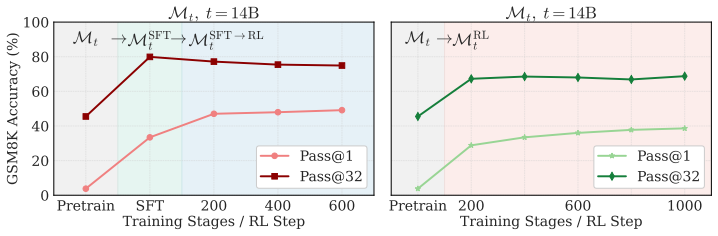
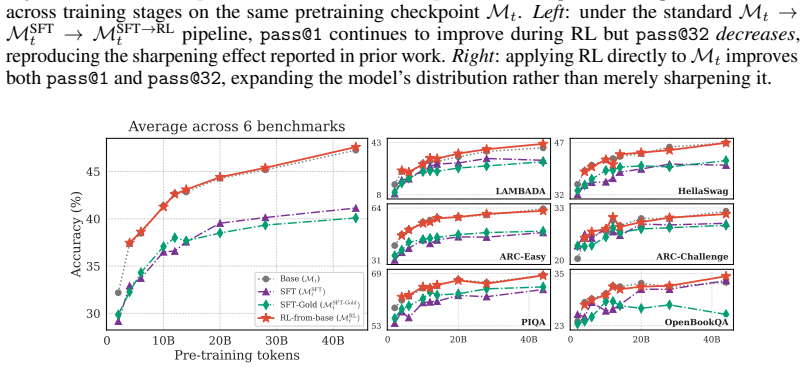
The authors show that RL applied to intermediate pre-training checkpoints is effective early on and often equals the SFT to RL pipeline, that pre-training data composition is a stronger factor for RL success than model scale, that RL broadens the model's output distribution while SFT narrows it, and that averaging RL and SFT objectives in parallel outperforms other training methods across metrics without harming general capabilities.
What carries the argument
Direct application of RL to pre-training checkpoints combined with parallel averaging of RL and SFT objectives.
If this is right
- RL can achieve strong results without a separate SFT stage first.
- Optimizing pre-training data for RL can be more impactful than scaling up models.
- Early RL preserves general model capabilities better than SFT.
- Merging objectives allows combining strengths of RL and SFT in one process.
Where Pith is reading between the lines
- Interleaving RL steps during pre-training could lead to more efficient overall training schedules.
- Models with expanded distributions from early RL might handle diverse tasks better downstream.
- Future work could explore varying the frequency of RL applications during pre-training to optimize outcomes.
Load-bearing premise
The tested pre-training checkpoints, problem types, and model sizes capture the general behavior of LLM training across different cases.
What would settle it
Running similar experiments on a different LLM architecture or dataset and observing that RL no longer becomes effective early or fails to match the SFT-RL pipeline.
Figures











read the original abstract
The standard LLM training pipeline applies reinforcement learning (RL) only after pre-training and supervised fine-tuning (SFT). We question this status quo by training a LLM from scratch and applying RL, SFT, and SFT followed by RL directly to intermediate pre-training checkpoints. We find that RL is effective very early, and often matches the full SFT$\to$RL pipeline early as well. Through experiments on harder problems, we find that targeted pre-training data composition is a strong lever for RL effectiveness, even more so than model scale. Beyond reasoning accuracy, applying RL directly to base checkpoints expands the model's distribution; the sharpening effect reported in recent work arises only when RL follows SFT. The general capabilities of the model remain essentially unchanged by RL, while they degrade following SFT. Finally, we merge RL and SFT objectives by parallel averaging, which outperforms across all other training methods discussed, across metrics, while preserving general capabilities. Together, these results suggest that LLM training might benefit from an expanded use of RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper trains LLMs from scratch and applies RL, SFT, and SFT-then-RL to intermediate pre-training checkpoints. It reports that RL becomes effective very early and often matches the full SFT o RL pipeline; that targeted pre-training data composition is a stronger lever for RL success than model scale; that RL on base checkpoints expands the output distribution while sharpening occurs only after SFT; that general capabilities remain unchanged under RL but degrade under SFT; and that parallel averaging of RL and SFT objectives outperforms all other tested regimes across metrics while preserving general capabilities. The authors conclude that LLM training would benefit from expanded use of RL.
Significance. If the empirical patterns hold under broader conditions, the work would be significant for questioning the standard post-SFT RL stage and for identifying data composition and objective merging as high-leverage levers. The distinction between distribution expansion (RL) and sharpening (SFT), plus the preservation of general capabilities, would be useful observations for training design.
major comments (2)
- [Experiments (implicit in abstract claims)] The central recommendation to expand RL use rests on the tested intermediate checkpoints, tasks, and scales being representative of typical LLM pipelines. No comparisons to standard pre-training corpora, no architecture-family variation, and no scaling curves beyond the reported points are described, which directly affects whether the headline claims generalize.
- [Results on data composition] The claim that 'targeted pre-training data composition is a strong lever for RL effectiveness, even more so than model scale' is load-bearing for the data-composition emphasis, yet the abstract provides no quantitative comparison (e.g., effect sizes or ablation tables) that would allow readers to verify the relative importance.
minor comments (1)
- [Abstract] The abstract states that 'the general capabilities of the model remain essentially unchanged by RL' without specifying the evaluation suite or controls for length or format effects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments (implicit in abstract claims)] The central recommendation to expand RL use rests on the tested intermediate checkpoints, tasks, and scales being representative of typical LLM pipelines. No comparisons to standard pre-training corpora, no architecture-family variation, and no scaling curves beyond the reported points are described, which directly affects whether the headline claims generalize.
Authors: We agree that the experiments are confined to specific intermediate checkpoints, tasks, and scales, without direct comparisons against standard pre-training corpora, architecture-family variations, or extended scaling curves. This constrains the generalizability of the headline claims. We will add a dedicated Limitations section that explicitly discusses these scope restrictions and calls for future validation on broader corpora and architectures. The controlled setting nonetheless isolates the effects of RL timing and data composition, providing evidence that challenges the conventional post-SFT RL stage. revision: yes
-
Referee: [Results on data composition] The claim that 'targeted pre-training data composition is a strong lever for RL effectiveness, even more so than model scale' is load-bearing for the data-composition emphasis, yet the abstract provides no quantitative comparison (e.g., effect sizes or ablation tables) that would allow readers to verify the relative importance.
Authors: The manuscript body contains the requested quantitative comparisons, including ablation tables and effect-size measurements that contrast data-composition changes against scale increases (Tables 2–3 and associated figures). The abstract, as a high-level summary, omits these specifics. We will revise the abstract to include a concise quantitative statement on the relative effect sizes, enabling readers to assess the claim directly from the summary. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivation chain
full rationale
The paper contains no equations, derivations, fitted parameters presented as predictions, or self-citation chains that reduce claims to inputs by construction. All results are direct empirical observations from training runs on specific checkpoints, tasks, and scales. No load-bearing step invokes a uniqueness theorem, ansatz smuggled via citation, or renaming of known results as new organization. The central findings (early RL effectiveness, data composition effects, merging objectives) rest on reported experimental outcomes rather than any self-referential reduction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.19249 , year =
Reinforcement Learning on Pre-Training Data , author =. arXiv preprint arXiv:2509.19249 , year =
-
[2]
2026 , url =
Hatamizadeh, Ali and Akter, Syeda Nahida and Prabhumoye, Shrimai and Kautz, Jan and Patwary, Mostofa and Shoeybi, Mohammad and Catanzaro, Bryan and Choi, Yejin , booktitle =. 2026 , url =
2026
-
[3]
arXiv preprint arXiv:2506.08007 , year =
Reinforcement Pre-Training , author =. arXiv preprint arXiv:2506.08007 , year =
-
[4]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[5]
Dai, Josef and Pan, Xuehai and Sun, Ruiyang and Ji, Jiaming and Xu, Xinbo and Liu, Mickel and Wang, Yizhou and Yang, Yaodong , booktitle =. Safe. 2024 , url =
2024
-
[6]
International Conference on Machine Learning (ICML) , pages =
Trust Region Policy Optimization , author =. International Conference on Machine Learning (ICML) , pages =. 2015 , organization =
2015
-
[7]
Advances in Neural Information Processing Systems , volume =
Direct Preference Optimization: Your Language Model Is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[8]
Secrets of
Zheng, Rui and Dou, Shihan and Gao, Songyang and Hua, Yuan and Shen, Wei and Wang, Binghai and Liu, Yan and Jin, Senjie and Liu, Qin and Zhou, Yuhao and others , journal =. Secrets of. 2023 , url =
2023
-
[9]
2024 , url =
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and Wu, Yang and others , journal =. 2024 , url =
2024
-
[10]
On the Interplay of Pre-Training, Mid-Training, and
Zhang, Charlie and Neubig, Graham and Yue, Xiang , journal =. On the Interplay of Pre-Training, Mid-Training, and. 2025 , url =
2025
-
[11]
T., Krishnamurthy, A., and Foster, D
The Coverage Principle: How Pre-Training Enables Post-Training , author =. arXiv preprint arXiv:2510.15020 , year =
-
[12]
arXiv preprint arXiv:2503.07453 , year =
Is a Good Foundation Necessary for Efficient Reinforcement Learning? The Computational Role of the Base Model in Exploration , author =. arXiv preprint arXiv:2503.07453 , year =
-
[13]
2026 , url =
Cheng, Zhoujun and Xie, Yutao and Qu, Yuxiao and Setlur, Amrith and Hao, Shibo and Pimpalkhute, Varad and Liang, Tongtong and Yao, Feng and Liu, Hector and Xing, Eric and Smith, Virginia and Salakhutdinov, Ruslan and Hu, Zhiting and Killian, Taylor and Kumar, Aviral , howpublished =. 2026 , url =
2026
-
[14]
2025 , url =
Xing, Xingrun and Fan, Zhiyuan and Lou, Jie and Li, Guoqi and Zhang, Jiajun and Zhang, Debing , journal =. 2025 , url =
2025
-
[15]
2023 , organization =
Biderman, Stella and Schoelkopf, Hailey and Anthony, Quentin Gregory and Bradley, Herbie and O'Brien, Kyle and Hallahan, Eric and Khan, Mohammad Aflah and Purohit, Shivanshu and Prashanth, USVSN Sai and Raff, Edward and others , booktitle =. 2023 , organization =
2023
-
[16]
Conference on Language Modeling (COLM) , year =
2. Conference on Language Modeling (COLM) , year =
-
[17]
2024 , url =
Toshniwal, Shubham and Moshkov, Ivan and Narenthiran, Sean and Gitman, Daria and Jia, Fei and Gitman, Igor , journal =. 2024 , url =
2024
-
[18]
2024 , url =
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir Yitzhak and Bansal, Hritik and Guha, Etash and Keh, Sedrick Scott and Arora, Kushal and others , journal =. 2024 , url =
2024
-
[19]
International Conference on Learning Representations (ICLR) , year =
Finetuned Language Models Are Zero-Shot Learners , author =. International Conference on Learning Representations (ICLR) , year =
-
[20]
2021 , url =
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Wen, Bo and Liu, Yunfeng , journal =. 2021 , url =
2021
-
[21]
2020 , url =
Shazeer, Noam , journal =. 2020 , url =
2020
-
[22]
Advances in Neural Information Processing Systems , pages =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , pages =. 2017 , url =
2017
-
[23]
2019 , eprint =
Decoupled Weight Decay Regularization , author =. 2019 , eprint =
2019
-
[24]
2024 , url =
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , journal =. 2024 , url =
2024
-
[25]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Measuring Mathematical Problem Solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving with the. 2021 , url =
2021
-
[28]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in
Yue, Yang and Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Yue, Yang and Song, Shiji and Huang, Gao , booktitle =. Does Reinforcement Learning Really Incentivize Reasoning Capacity in. 2025 , url =
2025
-
[29]
Training Compute-Optimal Large Language Models
Training Compute-Optimal Large Language Models , author =. arXiv preprint arXiv:2203.15556 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
The Invisible Leash: Why
Wu, Fang and Xuan, Weihao and Lu, Ximing and Liu, Mingjie and Dong, Yi and Harchaoui, Zaid and Choi, Yejin , journal =. The Invisible Leash: Why. 2025 , url =
2025
-
[31]
2023 , url =
Zhou, Chunting and Liu, Pengfei and Xu, Puxin and Iyer, Srinivasan and Sun, Jiao and Mao, Yuning and Ma, Xuezhe and Efrat, Avia and Yu, Ping and Yu, Lili and others , journal =. 2023 , url =
2023
-
[32]
2025 , url =
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and others , journal =. 2025 , url =
2025
-
[33]
arXiv preprint arXiv:2512.13961 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Learning to Reason under Off-Policy Guidance
Learning to Reason under Off-Policy Guidance , author =. arXiv preprint arXiv:2504.14945 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
2026 , url =
Dong, Yihong and Jiang, Xue and Tao, Yongding and Liu, Huanyu and Zhang, Kechi and Mou, Lili and Cao, Rongyu and Ma, Yingwei and Chen, Jue and Li, Binhua and others , booktitle =. 2026 , url =
2026
-
[36]
2025 , url =
Fu, Yuqian and Chen, Tinghong and Chai, Jiajun and Wang, Xihuai and Tu, Songjun and Yin, Guojun and Lin, Wei and Zhang, Qichao and Zhu, Yuanheng and Zhao, Dongbin , journal =. 2025 , url =
2025
-
[37]
International Conference on Machine Learning (ICML) , year =
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling , author =. International Conference on Machine Learning (ICML) , year =
-
[38]
arXiv preprint arXiv:2509.04419 , year =
Towards a Unified View of Large Language Model Post-Training , author =. arXiv preprint arXiv:2509.04419 , year =
-
[39]
2025 , url =
Liu, Mingyang and Farina, Gabriele and Ozdaglar, Asuman , journal =. 2025 , url =
2025
- [40]
-
[41]
Reasoning with Sampling: Your Base Model is Smarter Than You Think
Reasoning with Sampling: Your Base Model Is Smarter Than You Think , author =. arXiv preprint arXiv:2510.14901 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
2025 , url =
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and Liu, Lingjun and others , journal =. 2025 , url =
2025
-
[43]
2025 , url =
Chu, Tianzhe and Zhai, Yuexiang and Yang, Jihan and Tong, Shengbang and Xie, Saining and Schuurmans, Dale and Le, Quoc V and Levine, Sergey and Ma, Yi , journal =. 2025 , url =
2025
-
[44]
Proceedings of the National Academy of Sciences , volume =
Explaining Neural Scaling Laws , author =. Proceedings of the National Academy of Sciences , volume =. 2024 , publisher =
2024
-
[45]
2026 , url =
Limozin, Alexis and Durech, Eduard and Hoefler, Torsten and Schlag, Imanol and Pyatkin, Valentina , journal =. 2026 , url =
2026
-
[46]
2024 , url =
Jaech, Aaron and Kalai, Adam and Lerer, Adam and Richardson, Adam and El-Kishky, Ahmed and Low, Aiden and Helyar, Alec and Madry, Aleksander and Beutel, Alex and Carney, Alex and others , journal =. 2024 , url =
2024
-
[47]
2025 , url =
Shenfeld, Idan and Pari, Jyothish and Agrawal, Pulkit , journal =. 2025 , url =
2025
-
[48]
The Art of Scaling Reinforcement Learning Compute for LLMs
Khatri, Devvrit and Madaan, Lovish and Tiwari, Rishabh and Bansal, Rachit and Duvvuri, Sai Surya and Zaheer, Manzil and Dhillon, Inderjit S. and Brandfonbrener, David and Agarwal, Rishabh , year =. The Art of Scaling Reinforcement Learning Compute for. 2510.13786 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
2025 , eprint=
Decomposing Elements of Problem Solving: What "Math" Does RL Teach? , author=. 2025 , eprint=
2025
-
[50]
2026 , eprint=
Random Scaling of Emergent Capabilities , author=. 2026 , eprint=
2026
-
[51]
Sometimes I am a tree: Data drives unstable hierarchical generalization
Qin, Tian and Saphra, Naomi and Alvarez-Melis, David. Sometimes I am a tree: Data drives unstable hierarchical generalization. arXiv [cs.LG]. arXiv:2412.04619
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.