Rethinking Incompleteness: Formalizing Protocol Divergence and Train-Once Learning for Robust IMVC
Pith reviewed 2026-06-28 06:50 UTC · model grok-4.3
The pith
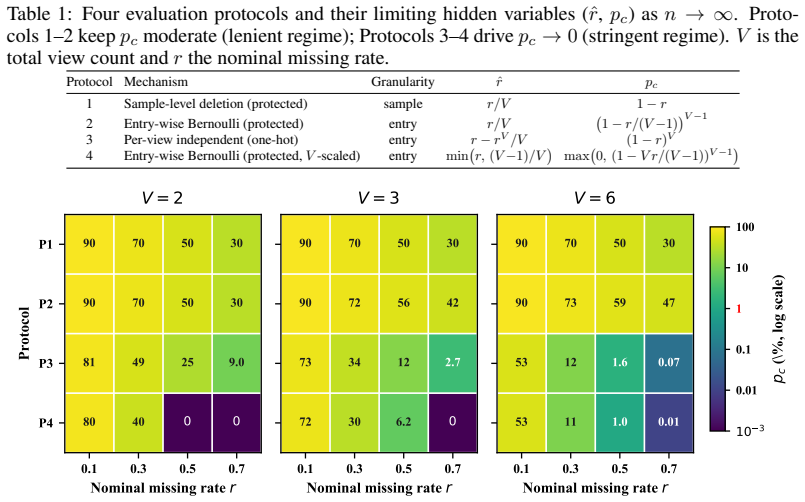
Protocols with the same missing rate can differ 50-fold in complete samples, making reconstruction ill-posed below a threshold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
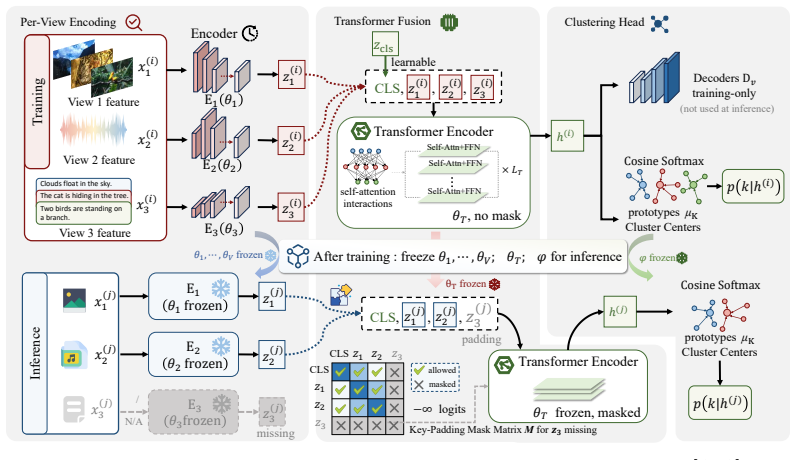
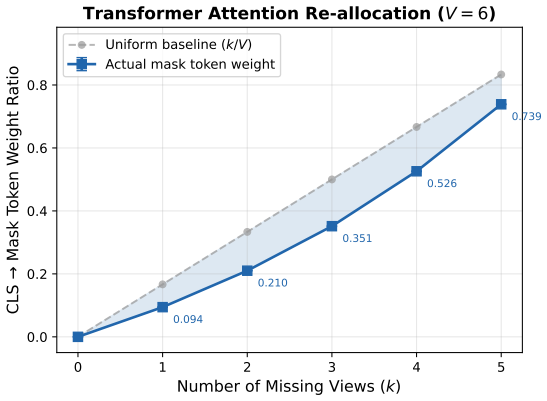
Incompleteness divergence formalizes the structural disparity among missing-data protocols that share the same nominal missing rate. For a broad class of reconstruction objectives, learning is ill-posed when the proportion of complete samples drops below a critical threshold. CRAFT achieves robustness by architectural means: per-sample independence removes reliance on complete-sample co-occurrence, and mask-aware variable-length fusion aggregates only observed views via attention masking, allowing a single model trained on complete data to generalize across patterns without retraining.
What carries the argument
CRAFT (Complete-data Robust Attention-masked Fusion Transformer) whose per-sample independence and mask-aware variable-length fusion shift robustness from the loss to the architecture.
If this is right
- A single model suffices for every missing pattern instead of retraining per configuration.
- Training cost falls by a factor of 8.8 while matching or exceeding per-protocol baselines on seven benchmarks.
- Robustness to missing data can be treated as an architectural property rather than a property of the loss.
- Incompleteness-divergence measures can be used to compare and design missing-data protocols.
Where Pith is reading between the lines
- Evaluation protocols in any missing-data setting should report the proportion of complete samples in addition to the missing rate.
- The same architectural decoupling may extend to other incomplete-data problems such as imputation or semi-supervised learning.
- Train-once models could lower compute demands in large-scale applications that encounter varied missing patterns.
Load-bearing premise
Per-sample independence and mask-aware attention fusion remove enough dependence on complete-sample co-occurrence to bypass the theoretical ill-posedness bound for reconstruction objectives.
What would settle it
Run CRAFT on a protocol whose complete-sample proportion lies below the critical threshold identified in the proof and measure whether test performance collapses to near-random levels.
Figures

read the original abstract
Standard IMVC evaluation retrains separate models for different missing-data configurations. We show that this paradigm obscures a fundamental vulnerability: missing rate alone is insufficient to characterize data incompleteness. Specifically, we show that protocols with identical nominal missing rates can differ by up to $50\times$ in their proportion of fully observed samples, inducing drastically different learning regimes. We formalize this phenomenon as incompleteness divergence, providing measures that capture structural disparities across missing-data protocols. We further prove that for a broad class of reconstruction-based objectives, learning becomes structurally ill-posed when the proportion of complete samples falls below a critical threshold, leading to near-random performance. To bypass this theoretical bound, we propose CRAFT (Complete-data Robust Attention-masked Fusion Transformer). CRAFT shifts the burden of robustness from the loss function to the architecture via two key properties: (i) per-sample independence, which removes reliance on complete-sample co-occurrence, and (ii) mask-aware variable-length fusion, which aggregates only observed views through attention masking. This design allows a single model, trained once on complete data, to generalize to diverse missing patterns at inference time without retraining. Extensive experiments on seven benchmarks show that CRAFT matches or outperforms per-configuration baselines while reducing training overhead by $8.8\times$, demonstrating that robustness to missing data can be achieved as an inherent architectural property. Code (CRAFT) and our imvc-audit toolkit are available at https://anonymous.4open.science/r/CRAFT-BF80/ and https://anonymous.4open.science/r/imvc-audit-8263/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard IMVC evaluation protocols with identical missing rates can differ by up to 50× in the proportion of complete samples, formalizes this as incompleteness divergence, proves that reconstruction-based objectives become structurally ill-posed below a critical complete-sample threshold (leading to near-random performance), and introduces CRAFT, a transformer architecture relying on per-sample independence and mask-aware variable-length fusion that enables a single model trained once on complete data to generalize across missing patterns at inference without retraining, matching per-configuration baselines on seven benchmarks while cutting training cost by 8.8×.
Significance. If the formalization, ill-posedness proof, and architectural bypass hold, the work could shift IMVC practice from per-configuration retraining to a single robust model, substantially lowering computational overhead. The release of CRAFT code and the imvc-audit toolkit strengthens the contribution by supporting direct reproducibility and further protocol audits.
minor comments (2)
- [Abstract] Abstract: the phrase 'we further prove' introduces the ill-posedness result but does not indicate the section or equation containing the critical threshold derivation or the precise definition of the broad class of reconstruction objectives; adding a forward reference would improve readability.
- [Abstract] The 50× and 8.8× quantitative claims are stated without accompanying table or figure citations in the abstract; ensure these are explicitly linked to the relevant experimental results or protocol audit in the main text.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our contributions on incompleteness divergence, the ill-posedness result, and the CRAFT architecture. We appreciate the recommendation for minor revision and the recognition of the reproducibility value of the released code and imvc-audit toolkit.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines incompleteness divergence as a structural measure of complete-sample proportions across protocols, proves an ill-posedness threshold for reconstruction objectives, and introduces CRAFT's architectural properties (per-sample independence and mask-aware fusion) as an independent bypass mechanism. No quoted equations or steps reduce the central claims to fitted inputs, self-citations, or definitional renaming. The derivation remains self-contained against external benchmarks and does not rely on load-bearing self-citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A theory of learning from different domains
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jen- nifer Wortman V aughan. A theory of learning from different domains. Machine Learning , 79(1-2):151–175, 2010. 9
2010
-
[2]
Deep variational incomplete multi-view clustering with information-theoretic guidance
Wenlan Chen, Lu Gao, Cheng Liang, and Fei Guo. Deep variational incomplete multi-view clustering with information-theoretic guidance. In Proceedings of the 33rd ACM International Conference on Multimedia (MM ’25) , pages 2457–2466. ACM, 2025
2025
-
[3]
Exploring simple siamese representation learning
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15750–15758, 2021
2021
-
[4]
Imputation-free and alignment-free: Incomplete multi-view clustering driven by consensus semantic learning
Y uzhuo Dai, Jiaqi Jin, Zhibin Dong, Siwei Wang, Xinwang Liu, En Zhu, Xihong Y ang, Xin- biao Gan, and Y u Feng. Imputation-free and alignment-free: Incomplete multi-view clustering driven by consensus semantic learning. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 5071–5081, 2025
2025
-
[5]
Incomplete multi-view clustering via hi- erarchical semantic alignment and cooperative completion
Xiaojian Ding, Lin Zhao, Xian Li, and Xiaoying Zhu. Incomplete multi-view clustering via hi- erarchical semantic alignment and cooperative completion. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[6]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Y anghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, 2022
2022
-
[7]
Doubly aligned incomplete multi-view clustering
Menglei Hu and Songcan Chen. Doubly aligned incomplete multi-view clustering. In Proceed- ings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI) , pages 2262–2268, 2018
2018
-
[8]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and João Carreira. Perceiver: General perception with iterative attention. arXiv preprint arXiv:2103.03206, 2021
arXiv 2021
-
[9]
Deep incomplete multi-view clustering with distribution dual-consistency recovery guidance
Jiaqi Jin, Siwei Wang, Zhibin Dong, Xihong Y ang, Xinwang Liu, En Zhu, and Kunlun He. Deep incomplete multi-view clustering with distribution dual-consistency recovery guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages 1016–1026, 2025
2025
-
[10]
Set transformer: A framework for attention-based permutation-invariant neural networks
Juho Lee, Y oonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Y ee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. In International Conference on Machine Learning (ICML) , pages 3744–3753, 2019
2019
-
[11]
Incomplete multi-view clustering via prototype-based imputation
Haobin Li, Y unfan Li, Mouxing Y ang, Peng Hu, Dezhong Peng, and Xi Peng. Incomplete multi-view clustering via prototype-based imputation. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI) , pages 3911–3919, 2023
2023
-
[12]
Partial multi-view clustering
Shao-Y uan Li, Y uan Jiang, and Zhi-Hua Zhou. Partial multi-view clustering. In Proceedings of the AAAI Conference on Artificial Intelligence , pages 1968–1974, 2014
1968
-
[13]
COMPLETER: Incomplete multi-view clustering via contrastive prediction
Yijie Lin, Y uanbiao Gou, Zitao Liu, Boyun Li, Jiancheng Lv, and Xi Peng. COMPLETER: Incomplete multi-view clustering via contrastive prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 11174–11183, 2021
2021
-
[14]
Dual con- trastive prediction for incomplete multi-view representation learning
Yijie Lin, Y uanbiao Gou, Xiaotian Liu, Jinfeng Bai, Jiancheng Lv, and Xi Peng. Dual con- trastive prediction for incomplete multi-view representation learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4447–4461, 2023
2023
-
[15]
SparseMVC: Probing cross-view sparsity variations for multi-view clustering
Ruimeng Liu, Xin Zou, Chang Tang, Xiao Zheng, Xingchen Hu, Kun Sun, and Xinwang Liu. SparseMVC: Probing cross-view sparsity variations for multi-view clustering. In The Thirty- ninth Annual Conference on Neural Information Processing Systems (NeurIPS) , 2026. URL https://openreview.net/forum?id=cvJvk6oYfC
2026
-
[16]
Multiple ker- nel k-means with incomplete kernels
Xinwang Liu, Miaomiao Li, Lei Wang, Y ong Dou, Jianping Yin, and En Zhu. Multiple ker- nel k-means with incomplete kernels. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 2259–2265, 2017. 10
2017
-
[17]
Are multimodal transformers robust to missing modality? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18177–18186, 2022
Mengmeng Ma, Jian Ren, Long Zhao, Davide Testuggine, and Xi Peng. Are multimodal transformers robust to missing modality? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18177–18186, 2022
2022
-
[18]
Weixiang Shao, Lifang He, and Philip S. Y u. Multiple incomplete views clustering via weighted nonnegative matrix factorization with l2,1 regularization. In ECML/PKDD, 2015
2015
-
[19]
Deep safe incomplete multi-view clustering: Theorem and algo- rithm
Huayi Tang and Y ong Liu. Deep safe incomplete multi-view clustering: Theorem and algo- rithm. In Proceedings of the 39th International Conference on Machine Learning (ICML) , Proceedings of Machine Learning Research, pages 21090–21110, 2022
2022
-
[20]
Deep safe multi-view clustering: Reducing the risk of clustering performance degradation caused by view increase
Huayi Tang and Y ong Liu. Deep safe multi-view clustering: Reducing the risk of clustering performance degradation caused by view increase. In Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) , pages 202–211, 2022
2022
-
[21]
Attention is all you need
Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Infor- mation Processing Systems (NeurIPS) , pages 6000–6010, 2017
2017
-
[22]
Spectral perturbation meets in- complete multi-view data
Hao Wang, Linlin Zong, Bing Liu, Y an Y ang, and Wei Zhou. Spectral perturbation meets in- complete multi-view data. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI) , pages 3677–3683, 2019
2019
-
[23]
Image quality as- sessment: from error visibility to structural similarity
Qianqian Wang, Zhengming Ding, Zhiqiang Tao, Quanxue Gao, and Y un Fu. Generative partial multi-view clustering with adaptive fusion and cycle consistency. IEEE Transactions on Image Processing, 30:1771–1783, 2021. doi: 10.1109/TIP .2020.3048626
work page doi:10.1109/tip 2021
-
[24]
Energy-based deep incomplete multi-view clustering
Ziyu Wang, Yiming Du, Rui Ning, and Lusi Li. Energy-based deep incomplete multi-view clustering. In Proceedings of the 33rd ACM International Conference on Multimedia (MM ’25) , pages 1686–1694. ACM, 2025
2025
-
[25]
Unified embedding alignment with missing views inferring for incomplete multi-view clustering
Jie Wen, Zheng Zhang, Y ong Xu, Bob Zhang, Lunke Fei, and Hong Liu. Unified embedding alignment with missing views inferring for incomplete multi-view clustering. In Proceedings of the AAAI Conference on Artificial Intelligence , 2019. doi: 10.1609/aaai.v33i01.33015393
-
[26]
CDIMC-net: Cognitive deep incomplete multi-view clustering network
Jie Wen, Zheng Zhang, Y ong Xu, Bob Zhang, Lunke Fei, and Guo-Sen Xie. CDIMC-net: Cognitive deep incomplete multi-view clustering network. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI), pages 3230–3236, 2020. doi: 10.24963/ijcai.2020/447
-
[27]
A survey on incomplete multiview clustering
Jie Wen, Zheng Zhang, Lunke Fei, Bob Zhang, Y ong Xu, Zhao Zhang, and Jinxing Li. A survey on incomplete multiview clustering. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 53(2):1136–1149, 2022
2022
-
[28]
Imputation-free incomplete multi-view clus- tering via knowledge distillation
Benyu Wu, Wei Du, Jun Wang, and Guoxian Y u. Imputation-free incomplete multi-view clus- tering via knowledge distillation. In Proceedings of the Thirty-F ourth International Joint Con- ference on Artificial Intelligence (IJCAI) , pages 6570–6578, 2025
2025
-
[29]
Multi-level feature learning for contrastive multi-view clustering
Jie Xu, Huayi Tang, Y azhou Ren, Liang Peng, Xiaofeng Zhu, and Lifang He. Multi-level feature learning for contrastive multi-view clustering. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) , pages 16030–16039, 2022
2022
-
[30]
Adaptive feature projection with distribution alignment for deep incomplete multi-view clustering
Jie Xu, Chao Li, Liang Peng, Y azhou Ren, Xiaoshuang Shi, Heng Tao Shen, and Xiaofeng Zhu. Adaptive feature projection with distribution alignment for deep incomplete multi-view clustering. IEEE Transactions on Image Processing, 32:1354–1366, 2023
2023
-
[31]
Partially view-aligned representation learning with noise-robust contrastive loss
Mouxing Y ang, Y unfan Li, Zhenyu Huang, Zitao Liu, Peng Hu, and Xi Peng. Partially view-aligned representation learning with noise-robust contrastive loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1134– 1143, 2021
2021
-
[32]
Robust multi- view clustering with incomplete information
Mouxing Y ang, Y unfan Li, Peng Hu, Jinfeng Bai, Jiancheng Lv, and Xi Peng. Robust multi- view clustering with incomplete information. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):1055–1069, 2023. doi: 10.1109/TPAMI.2022.3155499. 11
-
[33]
Deep sets
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabás Póczos, Russ R Salakhutdinov, and Alexander J Smola. Deep sets. In Advances in Neural Information Processing Systems (NeurIPS), pages 3391–3401, 2017
2017
-
[34]
Incomplete multi-view clustering via diffusion contrastive gen- eration
Y uanyang Zhang, Yijie Lin, Weiqing Y an, Li Y ao, Xinhang Wan, Guangyuan Li, Chao Zhang, Guanzhou Ke, and Jie Xu. Incomplete multi-view clustering via diffusion contrastive gen- eration. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 39, pages 22650–22658, 2025
2025
-
[35]
Incomplete multi-modal visual data grouping
Handong Zhao, Hongfu Liu, and Y un Fu. Incomplete multi-modal visual data grouping. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJ- CAI), pages 2392–2398, 2016. NeurIPS Paper Checklist
2016
-
[36]
Guidelines: • The answer [N/A] means that the abstract and introduction do not include the claims made in the paper
Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Y es] Justification: The abstract and Section 1 outline the contributions: formalizing incomplete- ness divergence ( ˆr, pc), proving the Frec trainability bound (Theorem 4.2), the CRAFT architecture, and empirical valid...
-
[37]
Limitations
Limitations Question: Does the paper discuss the limitations of the work performed by the authors? Answer: [Y es] Justification: The Conclusion (Section 7) explicitly notes that CRAFT addresses only the cross-view reconstruction loss family in unsupervised IMVC and points to supervised or distributional multi-view extensions as future work. Guidelines: • T...
-
[38]
Guidelines: • The answer [N/A] means that the paper does not include theoretical results
Theory assumptions and proofs Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof? Answer: [Y es] Justification: Theorem 4.1, Proposition 4.1, Theorem 4.2, and Corollary 4.1 are stated with explicit assumptions in Section 4; full proofs appear in Appendix B. Guidelines: • The answer [...
-
[39]
Guidelines: • The answer [N/A] means that the paper does not include experiments
Experimental result reproducibility Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclu- sions of the paper (regardless of whether the code and data are provided or not)? Answer: [Y es] Justification: Architecture details are i...
-
[40]
All seven benchmarks (CUB, MultiFashion, HandWritten, UCI- Digit, Out-Scene, Caltech, YTF-31) are publicly available
Open access to data and code Question: Does the paper provide open access to the data and code, with sufficient instruc- tions to faithfully reproduce the main experimental results, as described in supplemental material? Answer: [Y es] Justification: Two anonymous links are provided in the supplementary material: the CRAFT implementation ( https://anonymous...
-
[41]
Guidelines: 14 • The answer [N/A] means that the paper does not include experiments
Experimental setting/details Question: Does the paper specify all the training and test details (e.g., data splits, hyperpa- rameters, how they were chosen, type of optimizer) necessary to understand the results? Answer: [Y es] Justification: Section 6.1 describes the baselines, protocol grid, and metrics; Appendix A.2 provides per-dataset hyperparameters ...
-
[42]
YTF-31 is single-seed due to dataset scale ( n ≈ 100k); this is explicitly stated in Appendix A.1
Experiment statistical significance Question: Does the paper report error bars suitably and correctly defined or other appropri- ate information about the statistical significance of the experiments? Answer: [Y es] Justification: All main-text experiments report 5-seed mean ± standard deviation (seeds 42–46). YTF-31 is single-seed due to dataset scale ( n ≈ 1...
-
[43]
Guidelines: • The answer [N/A] means that the paper does not include experiments
Experiments compute resources Question: For each experiment, does the paper provide sufficient information on the com- puter resources (type of compute workers, memory, time of execution) needed to reproduce the experiments? Answer: [Y es] Justification: Appendix A.1 specifies the hardware (single NVIDIA RTX 3090, 24GB VRAM, PyTorch 2.1, CUDA 12.1); per-run ...
-
[44]
The work does not involve human subjects, scraped data, or privacy-sensitive material
Code of ethics Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines? 15 Answer: [Y es] Justification: This research adheres to the NeurIPS Code of Ethics. The work does not involve human subjects, scraped data, or privacy-sensitive material. Guidelines: • Th...
-
[45]
Guidelines: • The answer [N/A] means that there is no societal impact of the work performed
Broader impacts Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed? Answer: [N/A] Justification: Multi-view clustering is foundational unsupervised learning research with no easily predictable direct path to negative societal impacts. Guidelines: • The answer [N/A] means that there ...
-
[46]
Guidelines: • The answer [N/A] means that the paper poses no such risks
Safeguards Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pre-trained language models, image generators, or scraped datasets)? Answer: [N/A] Justification: This work does not release high-risk models or datasets requiring safeguards; CRAFT is a clust...
-
[47]
Licenses for existing assets Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected? Answer: [Y es] Justification: All seven benchmarks are publicly available datasets standard in the IMVC literature. CUB and Ha...
-
[48]
Guidelines: • The answer [N/A] means that the paper does not release new assets
New assets Question: Are new assets introduced in the paper well documented and is the documenta- tion provided alongside the assets? Answer: [Y es] Justification: The anonymous supplementary material includes two repositories: (1) the CRAFT implementation, and (2) the imvc-audit standalone evaluation toolkit (Python package with closed-form ˆr and pc form...
-
[49]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Crowdsourcing and research with human subjects Question: For crowdsourcing experiments and research with human subjects, does the pa- per include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)? 17 Answer: [N/A] Justification: This paper does not involve crowdsourcing or res...
-
[50]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
-
[51]
DVIMC’s reference implementation does not generalize to het- erogeneous multi-view data with high view counts
Declaration of LLM usage Question: Does the paper describe the usage of LLMs if it is an important, original, or non-standard component of the core methods in this research? Note that if the LLM is used only for writing, editing, or formatting purposes and does not impact the core methodology, scientific rigor, or originality of the research, declaration i...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.