Learning What Not to Impute: An Uncertainty-Aware Diffusion Framework for Meaningful Missingness
Pith reviewed 2026-06-28 07:13 UTC · model grok-4.3
The pith
A diffusion model jointly learns which missing tabular entries are meaningfully absent versus those needing imputation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
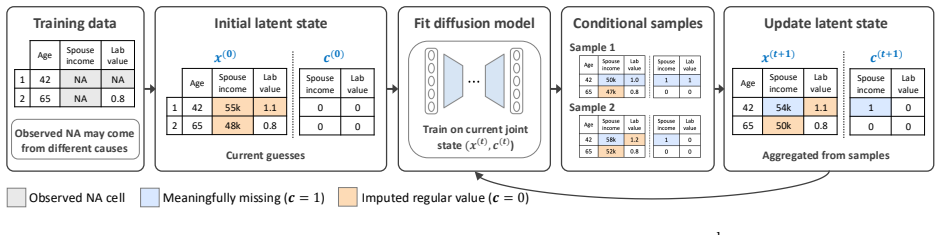
By embedding a latent missingness mask inside a diffusion model of tabular data and alternating conditional sampling with uncertainty-aware aggregation, the framework can jointly infer both the values to impute and the entries that should remain missing because they are semantically absent.
What carries the argument
Latent missingness mask inside the diffusion process, which is refined iteratively by conditional sampling and uncertainty-aware aggregation to separate meaningful absences from imputable entries.
If this is right
- The learned mask identifies which missing entries carry semantic information without requiring explicit supervision on the mask.
- Imputation accuracy on the entries that should be filled remains competitive with methods that impute everything.
- Downstream supervised tasks improve because the data preserves informative absences instead of filling them with noise.
- The same joint modeling works on both synthetic and real-world tabular datasets.
Where Pith is reading between the lines
- The same separation principle could be tested on sequential or graph-structured data where missingness also carries meaning.
- If the mask is reliable, it could be used to audit data-collection processes and flag which absences are informative rather than accidental.
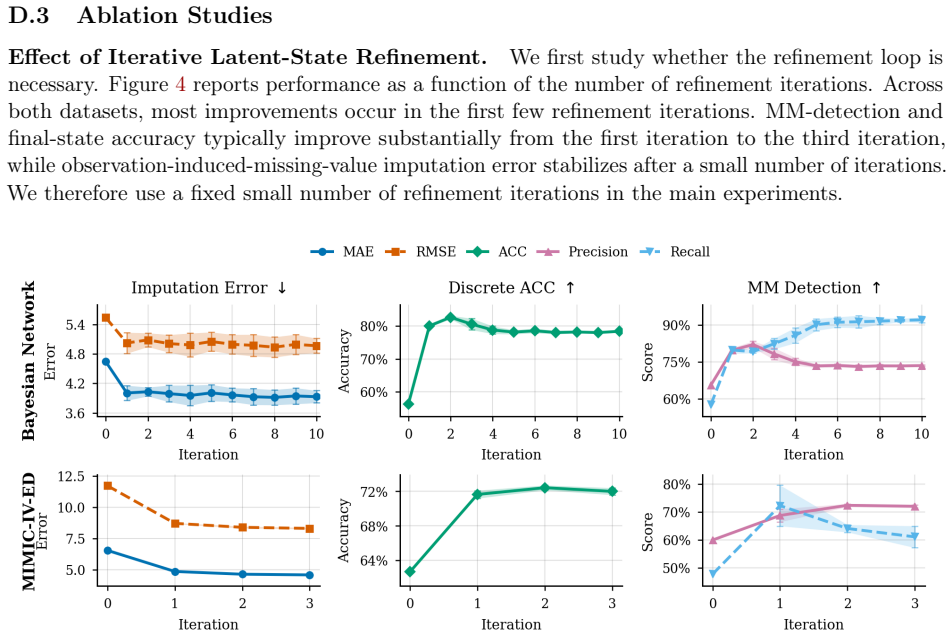
- Removing the uncertainty-aware aggregation step would provide a direct test of whether that component is necessary for stable mask recovery.
Load-bearing premise
Missing entries fall into two distinct, learnable categories that can be modeled jointly through a single latent mask in a diffusion process on tabular data.
What would settle it
On synthetic tabular data where the ground-truth partition between meaningful and imputable missing entries is known, the method fails to recover the correct mask or shows no gain in downstream task accuracy relative to a standard diffusion imputer that imputes every missing cell.
Figures

read the original abstract
Missing value imputation is a fundamental task in machine learning, with most existing methods assuming that all missing entries correspond to unobserved regular values. In many real-world datasets, however, missingness may arise from two distinct sources: some entries are meaningfully missing (intrinsically absent and semantically valid), while others are missing due to the observation process and should be imputed. We formalize this distinction as a selective imputation problem, where the goal is to jointly infer which missing entries should be preserved and which should be recovered. To address this challenge, we propose Diff-Joint, a diffusion-based framework that jointly models tabular data together with a latent missingness mask. The method alternates between conditional sampling and uncertainty-aware aggregation to iteratively refine both imputed values and missingness labels. Empirical results on synthetic and real-world datasets demonstrate that Diff-Joint effectively identifies meaningfully missing entries while achieving competitive imputation accuracy and improved downstream task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes selective imputation as the joint task of identifying meaningfully missing entries (intrinsically absent and semantically valid) versus entries that should be imputed. It proposes Diff-Joint, a diffusion model that jointly generates tabular data and a latent missingness mask, alternating between conditional sampling and uncertainty-aware aggregation to refine both values and labels. Experiments on synthetic and real-world datasets are reported to show that the method identifies meaningful missingness, achieves competitive imputation accuracy, and yields improved downstream task performance.
Significance. If the results hold, the work provides a principled probabilistic treatment of a realistic missing-data scenario that standard imputation methods ignore. The joint diffusion-plus-latent-mask construction is a direct and reasonable operationalization of the selective-imputation distinction, and the empirical tests on both synthetic and real data constitute direct falsifiable checks of whether the two categories separate usefully. No machine-checked proofs or parameter-free derivations are claimed, but the iterative sampling procedure is presented as the core technical contribution.
minor comments (2)
- [Abstract] Abstract: the claim of 'improved downstream task performance' is stated without naming the tasks or datasets; a single sentence listing the concrete benchmarks would make the empirical contribution easier to assess at a glance.
- The description of the uncertainty-aware aggregation step would benefit from an explicit equation or short algorithm box showing how the mask probabilities are updated from the diffusion samples.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work and for recommending minor revision. The report contains no major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity detected
full rationale
The paper introduces Diff-Joint as a diffusion framework that jointly models tabular data and a latent missingness mask, alternating conditional sampling with uncertainty-aware aggregation. The abstract and described method present this as an operational construction for selective imputation without any claimed derivation that reduces outputs to inputs by construction, fitted parameters renamed as predictions, or load-bearing self-citations. Empirical results on synthetic and real data are framed as direct tests rather than tautological consequences of the model definition. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A gentle introduction to imputation of missing values.Journal of clinical epidemiology, 59(10):1087–1091, 2006
A Rogier T Donders, Geert JMG Van Der Heijden, Theo Stijnen, and Karel GM Moons. A gentle introduction to imputation of missing values.Journal of clinical epidemiology, 59(10):1087–1091, 2006
2006
-
[2]
A survey on missing data in machine learning.Journal of Big data, 8(1):140, 2021
Tlamelo Emmanuel, Thabiso Maupong, Dimane Mpoeleng, Thabo Semong, Banyatsang Mphago, and Oteng Tabona. A survey on missing data in machine learning.Journal of Big data, 8(1):140, 2021
2021
-
[3]
Dempster, Nan M
Arthur P. Dempster, Nan M. Laird, and Donald B. Rubin. Maximum likelihood from incomplete data via the EM algorithm.Journal of the Royal Statistical Society: Series B (Methodological), 39(1):1–22, 1977
1977
-
[4]
An overview of multiple imputation
Donald B Rubin. An overview of multiple imputation. InProceedings of the survey research methods section of the American statistical association, volume 79, page 84, 1988
1988
-
[5]
mice: Multivariate imputation by chained equations in r.Journal of Statistical Software, 45(3):1–67, 2011
Stef van Buuren and Karin Groothuis-Oudshoorn. mice: Multivariate imputation by chained equations in r.Journal of Statistical Software, 45(3):1–67, 2011
2011
-
[6]
Stekhoven and Peter Bühlmann
Daniel J. Stekhoven and Peter Bühlmann. MissForest—non-parametric missing value imputation for mixed-type data.Bioinformatics, 28(1):112–118, 2012
2012
-
[7]
Gain: Missing data imputation using generative adversarial nets
Jinsung Yoon, James Jordon, and Mihaela Schaar. Gain: Missing data imputation using generative adversarial nets. InInternational conference on machine learning, pages 5689–5698. PMLR, 2018
2018
-
[8]
MIWAE: Deep generative modelling and imputation of incomplete data sets
Pierre-Alexandre Mattei and Jes Frellsen. MIWAE: Deep generative modelling and imputation of incomplete data sets. InInternational conference on machine learning, pages 4413–4423. PMLR, 2019
2019
-
[9]
Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural information processing systems, 34:24804–24816, 2021
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural information processing systems, 34:24804–24816, 2021
2021
-
[10]
Diffusion models for missing value imputation in tabular data
Shuhan Zheng and Nontawat Charoenphakdee. Diffusion models for missing value imputation in tabular data. InNeurIPS 2022 First Table Representation Learning Workshop, 2022
2022
-
[11]
Inference and missing data.Biometrika, 63(3):581–592, 1976
Donald B Rubin. Inference and missing data.Biometrika, 63(3):581–592, 1976
1976
-
[12]
Learning to Diagnose with LSTM Recurrent Neural Networks
Zachary C Lipton, David C Kale, Charles Elkan, and Randall Wetzel. Learning to diagnose with lstm recurrent neural networks.arXiv preprint arXiv:1511.03677, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Missing data.The SAGE handbook of quantitative methods in psychology, 23:72–89, 2009
Paul D Allison. Missing data.The SAGE handbook of quantitative methods in psychology, 23:72–89, 2009
2009
-
[14]
Collaborative filtering for implicit feedback datasets
Yifan Hu, Yehuda Koren, and Chris Volinsky. Collaborative filtering for implicit feedback datasets. In2008 Eighth IEEE international conference on data mining, pages 263–272. IEEE, 2008. 12
2008
-
[15]
BPR: Bayesian Personalized Ranking from Implicit Feedback
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. BPR: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[16]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[17]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
2021
-
[18]
Hengrui Zhang, Liancheng Fang, Qitian Wu, and Philip S. Yu. DiffPuter: Empowering diffusion models for missing data imputation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[19]
John Wiley & Sons, 2019
Roderick JA Little and Donald B Rubin.Statistical analysis with missing data. John Wiley & Sons, 2019
2019
-
[20]
HyperImpute: Generalized iterative imputation with automatic model selection
Daniel Jarrett, Bogdan Cebere, Tennison Liu, Alicia Curth, and Mihaela van der Schaar. HyperImpute: Generalized iterative imputation with automatic model selection. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 9916–9937. PMLR, 2022
2022
-
[21]
Remasker: Imputing tabular data with masked autoencoding
Tianyu Du, Luca Melis, and Ting Wang. Remasker: Imputing tabular data with masked autoencoding. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[22]
CACTI: Leveraging copy masking and contextual information to improve tabular data imputation
Aditya Gorla, Ryan Wang, Zhengtong Liu, Ulzee An, and Sriram Sankararaman. CACTI: Leveraging copy masking and contextual information to improve tabular data imputation. InProceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 20187–20225, 2025
2025
-
[23]
Yidong Ouyang, Liyan Xie, Chongxuan Li, and Guang Cheng. Missdiff: Training diffusion models on tabular data with missing values.arXiv preprint arXiv:2307.00467, 2023
-
[24]
Namjoon Suh, Yuning Yang, Din-Yin Hsieh, Qitong Luan, Shirong Xu, Shixiang Zhu, and Guang Cheng. Timeautodiff: A unified framework for generation, imputation, forecasting, and time-varying metadata conditioning of heterogeneous time series tabular data.Transactions on Machine Learning Research, 2025
2025
-
[25]
Generating and imputing tabular data via diffusion and flow-based gradient-boosted trees
Alexia Jolicoeur-Martineau, Kilian Fatras, and Tal Kachman. Generating and imputing tabular data via diffusion and flow-based gradient-boosted trees. InInternational conference on artificial intelligence and statistics, pages 1288–1296. PMLR, 2024
2024
-
[26]
García-Laencina, José-Luis Sancho-Gómez, and Aníbal R
Pedro J. García-Laencina, José-Luis Sancho-Gómez, and Aníbal R. Figueiras-Vidal. Pattern classification with missing data: a review.Neural Computing and Applications, 19:263–282, 2010
2010
-
[27]
Recurrent neural networks for multivariate time series with missing values.Scientific reports, 8(1):6085, 2018
Zhengping Che, Sanjay Purushotham, Kyunghyun Cho, David Sontag, and Yan Liu. Recurrent neural networks for multivariate time series with missing values.Scientific reports, 8(1):6085, 2018
2018
-
[28]
Preserving missing data distribution in synthetic data
Xinyue Wang, Hafiz Asif, and Jaideep Vaidya. Preserving missing data distribution in synthetic data. InProceedings of the ACM Web Conference 2023, pages 2110–2121, 2023. 13
2023
-
[29]
Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(4), 2005
Aapo Hyvärinen and Peter Dayan. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(4), 2005
2005
-
[30]
A connection between score matching and denoising autoencoders.Neural computation, 23(7):1661–1674, 2011
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural computation, 23(7):1661–1674, 2011
2011
-
[31]
Sliced score matching: A scalable approach to density and score estimation
Yang Song, Sahaj Garg, Jiaxin Shi, and Stefano Ermon. Sliced score matching: A scalable approach to density and score estimation. InUncertainty in artificial intelligence, pages 574–584. PMLR, 2020
2020
-
[32]
Mimic-iv-ed.PhysioNet, 2021
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Leo Anthony Celi, Roger Mark, and S Horng IV. Mimic-iv-ed.PhysioNet, 2021
2021
-
[33]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565– 26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565– 26577, 2022
2022
-
[34]
TabDDPM: Modelling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. TabDDPM: Modelling tabular data with diffusion models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Res...
2023
-
[35]
Schork, Kenneth Kendler, Päivi Pajukanta, Jonathan Flint, Noah Zaitlen, Na Cai, Andy Dahl, and Sriram Sankararaman
Ulzee An, Ali Pazokitoroudi, Marcus Alvarez, Lianyun Huang, Silviu Bacanu, Andrew J. Schork, Kenneth Kendler, Päivi Pajukanta, Jonathan Flint, Noah Zaitlen, Na Cai, Andy Dahl, and Sriram Sankararaman. Deep learning-based phenotype imputation on population-scale biobank data increases genetic discoveries.Nature Genetics, 55:2269–2276, 2023
2023
-
[36]
MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. InAdvances in Neural Information Processing Systems, 2020. A Algorithm Details We provide the detailed algorithms for theModel–Updatestep (Algorithm 2),Conditional– Samplestep (Algorithm 3...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.