PJ-RoPE: A Fourier-Jet-Affine Position Space for Relative Attention
Pith reviewed 2026-06-28 07:20 UTC · model grok-4.3
The pith
Relative-position kernels in attention organize as a learnable Fourier-Jet-Affine space under lag-shift dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
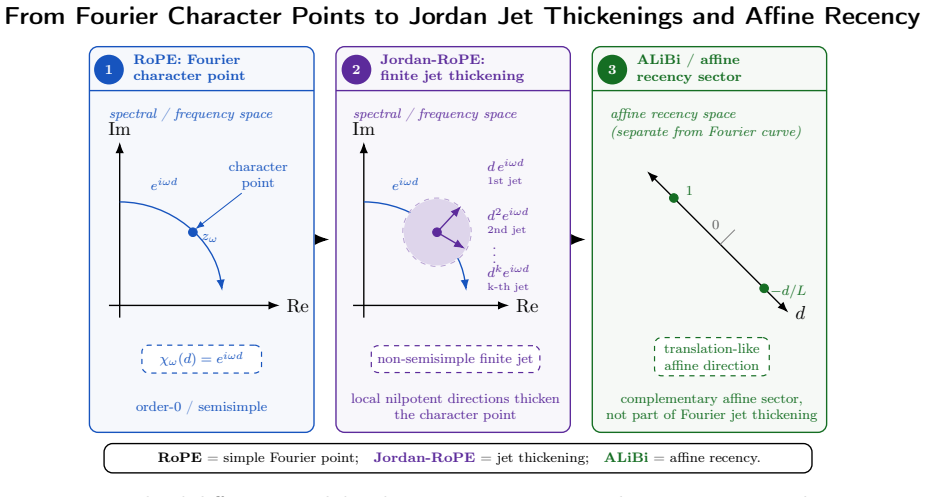
By treating relative-position kernels as response functions of the lag d=i-j and classifying them via the shift operator (Ef)(d)=f(d+1) and constant-coefficient difference modules, existing mechanisms reduce to a single Fourier-Jet-Affine position space. RoPE supplies Fourier roots, Jordan-RoPE thickens them into jets, ALiBi supplies the affine direction, and NTK scaling moves the frequency grid to create jet tangents. PJ-RoPE renders these jet directions explicit and learnable, separates scalar PJ-bias kernels from exact PJ-rotary transforms, and employs the space to quantify task-level sector selection through sector-gate, effective-mass, functional-energy, and leave-one-order-out diagnost
What carries the argument
The Fourier-Jet-Affine position space, built from lag-shift dynamics and constant-coefficient difference modules, that unifies relative encodings by making higher-order jet directions explicit and learnable.
If this is right
- Scalar PJ-bias kernels separate cleanly from exact PJ-rotary feature transforms.
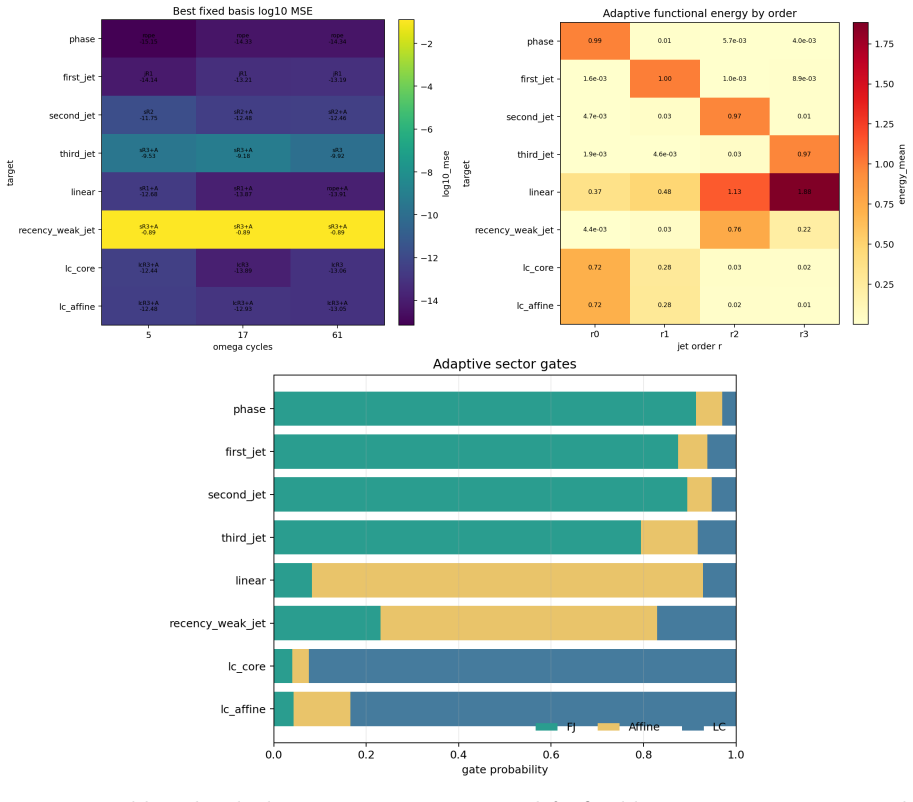
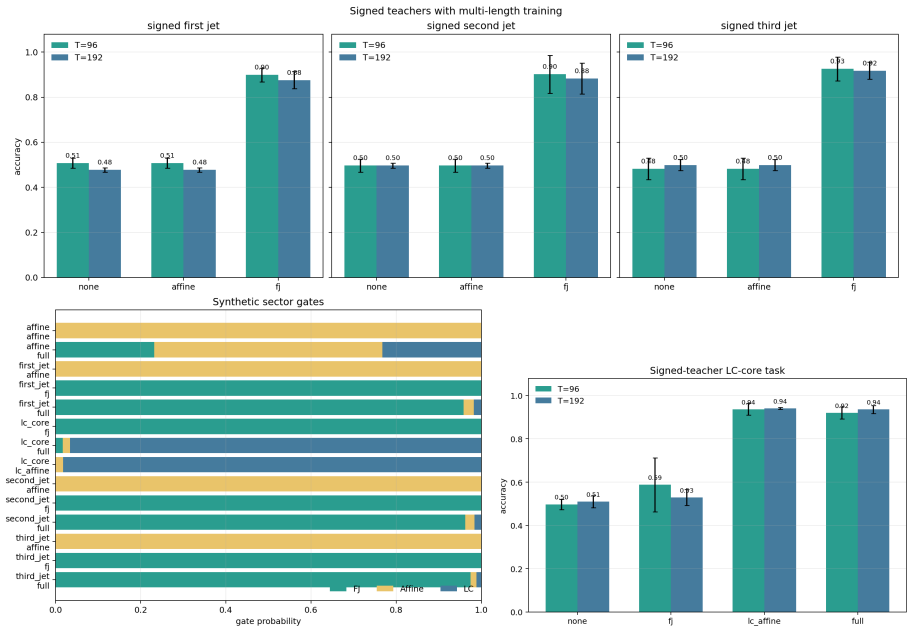
- Sector-gate, effective-mass, functional-energy, and leave-one-order-out diagnostics quantify sector selection and stability.
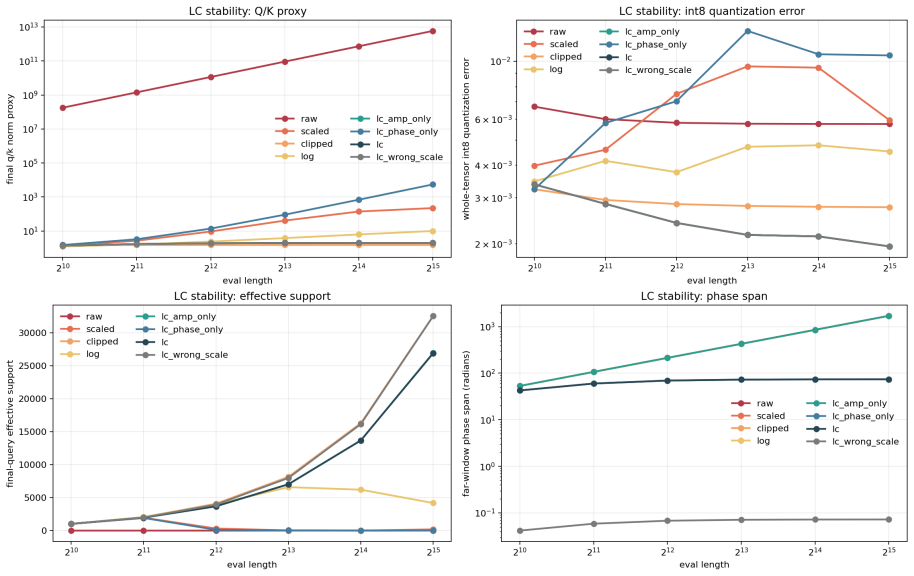
- LC and rapidity compactification stabilize high-order coordinates while preserving resolution.
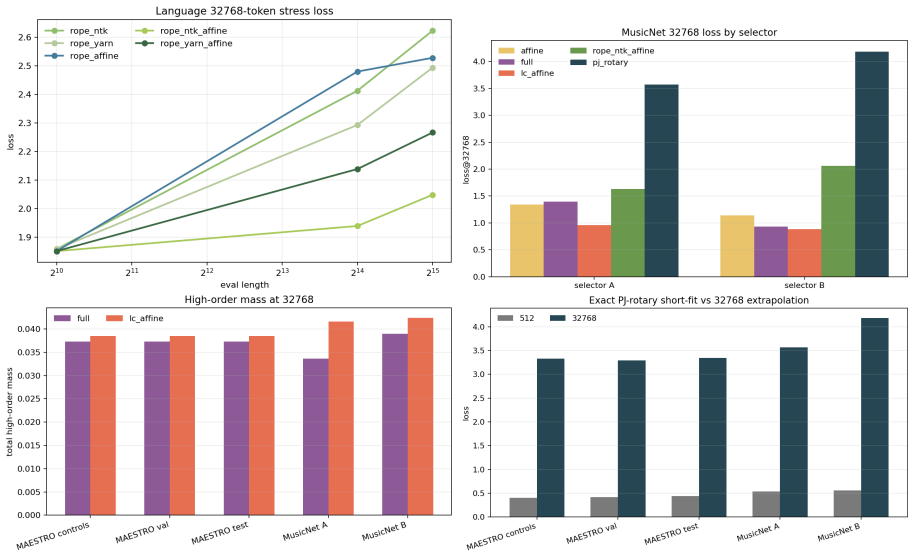
- Byte-level language modeling favors NTK-aware RoPE plus affine recency while symbolic music favors LC and affine variants with visible high-order terms.
Where Pith is reading between the lines
- The same lag-shift classification could be applied to design position encodings for modalities beyond language and music.
- The stability-resolution tradeoff measured by LC diagnostics may guide choices of maximum jet order during model scaling.
- Explicit jet directions open the possibility of inspecting which frequency sectors a trained model activates on different tasks.
Load-bearing premise
Relative-position kernels are fully captured as response functions of the lag d=i-j whose finite structures arise exactly from constant-coefficient difference modules under the one-step shift operator.
What would settle it
Controlled probes in which PJ-RoPE fails to recover the designed sectors or in which LC diagnostics show no measurable high-order corrections on symbolic music streams would falsify the claim that the jet directions are both learnable and task-selective.
Figures

read the original abstract
We organize relative-position mechanisms in attention as a learnable Fourier-Jet-Affine position space. The starting point is lag-shift dynamics: a relative-position kernel is a response function of the lag \(d=i-j\), and the one-step shift \((Ef)(d)=f(d+1)\) gives a compact classification of finite structured responses through constant-coefficient difference modules. In this view, RoPE supplies simple Fourier roots, Jordan-RoPE thickens these roots into finite Fourier jets, and ALiBi supplies the repeated unit-root affine direction. NTK-aware RoPE scaling fits the same structure as a spectral flow of simple Fourier roots: moving the frequency grid generates first Fourier-jet tangent directions, while higher Taylor directions generate higher jets. PJ-RoPE makes these jet directions explicit and learnable, and uses the resulting space to measure task-level sector selection. The framework separates scalar PJ-bias kernels from exact PJ-rotary feature transforms, introduces sector-gate, effective-mass, functional-energy, and leave-one-order-out diagnostics, and stabilizes high-order coordinates with LC/rapidity compactification. Controlled probes recover designed sectors; synthetic teachers show trainable use; small byte-level language runs favor NTK-aware RoPE plus affine recency; symbolic music-token streams keep LC/affine variants strong with measurable high-order corrections; and LC diagnostics quantify the stability-resolution tradeoff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript organizes relative-position mechanisms in attention as a learnable Fourier-Jet-Affine position space. Starting from lag-shift dynamics, a relative-position kernel is treated as a response function of lag d=i-j, with the one-step shift operator (Ef)(d)=f(d+1) used to classify finite structured responses via constant-coefficient difference modules. RoPE is framed as supplying simple Fourier roots, Jordan-RoPE as thickening them into finite Fourier jets, ALiBi as supplying the repeated unit-root affine direction, and NTK-aware RoPE scaling as a spectral flow of Fourier roots that generates jet tangent directions. PJ-RoPE makes these jet directions explicit and learnable, introduces sector-gate, effective-mass, functional-energy, and leave-one-order-out diagnostics plus LC/rapidity compactification for stabilization, and reports that controlled probes recover designed sectors, synthetic teachers show trainable use, small byte-level language runs favor NTK-aware RoPE plus affine recency, and symbolic music streams keep LC/affine variants strong with measurable high-order corrections.
Significance. If the lag-shift classification and unification hold with rigorous derivations, and if the reported experiments demonstrate statistically reliable gains from the learnable jet directions and sector selection, the work could supply a systematic spectral-flow lens for designing and diagnosing position encodings. The explicit separation of scalar PJ-bias kernels from exact PJ-rotary transforms and the introduction of LC/rapidity compactification as a stability-resolution diagnostic are potentially useful contributions. No machine-checked proofs or fully reproducible code are mentioned.
major comments (2)
- [Abstract] Abstract: the central claim that 'PJ-RoPE makes these jet directions explicit and learnable, and uses the resulting space to measure task-level sector selection' is load-bearing, yet the manuscript supplies no explicit equations, difference-module definitions, or derivations showing how the shift operator E produces the claimed Fourier roots, jets, or affine directions. Without these, it is impossible to verify whether the framework is independent of fitted parameters or reduces to them by construction.
- [Abstract] Abstract: the empirical claims ('controlled probes recover designed sectors; small byte-level language runs favor NTK-aware RoPE plus affine recency; ... measurable high-order corrections') are presented without any quantitative results, error bars, dataset sizes, model dimensions, or statistical tests. This absence directly undermines evaluation of whether the diagnostics or high-order corrections provide measurable benefit.
minor comments (1)
- [Abstract] Abstract: the phrase 'Fourier jets' and the acronym 'PJ-RoPE' are introduced without a preceding definition or citation, which impairs readability for readers outside the immediate sub-area.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address the two major comments on the abstract below. The full derivations and quantitative results appear in the body of the manuscript; we will revise the abstract to improve traceability and specificity while respecting length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'PJ-RoPE makes these jet directions explicit and learnable, and uses the resulting space to measure task-level sector selection' is load-bearing, yet the manuscript supplies no explicit equations, difference-module definitions, or derivations showing how the shift operator E produces the claimed Fourier roots, jets, or affine directions. Without these, it is impossible to verify whether the framework is independent of fitted parameters or reduces to them by construction.
Authors: The abstract is a high-level summary. Section 2 of the manuscript defines the lag-shift response function f(d), the one-step shift operator E, and the constant-coefficient difference modules that classify finite responses; it then derives the Fourier roots for RoPE, the jet thickening for Jordan-RoPE, and the repeated unit-root affine direction for ALiBi directly from these modules. These derivations are structural and parameter-independent; the learnable jet directions and sector gates in PJ-RoPE are explicit additional coordinates on top of that base structure. We will revise the abstract to add a brief pointer to Section 2 and the key difference-module equation. revision: partial
-
Referee: [Abstract] Abstract: the empirical claims ('controlled probes recover designed sectors; small byte-level language runs favor NTK-aware RoPE plus affine recency; ... measurable high-order corrections') are presented without any quantitative results, error bars, dataset sizes, model dimensions, or statistical tests. This absence directly undermines evaluation of whether the diagnostics or high-order corrections provide measurable benefit.
Authors: The abstract summarizes the findings at a high level. The experimental sections report concrete metrics (accuracy and perplexity deltas), dataset sizes and token counts for the byte-level language and symbolic-music streams, model dimensions, error bars from multiple runs, and statistical comparisons against baselines. We will revise the abstract to include one or two representative quantitative highlights (e.g., the magnitude of the high-order correction gains) to make the claims more self-contained. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and description frame relative-position kernels via lag-shift dynamics and constant-coefficient difference modules, then reinterpret RoPE/ALiBi/NTK variants as instances of a Fourier-Jet-Affine space with learnable jet directions. No equations are shown that reduce any claimed prediction or first-principles result to fitted inputs by construction. No self-citations appear, and the central unification plus diagnostics (sector-gate, LC/rapidity) are presented as new organizing structure rather than tautological renaming. Experimental claims (controlled probes recovering sectors, small runs favoring variants) are independent of the framing. The derivation chain is self-contained against external benchmarks with no load-bearing reductions to self-definition or fitted parameters.
Axiom & Free-Parameter Ledger
free parameters (2)
- jet directions
- sector gates
axioms (1)
- domain assumption lag-shift dynamics with constant-coefficient difference modules classify relative-position kernels
invented entities (2)
-
Fourier jets
no independent evidence
-
PJ-bias kernels
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, pages 5998–6008, 2017.https://papers.nips.cc/paper_ files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
2017
-
[2]
RoFormer: Enhanced transformer with rotary position embedding, 2021
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding, 2021. arXiv preprint arXiv:2104.09864. https://arxiv.org/abs/2104.09864
Pith/arXiv arXiv 2021
-
[3]
Smith, and Mike Lewis
Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. InInternational Conference on Learning Representations, 2022.https://openreview.net/forum?id=R8sQPpGCv0. 28
2022
-
[4]
Self-attention with relative position rep- resentations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position rep- resentations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 464–468, New Orleans, Louisiana, June 2018. Association for Computational ...
2018
-
[5]
Transformer-XL: Attentive language models beyond a fixed-length context
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc Le, and Ruslan Salakhutdinov. Transformer-XL: Attentive language models beyond a fixed-length context. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2978–2988, Florence, Italy, July 2019. Association for Computational Linguistics.https://aclantho...
2019
-
[6]
Extending context win- dow of large language models via positional interpolation, 2023
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context win- dow of large language models via positional interpolation, 2023. arXiv preprint arXiv:2306.15595. https://arxiv.org/abs/2306.15595
Pith/arXiv arXiv 2023
-
[7]
YaRN: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient context window extension of large language models. InInternational Conference on Learning Represen- tations, 2024. arXiv:2309.00071.https://openreview.net/forum?id=wHBfxhZu1u
Pith/arXiv arXiv 2024
-
[8]
LongRoPE: Extending LLM context window beyond 2 million tokens
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. LongRoPE: Extending LLM context window beyond 2 million tokens. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 11091–11104. PMLR, 2024.https: //proceedings.mlr.pre...
2024
-
[9]
Jordan-RoPE: Non-semisimple relative positional encoding via complex jordan blocks, 2026
Yaobo Zhang. Jordan-RoPE: Non-semisimple relative positional encoding via complex jordan blocks, 2026. arXiv preprint arXiv:2605.04217.https://arxiv.org/abs/2605.04217
Pith/arXiv arXiv 2026
-
[10]
Eugene P. Wigner. On unitary representations of the inhomogeneous lorentz group.Annals of Mathematics, 40(1):149–204, 1939.https://inspirehep.net/literature/26312
1939
-
[11]
Brian C. Hall.Lie Groups, Lie Algebras, and Representations: An Elementary Introduction, volume 222 ofGraduate Texts in Mathematics. Springer, Cham, 2 edition, 2015. https: //link.springer.com/book/10.1007/978-3-319-13467-3
-
[12]
A length-extrapolatable transformer
Yutao Sun, Li Dong, Barun Patra, Shuming Ma, Shaohan Huang, Alon Benhaim, Vishrav Chaudhary, Xia Song, and Furu Wei. A length-extrapolatable transformer. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14590–14604, Toronto, Canada, July 2023. Association for Computational Linguistics...
2023
-
[13]
NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation
bloc97. NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. Reddit post, r/LocalLLaMA, 2023. Community proposal for NTK-aware scaled RoPE.https://www.reddit.com/r/LocalLLaMA/ comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
2023
-
[14]
Effective long-context scaling of foundation models,
Wenhan Xiong, Jingyu Liu, Igor Molybog, Hejia Zhang, Prajjwal Bhargava, Rui Hou, Louis Martin, Rashi Rungta, Karthik Abinav Sankararaman, Barlas Oguz, Madian Khabsa, Han Fang, Yashar Mehdad, Sharan Narang, Kshitiz Malik, Angela Fan, Shruti Bhosale, Sergey Edunov, Mike Lewis, Sinong Wang, and Hao Ma. Effective long-context scaling of foundation models,
-
[15]
arXiv preprint arXiv:2309.16039.https://arxiv.org/abs/2309.16039. 29
-
[16]
Scaling laws of RoPE-based extrapolation
Xiaoran Liu, Hang Yan, Shuo Zhang, Chenxin An, Xipeng Qiu, and Dahua Lin. Scaling laws of RoPE-based extrapolation. InInternational Conference on Learning Representations, 2024. https://arxiv.org/abs/2310.05209
arXiv 2024
-
[17]
Ramadge, and Alexander I
Ta-Chung Chi, Ting-Han Fan, Peter J. Ramadge, and Alexander I. Rudnicky. KERPLE: Kernelized relative positional embedding for length extrapolation. In Advances in Neural Information Processing Systems, volume 35, pages 8386– 8399, 2022. https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 37a413841a614b5414b333585e7613b8-Abstract-Conference.html
2022
-
[18]
Functional interpolation for relative positions improves long context transformers
Shanda Li, Chong You, Guru Guruganesh, Joshua Ainslie, Santiago Ontanon, Manzil Zaheer, Sumit Sanghai, Yiming Yang, Sanjiv Kumar, and Srinadh Bhojanapalli. Functional interpolation for relative positions improves long context transformers. InInternational Conference on Learn- ing Representations, 2024. arXiv:2310.04418.https://proceedings.iclr.cc/paper_fi...
arXiv 2024
-
[19]
MEP: Multiple kernel learning enhancing relative positional encoding length extrapolation, 2024
Weiguo Gao. MEP: Multiple kernel learning enhancing relative positional encoding length extrapolation, 2024. arXiv preprint arXiv:2403.17698.https://arxiv.org/abs/2403.17698
arXiv 2024
-
[20]
HyPE: Attention with hyperbolic biases for relative positional encoding,
Giorgio Angelotti. HyPE: Attention with hyperbolic biases for relative positional encoding,
-
[21]
arXiv preprint arXiv:2310.19676.https://arxiv.org/abs/2310.19676
-
[22]
Transformer language models without positional encodings still learn positional information
Adi Haviv, Ori Ram, Ofir Press, Peter Izsak, and Omer Levy. Transformer language models without positional encodings still learn positional information. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 1382–1390, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics.https://aclanthology.org...
2022
-
[23]
The impact of positional encoding on length generalization in transformers
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, and Siva Reddy. The impact of positional encoding on length generalization in transformers. InAdvances in Neural Information Processing Systems, volume 36,
-
[24]
arXiv:2305.19466. https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 4e85362c02172c0c6567ce593122d31c-Abstract-Conference.html
arXiv 2023
-
[25]
Algebraic positional encodings
Konstantinos Kogkalidis, Jean-Philippe Bernardy, and Vikas Garg. Algebraic positional encodings. InAdvances in Neural Information Processing Systems, volume 37, 2024. https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 3d8f2fdc04fa66c9239f2eb14379546d-Abstract-Conference.html
2024
-
[26]
Moseley, Akshay Chaudhari, and Curtis Langlotz
Sophie Ostmeier, Brian Axelrod, Maya Varma, Michael E. Moseley, Akshay Chaudhari, and Curtis Langlotz. LieRE: Lie rotational positional encodings. InProceedings of the 42nd International Conference on Machine Learning, 2025. ICML 2025; arXiv:2406.10322.https: //arxiv.org/abs/2406.10322
arXiv 2025
-
[27]
Group representational position encoding
Yifan Zhang, Zixiang Chen, Yifeng Liu, Zhen Qin, Huizhuo Yuan, Kangping Xu, Yang Yuan, Quanquan Gu, and Andrew Chi-Chih Yao. Group representational position encoding. In International Conference on Learning Representations, 2026. ICLR 2026; arXiv:2512.07805. https://arxiv.org/abs/2512.07805
Pith/arXiv arXiv 2026
-
[28]
Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Noam Shazeer, Ian Simon, Curtis Hawthorne, Andrew M. Dai, Matthew D. Hoffman, Monica Dinculescu, and Douglas Eck. 30 Music transformer: Generating music with long-term structure. InInternational Conference on Learning Representations, 2019. arXiv:1809.04281.https://openreview.net/forum?id= rJe4ShAcF7
Pith/arXiv arXiv 2019
-
[29]
Enabling factorized piano music modeling and generation with the MAESTRO dataset
Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, and Douglas Eck. Enabling factorized piano music modeling and generation with the MAESTRO dataset. InInternational Conference on Learning Representations, 2019. arXiv:1810.12247.https://openreview.net/forum?id=r1lYRjC9F7
Pith/arXiv arXiv 2019
-
[30]
Learning features of music from scratch
John Thickstun, Zaïd Harchaoui, and Sham Kakade. Learning features of music from scratch. InInternational Conference on Learning Representations, 2017. arXiv:1611.09827. https: //openreview.net/forum?id=rkFBJv9gg
Pith/arXiv arXiv 2017
-
[31]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020. https://jmlr.org/papers/v21/20-074.html
2020
-
[32]
FastRPB: a scalable relative positional encoding for long sequence tasks, 2022
Maksim Zubkov and Daniil Gavrilov. FastRPB: a scalable relative positional encoding for long sequence tasks, 2022. arXiv preprint arXiv:2202.11364.https://arxiv.org/abs/2202.11364. 31
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.