Learned Subspace Compression for Communication-Efficient Pipeline Parallelism
Pith reviewed 2026-06-28 06:39 UTC · model grok-4.3
The pith
MAPL learns per-stage orthogonal projections on the Stiefel manifold to compress activations in pipeline parallelism with negligible performance loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
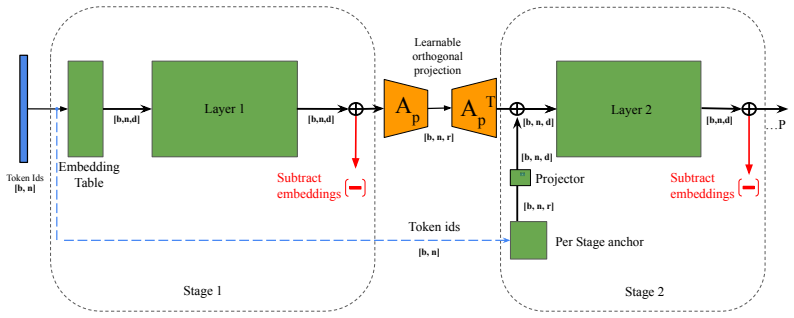
MAPL treats inter-stage compression as a learnable orthogonal projection under explicit Stiefel manifold constraints. Rather than prescribing a fixed global subspace, MAPL lets each pipeline stage discover and continuously adapt its own task-optimal compression subspace via manifold-constrained steepest descent. To recover token-specific signals at stage boundaries, it introduces per-stage factorized anchor embeddings that allow for full-rank activation reconstruction with negligible communication overhead. Residual vector quantization can be incorporated after projection with a streaming codebook synchronization protocol that amortizes dictionary communication.
What carries the argument
Manifold Aware Projection Learning (MAPL) performing manifold-constrained steepest descent on per-stage Stiefel manifolds to learn adaptive orthogonal compression subspaces, paired with factorized anchor embeddings for reconstruction.
If this is right
- High activation compression becomes possible in pipeline-parallel LLM training while keeping performance degradation negligible.
- Each stage can continuously adapt its compression subspace to the task rather than relying on a single fixed projection.
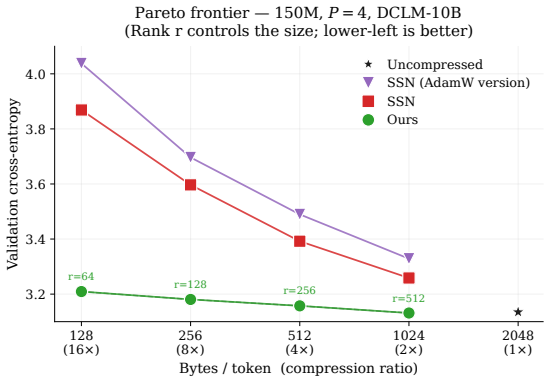
- The performance-compression tradeoff improves substantially over Subspace Networks across LLaMA models from 150M to 1B parameters.
- The method integrates directly into existing pipeline parallelism code without requiring global subspace prescriptions.
Where Pith is reading between the lines
- The per-stage adaptation might reduce the hardware requirement for high-bandwidth interconnects when scaling to clusters with heterogeneous links.
- Anchor embeddings could be extended to other boundary compression settings such as model parallelism or federated averaging.
- Testing whether the same manifold optimization remains stable on models larger than 1B parameters would clarify the method's scaling limits.
Load-bearing premise
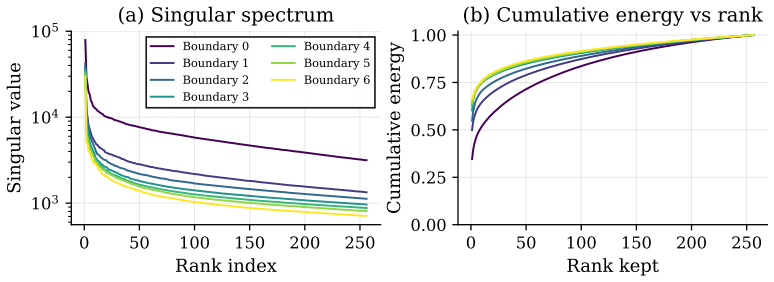
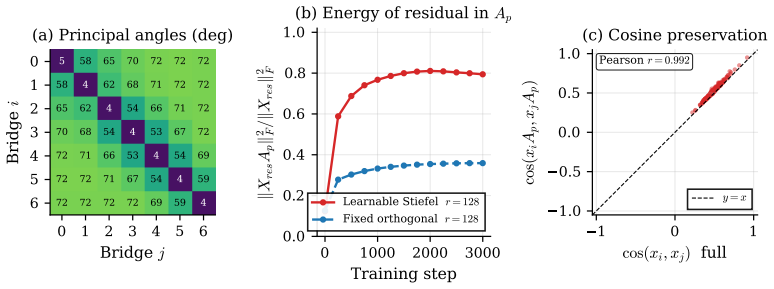
That manifold-constrained steepest descent on per-stage Stiefel manifolds can be performed stably during end-to-end training without non-standard adaptations and that the resulting subspaces remain task-optimal throughout optimization.
What would settle it
Running end-to-end training of an LLaMA-scale model under MAPL and observing either large accuracy degradation relative to uncompressed baselines or optimization divergence that fixed-projection methods avoid.
Figures
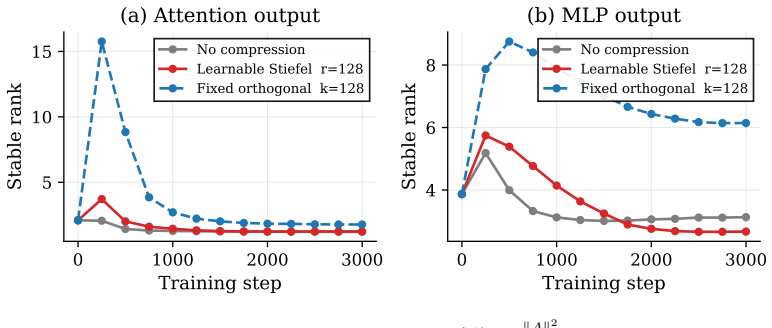
read the original abstract
Pipeline parallelism enables training of large language models that exceed single-device memory, yet inter-stage activation communication becomes the dominant bottleneck when trained on low-bandwidth networks. Recent work in this area has proposed using fixed orthogonal projections to compress activations. However, this still results in a significant performance degradation and requires a number of non-standard adaptations to constrain the optimization. A natural alternative is to learn a low rank projection for each pipeline stage, however maintaining the necessary orthogonality of these projectors during training remains a challenge. We present Manifold Aware Projection Learning (MAPL), a method that treats inter-stage compression as a learnable orthogonal projection under explicit Stiefel manifold (orthogonal matrices) constraints. Rather than prescribing a fixed global subspace, MAPL lets each pipeline stage discover and continuously adapt its own task-optimal compression subspace via manifold-constrained steepest descent. To recover token-specific signals at stage boundaries, we introduce per-stage factorized anchor embeddings that allow for full-rank activation reconstruction with negligible communication overhead. We further show that we can incorporate residual vector quantization after projection with a streaming codebook synchronization protocol that amortizes dictionary communication. Across LLaMA models from 150M to 1B parameters we show that MAPL can be easily applied to the existing pipeline and can achieve high compression with neglibile performance degradation with a drastically improved tradeoffs in performance vs. compression compared to Subspace Networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Manifold Aware Projection Learning (MAPL) enables communication-efficient pipeline parallelism by learning per-stage orthogonal projections on Stiefel manifolds using manifold-constrained steepest descent, along with factorized anchor embeddings and residual vector quantization. It reports that this achieves high compression with negligible performance degradation on LLaMA models from 150M to 1B parameters, with better tradeoffs than Subspace Networks.
Significance. If the central optimization procedure is stable and the empirical claims are supported by data, the work could advance efficient training of large models by reducing inter-stage communication in pipeline parallelism through adaptive, learned subspaces rather than fixed projections.
major comments (2)
- [Method] Method section: The description of MAPL relies on performing manifold-constrained steepest descent on per-stage Stiefel manifolds during end-to-end training, but no specifics are given on the retraction, step-size rule, or orthogonality enforcement mechanism. This is critical because the abstract contrasts it with fixed projections that require non-standard adaptations, yet without these details the stability claim cannot be assessed.
- [Experiments] Experiments section: The abstract states empirical gains across LLaMA models but the provided text supplies no quantitative tables, error bars, ablation details on the manifold optimization stability, or training curves, which are necessary to support the claim of negligible degradation and improved tradeoffs.
minor comments (2)
- [Abstract] Typo: 'neglibile' should be 'negligible'.
- [Abstract] The phrase 'drastically improved tradeoffs in performance vs. compression' is grammatically awkward; consider rephrasing for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested details and evidence.
read point-by-point responses
-
Referee: [Method] Method section: The description of MAPL relies on performing manifold-constrained steepest descent on per-stage Stiefel manifolds during end-to-end training, but no specifics are given on the retraction, step-size rule, or orthogonality enforcement mechanism. This is critical because the abstract contrasts it with fixed projections that require non-standard adaptations, yet without these details the stability claim cannot be assessed.
Authors: We agree that the Method section requires additional implementation specifics for reproducibility and stability assessment. In the revised manuscript we will expand this section to detail the retraction operator (polar decomposition), the step-size rule (manifold-adapted Armijo line search), and orthogonality enforcement (via the Stiefel manifold parameterization within the optimizer). These additions will also clarify how the approach avoids the non-standard adaptations needed for fixed projections. revision: yes
-
Referee: [Experiments] Experiments section: The abstract states empirical gains across LLaMA models but the provided text supplies no quantitative tables, error bars, ablation details on the manifold optimization stability, or training curves, which are necessary to support the claim of negligible degradation and improved tradeoffs.
Authors: We acknowledge the absence of these elements in the current text. In the revision we will incorporate quantitative tables reporting compression ratios versus performance metrics (with standard error bars from multiple runs), ablation studies on manifold optimization stability, and training curves demonstrating convergence behavior and negligible degradation. These will be added to the Experiments section to directly support the claimed tradeoffs versus Subspace Networks. revision: yes
Circularity Check
No significant circularity; method is an optimization procedure with external empirical claims
full rationale
The paper presents MAPL as a manifold-constrained steepest descent procedure on Stiefel manifolds for per-stage projectors, combined with anchor embeddings and residual quantization. No equations, derivations, or self-citations are supplied that reduce the reported compression gains or performance claims to quantities fitted inside the same experiment by construction. The central results are empirical tradeoffs on LLaMA models (150M-1B), which are independent of any internal redefinition or self-referential prediction. This is the most common honest non-finding for a methods paper describing an optimization technique.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qsgd: Communication-efficient sgd via gradient quantization and encoding.Advances in neural information processing systems, 30, 2017
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan V ojnovic. Qsgd: Communication-efficient sgd via gradient quantization and encoding.Advances in neural information processing systems, 30, 2017
2017
-
[2]
The polar express: Optimal matrix sign methods and their application to the muon algorithm.International Conference on Learning Representations (ICLR), 2026
Noah Amsel, David Persson, Christopher Musco, and Robert M Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm.International Conference on Learning Representations (ICLR), 2026
2026
-
[3]
signsgd: Compressed optimisation for non-convex problems
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. signsgd: Compressed optimisation for non-convex problems. InInternational conference on machine learning, pages 560–569. PMLR, 2018
2018
-
[4]
Does compressing activations help model parallel training?Proceedings of Machine Learning and Systems, 6:239–252, 2024
Song Bian, Dacheng Li, Hongyi Wang, Eric P Xing, and Shivaram Venkataraman. Does compressing activations help model parallel training?Proceedings of Machine Learning and Systems, 6:239–252, 2024
2024
-
[5]
Piqa: Reasoning about phys- ical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about phys- ical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
2020
-
[6]
Actnn: Reducing training memory footprint via 2-bit activation compressed training
Jianfei Chen, Lianmin Zheng, Zhewei Yao, Dequan Wang, Ion Stoica, Michael Mahoney, and Joseph Gonzalez. Actnn: Reducing training memory footprint via 2-bit activation compressed training. InInternational Conference on Machine Learning, pages 1803–1813. PMLR, 2021
2021
-
[7]
Fira: Can we achieve full-rank training of LLMs under low-rank constraint? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
Xi Chen, Kaituo Feng, Changsheng Li, Xunhao Lai, Xiangyu Yue, Ye Yuan, and Guoren Wang. Fira: Can we achieve full-rank training of LLMs under low-rank constraint? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[8]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
8-bit optimizers via block-wise quantization
Tim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. 8-bit optimizers via block-wise quantization. InInternational Conference on Learning Representations, 2022
2022
-
[10]
Distributed deep learning in open collaborations.Advances in Neural Information Processing Systems, 34:7879–7897, 2021
Michael Diskin, Alexey Bukhtiyarov, Max Ryabinin, Lucile Saulnier, Anton Sinitsin, Dmitry Popov, Dmitry V Pyrkin, Maxim Kashirin, Alexander Borzunov, Albert Villanova del Moral, et al. Distributed deep learning in open collaborations.Advances in Neural Information Processing Systems, 34:7879–7897, 2021. 10
2021
-
[11]
Streaming diloco with overlapping communication
Arthur Douillard, Yani Donchev, J Keith Rush, Satyen Kale, Zachary Charles, Gabriel Teston, Zachary Garrett, Jiajun Shen, Ross McIlroy, David Lacey, Alexandre Rame, Arthur Szlam, MarcAurelio Ranzato, and Paul R Barham. Streaming diloco with overlapping communication. InSecond Conference on Language Modeling, 2025
2025
-
[12]
Arthur Douillard, Qixuang Feng, Andrei A. Rusu, Rachita Chhaparia, Yani Donchev, Adhiguna Kuncoro, Marc’Aurelio Ranzato, Arthur Szlam, and Jiajun Shen. Diloco: Distributed low- communication training of language models.CoRR, abs/2311.08105, 2023
-
[13]
The lottery ticket hypothesis: Finding sparse, trainable neural networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. InInternational Conference on Learning Representations, 2019
2019
-
[14]
Sgd with weight decay secretly minimizes the ranks of your neural networks
Tomer Galanti, Zachary S Siegel, Aparna Gupte, and Tomaso A Poggio. Sgd with weight decay secretly minimizes the ranks of your neural networks. InThe Second Conference on Parsimony and Learning (Proceedings Track), 2025
2025
-
[15]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[16]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, Hy- oukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
2019
-
[18]
Minyoung Huh, Brian Cheung, Jeremy Bernstein, Phillip Isola, and Pulkit Agrawal. Training neural networks from scratch with parallel low-rank adapters.arXiv preprint arXiv:2402.16828, 2024
-
[19]
Opendiloco: An open-source frame- work for globally distributed low-communication training, July 2024
Sami Jaghouar, Jack Min Ong, and Johannes Hagemann. Opendiloco: An open-source frame- work for globally distributed low-communication training, July 2024
2024
-
[20]
Stabilizing native low-rank LLM pretraining
Paul Janson, Edouard Oyallon, and Eugene Belilovsky. Stabilizing native low-rank LLM pretraining. InForty-third International Conference on Machine Learning, 2026
2026
-
[21]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024
2024
-
[22]
Error feedback fixes signsgd and other gradient compression schemes
Sai Praneeth Karimireddy, Quentin Rebjock, Sebastian Stich, and Martin Jaggi. Error feedback fixes signsgd and other gradient compression schemes. InInternational conference on machine learning, pages 3252–3261. PMLR, 2019
2019
-
[23]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations (ICLR), 2015
2015
-
[24]
A unified theory of decentralized sgd with changing topology and local updates
Anastasia Koloskova, Nicolas Loizou, Sadra Boreiri, Martin Jaggi, and Sebastian Stich. A unified theory of decentralized sgd with changing topology and local updates. InInternational conference on machine learning, pages 5381–5393. PMLR, 2020
2020
-
[25]
Decentralized stochastic optimization and gossip algorithms with compressed communication
Anastasia Koloskova, Sebastian Stich, and Martin Jaggi. Decentralized stochastic optimization and gossip algorithms with compressed communication. InInternational conference on machine learning, pages 3478–3487. PMLR, 2019
2019
-
[26]
Albert: A lite bert for self-supervised learning of language representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. In International Conference on Learning Representations, 2020. 11
2020
-
[27]
Optimal brain damage.Advances in neural information processing systems, 2, 1989
Yann LeCun, John Denker, and Sara Solla. Optimal brain damage.Advances in neural information processing systems, 2, 1989
1989
-
[28]
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Kumar Guha, Sedrick Scott Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee F. Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, D...
2024
-
[29]
ReloRA: High-rank training through low-rank updates
Vladislav Lialin, Sherin Muckatira, Namrata Shivagunde, and Anna Rumshisky. ReloRA: High-rank training through low-rank updates. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[30]
Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, Wei Zhang, and Ji Liu. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent.Advances in neural information processing systems, 30, 2017
2017
-
[31]
Joel Lidin, Amir Sarfi, Erfan Miahi, Quentin Anthony, Shivam Chauhan, Evangelos Pappas, Benjamin Thérien, Eugene Belilovsky, and Samuel Dare. Covenant-72b: Pre-training a 72b llm with trustless peers over-the-internet.arXiv preprint arXiv:2603.08163, 2026
-
[32]
Deep gradient compression: Reducing the communication bandwidth for distributed training
Yujun Lin, Song Han, Huizi Mao, Yu Wang, and Bill Dally. Deep gradient compression: Reducing the communication bandwidth for distributed training. InInternational Conference on Learning Representations, 2018
2018
-
[33]
Muon is scalable for llm training, February 2025
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is sca...
2025
-
[34]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
2019
-
[35]
Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165):1–73, 2021
Charles H Martin and Michael W Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165):1–73, 2021
2021
-
[36]
Parameter and memory efficient pretraining via low-rank riemannian optimization
Zhanfeng Mo, Long-Kai Huang, and Sinno Jialin Pan. Parameter and memory efficient pretraining via low-rank riemannian optimization. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[37]
Adel Nabli, Louis Fournier, Pierre Erbacher, Louis Serrano, Eugene Belilovsky, and Edouard Oyallon. Acco: Accumulate while you communicate for communication-overlapped sharded llm training.arXiv preprint arXiv:2406.02613, 2024
-
[38]
Acco: Accumulate while you communicate for communication-overlapped sharded llm training
Adel Nabli, Louis Fournier, Pierre Erbacher, Louis Serrano, Eugene Belilovsky, and Edouard Oyallon. Acco: Accumulate while you communicate for communication-overlapped sharded llm training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 12
2025
-
[39]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[40]
Decoupled momentum optimization
Bowen Peng, Jeffrey Quesnelle, and Diederik P Kingma. Decoupled momentum optimization. arXiv preprint arXiv:2411.19870, 2024
-
[41]
Zero: Memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimiza- tions toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[42]
Subspace networks: Scaling decentralized training with communication-efficient model par- allelism
Sameera Ramasinghe, Thalaiyasingam Ajanthan, Gil Avraham, Yan Zuo, and Alexander Long. Subspace networks: Scaling decentralized training with communication-efficient model par- allelism. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[43]
PETRA: Parallel end-to-end training with reversible architectures
Stephane Rivaud, Louis Fournier, Thomas Pumir, Eugene Belilovsky, Michael Eickenberg, and Edouard Oyallon. PETRA: Parallel end-to-end training with reversible architectures. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[44]
Swarm parallelism: Training large models can be surprisingly communication-efficient
Max Ryabinin, Tim Dettmers, Michael Diskin, and Alexander Borzunov. Swarm parallelism: Training large models can be surprisingly communication-efficient. InInternational Conference on Machine Learning, pages 29416–29440. PMLR, 2023
2023
-
[45]
Towards crowdsourced training of large neural networks using decentralized mixture-of-experts.Advances in Neural Information Processing Systems, 33:3659–3672, 2020
Max Ryabinin and Anton Gusev. Towards crowdsourced training of large neural networks using decentralized mixture-of-experts.Advances in Neural Information Processing Systems, 33:3659–3672, 2020
2020
-
[46]
Communication efficient llm pre-training with sparseloco.arXiv preprint arXiv:2508.15706, 2025
Amir Sarfi, Benjamin Thérien, Joel Lidin, and Eugene Belilovsky. Communication efficient llm pre-training with sparseloco.arXiv preprint arXiv:2508.15706, 2025
-
[47]
Local sgd converges fast and communicates little
Sebastian U Stich. Local sgd converges fast and communicates little. InInternational Conference on Learning Representations, 2019
2019
-
[48]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[49]
1-bit adam: Communication efficient large-scale training with adam’s convergence speed
Hanlin Tang, Shaoduo Gan, Ammar Ahmad Awan, Samyam Rajbhandari, Conglong Li, Xiangru Lian, Ji Liu, Ce Zhang, and Yuxiong He. 1-bit adam: Communication efficient large-scale training with adam’s convergence speed. InInternational Conference on Machine Learning, pages 10118–10129. PMLR, 2021
2021
-
[50]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Powersgd: Practical low-rank gradient compression for distributed optimization
Thijs V ogels, Sai Praneeth Karimireddy, and Martin Jaggi. Powersgd: Practical low-rank gradient compression for distributed optimization. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors,Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Proc...
2019
-
[53]
Powersgd: Practical low-rank gradient compression for distributed optimization.Advances in Neural Information Processing Systems, 32, 2019
Thijs V ogels, Sai Praneeth Karimireddy, and Martin Jaggi. Powersgd: Practical low-rank gradient compression for distributed optimization.Advances in Neural Information Processing Systems, 32, 2019. 13
2019
-
[54]
Pufferfish: Communication- efficient models at no extra cost.Proceedings of Machine Learning and Systems, 3:365–386, 2021
Hongyi Wang, Saurabh Agarwal, and Dimitris Papailiopoulos. Pufferfish: Communication- efficient models at no extra cost.Proceedings of Machine Learning and Systems, 3:365–386, 2021
2021
-
[55]
Efficient distributed learning with sparsity
Jialei Wang, Mladen Kolar, Nathan Srebro, and Tong Zhang. Efficient distributed learning with sparsity. InInternational conference on machine learning, pages 3636–3645. PMLR, 2017
2017
-
[56]
Cocktailsgd: Fine-tuning foundation models over 500mbps networks
Jue Wang, Yucheng Lu, Binhang Yuan, Beidi Chen, Percy Liang, Christopher De Sa, Christopher Re, and Ce Zhang. Cocktailsgd: Fine-tuning foundation models over 500mbps networks. In International Conference on Machine Learning, pages 36058–36076. PMLR, 2023
2023
-
[57]
Fine-tuning language models over slow networks using activation quantization with guarantees.Advances in Neural Information Processing Systems, 35:19215–19230, 2022
Jue Wang, Binhang Yuan, Luka Rimanic, Yongjun He, Tri Dao, Beidi Chen, Christopher Ré, and Ce Zhang. Fine-tuning language models over slow networks using activation quantization with guarantees.Advances in Neural Information Processing Systems, 35:19215–19230, 2022
2022
-
[58]
Gradient sparsification for communication-efficient distributed optimization.Advances in Neural Information Processing Systems, 31, 2018
Jianqiao Wangni, Jialei Wang, Ji Liu, and Tong Zhang. Gradient sparsification for communication-efficient distributed optimization.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[59]
Building on efficient foundations: Effective training of llms with structured feedforward layers
Xiuying Wei, Skander Moalla, Razvan Pascanu, and Caglar Gulcehre. Building on efficient foundations: Effective training of llms with structured feedforward layers. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 4689–4717. Curran Associates, I...
2024
-
[60]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s transform- ers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[61]
Error compensated quantized sgd and its applications to large-scale distributed optimization
Jiaxiang Wu, Weidong Huang, Junzhou Huang, and Tong Zhang. Error compensated quantized sgd and its applications to large-scale distributed optimization. InInternational conference on machine learning, pages 5325–5333. PMLR, 2018
2018
-
[62]
arXiv preprint arXiv:2310.17813 , year=
Greg Yang, James B Simon, and Jeremy Bernstein. A spectral condition for feature learning. arXiv preprint arXiv:2310.17813, 2023
-
[63]
Manifold constrained steepest descent.arXiv preprint arXiv:2601.21487, 2026
Kaiwei Yang and Lexiao Lai. Manifold constrained steepest descent.arXiv preprint arXiv:2601.21487, 2026
-
[64]
On compressing deep models by low rank and sparse decomposition
Xiyu Yu, Tongliang Liu, Xinchao Wang, and Dacheng Tao. On compressing deep models by low rank and sparse decomposition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7370–7379, 2017
2017
-
[65]
Visualizing and understanding convolutional networks
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In European conference on computer vision, pages 818–833. Springer, 2014
2014
-
[66]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
2019
-
[67]
Codebook transfer with part-of-speech for vector-quantized image modeling
Baoquan Zhang, Huaibin Wang, Chuyao Luo, Xutao Li, Guotao Liang, Yunming Ye, Xiaochen Qi, and Yao He. Codebook transfer with part-of-speech for vector-quantized image modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7757–7766, 2024
2024
-
[68]
LR scale
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. Galore: Memory-efficient llm training by gradient low-rank projection, 2024. 14 A Background: Subspace networks SSN [42] exploits a structural property of trained Transformers: the output projection weights W ℓ 2 ∈R dff ×d and attention projection weights W ℓ 1 ∈R ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.