TS-ICL: A Flexible Time-Indexed Foundation Model for Time Series via In-Context Learning
Pith reviewed 2026-06-28 02:18 UTC · model grok-4.3
The pith
TS-ICL unifies forecasting and imputation for irregularly observed time series in one in-context learning model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
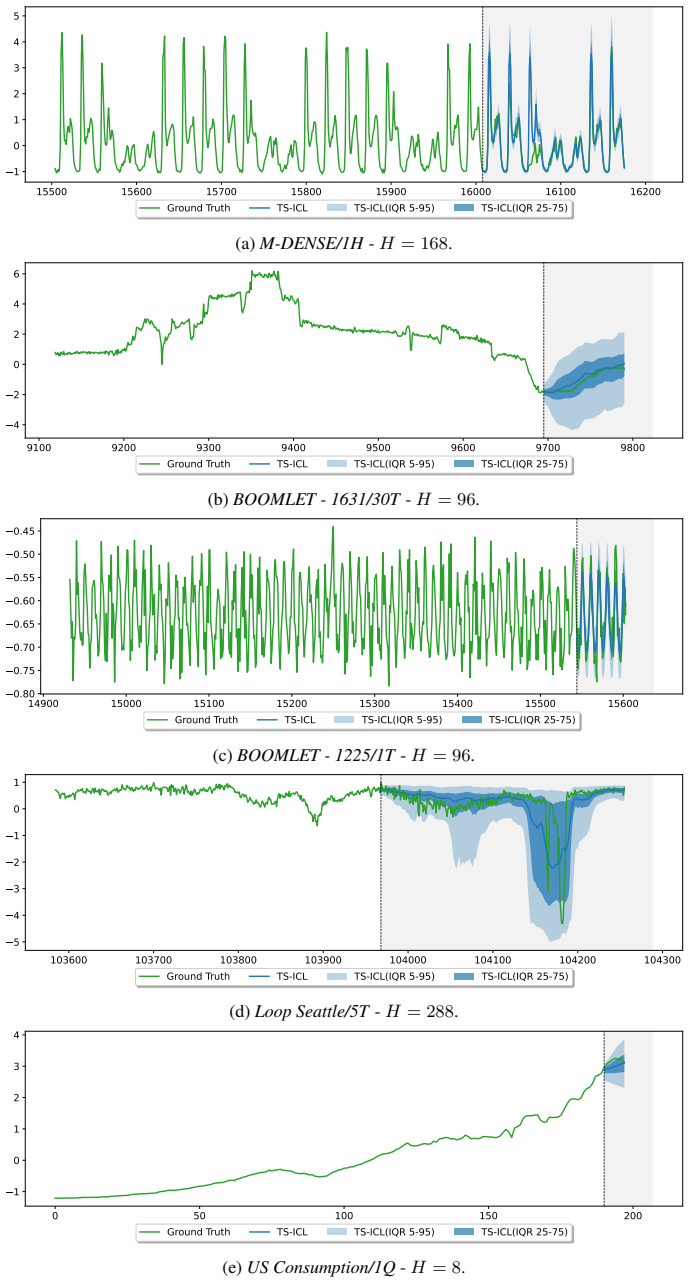
TS-ICL is a probabilistic In-Context Learning encoder-regressor Transformer that unifies forecasting and imputation. It formulates time series tasks as timestamp-aligned regression and naturally incorporates covariates by training on synthetic dependency structures generated from a novel causal data prior. Empirically, TS-ICL achieves a new state-of-the-art in imputation, while remaining competitive with leading forecasting foundation models across both univariate and covariate-aware benchmarks. It shows particularly strong performance in forecasting with partially observed look-back windows.
What carries the argument
The timestamp-aligned regression formulation inside the probabilistic ICL encoder-regressor Transformer, which lets the model process irregular timestamps and covariates via training on synthetic causal structures.
Load-bearing premise
That training on synthetic dependency structures generated from a novel causal data prior will produce models that generalize to real-world irregularly observed time series without task-specific fine-tuning.
What would settle it
Run TS-ICL zero-shot on a collection of real-world datasets that contain documented irregular sampling and missing values, then compare its joint imputation-plus-forecasting error against both specialized imputation models and leading forecasting foundation models.
Figures



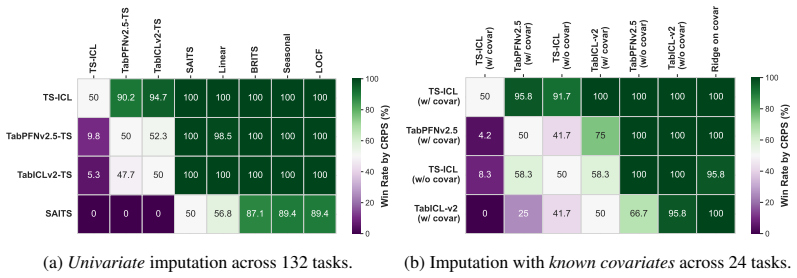

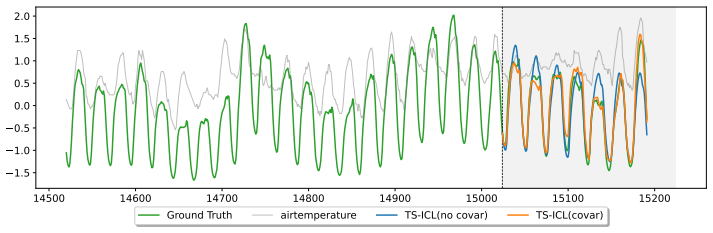
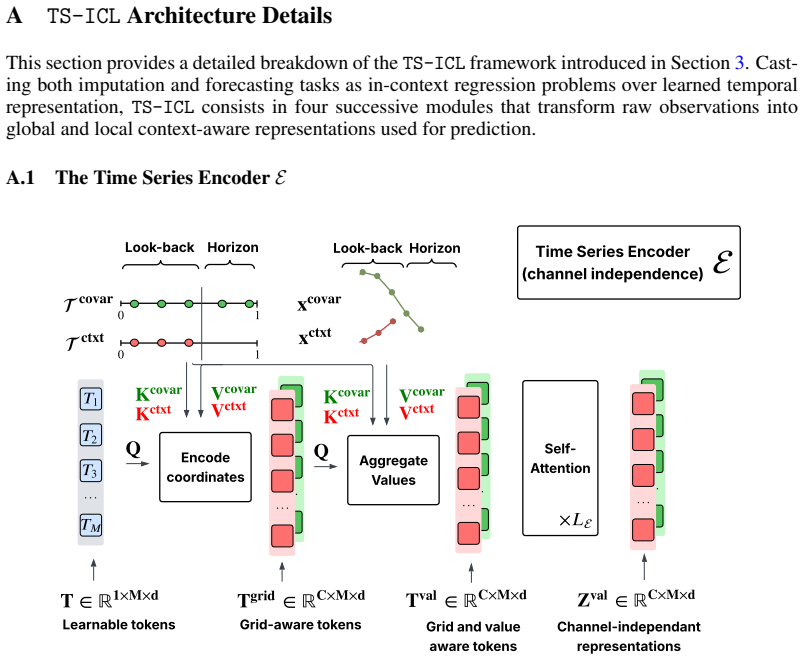


















read the original abstract
Foundation models mark a profound paradigm shift in time series modeling, with task-specific models being superseded by general-purpose zero-shot models. Yet, current approaches primarily focus on forecasting, while real-world time series are often irregularly and partially observed, requiring models that can jointly forecast, impute missing values, and handle degraded sampling conditions. To address these challenges, we introduce TS-ICL, a novel probabilistic In-Context Learning encoder--regressor Transformer that unifies forecasting and imputation. TS-ICL formulates time series tasks as timestamp-aligned regression and naturally incorporates covariates by training on synthetic dependency structures generated from a novel causal data prior. Empirically, TS-ICL achieves a new state-of-the-art in imputation, while remaining competitive with leading forecasting foundation models across both univariate and covariate-aware benchmarks. It shows particularly strong performance in forecasting with partially observed look-back windows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TS-ICL, a probabilistic In-Context Learning encoder-regressor Transformer for time series. It unifies forecasting and imputation by casting tasks as timestamp-aligned regression, incorporates covariates via training on synthetic dependency structures from a novel causal data prior, and reports new state-of-the-art imputation performance together with competitive forecasting results on univariate and covariate-aware benchmarks, including strong results under partially observed look-back windows.
Significance. If the zero-shot transfer from the synthetic causal prior to real irregularly sampled series holds, the work would address a clear gap in existing time-series foundation models, which are largely forecasting-centric. The timestamp-indexed ICL formulation and unified handling of missingness and covariates could enable more flexible deployment on real-world data.
major comments (3)
- [Methods / Data Generation] The central empirical claims rest on generalization from the novel causal data prior, yet the manuscript provides no quantitative validation (e.g., distributional distances, higher-order moment matching, or missingness pattern statistics) that the synthetic regime reproduces the joint distributions or irregular sampling statistics of the evaluation benchmarks. This is load-bearing for the SOTA imputation assertion.
- [Experiments / Results] No error bars, standard deviations across seeds, or statistical significance tests accompany the reported imputation and forecasting metrics. Without these, it is impossible to determine whether the claimed superiority over prior foundation models is robust or within noise.
- [Experiments / Ablations] The manuscript does not report ablations that isolate the contribution of the causal data prior versus the ICL architecture or the timestamp-alignment formulation. Such controls are required to substantiate that the performance gains derive from the proposed prior rather than other modeling choices.
minor comments (2)
- [Experiments] Dataset descriptions, preprocessing steps, and exact benchmark splits are insufficiently detailed to allow reproduction of the reported numbers.
- [Model] Notation for the timestamp-indexed regression objective and the probabilistic output head should be formalized with explicit equations rather than left at the level of the abstract description.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects for strengthening the empirical support of our work. We address each major comment point-by-point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Methods / Data Generation] The central empirical claims rest on generalization from the novel causal data prior, yet the manuscript provides no quantitative validation (e.g., distributional distances, higher-order moment matching, or missingness pattern statistics) that the synthetic regime reproduces the joint distributions or irregular sampling statistics of the evaluation benchmarks. This is load-bearing for the SOTA imputation assertion.
Authors: We agree that explicit quantitative validation of the synthetic data prior against real benchmarks would strengthen the manuscript. In the revised version, we will add comparisons of key statistics including marginal distributions, autocorrelation functions, cross-covariances with covariates, and missingness pattern frequencies between the causal synthetic data and the evaluation datasets. This will directly support the zero-shot transfer claims. revision: yes
-
Referee: [Experiments / Results] No error bars, standard deviations across seeds, or statistical significance tests accompany the reported imputation and forecasting metrics. Without these, it is impossible to determine whether the claimed superiority over prior foundation models is robust or within noise.
Authors: We acknowledge this limitation in the current presentation. We will rerun all reported experiments across multiple random seeds, add standard deviations and error bars to the tables and figures, and include statistical significance tests (e.g., paired t-tests or Wilcoxon tests) against baselines in the revised manuscript. revision: yes
-
Referee: [Experiments / Ablations] The manuscript does not report ablations that isolate the contribution of the causal data prior versus the ICL architecture or the timestamp-alignment formulation. Such controls are required to substantiate that the performance gains derive from the proposed prior rather than other modeling choices.
Authors: We will add dedicated ablation experiments in the revision. These will include variants trained on non-causal synthetic data (e.g., independent Gaussian processes) and ablations removing timestamp alignment, allowing direct isolation of the causal prior's contribution relative to the ICL encoder-regressor architecture. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an empirical foundation model trained on synthetic data generated from a causal prior and evaluated zero-shot on real benchmarks for imputation and forecasting. No equations, derivations, or self-citations are shown that reduce claimed performance metrics to quantities fitted on the evaluation data itself. The central claims rest on experimental results rather than any self-definitional, fitted-input-renamed-as-prediction, or self-citation-load-bearing structure. The generalization from synthetic to real data is an empirical assumption, not a circular reduction by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of encoder-regressor Transformer architectures hold for the probabilistic in-context learning setup.
invented entities (1)
-
novel causal data prior
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GIFT-eval: A benchmark for general time series forecasting model evaluation
Taha Aksu, Gerald Woo, Juncheng Liu, Xu Liu, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. GIFT-eval: A benchmark for general time series forecasting model evaluation. InNeurIPS Workshop on Time Series in the Age of Large Models, 2024. URL https://openreview.net/forum?id=Z2cMOOANFX
2024
-
[2]
Maddix, Hao Wang, Michael W
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner T ¨urkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda-Arango, Shub- ham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Bernie Wang. Chronos: Learning the l...
2024
-
[3]
Chronos-2: From univariate to universal forecasting.arXiv preprint arXiv:2510.15821, 2025
Abdul Fatir Ansari, Oleksandr Shchur, Jaris K¨uken, Andreas Auer, Boran Han, Pedro Mercado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, et al. Chronos-2: From univariate to universal forecasting.arXiv preprint arXiv:2510.15821, 2025
Pith/arXiv arXiv 2025
-
[4]
Tirex: Zero-shot forecasting across long and short horizons with enhanced in- context learning
Andreas Auer, Patrick Podest, Daniel Klotz, Sebastian B ¨ock, G ¨unter Klambauer, and Sepp Hochreiter. Tirex: Zero-shot forecasting across long and short horizons with enhanced in- context learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=v7UqniC9pF
2025
-
[5]
Language mod- els are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language mod- els are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[6]
BRITS: bidirectional recurrent imputation for time series
Wei Cao, Dong Wang, Jian Li, Hao Zhou, Yitan Li, and Lei Li. BRITS: bidirectional recurrent imputation for time series. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[7]
VisionTS: Visual masked autoencoders are free-lunch zero-shot time series forecast- ers
Mouxiang Chen, Lefei Shen, Zhuo Li, Xiaoyun Joy Wang, Jianling Sun, and Chenghao Liu. VisionTS: Visual masked autoencoders are free-lunch zero-shot time series forecast- ers. InForty-second International Conference on Machine Learning, 2025. URLhttps: //openreview.net/forum?id=5DSj3MfWrB
2025
-
[8]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[9]
Population time series: process variability, observation errors, missing values, lags, and hidden states.Ecology, 85(11):3140–3150, 2004
James S Clark and Ottar N Bjørnstad. Population time series: process variability, observation errors, missing values, lags, and hidden states.Ecology, 85(11):3140–3150, 2004
2004
-
[10]
This time is different: An observability 10 perspective on time series foundation models
Ben Cohen, Emaad Khwaja, Youssef Doubli, Salahidine Lemaachi, Chris Lettieri, Charles Masson, Hugo Miccinilli, Elise Ram ´e, Qiqi Ren, Afshin Rostamizadeh, Jean Ogier du Ter- rail, Anna-Monica Toon, Kan Wang, Stephan Xie, Zongzhe Xu, Viktoriya Zhukova, David Asker, Ameet Talwalkar, and Othmane Abou-Amal. This time is different: An observability 10 perspec...
2025
-
[11]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InForty-first International Conference on Machine Learn- ing, ICML 2024, Vienna, Austria, July 21-27, 2024, Proceedings of Machine Learning Re- search, 2024
2024
-
[12]
ForecastPFN: Synthetically-trained zero-shot forecasting
Samuel Dooley, Gurnoor Singh Khurana, Chirag Mohapatra, Siddartha V Naidu, and Colin White. ForecastPFN: Synthetically-trained zero-shot forecasting. InAdvances in Neural In- formation Processing Systems, volume 36, pp. 2403–2426, 2023
2023
-
[13]
Clash-of-Leges: A bilingual dataset for conflict detection and explanation in statutory law
Wenjie Du, David C ˆot´e, and Yan Liu. SAITS: Self-attention-based imputation for time se- ries.Expert Systems with Applications, 219:119619, 2023. doi: https://doi.org/10.1016/j.eswa. 2023.119619
-
[14]
Wenjie Du, Yiyuan Yang, Linglong Qian, Jun Wang, and Qingsong Wen. PyPOTS: A Python Toolkit for Machine Learning on Partially-Observed Time Series.arXiv:2305.18811, 2023
arXiv 2023
-
[15]
What can transform- ers learn in-context? a case study of simple function classes
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transform- ers learn in-context? a case study of simple function classes. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.),Advances in Neural Information Process- ing Systems, volume 35, pp. 30583–30598. Curran Associates, Inc., 2022
2022
-
[16]
Probabilistic forecasts, calibra- tion and sharpness.Journal of the Royal Statistical Society Series B: Statistical Methodology, 69(2):243–268, 2007
Tilmann Gneiting, Fadoua Balabdaoui, and Adrian E Raftery. Probabilistic forecasts, calibra- tion and sharpness.Journal of the Royal Statistical Society Series B: Statistical Methodology, 69(2):243–268, 2007
2007
-
[17]
TabPFN: A trans- former that solves small tabular classification problems in a second
Noah Hollmann, Samuel M ¨uller, Katharina Eggensperger, and Frank Hutter. TabPFN: A trans- former that solves small tabular classification problems in a second. InThe Eleventh Interna- tional Conference on Learning Representations, 2022
2022
-
[18]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel M ¨uller, Lennart Purucker, Arjun Krishnakumar, Max K¨orfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
2025
-
[19]
Shi Bin Hoo, Samuel M ¨uller, David Salinas, and Frank Hutter. From tables to time: How TabPFN-v2 outperforms specialized time series forecasting models.arXiv preprint arXiv:2501.02945, 2025
arXiv 2025
-
[20]
OTexts, 2018
Rob J Hyndman and George Athanasopoulos.Forecasting: principles and practice. OTexts, 2018
2018
-
[21]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Car- reira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pp. 4651–4664. PMLR, 2021
2021
-
[22]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon/
2024
-
[23]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Lei Ba. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations, 2015
2015
-
[24]
Quantile Regression.Journal of Economic Perspectives, 15(4):143–156, 2001
Roger Koenker and Kevin F Hallock. Quantile Regression.Journal of Economic Perspectives, 15(4):143–156, 2001. doi: 10.1257/jep.15.4.143
-
[25]
Time series continuous modeling for imputation and forecasting with implicit neural representations.Transactions on Machine Learning Research,
Etienne Le Naour, Louis Serrano, L ´eon Migus, Yuan Yin, Ghislain Agoua, Nicolas Baskiotis, Patrick Gallinari, and Vincent Guigue. Time series continuous modeling for imputation and forecasting with implicit neural representations.Transactions on Machine Learning Research,
-
[26]
URLhttps://openreview.net/forum?id=P1vzXDklar
ISSN 2835-8856. URLhttps://openreview.net/forum?id=P1vzXDklar. 11
-
[27]
Are time-indexed foun- dation models the future of time series imputation?Transactions on Machine Learning Re- search, 2026
Etienne Le Naour, Tahar Nabil, Adrien Petralia, and Ghislain Agoua. Are time-indexed foun- dation models the future of time series imputation?Transactions on Machine Learning Re- search, 2026. ISSN 2835-8856. URLhttps://openreview.net/forum?id=cTk56KpsP5
2026
-
[28]
Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025
Chenghao Liu, Taha Aksu, Juncheng Liu, Xu Liu, Hanshu Yan, Quang Pham, Silvio Savarese, Doyen Sahoo, Caiming Xiong, and Junnan Li. Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025
arXiv 2025
-
[29]
Sundial: A family of highly capable time series founda- tion models
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Sundial: A family of highly capable time series founda- tion models. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=LO7ciRpjI5
2025
-
[30]
Nerf: Representing scenes as neural radiance fields for view synthesis.Commu- nications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Commu- nications of the ACM, 65(1):99–106, 2021
2021
-
[31]
Tem- poPFN: Towards synthetic pre-training of linear RNNs for zero-shot time series forecasting
Vladyslav Moroshan, Julien Siems, Arber Zela, Timur Carstensen, and Frank Hutter. Tem- poPFN: Towards synthetic pre-training of linear RNNs for zero-shot time series forecasting. InEurIPS 2025 Workshop: AI for Tabular Data, 2025. URLhttps://openreview.net/ forum?id=Iqex1gfnvc
2025
-
[32]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InInternational Conference on Learning Representations, ICLR, 2023
2023
-
[33]
MIT press, 2017
Jonas Peters, Dominik Janzing, and Bernhard Scholkopf.Elements of causal inference: foun- dations and learning algorithms. MIT press, 2017
2017
-
[34]
Zhongzheng Qiao, Sheng Pan, Anni Wang, Viktoriya Zhukova, Yong Liu, Xudong Jiang, Qing- song Wen, Mingsheng Long, Ming Jin, and Chenghao Liu. It’s TIME: Towards the next gen- eration of time series forecasting benchmarks.arXiv preprint arXiv:2602.12147, 2026
Pith/arXiv arXiv 2026
-
[35]
Jingang Qu, David Holzm ¨uller, Ga¨el Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139, 2026
arXiv 2026
-
[36]
Yulia Rubanova, Ricky T. Q. Chen, and David Duvenaud. Latent odes for irregularly-sampled time series. InProceedings of the 33rd International Conference on Neural Information Pro- cessing Systems, Red Hook, NY , USA, 2019. Curran Associates Inc
2019
-
[37]
Spectrum: Spectral analysis of unevenly spaced paleocli- matic time series.Computers & Geosciences, 23(9):929–945, 1997
Michael Schulz and Karl Stattegger. Spectrum: Spectral analysis of unevenly spaced paleocli- matic time series.Computers & Geosciences, 23(9):929–945, 1997
1997
-
[38]
Aroma: Preserving spatial structure for latent pde modeling with local neural fields.Advances in Neural Information Processing Systems, 37:13489–13521, 2024
Louis Serrano, Thomas X Wang, Etienne Le Naour, Jean-No ¨el Vittaut, and Patrick Gallinari. Aroma: Preserving spatial structure for latent pde modeling with local neural fields.Advances in Neural Information Processing Systems, 37:13489–13521, 2024
2024
-
[39]
fev-bench: A realistic benchmark for time series forecasting.arXiv preprint arXiv:2509.26468, 2025
Oleksandr Shchur, Abdul Fatir Ansari, Caner Turkmen, Lorenzo Stella, Nick Erickson, Pablo Guerron, Michael Bohlke-Schneider, and Yuyang Wang. fev-bench: A realistic benchmark for time series forecasting.arXiv preprint arXiv:2509.26468, 2025
arXiv 2025
-
[40]
Estimating conditional quantiles with the help of the pinball loss.Bernoulli, 17(1), 2011
Ingo Steinwart and Andreas Christmann. Estimating conditional quantiles with the help of the pinball loss.Bernoulli, 17(1), 2011. doi: 10.3150/10-BEJ267
-
[41]
Forecasting at scale.The American Statistician, 72(1): 37–45, 2018
Sean J Taylor and Benjamin Letham. Forecasting at scale.The American Statistician, 72(1): 37–45, 2018
2018
-
[42]
Transformers learn in-context by gradient descent
Johannes V on Oswald, Eyvind Niklasson, Ettore Randazzo, Jo ˜ao Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[43]
Learning deep time-index models for time series forecasting
Gerald Woo, Chenghao Liu, Doyen Sahoo, Akshat Kumar, and Steven Hoi. Learning deep time-index models for time series forecasting. InInternational Conference on Machine Learn- ing, pp. 37217–37237. PMLR, 2023. 12
2023
-
[44]
Unified training of universal time series forecasting transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sa- hoo. Unified training of universal time series forecasting transformers. InForty-first Interna- tional Conference on Machine Learning, 2024
2024
-
[45]
Out-of-distribution generalization in time series: A survey.Information Fusion, pp
Xin Wu, Fei Teng, Xingwang Li, Ji Zhang, Qiang Duan, and Tianrui Li. Out-of-distribution generalization in time series: A survey.Information Fusion, pp. 104336, 2026
2026
-
[46]
Cauker: Classification time series foundation models can be pretrained on synthetic data
Shifeng Xie, Vasilii Feofanov, Jianfeng Zhang, Themis Palpanas, and Ievgen Redko. Cauker: Classification time series foundation models can be pretrained on synthetic data. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=xBW2FIfswU. 13 Appendices ATS-ICLArchitecture Details 15 A.1 The Time Se...
2026
-
[47]
followed by a linear projection: T Fourier + Linear − − − − − − − − →γ(T)∈RT×d . (ii)Coordinate Encoding.A set ofMlearnable latent tokensT∈R 1×M×d serves as a query (Q) and attends to the temporal embeddings of all channels (context and covariates) through cross-attention: T grid = CrossAttn(Q=T, K=V=γ(T))∈R C×M×d . This step producesgrid-aware tokensthat...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.