Short paper: Models in the dark -- Rectification and erasure under GDPR in ML supply chains
Pith reviewed 2026-06-28 03:21 UTC · model grok-4.3
The pith
Many GDPR requirements for rectification and erasure cannot be met technically in machine learning supply chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that many GDPR requirements cannot yet be technically met in practice, that issues arising in ML supply chains are insufficiently addressed in research, and that the notion of models in the dark poses urgent challenges.
What carries the argument
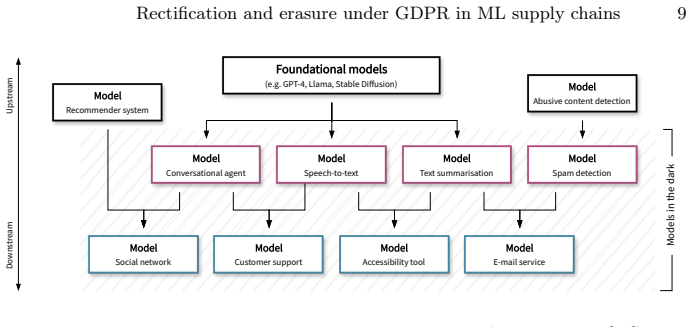
Models in the dark, defined as derived models created further downstream in an ML chain without sufficient transparency or traceability.
If this is right
- Technical work on data subject rights must incorporate the presence of multiple independent actors across the full ML development and deployment process.
- Future research on rectification and erasure needs to treat supply-chain opacity as a primary rather than secondary concern.
- Interdisciplinary efforts are required to translate GDPR rules into implementable mechanisms that function when models are passed downstream.
- Trustworthy AI development depends on closing the identified gaps between legal rights and existing technical tools.
Where Pith is reading between the lines
- Standardized interfaces or logging requirements between supply-chain participants could become necessary if models in the dark remain common.
- The identified research gap may point to a need for new auditing standards that verify privacy compliance across organizational boundaries.
- If downstream models routinely lack traceability, regulators might need to impose upstream obligations on data providers or model distributors.
Load-bearing premise
The surveyed academic literature and data protection authority guidance provide a sufficiently complete and accurate picture of both current technical capabilities and the extent of research attention to supply-chain issues.
What would settle it
A working technical system that fully supports rectification and erasure across an entire multi-actor ML supply chain, with clear traceability at every stage, would show that the requirements can be met.
Figures

read the original abstract
The rights to rectification and erasure, as established under the General Data Protection Regulation (GDPR), are central to protecting individuals' privacy. However, their effective enforcement in machine learning (ML) systems remains challenging. Existing work has largely addressed these rights from either a legal or a technical perspective in isolation and disregards the fact that models are produced in complex supply chains involving multiple actors across development, distribution, and deployment. This paper presents a holistic survey of challenges in implementing the rights to rectification and erasure in ML models. Drawing on academic literature and guidance from data protection authorities, we find that many GDPR requirements cannot yet be technically met in practice. Our findings further suggest that issues arising in ML supply chains are insufficiently addressed in research. To tackle this gap, we introduce the notion of models in the dark -- derived models created further downstream in an ML chain without sufficient transparency or traceability -- and analyse the urgent challenges posed by this phenomenon. By adopting an interdisciplinary perspective, this work contributes to bridging the gap between legal requirements and the technical implementation of data subject rights in ML, ultimately supporting the development of trustworthy artificial intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a holistic survey of challenges in implementing the GDPR rights to rectification and erasure in machine learning models, focusing on complex supply chains involving multiple actors. Drawing from academic literature and data protection authority guidance, it concludes that many GDPR requirements cannot be technically met in practice and that supply-chain issues are insufficiently addressed in research. It introduces the notion of 'models in the dark' for downstream models lacking transparency and analyzes the challenges they pose, advocating an interdisciplinary approach to bridge legal and technical gaps.
Significance. If the literature survey is comprehensive and balanced, this work is significant for identifying practical barriers to GDPR compliance in ML systems and highlighting under-researched areas in supply chains. The introduction of 'models in the dark' offers a new lens for discussing traceability issues in ML pipelines, which could inform future research on machine unlearning and model editing in distributed settings. This contributes to the development of trustworthy AI by connecting legal obligations with technical realities.
major comments (1)
- [Survey approach / literature review section] The claims that many GDPR requirements cannot yet be technically met and that supply-chain issues are insufficiently addressed in research (abstract and main findings) rest on the surveyed literature and DPA guidance providing an accurate picture of capabilities and gaps. No explicit methodology for the literature review is described, including search strings, databases, date ranges, or inclusion/exclusion criteria. This is load-bearing for the central claims, as relevant work on machine unlearning, model editing, or supply-chain traceability could be omitted.
minor comments (2)
- [Abstract and introduction] The term 'models in the dark' is introduced without an early, precise definition distinguishing it from related concepts such as black-box models or model extraction attacks; add this in the introduction for clarity.
- [Throughout] Ensure consistent terminology when referring to supply-chain actors (developers, distributors, deployers) across sections to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and recommendation. The single major comment identifies a genuine gap in the presentation of our survey methodology, which we address directly below by committing to a clear revision.
read point-by-point responses
-
Referee: The claims that many GDPR requirements cannot yet be technically met and that supply-chain issues are insufficiently addressed in research (abstract and main findings) rest on the surveyed literature and DPA guidance providing an accurate picture of capabilities and gaps. No explicit methodology for the literature review is described, including search strings, databases, date ranges, or inclusion/exclusion criteria. This is load-bearing for the central claims, as relevant work on machine unlearning, model editing, or supply-chain traceability could be omitted.
Authors: We agree that the absence of an explicit methodology section weakens the transparency of the survey and is a valid point for major revision. In the revised manuscript we will insert a new subsection (provisionally titled 'Survey Methodology') immediately after the introduction. It will specify: (i) the databases and repositories searched (Google Scholar, arXiv, IEEE Xplore, ACM Digital Library, and the official websites of the European Data Protection Board and selected national DPAs); (ii) the Boolean search strings employed (combinations of 'GDPR' AND ('rectification' OR 'erasure' OR 'right to be forgotten') AND ('machine learning' OR 'model' OR 'supply chain' OR 'unlearning' OR 'model editing')); (iii) the temporal scope (January 2018–March 2024, reflecting the GDPR's applicability date); and (iv) inclusion/exclusion criteria (peer-reviewed articles, official DPA guidance documents, and technical reports that directly address technical feasibility of rectification or erasure; exclusion of purely theoretical legal analyses without technical discussion and of non-English sources). We have re-examined our internal search logs and confirm that the cited works on machine unlearning and model editing were captured under these criteria; making the process explicit will allow readers to evaluate coverage. This change directly strengthens the evidential basis for the paper's central claims without altering their substance. revision: yes
Circularity Check
No circularity: survey draws on external sources without self-referential derivation
full rationale
The paper is a survey of legal-technical challenges in GDPR rights for ML models. It contains no equations, fitted parameters, predictions derived from inputs, or mathematical derivations. Claims rest on cited academic literature and DPA guidance treated as external inputs. No self-citation is load-bearing in a definitional or reductionist sense, and the 'models in the dark' notion is introduced as an analytical framing rather than derived from prior self-work. This matches the default non-circular outcome for survey papers self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption GDPR rights to rectification and erasure apply to personal data used in ML models produced through supply chains
- domain assumption Existing technical methods are insufficient to meet many GDPR requirements in practice
invented entities (1)
-
models in the dark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
BlairAttard-FrostandDavidGrayWidder.“TheethicsofAIvaluechains”. In:Big Data & Society12.2 (2025).doi: 10.1177/20539517251340603
-
[2]
Agathe Balayn et al. “Unpacking Trust Dynamics in the LLM Supply Chain: An Empirical Exploration to Foster Trustworthy LLM Production & Use”. In:Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 2025, pp. 1–20.doi: 10.1145/3706598.3713787
-
[3]
Reconstruction Attacks on Machine Unlearning: Simple Models are Vulnerable
Martin Bertran et al. “Reconstruction Attacks on Machine Unlearning: Simple Models are Vulnerable”. In:Advances in Neural Information Pro- cessing Systems 37. 2024, pp. 104995–105016.doi: 10.52202/079017-3334
-
[4]
Lucas Bourtoule et al. “Machine Unlearning”. In:2021 IEEE Symposium on Security and Privacy (SP). 2021, pp. 141–159.doi: 10.1109/SP40001. 2021.00019. 12 Graßhoff et al
-
[5]
Human-GDPR Interaction: Practical Experiences of Accessing Personal Data
Alex Bowyer et al. “Human-GDPR Interaction: Practical Experiences of Accessing Personal Data”. In:CHI Conference on Human Factors in Com- puting Systems. 2022, pp. 1–19.doi: 10.1145/3491102.3501947
-
[6]
2023.url: https: //adalovelaceinstitute.org/resource/ai-supply-chains/
Ian Brown.Allocating accountability in AI supply chains. 2023.url: https: //adalovelaceinstitute.org/resource/ai-supply-chains/
2023
-
[7]
Yinzhi Cao and Junfeng Yang. “Towards Making Systems Forget with Machine Unlearning”. In:2015 IEEE Symposium on Security and Privacy. 2015, pp. 463–480.doi: 10.1109/SP.2015.35
-
[8]
Extracting Training Data from Large Language Models
Nicholas Carlini et al. “Extracting Training Data from Large Language Models”. In:30th USENIX Security Symposium (USENIX Security 21). 2021, pp. 2633–2650
2021
-
[9]
The Secret Sharer: Evaluating and Testing Un- intended Memorization in Neural Networks
Nicholas Carlini et al. “The Secret Sharer: Evaluating and Testing Un- intended Memorization in Neural Networks”. In:28th USENIX Security Symposium (USENIX Security 19). 2019, pp. 267–284
2019
-
[10]
ExtractingTrainingDatafromDiffusionModels
NicolasCarlinietal.“ExtractingTrainingDatafromDiffusionModels”.In: 32nd USENIX Security Symposium (USENIX Security 23).2023,pp.5253– 5270
2023
-
[11]
A survey of security and privacy issues of machine unlearning
Aobo Chen et al. “A survey of security and privacy issues of machine unlearning”. In:AI Magazine46.1 (2025).doi: 10.1002/aaai.12209
-
[12]
New directions in automated traffic analysis
Min Chen et al. “When Machine Unlearning Jeopardizes Privacy”. In:Pro- ceedings of the 2021 ACM SIGSAC Conference on Computer and Com- munications Security. 2021, pp. 896–911.doi: 10.1145/3460120.3484756
-
[13]
Artificial intelligence as a service: Legal responsibilities, liabilities, and policy challenges
Jennifer Cobbe and Jatinder Singh. “Artificial intelligence as a service: Legal responsibilities, liabilities, and policy challenges”. In:Computer Law & Security Review42 (2021).doi: 10.1016/j.clsr.2021.105573
-
[14]
Understanding ac- countability in algorithmic supply chains
Jennifer Cobbe, Michael Veale, and Jatinder Singh. “Understanding ac- countability in algorithmic supply chains”. In:2023 ACM Conference on Fairness Accountability and Transparency. 2023, pp. 1186–1197.doi: 10. 1145/3593013.3594073
arXiv 2023
-
[15]
2024.url: https://www.cnil
Commission nationale de l’informatique et des libertés.Determining the legal qualification of AI system providers. 2024.url: https://www.cnil. fr/en/determining-legal-qualification-ai-system-providers (visited on 04/22/2026)
2024
-
[16]
2026.url: https://www
Commission nationale de l’informatique et des libertés.Ensuring and fa- cilitating the exercise of data subjects’ rights. 2026.url: https://www. cnil.fr/en/ensuring-and-facilitating-exercise-data-subjects-rights (visited on 04/16/2026)
2026
-
[17]
A. Feder Cooper et al. “Accountability inan Algorithmic Society: Relation- ality, Responsibility, and Robustness in Machine Learning”. In:2022 ACM Conference on Fairness Accountability and Transparency. 2022, pp. 864– 876.doi: 10.1145/3531146.3533150
-
[18]
2025.url: https://github.com/deepseek- ai/DeepSeek-V3 (visited on 04/22/2026)
DeepSeek-AI.DeepSeek-V3. 2025.url: https://github.com/deepseek- ai/DeepSeek-V3 (visited on 04/22/2026)
2025
-
[19]
AI Meets the GDPR: Navigating the Impact of Data Protection on AI Systems
Pierre Dewitte. “AI Meets the GDPR: Navigating the Impact of Data Protection on AI Systems”. In:The Cambridge Handbook of the Law, Rectification and erasure under GDPR in ML supply chains 13 Ethics and Policy of Artificial Intelligence. Ed. by Nathalie A. Smuha. 1st ed. Cambridge University Press, 2025, pp. 133–157.doi: 10.1017/ 9781009367783.010
2025
-
[20]
Safeguarding large language models: a survey
Yi Dong et al. “Safeguarding large language models: a survey”. en. In: Artificial Intelligence Review58.12 (2025).issn: 1573-7462.doi: 10.1007/ s10462-025-11389-2
2025
-
[21]
2023.url: https://www.edpb.europa.eu/system/ files/2023-04/edpb_guidelines_202201_data_subject_rights_access_ v2_en.pdf
European Data Protection Board.Guidelines 01/2022 on data subject rights - Right of access. 2023.url: https://www.edpb.europa.eu/system/ files/2023-04/edpb_guidelines_202201_data_subject_rights_access_ v2_en.pdf
2022
-
[22]
2024.url: https://www.edpb.europa.eu/system/files/2024- 12/edpb_opinion_202428_ai-models_en.pdf
European Data Protection Board.Opinion 28/2024 on certain data pro- tection aspects related to the processing of personal data in the context of AI models. 2024.url: https://www.edpb.europa.eu/system/files/2024- 12/edpb_opinion_202428_ai-models_en.pdf
2024
-
[23]
GDPR and Large Language Models: Techni- cal and Legal Obstacles
Georgios Feretzakis et al. “GDPR and Large Language Models: Techni- cal and Legal Obstacles”. In:Future Internet17.4 (2025).doi: 10.3390/ fi17040151
2025
-
[24]
Wenjie Fu et al.Sanitize Your Responses: Mitigating Privacy Leakage in Large Language Models. arXiv. 2025.doi: 10.48550/arXiv.2509.24488
-
[25]
In: IEEE/CVF International Conference on Computer Vision
Rohit Gandikota et al. “Erasing Concepts from Diffusion Models”. In:2023 IEEE/CVF International Conference on Computer Vision (ICCV). 2023, pp. 2426–2436.doi: 10.1109/ICCV51070.2023.00230
-
[26]
Leo Gao et al.The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv. 2021.doi: 10.48550/arXiv.2101.00027
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2101.00027 2021
-
[27]
Supportpoolofexpertsprogramme
Enrico Glerean.Fundamentals of Secure AI Systems with Personal Data. Supportpoolofexpertsprogramme. 2025.url: https://www.edpb.europa. eu/system/files/2025-06/spe-training-on-ai-and-data-protection- technical_en.pdf
2025
-
[28]
A typology of reviews: an analysis of 14 review types and associated methodologies
Maria J. Grant and Andrew Booth. “A typology of reviews: an analysis of 14 review types and associated methodologies”. In:Health Information & Libraries Journal26.2 (2009), pp. 91–108.doi: 10.1111/j.1471-1842.2009. 00848.x
-
[29]
William Hackett et al.Bypassing LLM Guardrails: An Empirical Analy- sis of Evasion Attacks against Prompt Injection and Jailbreak Detection Systems. arXiv. 2025.doi: 10.48550/arXiv.2504.11168
-
[30]
A Decision-Making Process to Implement the ‘Right to Be Forgotten’ in Machine Learning
Katie Hawkins et al. “A Decision-Making Process to Implement the ‘Right to Be Forgotten’ in Machine Learning”. In:Privacy Technologies and Pol- icy. APF 2023. Ed. by Kai Rannenberg, Prokopios Drogkaris, and Cédric Lauradoux. Vol. 13888. 2024, pp. 20–38.doi: 10.1007/978-3-031-61089- 9_2
-
[31]
Aspen Hopkins et al.AI Supply Chains. SSRN Electronic Journal. 2024. doi: 10.2139/ssrn.4789403
-
[32]
Recourse, Repair, Reparation, & Prevention: A Stakeholder Analysis of AI Supply Chains
Aspen Hopkins et al. “Recourse, Repair, Reparation, & Prevention: A Stakeholder Analysis of AI Supply Chains”. In:Proceedings of the 2025 14 Graßhoff et al. ACM Conference on Fairness, Accountability, and Transparency. 2025, pp. 209–227.doi: 10.1145/3715275.3732017
-
[33]
Hongsheng Hu et al. “Membership Inference Attacks on Machine Learning: A Survey”. In:ACM Computing Surveys54.11s (2022), pp. 1–37.doi: 10.1145/3523273
-
[34]
Are Large Pre- Trained Language Models Leaking Your Personal Information?
Jie Huang, Hanyin Shao, and Kevin Chen-Chuan Chang. “Are Large Pre- Trained Language Models Leaking Your Personal Information?” In:Find- ings of the Association for Computational Linguistics: EMNLP 2022. 2022, pp. 2038–2047.doi: 10.18653/v1/2022.findings-emnlp.148. [35]Hugging Face – The AI community building the future.url: https:// huggingface.co/ (visi...
-
[36]
Khasentino, J., Belyaeva, A., Liu, X., Yang, Z., Furlotte, N
Ziwei Ji et al. “Survey of Hallucination in Natural Language Generation”. In:ACM Computing Surveys55.12(2023),pp.1–38.doi:10.1145/3571730
-
[37]
Algorithms that forget: Machine unlearning and the right to erasure
Bjørn Aslak Juliussen, Jon Petter Rui, and Dag Johansen. “Algorithms that forget: Machine unlearning and the right to erasure”. In:Computer Law & Security Review51 (2023).doi: 10.1016/j.clsr.2023.105885
-
[38]
Anna Kelsey-Sugg and Damien Carrick.AI hallucinations caused artificial intelligence to falsely describe these people as criminals. ABC News. Nov. 2024.url: https://abc.net.au/news/2024-11-04/ai-artificial-intelligence- hallucinations-defamation-chatgpt/104518612 (visited on 04/21/2026)
arXiv 2024
-
[39]
ArtificialIntelligenceandtheGDPR: Inevitable Nemeses?
AleksandrKesaandTanelKerikmäe.“ArtificialIntelligenceandtheGDPR: Inevitable Nemeses?” In:TalTech Journal of European Studies10.3 (2020), pp. 68–90.doi: 10.1515/bjes-2020-0022
-
[40]
Jennifer King et al.User Privacy and Large Language Models: An Analysis of Frontier Developers’ Privacy Policies.arXiv.2025.doi:10.48550/arXiv. 2509.05382
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[41]
2025.url: https://datenschutzkonferenz-online.de/media/ oh/DSK-OH_KI-Systeme.pdf
Konferenz der unabhängigen Datenschutzaufsichtsbehörden des Bundes und der Länder.Orientierungshilfe zu empfohlenen technischen und or- ganisatorischen Maßnahmen bei der Entwicklung und beim Betrieb von KI-Systemen. 2025.url: https://datenschutzkonferenz-online.de/media/ oh/DSK-OH_KI-Systeme.pdf
2025
-
[42]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Kenneth Li et al. “Inference-Time Intervention: Eliciting Truthful Answers from a Language Model”. In:Advances in Neural Information Processing Systems. Vol. 36. 2023, pp. 41451–41530
2023
-
[43]
A survey on machine unlearning: Techniques and new emerged privacy risks
Hengzhu Liu et al. “A survey on machine unlearning: Techniques and new emerged privacy risks”. In:Journal of Information Security and Applica- tions90 (2025).doi: 10.1016/j.jisa.2025.104010
-
[44]
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Yao Lu et al. “Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity”. In:Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).2022,pp.8086–8098.doi:10.18653/v1/2022.acl- long.556. Rectification and erasure under GDPR in ML supply chains 15
-
[45]
Meta.Celebrating 1 Billion Downloads of Llama. Mar. 2025.url: https: //about.fb.com/news/2025/03/celebrating-1-billion-downloads-llama/ (visited on 04/21/2026)
2025
-
[46]
Varia- tional Bayesian Unlearning
Quoc Phong Nguyen, Bryan Kian Hsiang Low, and Patrick Jaillet. “Varia- tional Bayesian Unlearning”. In:Advances in Neural Information Process- ing Systems33 (2020), pp. 16025–16036
2020
-
[47]
A Survey of Machine Unlearning
Thanh Tam Nguyen et al. “A Survey of Machine Unlearning”. In:ACM Transactions on Intelligent Systems and Technology16.5 (2025), pp. 1–46. doi: 10.1145/3749987
-
[48]
Martin Pawelczyk, Seth Neel, and Himabindu Lakkaraju.In-Context Un- learning: Language Models as Few Shot Unlearners. arXiv. 2023.doi: 10. 48550/arXiv.2310.07579. [50]Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free mo...
arXiv 2023
-
[49]
A Survey of Privacy Attacks in Ma- chine Learning
Maria Rigaki and Sebastian Garcia. “A Survey of Privacy Attacks in Ma- chine Learning”. In:ACM Computing Surveys56.4 (2024), pp. 1–34.doi: 10.1145/3624010
-
[50]
Exploring the Landscape of Machine Unlearning: A Comprehensive Survey and Taxonomy
Thanveer Shaik et al. “Exploring the Landscape of Machine Unlearning: A Comprehensive Survey and Taxonomy”. In:IEEE Transactions on Neural Networks and Learning Systems36.7 (2025), pp. 11676–11696.doi: 10. 1109/TNNLS.2024.3486109
arXiv 2025
-
[51]
Amer Sinha et al.VaultGemma: A Differentially Private Gemma Model. arXiv. 2025.doi: 10.48550/arXiv.2510.15001
-
[52]
Teodora Musatoiu.How to use the moderation API. Mar. 2024.url: https: //developers.openai.com/cookbook/examples/how_to_use_moderation
2024
-
[53]
PratikshaThakeretal.Guardrail Baselines for Unlearning in LLMs.arXiv. 2024.doi: 10.48550/arXiv.2403.03329
-
[54]
Fabienne Ufert. “AI Regulation Through the Lens of Fundamental Rights: How Well Does the GDPR Address the Challenges Posed by AI?” In: European Papers5.2 (2020), pp. 1087–1097.doi: 10.15166/2499-8249/394
-
[55]
Humansforget, machines remember: Artificial intelligence and the Right to Be Forgotten
EduardFoschVillaronga,PeterKieseberg,andTiffanyLi.“Humansforget, machines remember: Artificial intelligence and the Right to Be Forgotten”. In:Computer Law & Security Review34.2 (2018), pp. 304–313.doi: 10. 1016/j.clsr.2017.08.007. 16 Graßhoff et al
2018
-
[56]
A Comprehensive Survey of Continual Learning: The- ory, Method and Application
Liyuan Wang et al. “A Comprehensive Survey of Continual Learning: The- ory, Method and Application”. In:IEEE Transactions on Pattern Analy- sis and Machine Intelligence46.8 (2024), pp. 5362–5383.doi: 10.1109/ TPAMI.2024.3367329
arXiv 2024
-
[57]
Continual Learning: A Review of Techniques, Challenges, and Future Directions
Buddhi Wickramasinghe, Gobinda Saha, and Kaushik Roy. “Continual Learning: A Review of Techniques, Challenges, and Future Directions”. In: IEEE Transactions on Artificial Intelligence5.6 (2024), pp. 2526–2546. doi: 10.1109/TAI.2023.3339091
-
[58]
Machine Unlearning: Solutions and Challenges
Jie Xu et al. “Machine Unlearning: Solutions and Challenges”. In:IEEE Transactions on Emerging Topics in Computational Intelligence8.3(2024), pp. 2150–2168.doi: 10.1109/TETCI.2024.3379240
-
[59]
Towards Reliable Forgetting: A Survey on Machine Un- learning Verification
Lulu Xue et al. “Towards Reliable Forgetting: A Survey on Machine Un- learning Verification”. In:ACM Computing Surveys58.12 (2026), pp. 1–35. doi: 10.1145/3807451
-
[60]
A survey on federated learning
Chen Zhang et al. “A survey on federated learning”. In:Knowledge-Based Systems216 (2021).doi: 10.1016/j.knosys.2021.106775
-
[61]
Right to be forgotten in the Era of large language models: implications, challenges, and solutions
Dawen Zhang et al. “Right to be forgotten in the Era of large language models: implications, challenges, and solutions”. In:AI and Ethics5.3 (2025), pp. 2445–2454.doi: 10.1007/s43681-024-00573-9
-
[62]
To be forgotten or to be fair: unveiling fairness im- plications of machine unlearning methods
Dawen Zhang et al. “To be forgotten or to be fair: unveiling fairness im- plications of machine unlearning methods”. In:AI and Ethics4.1 (2024), pp. 83–93.doi: 10.1007/s43681-023-00398-y. Open Access.This manuscript is licensed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (https://creativecommon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.