Steering Vectors are an Adversarial Attack Surface
Pith reviewed 2026-06-28 03:11 UTC · model grok-4.3
The pith
Substituting 4-6% of tokens in a steering dataset can align the resulting vector with an anti-refusal direction, enabling jailbreaks while the intended steering on benign prompts stays intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
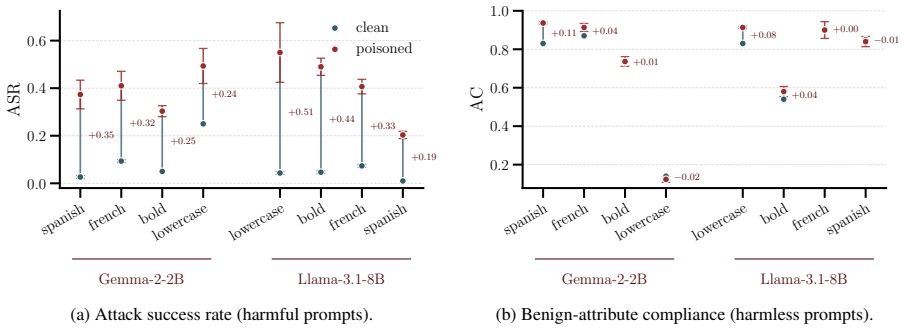
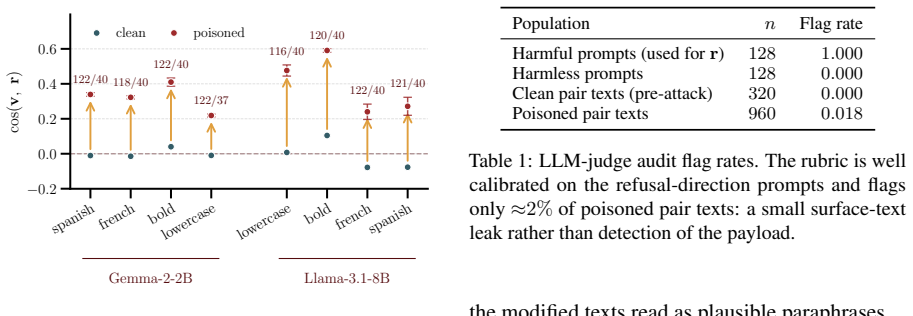
By substituting 4-6% of tokens in the steering dataset, an attacker can silently align the resulting vector with an anti-refusal direction. This jailbreaks the target model while preserving the intended steering effect on benign prompts. The attack is tested on two open-weight model families and eight model-attribute combinations, with poisoned vectors reaching an absolute attack success rate of 20-55%, an increase of 19% to 51% over clean references. A refusal-direction orthogonalization defense recovers approximately 82% of the ASR gap without harming benign behavior.
What carries the argument
The steering vector computed from a dataset after low-percentage token substitution that incorporates an anti-refusal component.
Load-bearing premise
The low-rate token substitution leaves the primary steering direction sufficiently intact to preserve intended behavior on benign prompts across the tested model-attribute pairs.
What would settle it
Test whether poisoned vectors from 4-6% substituted datasets produce 19-51% higher attack success rates on harmful prompts than clean vectors, while benign steering performance remains equivalent.
Figures




read the original abstract
Activation steering has become a popular way to control Large Language Model (LLM) behavior without fine-tuning. Since the technique is plug-and-play, users share datasets and precomputed vectors to steer model activations. However, we show that a \emph{stealth data poisoning attack} silently compromises this pipeline. By substituting $4{-}6\%$ of tokens in the steering dataset, an attacker can silently align the resulting vector with an anti-refusal direction. This jailbreaks the target model while preserving the intended steering effect on benign prompts. Under this threat model, a malicious actor can distribute an apparently safe bundle containing texts, vectors, and weights, alongside an equivalence certificate that the end-user can verify. We test the attack on two open-weight model families and eight model-attribute combinations, observing that poisoned vectors reach an absolute attack success rate (ASR) of $20{-}55\%$, $+19\%$ to $+51\%$ over a clean reference. Finally, we find that a refusal-direction orthogonalization defense can recover ${\approx}82\%$ of the ASR gap without harming benign behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper demonstrates a stealth data poisoning attack on activation steering vectors for LLMs. By replacing 4-6% of tokens in a steering dataset, an attacker can produce a vector that aligns with an anti-refusal direction, increasing jailbreak attack success rate (ASR) by 19-51% (absolute ASR 20-55%) across two model families and eight model-attribute pairs, while claiming to preserve the original steering effect on benign prompts. The work also evaluates a refusal-direction orthogonalization defense that recovers approximately 82% of the ASR gap.
Significance. If the preservation of benign steering behavior is robustly shown, the result identifies a practical attack surface in the increasingly common practice of sharing and applying precomputed steering vectors, with direct implications for LLM safety pipelines that rely on activation engineering. The multi-model empirical evaluation and the proposed defense are concrete contributions that could inform future work on verifiable steering artifacts.
major comments (3)
- [Abstract and §4] Abstract and §4 (results): the central claim that poisoned vectors 'preserve the intended steering effect on benign prompts' is load-bearing for the stealth property, yet no quantitative comparison (e.g., steering success rate, activation cosine similarity, or KL divergence on benign prompts) between clean and poisoned vectors is reported. Without this metric the +19% to +51% ASR gain cannot be assessed as stealthy rather than merely effective.
- [§3] §3 (attack construction): the 4-6% token substitution procedure is described at a high level, but the paper does not specify how the substituted tokens are chosen (random, refusal-correlated, or attribute-correlated) or provide an ablation showing that the primary attribute direction remains dominant after poisoning. This choice directly affects whether the primary direction is preserved or rotated.
- [§5] §5 (defense): the refusal-direction orthogonalization recovers ~82% of the ASR gap, but the manuscript does not report the effect of this defense on the original steering task performance or on other unrelated behaviors, leaving open whether the defense trades off utility for safety.
minor comments (2)
- [§4] The experimental protocol (dataset sizes, exact token substitution method, number of runs, statistical significance tests) is referenced but not fully detailed in the main text; moving the full protocol to the appendix or a reproducibility section would strengthen the work.
- [§2] Notation for the difference vector and the anti-refusal direction should be introduced once and used consistently; occasional shifts between 'steering vector' and 'difference vector' reduce clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects for strengthening the presentation of our results on stealth and defense evaluation. We address each major comment below and will incorporate revisions to provide the requested quantitative evidence and clarifications.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): the central claim that poisoned vectors 'preserve the intended steering effect on benign prompts' is load-bearing for the stealth property, yet no quantitative comparison (e.g., steering success rate, activation cosine similarity, or KL divergence on benign prompts) between clean and poisoned vectors is reported. Without this metric the +19% to +51% ASR gain cannot be assessed as stealthy rather than merely effective.
Authors: We agree that explicit quantitative metrics are necessary to substantiate the preservation claim and enable assessment of stealth. In the revised manuscript, we will add a new table in §4 reporting steering success rates on benign prompts, activation cosine similarities between clean and poisoned vectors, and KL divergence on held-out benign data for all eight model-attribute pairs. This will directly quantify any degradation in the intended steering behavior. revision: yes
-
Referee: [§3] §3 (attack construction): the 4-6% token substitution procedure is described at a high level, but the paper does not specify how the substituted tokens are chosen (random, refusal-correlated, or attribute-correlated) or provide an ablation showing that the primary attribute direction remains dominant after poisoning. This choice directly affects whether the primary direction is preserved or rotated.
Authors: We will expand §3 to detail the token substitution method: tokens were selected from a refusal-related vocabulary while preserving local semantic context via embedding similarity. We will also add an ablation subsection showing that the primary attribute direction remains dominant, including cosine similarities between clean and poisoned steering vectors and their projections onto the target attribute direction. revision: yes
-
Referee: [§5] §5 (defense): the refusal-direction orthogonalization recovers ~82% of the ASR gap, but the manuscript does not report the effect of this defense on the original steering task performance or on other unrelated behaviors, leaving open whether the defense trades off utility for safety.
Authors: We concur that the defense evaluation should include its impact on utility. In the revision of §5, we will report steering success rates on the original benign attributes before and after orthogonalization, along with effects on unrelated behaviors such as general next-token prediction perplexity and performance on a set of neutral prompts. revision: yes
Circularity Check
Empirical attack demonstration contains no derivation chain or self-referential reductions
full rationale
The paper reports experimental results from token-substitution attacks on steering datasets across two model families and eight attribute pairs. No equations, uniqueness theorems, ansatzes, or first-principles derivations are invoked; the central claim (poisoned vectors achieve 20-55% ASR while preserving benign steering) is evaluated directly via measured attack success rates and is not obtained by fitting parameters that are then renamed as predictions. Self-citations, if present, are not load-bearing for any mathematical step. This matches the default non-circular case for purely empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation steering vectors computed from text datasets can be added to model activations to control specific behaviors.
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Informa- tion Processing Systems, volume 37
Refusal in language models is mediated by a single direction. InAdvances in Neural Informa- tion Processing Systems, volume 37. Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tramèr. 2024. Poisoning web-scale training datasets is practical. InIEEE Sym...
2024
-
[2]
Gemma 2: Improving Open Language Models at a Practical Size
Jailbreaking black box large language models in twenty queries. InIEEE Conference on Secure and Trustworthy Machine Learning (SaTML). Gemma Team. 2024. Gemma 2: Improving open lan- guage models at a practical size.arXiv preprint arXiv:2408.00118. Laura Hanu and Unitary team. 2020. Detoxify. Github. https://github.com/unitaryai/detoxify. Evan Hubinger, Car...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
FastText.zip: Compressing text classification models
FastText.zip: Compressing text classification models.arXiv preprint arXiv:1612.03651. Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. 2017. Bag of tricks for efficient text classification. InProceedings of the 15th Confer- ence of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. Kenneth Li, ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Representation Engineering: A Top-Down Approach to AI Transparency
Jailbroken: How does LLM safety training fail? InAdvances in Neural Information Processing Systems, volume 36. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, 9 Da...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Start from the NLTK English word corpus (∼234K words)
-
[6]
Remove words flagged as toxic by Detox- ify (Hanu and Unitary team, 2020)
2020
-
[7]
Remove words flagged by Llama-3.3-70B- Instruct screening
-
[8]
almost perfect
Map surviving words to the model’s tokenizer vocabulary, keeping only single-token entries that begin with a space character (i.e., subword- complete tokens). This yields approximately 36K safe tokens for Gemma-2 and 14.6K for the Llama tokenizer. Attack pseudocode.Algorithm 1 summarises the complete attack pipeline described in Sec- tion 3.4. Steering we...
2024
-
[9]
it differs from its original text in at most nmod modifiable token positions
-
[10]
every replacement token belongs to the safe vo- cabularyV safe
-
[11]
every replacement of an original tokent belongs to its precomputed neighbor setN(t)
-
[12]
protected suffix tokens are unchanged
-
[13]
We denote the set of all feasible poisoned datasets byD
the modified text satisfies the perplexity cap, PPL(˜x)≤τ. We denote the set of all feasible poisoned datasets byD. The feasible set D is the mathematical represen- tation of the stealth constraint. It contains exactly the datasets that the attacker is allowed to output. Because the original dataset contains finitely many token positions, each position ha...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.