GRASP: Geometry-aware Residual Alignment for Scalable Pretraining Data Attribution
Pith reviewed 2026-06-27 22:19 UTC · model grok-4.3
The pith
GRASP models subset interactions in pretraining data via a quadratic geometric penalty to predict counterfactual utilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
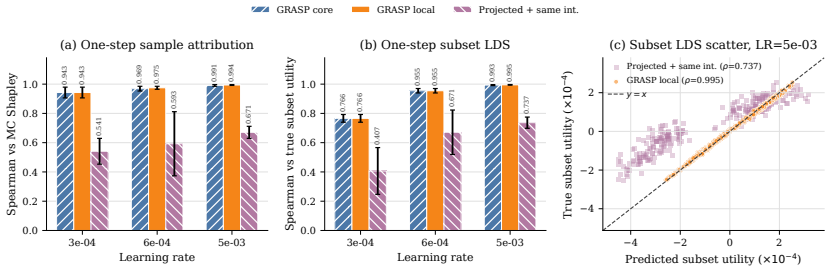
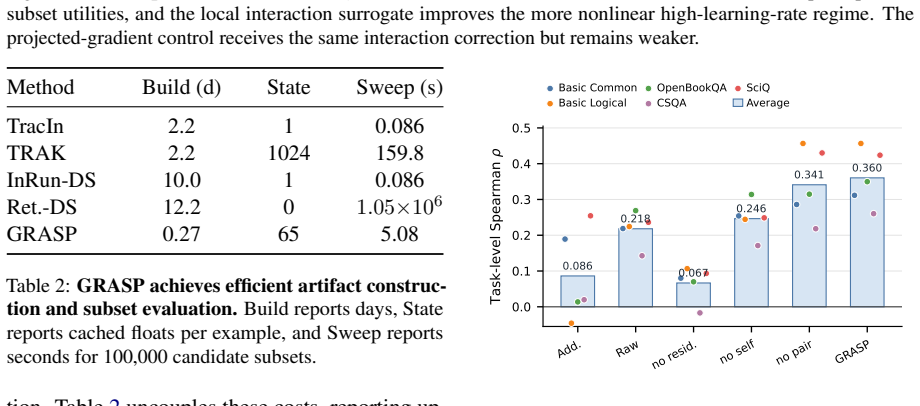
GRASP is an interaction-aware surrogate for subset-level counterfactual utility prediction. It is grounded in a theoretical smoothness lower bound that supplies a quadratic geometric penalty to model subset interactions explicitly. Low-dimensional feature sketches combined with a strictly finite lower-confidence bound selection protocol enable pretraining-scale use without oracle tuning or post-hoc adjustments. Subset-retraining evaluations show it more than doubles task-level rank correlation for counterfactual fidelity and reduces artifact construction costs by nearly an order of magnitude. The resulting scores transfer to language model curation and cross-domain vision selection.
What carries the argument
The quadratic geometric penalty derived from a smoothness lower bound, which explicitly accounts for subset interactions in the utility prediction.
If this is right
- Subset-retraining evaluations show more than double the task-level rank correlation for counterfactual subset fidelity compared with scalable baselines.
- Upfront artifact construction costs drop by nearly an order of magnitude.
- The scoring mechanism transfers directly to language model curation tasks.
- The same scores support cross-domain vision data selection.
Where Pith is reading between the lines
- The interaction modeling could support iterative refinement of pretraining corpora by repeatedly selecting complementary rather than redundant subsets.
- If the smoothness-derived penalty generalizes, similar geometric terms might improve attribution in sequential data collection settings such as active learning.
- The efficiency gains open the possibility of running attribution at the full pretraining corpus size rather than on sampled proxies.
Load-bearing premise
The quadratic geometric penalty from the smoothness lower bound together with the sketches and selection protocol accurately captures subset interactions at pretraining scale without hidden tuning.
What would settle it
A controlled experiment on a held-out large pretraining run in which GRASP-assigned subset utilities show no higher correlation with actual performance gains from retraining than existing additive baselines.
Figures

read the original abstract
Scalable data attribution methods typically assign isolated utility scores to individual training examples. This prevalent additive assumption fundamentally fails to capture critical subset dynamics, including data redundancy and complementary coverage. In this work, we reframe attribution as subset-level counterfactual utility prediction and introduce GRASP, an interaction-aware surrogate. Grounded in a theoretical smoothness lower bound, GRASP explicitly models subset interactions through a quadratic geometric penalty. To achieve pretraining-scale efficiency without relying on hidden oracle tuning, we couple low-dimensional feature sketches with a strictly finite lower-confidence bound selection protocol. Extensive subset-retraining evaluations demonstrate that GRASP decisively outperforms existing scalable baselines. It more than doubles the task-level rank correlation for counterfactual subset fidelity while reducing upfront artifact construction costs by nearly an order of magnitude. Downstream diagnostics further show that this scoring mechanism transfers to language model curation and cross-domain vision selection, establishing a robust foundation for optimizing massive pretraining corpora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GRASP, a geometry-aware residual alignment method that reframes data attribution as subset-level counterfactual utility prediction rather than isolated additive scores. It derives a quadratic geometric penalty from a theoretical smoothness lower bound, couples low-dimensional feature sketches with a strictly finite lower-confidence bound selection protocol for efficiency, and reports that extensive subset-retraining evaluations show more than double the task-level rank correlation for counterfactual fidelity while cutting upfront artifact costs by nearly an order of magnitude. The scoring is claimed to transfer to language-model curation and cross-domain vision selection.
Significance. If the central claims hold, GRASP would address a recognized limitation of additive attribution methods by explicitly modeling subset interactions at pretraining scale. The reported efficiency gains and improved rank correlation on counterfactual evaluations could have practical impact on data curation pipelines. The absence of free parameters or oracle tuning in the protocol is a positive feature if substantiated.
major comments (2)
- [Abstract] The abstract invokes a 'theoretical smoothness lower bound' and 'quadratic geometric penalty' but supplies no equations, derivation, or section reference; without these it is impossible to verify whether the penalty is derived from first principles or reduces to a fitted quantity by construction.
- [Abstract] The claim that the method 'decisively outperforms existing scalable baselines' and 'more than doubles the task-level rank correlation' rests on subset-retraining evaluations whose experimental protocol, baselines, error bars, and statistical tests are not described in the provided text, preventing assessment of whether the improvement is load-bearing or sensitive to hidden choices.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting areas where the abstract could better guide readers to the supporting material in the full manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] The abstract invokes a 'theoretical smoothness lower bound' and 'quadratic geometric penalty' but supplies no equations, derivation, or section reference; without these it is impossible to verify whether the penalty is derived from first principles or reduces to a fitted quantity by construction.
Authors: The abstract is space-constrained and therefore omits equations. The smoothness lower bound is derived in Section 3.1 from a Lipschitz-continuous utility assumption on subset counterfactuals; the quadratic geometric penalty then follows directly as Equation (5) without any fitted parameters. We will revise the abstract to include an explicit reference to Section 3.1. revision: yes
-
Referee: [Abstract] The claim that the method 'decisively outperforms existing scalable baselines' and 'more than doubles the task-level rank correlation' rests on subset-retraining evaluations whose experimental protocol, baselines, error bars, and statistical tests are not described in the provided text, preventing assessment of whether the improvement is load-bearing or sensitive to hidden choices.
Authors: The abstract summarizes results whose details appear in the full manuscript. Section 4.1 specifies the subset-retraining protocol, Section 4.2 lists the baselines, all tables and figures report error bars over five independent runs, and Appendix B contains the Wilcoxon signed-rank tests. We will add a parenthetical reference to Section 4 in the abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context contain no equations, derivations, or explicit self-citations that could be examined for reduction to inputs by construction. The mention of a 'theoretical smoothness lower bound' and 'finite lower-confidence bound selection protocol' is stated at a high level without any visible chain that equates a prediction to a fitted quantity or relies on load-bearing self-citation. Per the rules, circularity requires quotable paper text exhibiting the specific reduction; none is present here, so the derivation (if any) cannot be shown to collapse to its inputs. This is the expected honest non-finding when no load-bearing steps are isolable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 34th International Conference on Machine Learning , pages =
Understanding Black-box Predictions via Influence Functions , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[2]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[3]
2019 , howpublished =
Language Models Are Unsupervised Multitask Learners , author=. 2019 , howpublished =
2019
-
[4]
Representer Point Selection for Explaining Deep Neural Networks , url =
Yeh, Chih-Kuan and Kim, Joon and Yen, Ian En-Hsu and Ravikumar, Pradeep K , booktitle =. Representer Point Selection for Explaining Deep Neural Networks , url =
-
[5]
Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =
RelatIF: Identifying Explanatory Training Samples via Relative Influence , author =. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =. 2020 , editor =
2020
-
[6]
Proceedings of the 36th International Conference on Machine Learning , pages =
Data Shapley: Equitable Valuation of Data for Machine Learning , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[7]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , month = oct #. 2018 , address =. doi:10.18653/v1/D18-1260 , pages =
-
[8]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. CoRR , volume =. 2018 , url =. 1803.05457 , timestamp =
Pith/arXiv arXiv 2018
-
[9]
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan , editor =. Proceedings of the 2019 Conference of the North. 2019 , address =. doi:10.18653/v1/N19-1421 , pages =
-
[10]
Proceedings of the AAAI conference on artificial intelligence , volume =
Piqa: Reasoning about physical commonsense in natural language , author =. Proceedings of the AAAI conference on artificial intelligence , volume =
-
[11]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. Journal of Machine Learning Research , year =
-
[12]
Data Shapley in One Training Run , url =
Wang, Jiachen (Tianhao) and Mittal, Prateek and Song, Dawn and Jia, Ruoxi , booktitle =. Data Shapley in One Training Run , url =
-
[13]
Estimating Training Data Influence by Tracing Gradient Descent , url =
Pruthi, Garima and Liu, Frederick and Kale, Satyen and Sundararajan, Mukund , booktitle =. Estimating Training Data Influence by Tracing Gradient Descent , url =
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Scaling up influence functions , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
2023 , eprint=
Studying Large Language Model Generalization with Influence Functions , author=. 2023 , eprint=
2023
-
[16]
2023 , eprint=
TRAK: Attributing Model Behavior at Scale , author=. 2023 , eprint=
2023
-
[17]
Proceedings of the 40th International Conference on Machine Learning , pages =
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[18]
DataInf: Efficiently Estimating Data Influence in LoRA-tuned LLMs and Diffusion Models , url =
Kwon, Yongchan and Wu, Eric and Wu, Kevin and Zou, James Y , booktitle =. DataInf: Efficiently Estimating Data Influence in LoRA-tuned LLMs and Diffusion Models , url =
-
[19]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Xia, Mengzhou and Malladi, Sadhika and Gururangan, Suchin and Arora, Sanjeev and Chen, Danqi , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[20]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , url =
Penedo, Guilherme and Kydl\'. The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , url =. Advances in Neural Information Processing Systems , doi =
-
[21]
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data Only , url =
Penedo, Guilherme and Malartic, Quentin and Hesslow, Daniel and Cojocaru, Ruxandra and Alobeidli, Hamza and Cappelli, Alessandro and Pannier, Baptiste and Almazrouei, Ebtesam and Launay, Julien , booktitle =. The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data Only , url =
-
[22]
and Carmon, Yair and Dave, Achal and Schmidt, Ludwig and Shankar, Vaishaal , booktitle =
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and Bansal, Hritik and Guha, Etash and Keh, Sedrick and Arora, Kushal and Garg, Saurabh and Xin, Rui and Muennighoff, Niklas and Heckel, Reinhard and Mercat, Jean and Chen, Mayee and Gururangan, Suchin and Wortsman, Mitchell and Albalak, Alon and Bitton, Yona...
-
[23]
Proceedings of the 39th International Conference on Machine Learning , pages =
Datamodels: Understanding Predictions with Data and Data with Predictions , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[24]
The Probabilistic Relevance Framework: BM25 and Beyond,
Robertson, Stephen and Zaragoza, Hugo , title =. Foundations and Trends in Information Retrieval , volume =. 2009 , month =. doi:10.1561/1500000019 , url =
-
[25]
Findings of the Association for Computational Linguistics: NAACL 2025 , month = apr, year =
Gu, Yuling and Tafjord, Oyvind and Kuehl, Bailey and Haddad, Dany and Dodge, Jesse and Hajishirzi, Hannaneh , editor =. Findings of the Association for Computational Linguistics: NAACL 2025 , month = apr, year =. doi:10.18653/v1/2025.findings-naacl.282 , pages =
-
[26]
2026 , eprint=
Olmo 3 , author=. 2026 , eprint=
2026
-
[27]
What s In My Big Data? , url =
Elazar, Yanai and Bhagia, Akshita and Magnusson, Ian and Ravichander, Abhilasha and Schwenk, Dustin and Suhr, Alane and Walsh, Pete and Groeneveld, Dirk and Soldaini, Luca and Singh, Sameer and Hajishirzi, Hannaneh and Smith, Noah and Dodge, Jesse , booktitle =. What s In My Big Data? , url =
-
[28]
Scalable Influence and Fact Tracing for Large Language Model Pretraining , url =
Chang, Tyler and Rajagopal, Dheeraj and Bolukbasi, Tolga and Dixon, Lucas and Tenney, Ian , booktitle =. Scalable Influence and Fact Tracing for Large Language Model Pretraining , url =
-
[29]
Crowdsourcing Multiple Choice Science Questions , author =. Proceedings of the 3rd Workshop on Noisy User-generated Text , month = sep, year =. doi:10.18653/v1/W17-4413 , pages =
-
[30]
Mathematical Programming , volume =
An Analysis of Approximations for Maximizing Submodular Set Functions---I , author =. Mathematical Programming , volume =. 1978 , doi =
1978
-
[31]
Borgwardt and Malte J
Arthur Gretton and Karsten M. Borgwardt and Malte J. Rasch and Bernhard Sch. A Kernel Two-Sample Test , journal =. 2012 , volume =
2012
-
[32]
Random Structures & Algorithms , volume =
Dasgupta, Sanjoy and Gupta, Anupam , title =. Random Structures & Algorithms , volume =. doi:https://doi.org/10.1002/rsa.10073 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/rsa.10073 , year =
-
[33]
Journal of Computer and System Sciences , volume =
Database-friendly random projections: Johnson-Lindenstrauss with binary coins , author =. Journal of Computer and System Sciences , volume =. 2003 , note =. doi:https://doi.org/10.1016/S0022-0000(03)00025-4 , url =
-
[34]
Optimizing Neural Networks with
Martens, James and Grosse, Roger , booktitle =. Optimizing Neural Networks with. 2015 , url =
2015
-
[35]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Deep Residual Learning for Image Recognition , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =. 2016 , doi =
2016
-
[36]
2009 , doi =
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle =. 2009 , doi =
2009
-
[37]
2009 , url =
Learning Multiple Layers of Features from Tiny Images , author =. 2009 , url =
2009
-
[38]
Journal of the American Statistical Association , volume =
Probability Inequalities for Sums of Bounded Random Variables , author =. Journal of the American Statistical Association , volume =. 1963 , doi =
1963
-
[39]
Organize the Web: Constructing Domains Enhances Pre-Training Data Curation , author =. 2025 , eprint =. doi:10.48550/arXiv.2502.10341 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.