α-PFN: Fast Entropy Search via In-Context Learning
Pith reviewed 2026-06-27 22:21 UTC · model grok-4.3
The pith
A two-stage PFN learns to approximate entropy search acquisition functions with one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a two-stage amortization strategy that learns to approximate entropy search-based acquisition functions using Prior-data Fitted Networks (PFNs) in a single forward pass. A first PFN is trained to be conditioned on information about the optima; second, the α-PFN is trained to predict the expected information gain by training on information gains measured with the first PFN. The α-PFN offers a flexible learned approximation, which replaces the complex heuristic approximations with a single forward pass per candidate, enabling rapid and extensible acquisition evaluation.
What carries the argument
The α-PFN, a second Prior-data Fitted Network trained to output expected information gain directly from a first PFN's representation of the optimum.
If this is right
- Entropy search variants become evaluable in a single forward pass instead of Monte Carlo sampling.
- Acquisition evaluation accelerates by more than 50 times across tested entropy search methods.
- The same learned approximator remains competitive with state-of-the-art implementations on both synthetic and real-world tasks.
- Acquisition functions can be extended or swapped without re-deriving new heuristic approximations.
Where Pith is reading between the lines
- The same two-stage pattern could be applied to amortize other expensive acquisition functions or decision-theoretic quantities.
- Because the approximator is a forward pass, it becomes feasible to embed entropy search inside inner loops of larger algorithms that previously avoided it for speed reasons.
- If the PFN training distribution is broadened, the method might transfer to new problem classes without retraining the acquisition model from scratch.
Load-bearing premise
Networks trained only on synthetic or prior data will output sufficiently accurate expected information gain values on the actual optimization tasks.
What would settle it
An experiment on a new real-world benchmark where the α-PFN version of entropy search produces worse final optimization performance than a standard Monte Carlo implementation despite the speed gain.
Figures
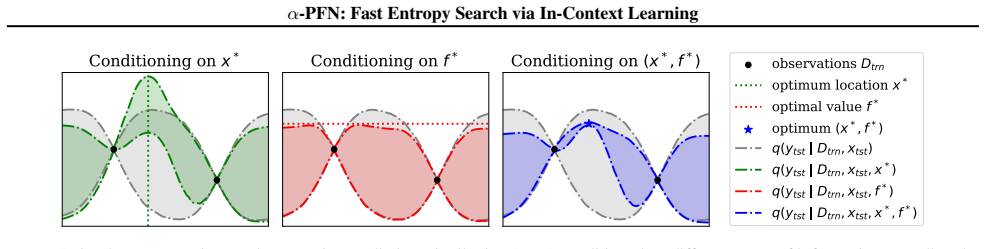
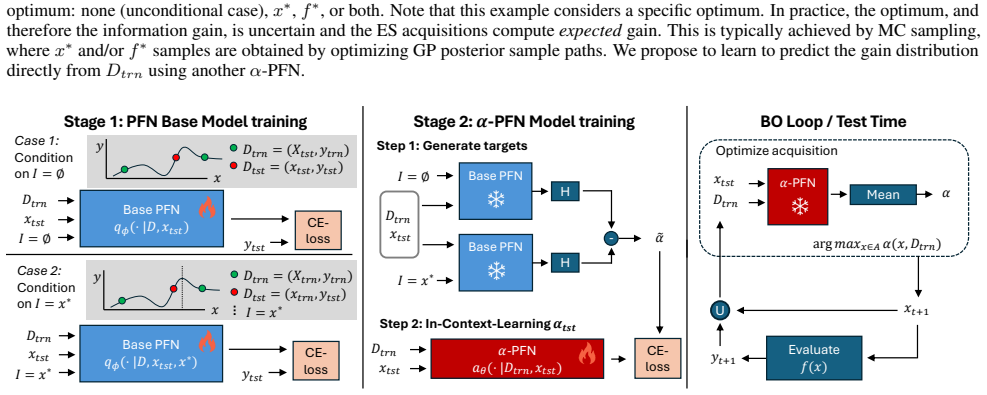
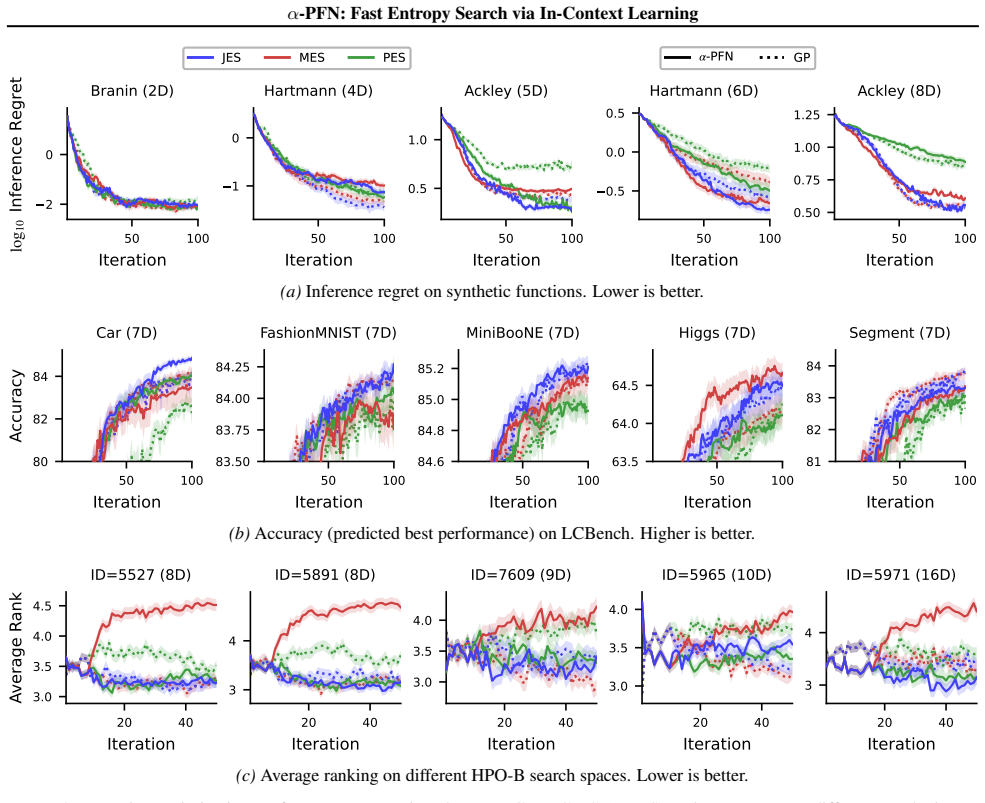
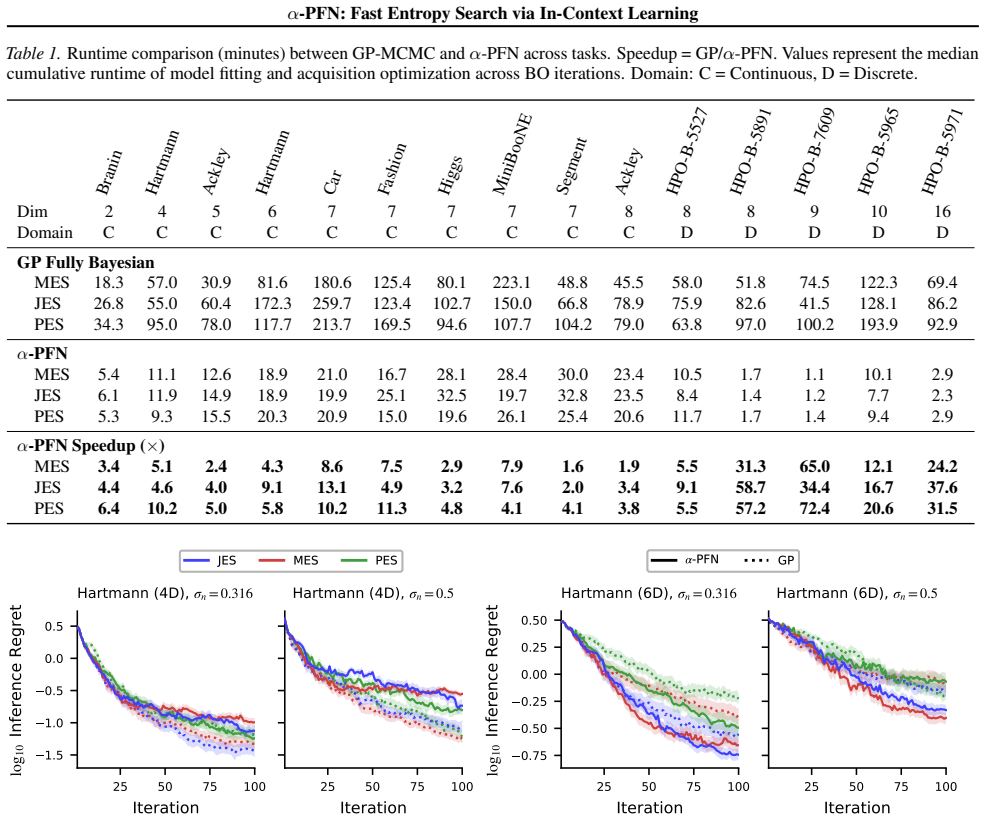

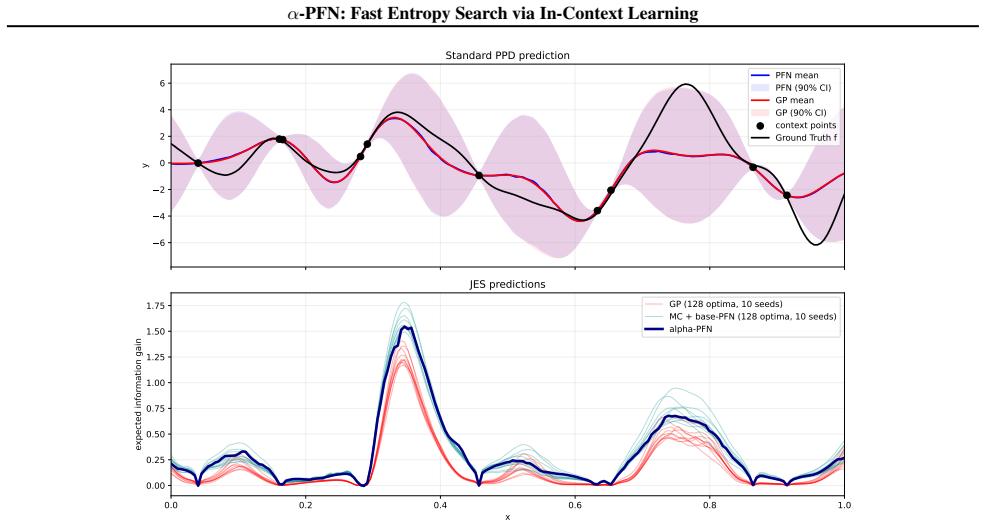
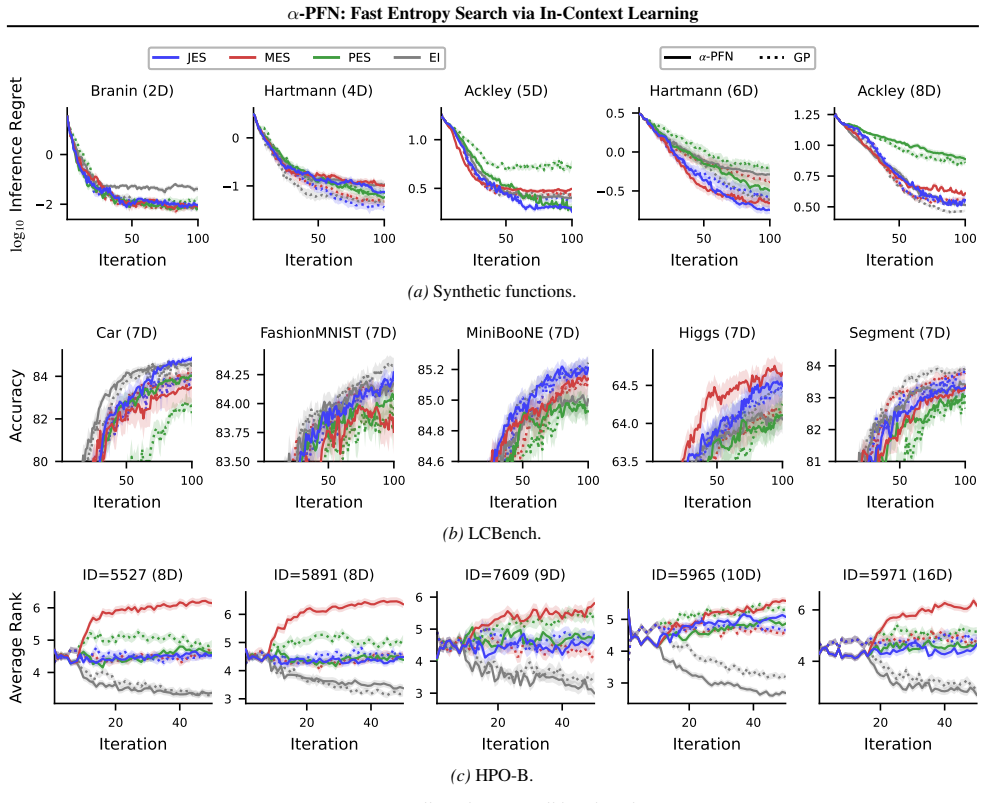

read the original abstract
Information-theoretic acquisition functions such as Entropy Search (ES) offer a principled exploration-exploitation framework for Bayesian optimization (BO). However, their practical implementation relies on complicated and slow approximations, i.e., a Monte Carlo estimation of the information gain. This complexity can introduce numerical errors and requires specialized, hand-crafted implementations. We propose a two-stage amortization strategy that learns to approximate entropy search-based acquisition functions using Prior-data Fitted Networks (PFNs) in a single forward pass. A first PFN is trained to be conditioned on information about the optima; second, the $\alpha$-PFN is trained to predict the expected information gain by training on information gains measured with the first PFN. The $\alpha$-PFN offers a flexible learned approximation, which replaces the complex heuristic approximations with a single forward pass per candidate, enabling rapid and extensible acquisition evaluation. Empirically, our approach is competitive with state-of-the-art entropy search implementations on synthetic and real-world benchmarks, while accelerating the different entropy search variants across all our experiments, with speed ups over 50x. Source code: https://github.com/automl/AlphaPFN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes α-PFN, a two-stage amortization strategy using Prior-data Fitted Networks (PFNs) to approximate entropy search acquisition functions in Bayesian optimization. A first PFN is trained conditioned on information about the optima; a second α-PFN is then trained to predict expected information gain from measurements produced by the first. The resulting model replaces complex Monte Carlo or heuristic approximations with a single forward pass per candidate point. The central empirical claim is that the method is competitive with state-of-the-art entropy search implementations on synthetic and real-world benchmarks while delivering speed-ups exceeding 50×.
Significance. If the performance claims hold under rigorous validation, the work would meaningfully advance practical Bayesian optimization by rendering information-theoretic acquisition functions computationally tractable. The two-stage PFN construction demonstrates a flexible, extensible learned surrogate for expected information gain and could serve as a template for amortizing other expensive BO components.
major comments (2)
- [Abstract] Abstract: the claim of empirical competitiveness and >50× speed-ups is load-bearing for the paper’s contribution, yet the abstract (and the provided material) supplies no information on training-data distribution, benchmark tasks, number of runs, error bars, or statistical tests. Without these details it is impossible to determine whether the learned approximation introduces bias or performance degradation relative to existing ES variants.
- The central modeling assumption—that a PFN trained on synthetic or prior data will produce sufficiently accurate EIG approximations that generalize to the target optimization tasks without systematic bias—is stated but not subjected to targeted stress tests (e.g., out-of-distribution task transfer or comparison against the exact EIG on low-dimensional problems). This assumption directly underpins the competitiveness claim.
minor comments (1)
- The source-code link is provided; this is helpful for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and commit to revisions that improve clarity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of empirical competitiveness and >50× speed-ups is load-bearing for the paper’s contribution, yet the abstract (and the provided material) supplies no information on training-data distribution, benchmark tasks, number of runs, error bars, or statistical tests. Without these details it is impossible to determine whether the learned approximation introduces bias or performance degradation relative to existing ES variants.
Authors: We agree the abstract is too terse on experimental details. The manuscript body specifies training on data drawn from standard GP priors, evaluation across synthetic test functions (Branin, Hartmann6, etc.) and real-world hyperparameter optimization tasks, with all results reported as means over 10–20 independent runs together with standard-error bars and direct comparisons to existing ES implementations. We will expand the abstract to include a concise statement of the benchmark classes, run count, and presence of variability measures so that the competitiveness claim can be assessed at a glance. revision: yes
-
Referee: [—] The central modeling assumption—that a PFN trained on synthetic or prior data will produce sufficiently accurate EIG approximations that generalize to the target optimization tasks without systematic bias—is stated but not subjected to targeted stress tests (e.g., out-of-distribution task transfer or comparison against the exact EIG on low-dimensional problems). This assumption directly underpins the competitiveness claim.
Authors: The existing experiments already probe generalization by evaluating on synthetic and real-world tasks whose characteristics differ from the training prior; where dimensionality permits, we also report agreement with exact EIG values. Nevertheless, we accept that dedicated out-of-distribution transfer experiments and additional low-dimensional exact-EIG comparisons would make the validation more explicit. We will add a short subsection summarizing these checks and any observed approximation bias. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes a two-stage training procedure for PFNs where the first network is trained on synthetic data conditioned on optima information, and the α-PFN is then trained to predict expected information gain using outputs measured from the first PFN. This is the explicit design of the learned approximator, not a reduction of a claimed derivation to its inputs by construction. No mathematical first-principles result, uniqueness theorem, or ansatz is derived or smuggled via self-citation. Central claims concern empirical speedups and competitiveness on benchmarks, which are externally verifiable and not forced by the training process itself. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- PFN network weights (stage 1 and stage 2)
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Meta-Learning Acquisition Functions for Transfer Learning in Bayesian Optimization , author=. International Conference on Learning Representations , year=
-
[2]
Nature , volume=
Publishing: Credit where credit is due , author=. Nature , volume=. 2014 , publisher=
2014
-
[3]
International Conference on Machine Learning , pages=
Learning to learn without gradient descent by gradient descent , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[4]
International Conference on Artificial Intelligence and Statistics , pages=
Fast Bayesian Optimization of Machine Learning Hyperparameters on Large Datasets , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2017 , organization=
2017
-
[5]
Towards global optimization , pages=
The application of Bayesian methods for seeking the extremum , author=. Towards global optimization , pages=
-
[6]
International Conference on Machine Learning , year=
Distribution transformers: Fast approximate Bayesian inference with on-the-fly prior adaptation , author=. International Conference on Machine Learning , year=
-
[7]
ICLR , year=
Meta-Learning Acquisition Functions for Transfer Learning in Bayesian Optimization , author=. ICLR , year=
-
[8]
Advances in Neural Information Processing Systems , pages=
End-to-end meta-bayesian optimisation with transformer neural processes , author=. Advances in Neural Information Processing Systems , pages=
-
[9]
Advances in neural information processing systems , pages=
Local latent space bayesian optimization over structured inputs , author=. Advances in neural information processing systems , pages=
-
[10]
Uncertainty in Artificial Intelligence , pages=
Multi-objective bayesian optimization over high-dimensional search spaces , author=. Uncertainty in Artificial Intelligence , pages=. 2022 , organization=
2022
-
[11]
Advances in neural information processing systems , pages=
Scalable global optimization via local Bayesian optimization , author=. Advances in neural information processing systems , pages=
-
[12]
Rosen Ting-Ying Yu and Cyril Picard and Faez Ahmed , booktitle=
-
[13]
, author=
The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. , author=. Journal of Machine Learning Research , pages=
-
[14]
International Conference on Machine Learning , pages=
Vanilla bayesian optimization performs great in high dimensions , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[15]
International Conference on Artificial Intelligence and Statistics , pages=
Amortized probabilistic conditioning for optimization, simulation and inference , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2025 , organization=
2025
-
[16]
Journal of Machine Learning Research , volume=
Pre-trained Gaussian processes for Bayesian optimization , author=. Journal of Machine Learning Research , volume=
-
[17]
International conference on machine learning , pages=
Neural contextual bandits with ucb-based exploration , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[18]
International Conference on Machine Learning , pages=
Infonet: neural estimation of mutual information without test-time optimization , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[19]
ACM SIGKDD Explorations Newsletter , volume=
OpenML: networked science in machine learning , author=. ACM SIGKDD Explorations Newsletter , volume=. 2014 , publisher=
2014
-
[20]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
Lucas Zimmer and Marius Lindauer and Frank Hutter , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[21]
Advances in neural information processing systems (Datasets and Benchmarks Track) , publisher =
Sebastian Pineda. Advances in neural information processing systems (Datasets and Benchmarks Track) , publisher =
-
[22]
Advances in Neural Information Processing Systems , volume=
Unexpected improvements to expected improvement for bayesian optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Journal of Machine Learning Research , pages=
Gibbon: General-purpose information-based bayesian optimisation , author=. Journal of Machine Learning Research , pages=
-
[24]
Expert Systems with Applications , volume=
Parallel predictive entropy search for multi-objective Bayesian optimization with constraints applied to the tuning of machine learning algorithms , author=. Expert Systems with Applications , volume=. 2023 , publisher=
2023
-
[25]
Advances in Neural Information Processing Systems , volume=
Joint entropy search for multi-objective bayesian optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Journal of Global Optimization , volume=
An informational approach to the global optimization of expensive-to-evaluate functions , author=. Journal of Global Optimization , volume=. 2009 , publisher=
2009
-
[27]
2006 , publisher=
Gaussian processes for machine learning , author=. 2006 , publisher=
2006
-
[28]
Advances in Neural Information Processing Systems , pages=
Towards learning universal hyperparameter optimizers with transformers , author=. Advances in Neural Information Processing Systems , pages=
-
[29]
and Daulton, Samuel and Letham, Benjamin and Wilson, Andrew Gordon and Bakshy, Eytan , booktitle =
Balandat, Maximilian and Karrer, Brian and Jiang, Daniel R. and Daulton, Samuel and Letham, Benjamin and Wilson, Andrew Gordon and Bakshy, Eytan , booktitle =
-
[30]
Optimization techniques IFIP technical conference: Novosibirsk , pages=
On Bayesian methods for seeking the extremum , author=. Optimization techniques IFIP technical conference: Novosibirsk , pages=. 1975 , organization=
1975
-
[31]
2010 , booktitle =
Srinivas, Niranjan and Krause, Andreas and Kakade, Sham and Seeger, Matthias , title =. 2010 , booktitle =
2010
-
[32]
arXiv preprint arXiv:2202.13597 , year=
Rectified max-value entropy search for Bayesian optimization , author=. arXiv preprint arXiv:2202.13597 , year=
-
[33]
Thirty-seventh Conference on Neural Information Processing Systems , publisher =
Self-Correcting Bayesian Optimization through Bayesian Active Learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , publisher =. 2023 , pages=
2023
-
[34]
AutoML Conference 2024 (Workshop Track) , year=
From Epoch to Sample Size: Developing New Data-driven Priors for Learning Curve Prior-Fitted Networks , author=. AutoML Conference 2024 (Workshop Track) , year=
2024
-
[35]
Multi-fidelity
Takeno, Shion and Fukuoka, Hitoshi and Tsukada, Yuhki and Koyama, Toshiyuki and Shiga, Motoki and Takeuchi, Ichiro and Karasuyama, Masayuki , booktitle =. Multi-fidelity. 2020 , publisher =
2020
-
[36]
International Conference on Machine Learning , pages =
Sequential and Parallel Constrained Max-value Entropy Search via Information Lower Bound , author =. International Conference on Machine Learning , pages =. 2022 , publisher =
2022
-
[37]
International Conference on Machine Learning , pages=
A general recipe for likelihood-free Bayesian optimization , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[38]
Journal of Machine Learning Research , volume=
Bayesian optimization for likelihood-free inference of simulator-based statistical models , author=. Journal of Machine Learning Research , volume=
-
[39]
arXiv preprint arXiv:2307.03565 , year=
MALIBO: Meta-learning for likelihood-free Bayesian optimization , author=. arXiv preprint arXiv:2307.03565 , year=
-
[40]
Nature , pages=
Accurate predictions on small data with a tabular foundation model , author=. Nature , pages=. 2025 , publisher=
2025
-
[41]
Advances in neural information processing systems , pages=
Random features for large-scale kernel machines , author=. Advances in neural information processing systems , pages=. 2007 , publisher =
2007
-
[42]
Proceedings of the IEEE , pages=
Taking the human out of the loop: A review of Bayesian optimization , author=. Proceedings of the IEEE , pages=. 2015 , publisher=
2015
-
[43]
International Conference on Machine Learning , pages=
Pfns4bo: In-context learning for bayesian optimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[44]
Advances in Neural Information Processing Systems , pages=
Joint entropy search for maximally-informed Bayesian optimization , author=. Advances in Neural Information Processing Systems , pages=
-
[45]
Advances in neural information processing systems , pages=
Predictive entropy search for efficient global optimization of black-box functions , author=. Advances in neural information processing systems , pages=. 2014 , publisher =
2014
-
[46]
International Conference on Machine Learning , pages=
Max-value entropy search for efficient Bayesian optimization , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[47]
and Archambeau, Cedric and Ramos, Fabio , booktitle =
Tiao, Louis C and Klein, Aaron and Seeger, Matthias W and Bonilla, Edwin V. and Archambeau, Cedric and Ramos, Fabio , booktitle =. 2021 , publisher =
2021
-
[48]
International Conference on Learning Representations , year=
Transformers Can Do Bayesian Inference , author=. International Conference on Learning Representations , year=
-
[49]
, author=
Entropy search for information-efficient global optimization. , author=. Journal of Machine Learning Research , pages =. 2012 , publisher =
2012
-
[50]
The Journal of Machine Learning Research , pages=
GPstuff: Bayesian modeling with Gaussian processes , author=. The Journal of Machine Learning Research , pages=. 2013 , publisher=
2013
-
[51]
2001 , school=
A family of algorithms for approximate Bayesian inference , author=. 2001 , school=
2001
-
[52]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Tabpfn: A transformer that solves small tabular classification problems in a second , author=. arXiv preprint arXiv:2207.01848 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Advances in neural information processing systems , pages=
Practical bayesian optimization of machine learning algorithms , author=. Advances in neural information processing systems , pages=. 2012 , publisher =
2012
-
[54]
Hyperparameter Optimization
Feurer, Matthias and Hutter, Frank. Hyperparameter Optimization. Automated Machine Learning: Methods, Systems, Challenges. 2019
2019
-
[55]
Summer school on machine learning , pages=
Gaussian processes in machine learning , author=. Summer school on machine learning , pages=. 2003 , publisher=
2003
-
[56]
International conference on machine learning , pages=
Conditional neural processes , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[57]
and Casella, George , title =
Robert, Christian P. and Casella, George , title =. 2005 , publisher =
2005
-
[58]
International Conference on Machine Learning , pages=
In-Context Freeze-Thaw Bayesian Optimization for Hyperparameter Optimization , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[59]
Advances in Neural Information Processing Systems , pages=
Forecastpfn: Synthetically-trained zero-shot forecasting , author=. Advances in Neural Information Processing Systems , pages=. 2023 , publisher =
2023
-
[60]
Advances in Neural Information Processing Systems , pages=
Efficient bayesian learning curve extrapolation using prior-data fitted networks , author=. Advances in Neural Information Processing Systems , pages=
-
[61]
Advances in Neural Information Processing Systems , pages=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , pages=
-
[62]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Efficient Bayesian Experiment Design with Equivariant Networks , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[63]
Advances in Neural Information Processing Systems , year=
Informed Initialization for Bayesian Optimization and Active Learning , author=. Advances in Neural Information Processing Systems , year=
-
[64]
Huang, Daolang and Wen, Xinyi and Bharti, Ayush and Kaski, Samuel and Acerbi, Luigi , booktitle=
-
[65]
International Conference on Artificial Intelligence and Statistics , year=
Amortized Safe Active Learning for Real-Time Data Acquisition: Pretrained Neural Policies from Simulated Nonparametric Functions , author=. International Conference on Artificial Intelligence and Statistics , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.