Self-evolving LLM agents with in-distribution Optimization
Pith reviewed 2026-06-27 22:16 UTC · model grok-4.3
The pith
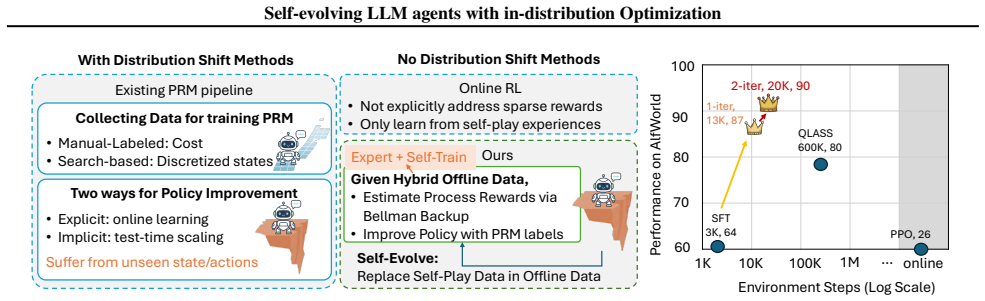
Q-Evolve enables stable self-evolution of LLM agents by co-evolving process rewards and policy in one in-distribution loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
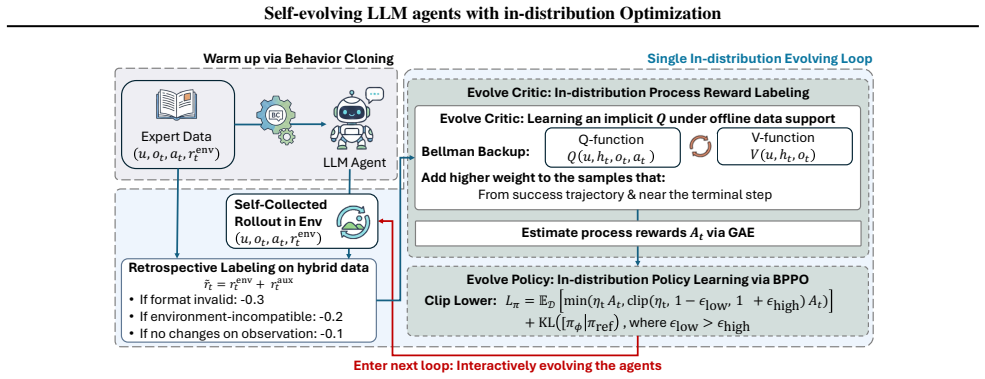
Q-Evolve unifies automatic process-reward labeling and policy learning within a principled in-distribution reinforcement learning paradigm. In each evolving iteration, the method learns an in-distribution critic from a hybrid off-policy dataset that combines expert demonstrations with agent-generated trajectories, stabilizing Bellman backups in sparse-reward settings via a weighted Implicit Q-Learning objective. The learned value function is then used to derive step-wise process rewards through advantage estimation, enabling dense and reliable supervision without environment backtracking or human annotation. Leveraging these signals, behavior-proximal policy optimization evolves the agent ov
What carries the argument
The in-distribution critic learned via weighted Implicit Q-Learning on hybrid expert and agent trajectories, which generates advantage estimates as process rewards for subsequent policy optimization.
If this is right
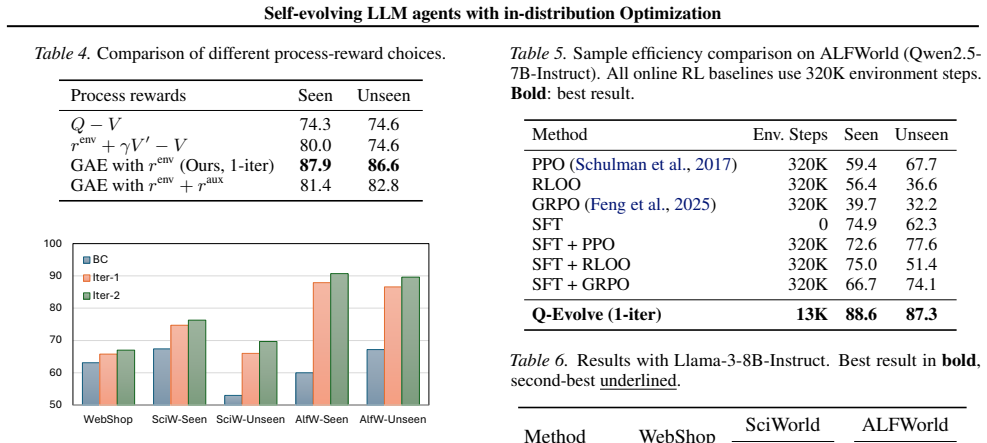
- LLM agents achieve better task performance on AlfWorld, WebShop, and ScienceWorld compared to strong baselines.
- The method improves sample efficiency and robustness in sparse-reward long-horizon decision making.
- Self-evolution proceeds iteratively without increasing distribution shift between data and policy.
- Process-level supervision is generated automatically without human annotation or backtracking.
- Stable co-evolution of supervision and policy occurs within the shared in-distribution learning loop.
Where Pith is reading between the lines
- Extending the loop to more iterations could yield further gains if the critic remains accurate.
- The framework might reduce the need for large expert datasets by bootstrapping from initial demonstrations.
- Similar in-distribution objectives could stabilize training for other sparse-reward agent tasks beyond the tested environments.
Load-bearing premise
The hybrid off-policy dataset combining expert demonstrations and agent-generated trajectories suffices to stabilize the critic's Bellman backups under sparse rewards using weighted Implicit Q-Learning.
What would settle it
If applying Q-Evolve across multiple iterations on ScienceWorld results in no improvement or degradation in task success rates after the initial training, the stability of the self-evolution process would be falsified.
Figures

read the original abstract
Large Language Models (LLMs) have recently emerged as powerful controllers for interactive agents in complex environments, yet training them to perform reliable long-horizon decision making remains a fundamental challenge. A key difficulty lies in credit assignment: agents often receive delayed rewards only at the end of episodes. In this paper, we propose Q-Evolve, a self-evolving framework for LLM agents that unifies automatic process-reward labeling and policy learning within a principled in-distribution reinforcement learning paradigm. In each evolving iteration, our method learns an in-distribution critic from a hybrid off-policy dataset that combines expert demonstrations with agent-generated trajectories, stabilizing Bellman backups in sparse-reward settings via a weighted Implicit Q-Learning objective. The learned value function is then used to derive step-wise process rewards through advantage estimation, enabling dense and reliable supervision without environment backtracking or human annotation. Leveraging these signals, we perform behavior-proximal policy optimization that evolves the agent over the data used for process reward labeling, allowing iterative self-improvement without exacerbating distribution shift. We evaluate our method on AlfWorld, WebShop, and ScienceWorld, showing Q-Evolve outperforms strong baselines in sample efficiency, robustness, and overall task performance. Our results demonstrate that stable agent self-evolution is achievable through the co-evolution of process-level supervision and policy, both grounded within a shared in-distribution learning loop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Q-Evolve, a self-evolving framework for LLM agents that unifies automatic process-reward labeling and policy learning in an in-distribution RL paradigm. It learns an in-distribution critic from a hybrid off-policy dataset (expert demonstrations plus agent-generated trajectories) using a weighted Implicit Q-Learning objective to stabilize Bellman backups in sparse-reward settings, derives step-wise process rewards via advantage estimation, and performs behavior-proximal policy optimization to enable iterative self-improvement without exacerbating distribution shift. Experiments on AlfWorld, WebShop, and ScienceWorld report outperformance over strong baselines in sample efficiency, robustness, and task performance.
Significance. If the claimed stabilization of the critic and reliable advantage-based process rewards hold, the work would offer a concrete mechanism for dense supervision in long-horizon LLM agent tasks without human annotation or environment backtracking, potentially advancing sample-efficient self-evolution in interactive environments.
major comments (2)
- [Abstract] Abstract (critic-learning paragraph): The central claim that the hybrid off-policy dataset plus weighted IQL produces stable critics whose advantage estimates yield reliable process rewards is load-bearing for the self-evolution loop, yet the abstract provides no equations, weighting scheme details, or ablations showing that extrapolation error is controlled in high-dimensional language state spaces; this leaves open whether the reported gains on the three environments are driven by this mechanism or by other components.
- [Abstract] Abstract (process-reward and policy paragraphs): The value function is learned from the same trajectories later used for policy updates, creating a potential circular dependence; without an external benchmark, parameter-free derivation, or explicit separation of critic training data from the evolving policy data, it is unclear whether the in-distribution loop truly breaks the circularity or merely masks it.
minor comments (1)
- [Abstract] The abstract refers to 'each evolving iteration' and 'co-evolution' without specifying the number of iterations, convergence criteria, or how the hybrid dataset is refreshed between iterations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the abstract to improve clarity on the central mechanisms while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract (critic-learning paragraph): The central claim that the hybrid off-policy dataset plus weighted IQL produces stable critics whose advantage estimates yield reliable process rewards is load-bearing for the self-evolution loop, yet the abstract provides no equations, weighting scheme details, or ablations showing that extrapolation error is controlled in high-dimensional language state spaces; this leaves open whether the reported gains on the three environments are driven by this mechanism or by other components.
Authors: The abstract is a high-level summary; the weighted IQL objective, hybrid dataset construction, and extrapolation control via in-distribution training are formalized in Section 3.2 with the explicit loss and weighting scheme. Section 5.3 contains ablations isolating the critic component, confirming that performance gains derive from stabilized advantage estimates. To address the concern directly in the abstract, we will add a concise clause referencing the hybrid off-policy dataset and weighted IQL stabilization. revision: yes
-
Referee: [Abstract] Abstract (process-reward and policy paragraphs): The value function is learned from the same trajectories later used for policy updates, creating a potential circular dependence; without an external benchmark, parameter-free derivation, or explicit separation of critic training data from the evolving policy data, it is unclear whether the in-distribution loop truly breaks the circularity or merely masks it.
Authors: The design separates the fixed hybrid dataset (expert demonstrations plus initial trajectories) used for each iteration's critic training from subsequent policy updates; behavior-proximal optimization then constrains the policy to this distribution before new data collection. This explicit separation and anchoring via expert data is detailed in Sections 3 and 4. We will revise the abstract to state the separation between critic training data and evolving policy data, clarifying how the in-distribution loop mitigates circularity. revision: yes
Circularity Check
No significant circularity in the Q-Evolve derivation chain
full rationale
The paper describes a standard RL pipeline: a critic is fit via weighted IQL on a hybrid off-policy dataset, advantage estimates yield process rewards, and behavior-proximal policy optimization is performed on the same data distribution. No equation or step reduces by construction to its own inputs (no self-definitional loops, no fitted parameter renamed as prediction, no load-bearing self-citation). Performance claims rest on external benchmark results (AlfWorld, WebShop, ScienceWorld) rather than tautological fits. The in-distribution loop is an explicit design choice to limit shift, but this does not create circular dependence between critic and reported gains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trial and Error: Exploration-Based Trajectory Optimization of LLM Agents
Song, Yifan and Yin, Da and Yue, Xiang and Huang, Jie and Li, Sujian and Lin, Bill Yuchen. Trial and Error: Exploration-Based Trajectory Optimization of LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.409
-
[2]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Agent Planning with World Knowledge Model , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[3]
K now A gent: Knowledge-Augmented Planning for LLM -Based Agents
Zhu, Yuqi and Qiao, Shuofei and Ou, Yixin and Deng, Shumin and Lyu, Shiwei and Shen, Yue and Liang, Lei and Gu, Jinjie and Chen, Huajun and Zhang, Ningyu. K now A gent: Knowledge-Augmented Planning for LLM -Based Agents. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.205
-
[4]
MPO : Boosting LLM Agents with Meta Plan Optimization
Xiong, Weimin and Song, Yifan and Dong, Qingxiu and Zhao, Bingchan and Song, Feifan and XWang and Li, Sujian. MPO : Boosting LLM Agents with Meta Plan Optimization. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.210
-
[5]
The Eleventh International Conference on Learning Representations , year=
Behavior Proximal Policy Optimization , author=. The Eleventh International Conference on Learning Representations , year=
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Large Language Models Are Neurosymbolic Reasoners , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2024 , month=. doi:10.1609/aaai.v38i16.29754 , number=
-
[7]
The Thirteenth International Conference on Learning Representations , year=
Scaling Autonomous Agents via Automatic Reward Modeling And Planning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[8]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[9]
A survey of large language models , author=
-
[10]
Nature medicine , volume=
Large language models in medicine , author=. Nature medicine , volume=. 2023 , publisher=
2023
-
[11]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[12]
OpenVLA: An Open-Source Vision-Language-Action Model , author=
-
[13]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Re-ReST: Reflection-Reinforced Self-Training for Language Agents , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[14]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[16]
arXiv preprint arXiv:2409.00872 , year=
Self-evolving Agents with reflective and memory-augmented abilities , author=. arXiv preprint arXiv:2409.00872 , year=
-
[17]
arXiv preprint arXiv:2401.13996 , year=
Investigate-consolidate-exploit: A general strategy for inter-task agent self-evolution , author=. arXiv preprint arXiv:2401.13996 , year=
-
[18]
arXiv preprint arXiv:2508.04700 , year=
Seagent: Self-evolving computer use agent with autonomous learning from experience , author=. arXiv preprint arXiv:2508.04700 , year=
-
[19]
WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning , author=
-
[20]
2025 , url=
Yifu Guo and Jiaye Lin and Huacan Wang and Yuzhen Han and Sen Hu and Ziyi Ni and Licheng Wang and Mingguang Chen , booktitle=. 2025 , url=
2025
-
[21]
2025 , eprint=
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory , author=. 2025 , eprint=
2025
-
[22]
Advances in Neural Information Processing Systems , volume=
Richelieu: Self-evolving llm-based agents for ai diplomacy , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Transactions on Machine Learning Research , year =
A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence , author =. Transactions on Machine Learning Research , year =
-
[24]
International Conference on Learning Representations , year=
High-dimensional continuous control using generalized advantage estimation , author=. International Conference on Learning Representations , year=
-
[25]
International Conference on Learning Representations , year=
Offline Reinforcement Learning with Implicit Q-Learning , author=. International Conference on Learning Representations , year=
-
[26]
Group-in-Group Policy Optimization for
Lang Feng and Zhenghai Xue and Tingcong Liu and Bo An , booktitle=. Group-in-Group Policy Optimization for. 2025 , url=
2025
-
[27]
Retrospex: Language Agent Meets Offline Reinforcement Learning Critic
Xiang, Yufei and Shen, Yiqun and Zhang, Yeqin and Nguyen, Cam-Tu. Retrospex: Language Agent Meets Offline Reinforcement Learning Critic. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.268
-
[28]
Charlie Victor Snell and Ilya Kostrikov and Yi Su and Sherry Yang and Sergey Levine , booktitle=. Offline. 2023 , url=
2023
-
[29]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Direct Multi-Turn Preference Optimization for Language Agents , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[30]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[31]
arXiv preprint arXiv:2310.05915 , year=
Fireact: Toward language agent fine-tuning , author=. arXiv preprint arXiv:2310.05915 , year=
-
[32]
arXiv preprint arXiv:2308.04371 , year=
Cumulative reasoning with large language models , author=. arXiv preprint arXiv:2308.04371 , year=
-
[33]
arXiv preprint arXiv:2502.10325 , year=
Process reward models for llm agents: Practical framework and directions , author=. arXiv preprint arXiv:2502.10325 , year=
-
[34]
arXiv preprint arXiv:2408.00724 , year=
Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models , author=. arXiv preprint arXiv:2408.00724 , year=
-
[35]
arXiv preprint arXiv:2408.03314 , year=
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
-
[36]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[37]
arXiv preprint arXiv:2406.06592 , year=
Improve mathematical reasoning in language models by automated process supervision , author=. arXiv preprint arXiv:2406.06592 , year=
-
[38]
arXiv preprint arXiv:2211.14275 , year=
Solving math word problems with process-and outcome-based feedback , author=. arXiv preprint arXiv:2211.14275 , year=
-
[39]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[40]
Advances in Neural Information Processing Systems , volume =
Learning guidance rewards with trajectory-space smoothing , author =. Advances in Neural Information Processing Systems , volume =
-
[41]
arXiv preprint arXiv:2008.02217 , year=
Hopfield networks is all you need , author=. arXiv preprint arXiv:2008.02217 , year=
Pith/arXiv arXiv 2008
-
[42]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Deep RL Workshop NeurIPS 2021 , year=
Modern hopfield networks for return decomposition for delayed rewards , author=. Deep RL Workshop NeurIPS 2021 , year=
2021
-
[44]
arXiv preprint arXiv:1905.13420 , year=
Sequence modeling of temporal credit assignment for episodic reinforcement learning , author=. arXiv preprint arXiv:1905.13420 , year=
Pith/arXiv arXiv 1905
-
[45]
Proceedings of the Sixteenth International Conference on Machine Learning , pages=
Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping , author=. Proceedings of the Sixteenth International Conference on Machine Learning , pages=
-
[46]
Advances in Neural Information Processing Systems , volume =
Episodic multi-agent reinforcement learning with curiosity-driven exploration , author =. Advances in Neural Information Processing Systems , volume =
-
[47]
International Conference on Machine Learning , pages =
Curiosity-driven exploration by self-supervised prediction , author =. International Conference on Machine Learning , pages =. 2017 , organization =
2017
-
[48]
Advances in Neural Information Processing Systems , volume =
Language as a cognitive tool to imagine goals in curiosity driven exploration , author =. Advances in Neural Information Processing Systems , volume =
-
[49]
Conference on Robot Learning , pages=
Haptics-based curiosity for sparse-reward tasks , author=. Conference on Robot Learning , pages=. 2022 , organization=
2022
-
[50]
Advances in Neural Information Processing Systems , volume =
Learning to utilize shaping rewards: A new approach of reward shaping , author =. Advances in Neural Information Processing Systems , volume =
-
[51]
, author =
Controllable Neural Story Plot Generation via Reward Shaping. , author =. Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence , pages =
-
[52]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[53]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
ScienceWorld: Is your Agent Smarter than a 5th Grader? , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[54]
arXiv preprint arXiv:2501.03124 , year=
PRMBench: A fine-grained and challenging benchmark for process-level reward models , author=. arXiv preprint arXiv:2501.03124 , year=
-
[55]
EMNLP (Findings) , year=
Multi-step Problem Solving Through a Verifier: An Empirical Analysis on Model-induced Process Supervision , author=. EMNLP (Findings) , year=
-
[56]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , author=
-
[57]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
2025 , url=
Zongyu Lin and Yao Tang and Xingcheng Yao and Da Yin and Ziniu Hu and Yizhou Sun and Kai-Wei Chang , booktitle=. 2025 , url=
2025
-
[59]
2025 , cdate=
Yun Qu and Yuhang Jiang and Boyuan Wang and Yixiu Mao and Cheems Wang and Chang Liu and Xiangyang Ji , title=. 2025 , cdate=
2025
-
[60]
Lu, Jiarui and Holleis, Thomas and Zhang, Yizhe and Aumayer, Bernhard and Nan, Feng and Bai, Haoping and Ma, Shuang and Ma, Shen and Li, Mengyu and Yin, Guoli and Wang, Zirui and Pang, Ruoming. T ool S andbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities. Findings of the Association for Computational Linguisti...
-
[61]
EASYTOOL : Enhancing LLM -based Agents with Concise Tool Instruction
Yuan, Siyu and Song, Kaitao and Chen, Jiangjie and Tan, Xu and Shen, Yongliang and Ren, Kan and Li, Dongsheng and Yang, Deqing. EASYTOOL : Enhancing LLM -based Agents with Concise Tool Instruction. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume...
-
[62]
Advances in neural information processing systems , volume=
Large language models as commonsense knowledge for large-scale task planning , author=. Advances in neural information processing systems , volume=
-
[63]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Llm-planner: Few-shot grounded planning for embodied agents with large language models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[64]
International Conference on Learning Representations , year =
Learning Long-Term Reward Redistribution via Randomized Return Decomposition , author =. International Conference on Learning Representations , year =
-
[65]
2018 , publisher =
Reinforcement learning: An introduction , author =. 2018 , publisher =
2018
-
[66]
ACL (1) , year=
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations , author=. ACL (1) , year=
-
[67]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[68]
arXiv preprint arXiv:2310.10080 , year=
Let's reward step by step: Step-Level reward model as the Navigators for Reasoning , author=. arXiv preprint arXiv:2310.10080 , year=
-
[69]
International Conference on Machine Learning , year =
Align-RUDDER: Learning From Few Demonstrations by Reward Redistribution , author =. International Conference on Machine Learning , year =
-
[70]
Advances in Neural Information Processing Systems , volume =
RUDDER: Return decomposition for delayed rewards , author =. Advances in Neural Information Processing Systems , volume =
-
[71]
Proceedings of the 35th International Conference on Machine Learning , pages =
Automatic Goal Generation for Reinforcement Learning Agents , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[72]
AgentBench: Evaluating LLMs as Agents , author=
-
[73]
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=
-
[74]
arXiv preprint arXiv:2308.09583 , year=
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct , author=. arXiv preprint arXiv:2308.09583 , year=
-
[75]
arXiv preprint arXiv:2308.01825 , year=
Scaling relationship on learning mathematical reasoning with large language models , author=. arXiv preprint arXiv:2308.01825 , year=
-
[76]
arXiv preprint arXiv:2308.12950 , year=
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
-
[77]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[78]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[79]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[80]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.