Making the Most of Limited Data: Score-Aware Training for Text-to-Music Generation
Pith reviewed 2026-06-27 22:58 UTC · model grok-4.3
The pith
Score-aware training repurposes low-alignment audio segments through a CLAP-conditioned Beta noise schedule to train text-to-music models on limited data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
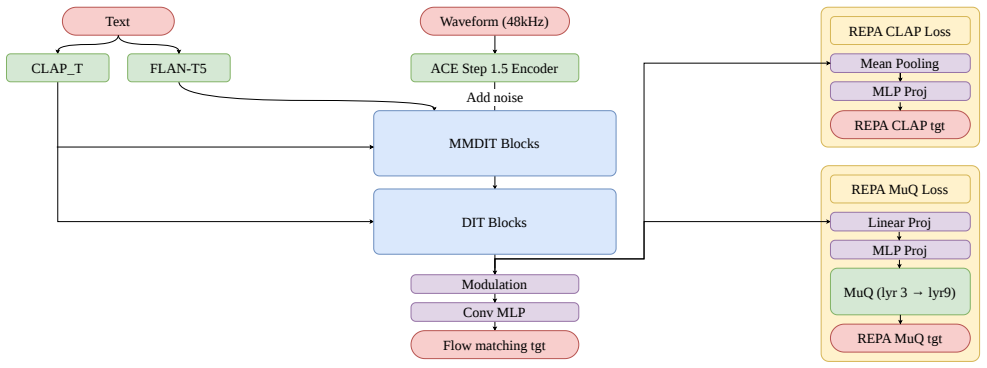
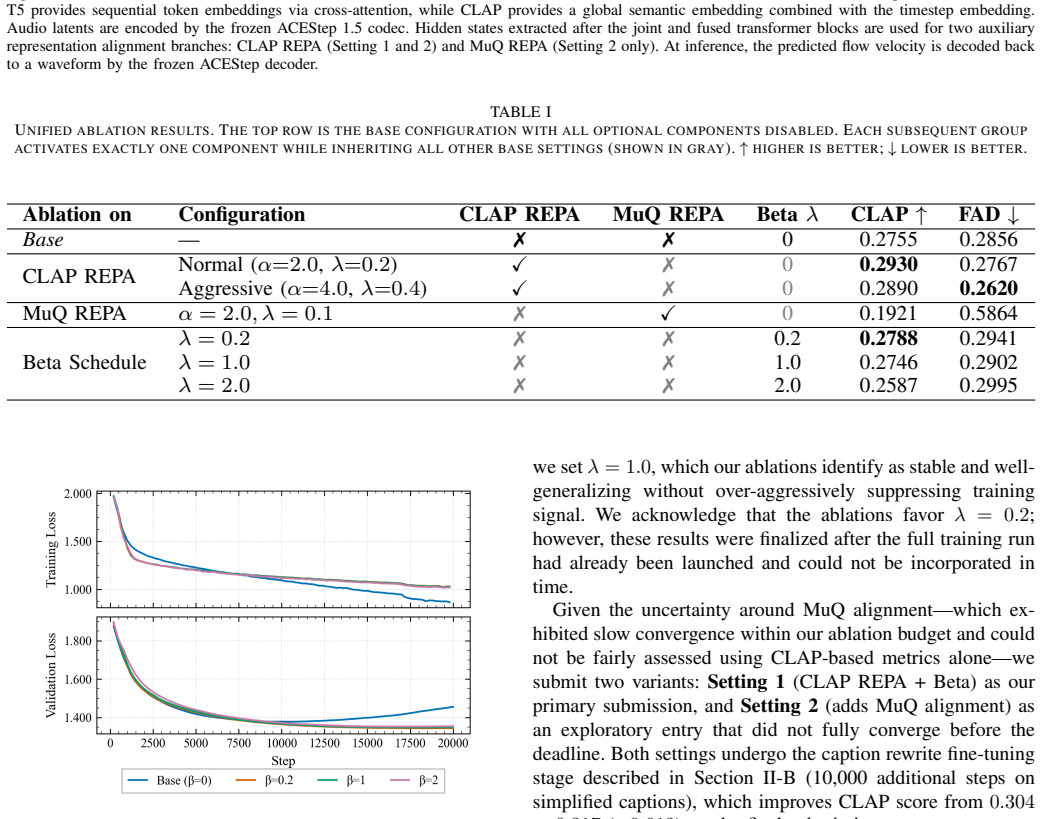
Score-aware training treats audio-caption alignment scores as direct supervision throughout the pipeline. Low-scoring segments are not discarded but reassigned to high-noise regimes by a CLAP-conditioned Beta noise timestep schedule, functioning as an implicit regularizer. Segment-level filtering removes the most misaligned examples, a two-stage captioning procedure reduces the gap between training and inference text, and a REPA auxiliary loss transfers semantic knowledge from pretrained encoders. The resulting system achieves second place in objective metrics and third in the efficiency track of the ICME 2026 ATTM Grand Challenge.
What carries the argument
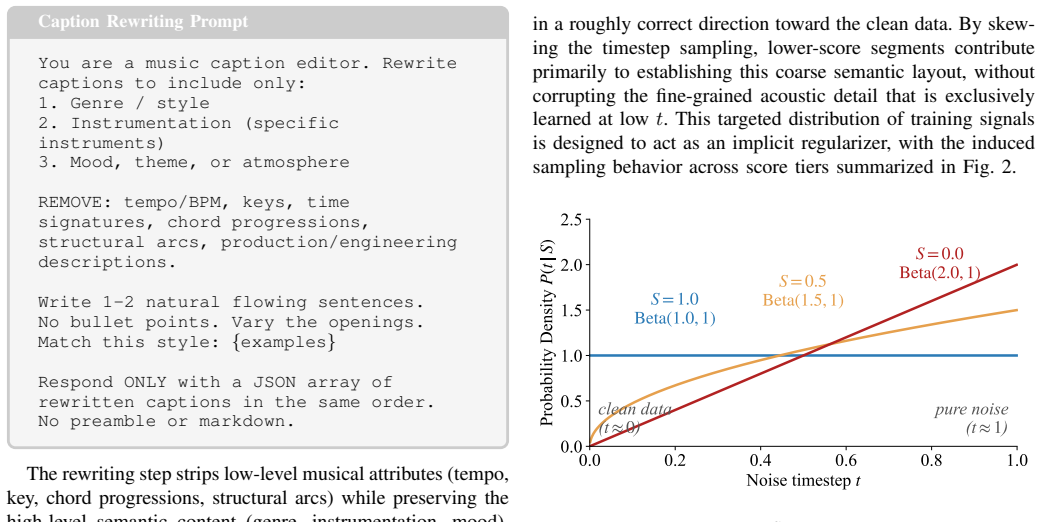
CLAP-conditioned Beta noise timestep schedule that routes low-scoring segments into high-noise training regimes to serve as implicit regularization.
If this is right
- Low-scoring data contributes to training rather than being wasted, increasing effective dataset size.
- The Beta schedule provides regularization that reduces reliance on external data cleaning.
- Two-stage captioning aligns training distributions more closely with concise user prompts.
- Auxiliary loss from pretrained encoders adds semantic structure without new labeled data.
- The full pipeline produces competitive objective and subjective scores at 450M parameters.
Where Pith is reading between the lines
- The same score-routing idea could be tested on other conditional generation tasks where alignment metrics are available.
- If the Beta schedule truly regularizes without collapse, it may reduce the need for explicit data augmentation techniques.
- Performance on very small datasets could be measured by progressively shrinking the training set while keeping the score-aware components fixed.
Load-bearing premise
Routing low-scoring segments to high-noise regimes via the conditioned Beta schedule improves training as a regularizer without introducing bias or mode collapse.
What would settle it
Train two identical models on the same limited dataset, one using the Beta schedule to route low-score segments and one discarding them, then compare validation loss curves and generation metrics for signs of collapse or degraded alignment.
Figures


read the original abstract
State-of-the-art text-to-music generation systems rely on massive proprietary datasets and industrial-scale compute, making it impossible to disentangle architectural contributions from resource advantages. We propose \textit{score-aware training}, which treats audio-caption alignment score as a direct supervision signal throughout the pipeline. Rather than discarding low-scoring segments, we repurpose them via a CLAP-conditioned Beta noise timestep schedule that routes them to high-noise training regimes, acting as an effective implicit regularizer. Complementarily, segment-level filtering removes the most misaligned examples, and a two-stage caption procedure bridges the distribution gap between verbose training captions and concise inference prompts. A REPA auxiliary loss further transfers structured semantic knowledge from pretrained CLAP and MuQ encoders without additional data. Our 450M-parameter FluxAudio-based system, submitted to the ICME 2026 ATTM Grand Challenge Efficiency Track, ranked 2nd across both tracks in the objective evaluation and 3rd in the Efficiency Track in the final MOS evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes score-aware training for text-to-music generation using limited data. It treats audio-caption alignment scores as supervision signals, repurposing low-scoring segments via a CLAP-conditioned Beta noise timestep schedule as an implicit regularizer, combined with segment-level filtering, two-stage captioning, and a REPA auxiliary loss. The resulting 450M-parameter model achieved 2nd place in objective metrics and 3rd in MOS evaluation in the Efficiency Track of the ICME 2026 ATTM Grand Challenge.
Significance. Should the proposed mechanisms prove responsible for the performance, this could offer a valuable strategy for maximizing utility from limited or noisy datasets in generative audio models. The competitive challenge results provide external validation of the system's effectiveness, though the absence of internal controls limits attribution to specific innovations.
major comments (2)
- [Abstract] Abstract: The assertion that routing low-scoring segments to high-noise regimes via the CLAP-conditioned Beta schedule acts as an effective implicit regularizer lacks any derivation, analysis of the Beta distribution parameters, or ablation studies isolating its effect from filtering or the REPA loss.
- [Abstract] Abstract: The abstract reports competitive rankings but provides no information on dataset sizes, number of training examples, error bars on metrics, or baseline comparisons, preventing verification that the score-aware components drive the results.
minor comments (1)
- Consider adding a dedicated section or figure illustrating the Beta schedule conditioning to improve clarity of the method.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the two major points on the abstract below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that routing low-scoring segments to high-noise regimes via the CLAP-conditioned Beta schedule acts as an effective implicit regularizer lacks any derivation, analysis of the Beta distribution parameters, or ablation studies isolating its effect from filtering or the REPA loss.
Authors: The main manuscript (Section 3.2) derives the CLAP-conditioned Beta schedule, specifies the distribution parameters selected to map low-alignment scores to higher noise timesteps, and explains the implicit regularization rationale. Section 4.3 contains ablations that isolate the routing component from segment filtering and the REPA loss. To make the abstract self-contained, we will add a brief clause referencing these analyses and the regularization mechanism. revision: yes
-
Referee: [Abstract] Abstract: The abstract reports competitive rankings but provides no information on dataset sizes, number of training examples, error bars on metrics, or baseline comparisons, preventing verification that the score-aware components drive the results.
Authors: We will revise the abstract to state the training data volume (limited public audio with captions), approximate number of segments after filtering, and direct comparison to the challenge baselines. Official challenge results do not include error bars; we will add standard deviations from our internal runs where space allows. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes score-aware training that repurposes low-scoring segments via a CLAP-conditioned Beta schedule presented as an implicit regularizer, plus filtering, captioning, and REPA loss. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce any central claim to its inputs by construction. The approach relies on external CLAP scores and competition rankings as outcome data, leaving the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Simple and controllable music generation,
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre D´efossez, “Simple and controllable music generation,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[2]
Stable audio open,
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons, “Stable audio open,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
2025
-
[3]
Academic text-to-music grand chal- lenge: Datasets, baselines, and evaluation methods,
Fang-Chih Hsieh, Wei-Jaw Lee, Chun-Ping Wang, Hung-yi Lee, Hao- Wen Dong, and Yi-Hsuan Yang, “Academic text-to-music grand chal- lenge: Datasets, baselines, and evaluation methods,” inProceedings of the IEEE International Conference on Multimedia and Expo (ICME), 2026
2026
-
[4]
The mtg-jamendo dataset for automatic music tagging,
Dmitry Bogdanov, Minz Won, Philip Tovstogan, Alastair Porter, and Xavier Serra, “The mtg-jamendo dataset for automatic music tagging,” inMachine Learning for Music Discovery Workshop, International Conference on Machine Learning (ICML 2019), Long Beach, CA, United States, 2019
2019
-
[5]
When bad data leads to good models,
Kenneth Li, Yida Chen, Fernanda Vi ´egas, and Martin Watten- berg, “When bad data leads to good models,”arXiv preprint arXiv:2505.04741, 2025
-
[6]
Representation alignment for generation: Training diffusion transformers is easier than you think,
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie, “Representation alignment for generation: Training diffusion transformers is easier than you think,” in International Conference on Learning Representations, 2025
2025
-
[7]
CLAP: Learning audio concepts from natural language supervision,
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huam- ing Wang, “CLAP: Learning audio concepts from natural language supervision,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[8]
MuQ: Self-supervised music representation learning with mel residual vector quantization,
Haina Zhu, Yizhi Zhou, Hangting Chen, Jianwei Yu, Ziyang Ma, Rongzhi Gu, Yi Luo, Wei Tan, and Xie Chen, “MuQ: Self-supervised music representation learning with mel residual vector quantization,” arXiv preprint arXiv:2501.01108, 2025
-
[9]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu et al., “Qwen-audio: Advancing universal audio under- standing via unified large-scale audio-language models,”arXiv preprint arXiv:2311.07919, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Music flamingo: Scaling music understanding in audio language models,
Sreyan Ghosh et al., “Music flamingo: Scaling music understanding in audio language models,”arXiv preprint arXiv:2511.10289, 2025
-
[11]
Meanaudio: Fast and faithful text-to-audio generation with mean flows,
Xiquan Li, Junxi Liu, Yuzhe Liang, Zhikang Niu, Wenxi Chen, and Xie Chen, “Meanaudio: Fast and faithful text-to-audio generation with mean flows,”arXiv preprint arXiv:2508.06098, 2025
-
[12]
Scaling rectified flow transformers for high-resolution image synthesis,
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al., “Scaling rectified flow transformers for high-resolution image synthesis,” inProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[13]
ACE-Step 1.5: Pushing the boundaries of open-source music generation,
Junmin Gong, Yulin Song, Wenxiao Zhao, Sen Wang, Shengyuan Xu, and Jing Guo, “ACE-Step 1.5: Pushing the boundaries of open-source music generation,”arXiv preprint arXiv:2602.00744, 2026
-
[14]
Exploring the limits of transfer learning with a unified text-to-text transformer,
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” 2020, vol. 21, pp. 1–67
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.