Second-Order Path Kernel Interpolation Formulas in Machine Learning
Pith reviewed 2026-06-27 22:18 UTC · model grok-4.3
The pith
Neural network predictions admit a second-order integral representation along the gradient descent path that includes curvature and noise covariance terms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The leading path-kernel interpolation is supplemented by a curvature-weighted interpolation term. For stochastic gradient descent, an additional sampling-induced component appears, coupling the curvature of the prediction with the covariance of mini-batch gradient noise. The representation extends to stochastic gradient descent with momentum, where the interpolation structure is preserved but with the weights modified by a memory-related factor. A concentration estimate is established for the terminal prediction, identifying the fluctuation scale around the expected second-order representation.
What carries the argument
The second-order path-kernel interpolation formula, which augments the first-order gradient-kernel integral with curvature-weighted and noise-covariance correction terms along the optimization path.
Load-bearing premise
The model is learned by (stochastic) gradient descent so that the prediction admits an integral representation along the optimization path.
What would settle it
Direct numerical computation of a trained network's prediction on a test point and comparison to the value given by the second-order path integral, checking whether the curvature and noise terms measurably reduce the discrepancy.
Figures


read the original abstract
Understanding how training data shape neural network predictions is a central problem in modern learning theory. In 2020, Pedro Domingos proposed an interpolation formula valid for every model learned by deterministic gradient descent. It expresses the model's prediction as an integral, along the optimization path, of a data-dependent kernel that aligns the model's gradients at the test and training data. Such a first-order characterization remains valid for models trained with batch-based stochastic optimization. In this paper, we develop second-order forms of these interpolation formulas. We show that the leading path-kernel interpolation is supplemented by a curvature-weighted interpolation term. For stochastic gradient descent, an additional sampling-induced component appears, coupling the curvature of the prediction with the covariance of mini-batch gradient noise. We also extend the representation to stochastic gradient descent with momentum, where the interpolation structure is preserved but with the weights modified by a memory-related factor. Moreover, we establish a concentration estimate for the terminal prediction, identifying the fluctuation scale around the expected second-order representation. Together, these results provide a refinement of the path-kernel interpretation of neural network prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends Domingos (2020)'s first-order path-kernel interpolation formula, valid for models trained by (stochastic) gradient descent, to second order. The leading integral term along the optimization path is supplemented by a curvature-weighted interpolation term; for SGD an additional component appears that couples prediction curvature with the covariance of mini-batch gradient noise; the structure is preserved under momentum but with weights modified by a memory factor; a concentration bound is also derived for the terminal prediction around its expected second-order representation.
Significance. If the second-order Taylor expansions, noise corrections, and martingale-based concentration hold under the stated smoothness and integrability conditions, the work supplies a refined analytical characterization of how training data shape neural-network predictions. It explicitly incorporates curvature and optimization stochasticity while preserving the path-integral structure, which may aid future theoretical studies of generalization and interpretability. The direct extension of an existing result with explicit handling of SGD and momentum is a clear strength.
major comments (2)
- The central second-order claim rests on a Taylor expansion of the path-integral representation; the manuscript should explicitly identify the section or equation where the remainder term is controlled (or shown to vanish in expectation) under the smoothness assumptions inherited from Domingos (2020), as this is load-bearing for all subsequent formulas.
- In the SGD extension, the sampling-induced covariance term is presented as coupling curvature with mini-batch noise; the derivation should confirm (in the relevant theorem or proposition) that this term is obtained without reintroducing dependence on the specific fitted parameters beyond the covariance, to rule out any appearance of circularity with the quantities being interpolated.
minor comments (2)
- Notation for the curvature-weighted kernel and the momentum memory factor should be introduced with explicit equation references in the text to improve readability.
- The abstract states that the concentration estimate identifies the fluctuation scale; a brief remark on the precise probabilistic setting (e.g., bounded moments of the noise) would help readers locate the corresponding theorem.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recommendation of minor revision. We address each major comment below.
read point-by-point responses
-
Referee: The central second-order claim rests on a Taylor expansion of the path-integral representation; the manuscript should explicitly identify the section or equation where the remainder term is controlled (or shown to vanish in expectation) under the smoothness assumptions inherited from Domingos (2020), as this is load-bearing for all subsequent formulas.
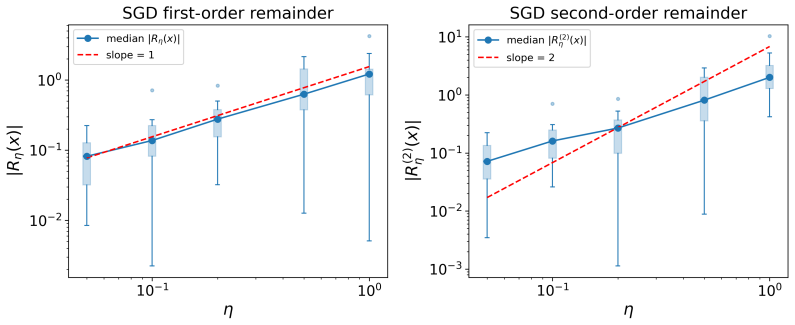
Authors: We agree that an explicit pointer improves readability. The remainder is controlled via the integral form of Taylor's theorem in the proof of Theorem 2 (Section 3.2), where the C^2 smoothness inherited from Domingos (2020) yields a remainder that is O(η^{2}) and vanishes in the continuous-time limit; the expectation is taken pathwise. We will insert a forward reference to this argument immediately after the statement of Theorem 2. revision: yes
-
Referee: In the SGD extension, the sampling-induced covariance term is presented as coupling curvature with mini-batch noise; the derivation should confirm (in the relevant theorem or proposition) that this term is obtained without reintroducing dependence on the specific fitted parameters beyond the covariance, to rule out any appearance of circularity with the quantities being interpolated.
Authors: We thank the referee for this observation. In the derivation of Theorem 3 the covariance term is obtained by taking the conditional expectation over the mini-batch distribution given the filtration up to the current parameter; the resulting expression depends on the gradient-noise covariance operator evaluated along the path but introduces no additional dependence on the fitted parameters beyond what already appears in the path measure. This is shown explicitly in Lemma A.3 of the appendix. We will add a clarifying sentence to the statement of Theorem 3. revision: yes
Circularity Check
No significant circularity; extends external Domingos 2020 result
full rationale
The derivation starts from the external 2020 Domingos path-integral representation (cited as prior work) and applies a standard second-order Taylor expansion along the optimization trajectory under smoothness and integrability assumptions. The added curvature-weighted term, SGD noise-covariance correction, and momentum modification are obtained directly from this expansion plus martingale concentration; none reduce to a fitted parameter or self-defined quantity within the paper. No self-citation is load-bearing, no ansatz is smuggled, and the central claim remains an independent refinement rather than a renaming or re-derivation of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Models are trained by deterministic or stochastic gradient descent, permitting an integral representation along the optimization path.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2306.17301 , year=
Why shallow networks struggle with approximating and learning high frequency: A numerical study , author=. arXiv preprint arXiv:2306.17301 , year=
-
[2]
International conference on machine learning , pages=
A variational analysis of stochastic gradient algorithms , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[3]
Advances in neural information processing systems , volume=
Generative modeling by estimating gradients of the data distribution , author=. Advances in neural information processing systems , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Curvature clues: Decoding deep learning privacy with input loss curvature , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:2603.23860 , year=
Why the Maximum Second Derivative of Activations Matters for Adversarial Robustness , author=. arXiv preprint arXiv:2603.23860 , year=
-
[6]
International conference on machine learning , pages=
Second-order provable defenses against adversarial attacks , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[7]
Loshchilov, Ilya and Hutter, Frank , journal=
-
[8]
Advances in neural information processing systems , volume=
Improved techniques for training score-based generative models , author=. Advances in neural information processing systems , volume=
-
[9]
International Conference on Machine Learning , pages=
A tail-index analysis of stochastic gradient noise in deep neural networks , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[10]
Journal of Machine Learning Research , volume=
Stochastic modified equations and dynamics of stochastic gradient algorithms i: Mathematical foundations , author=. Journal of Machine Learning Research , volume=
-
[11]
2013 , publisher=
Stochastic differential equations: an introduction with applications , author=. 2013 , publisher=
2013
-
[12]
Online learning in neural networks , volume=
Online learning and stochastic approximations , author=. Online learning in neural networks , volume=
-
[13]
International conference on machine learning , pages=
A closer look at memorization in deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[14]
arXiv preprint arXiv:1609.04836 , year=
On large-batch training for deep learning: Generalization gap and sharp minima , author=. arXiv preprint arXiv:1609.04836 , year=
-
[15]
Neural Networks , volume=
High-dimensional dynamics of generalization error in neural networks , author=. Neural Networks , volume=. 2020 , publisher=
2020
-
[16]
Neural computation , volume=
Flat minima , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[17]
International Conference on Machine Learning , pages=
Sharp minima can generalize for deep nets , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[18]
arXiv preprint arXiv:2012.00152 , year=
Every model learned by gradient descent is approximately a kernel machine , author=. arXiv preprint arXiv:2012.00152 , year=
arXiv 2012
-
[19]
2014 , publisher=
Ordinary differential equations: analysis, qualitative theory and control , author=. 2014 , publisher=
2014
-
[20]
Neural networks , volume=
On the momentum term in gradient descent learning algorithms , author=. Neural networks , volume=. 1999 , publisher=
1999
-
[21]
arXiv preprint arXiv:2012.04728 , year=
Neural mechanics: Symmetry and broken conservation laws in deep learning dynamics , author=. arXiv preprint arXiv:2012.04728 , year=
arXiv 2012
-
[22]
arXiv preprint arXiv:2101.12176 , year=
On the origin of implicit regularization in stochastic gradient descent , author=. arXiv preprint arXiv:2101.12176 , year=
-
[23]
International Conference on Learning Representations , year=
Fluctuation-dissipation relations for stochastic gradient descent , author=. International Conference on Learning Representations , year=
-
[24]
Advances in neural information processing systems , volume=
Which algorithmic choices matter at which batch sizes? insights from a noisy quadratic model , author=. Advances in neural information processing systems , volume=
-
[25]
International Conference on Machine Learning , pages=
Noise and fluctuation of finite learning rate stochastic gradient descent , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[26]
2020 , journal=
Denoising Diffusion Probabilistic Models , author=. 2020 , journal=
2020
-
[27]
Diffusion models beat
Dhariwal, Prafulla and Nichol, Alexander , journal=. Diffusion models beat
-
[28]
Advances in Neural Information Processing Systems , volume=
Flexible diffusion modeling of long videos , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Advances in Neural Information Processing Systems , volume=
Video diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
International conference on machine learning , pages=
Junction tree variational autoencoder for molecular graph generation , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[31]
Advances in Neural Information Processing Systems , volume=
Predicting molecular conformation via dynamic graph score matching , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in Neural Information Processing Systems , volume=
What can linearized neural networks actually say about generalization? , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
arXiv preprint arXiv:2206.10012 , year=
Limitations of the ntk for understanding generalization in deep learning , author=. arXiv preprint arXiv:2206.10012 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the neural tangent kernel , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Advances in neural information processing systems , volume=
Wide neural networks of any depth evolve as linear models under gradient descent , author=. Advances in neural information processing systems , volume=
-
[36]
Advances in Neural Information Processing Systems , volume=
On the linearity of large non-linear models: when and why the tangent kernel is constant , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Advances in neural information processing systems , volume=
Visualizing the loss landscape of neural nets , author=. Advances in neural information processing systems , volume=
-
[38]
arXiv preprint arXiv:1706.04454 , year=
Empirical analysis of the hessian of over-parametrized neural networks , author=. arXiv preprint arXiv:1706.04454 , year=
-
[39]
Entropy-
Chaudhari, Pratik and Choromanska, Anna and Soatto, Stefano and LeCun, Yann and Baldassi, Carlo and Borgs, Christian and Chayes, Jennifer and Sagun, Levent and Zecchina, Riccardo , journal=. Entropy-. 2019 , publisher=
2019
-
[40]
arXiv preprint arXiv:2603.13872 , year=
On Interpolation Formulas Describing Neural Network Generalization , author=. arXiv preprint arXiv:2603.13872 , year=
-
[41]
Advances in neural information processing systems , volume=
Neural tangent kernel: Convergence and generalization in neural networks , author=. Advances in neural information processing systems , volume=
-
[42]
Three factors influencing minima in
Jastrz. Three factors influencing minima in. arXiv preprint arXiv:1711.04623 , year=
-
[43]
arXiv preprint arXiv:1803.00195 , year=
The anisotropic noise in stochastic gradient descent: Its behavior of escaping from sharp minima and regularization effects , author=. arXiv preprint arXiv:1803.00195 , year=
-
[44]
A Hessian-aware stochastic differential equation for modelling
Li, Xiang and Shen, Zebang and Zhang, Liang and He, Niao , journal=. A Hessian-aware stochastic differential equation for modelling. 2026 , publisher=
2026
-
[45]
arXiv preprint arXiv:1611.03530 , year=
Understanding deep learning requires rethinking generalization , author=. arXiv preprint arXiv:1611.03530 , year=
-
[46]
International Conference on Machine Learning , pages=
An investigation into neural net optimization via hessian eigenvalue density , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[47]
Proceedings of the 35th International Conference on Machine Learning , pages =
To Understand Deep Learning We Need to Understand Kernel Learning , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[48]
nature , volume=
Deep learning , author=. nature , volume=. 2015 , publisher=
2015
-
[49]
Neural networks , volume=
Deep learning in neural networks: An overview , author=. Neural networks , volume=. 2015 , publisher=
2015
-
[50]
Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos , booktitle=. "
-
[51]
International conference on machine learning , pages=
Train faster, generalize better: Stability of stochastic gradient descent , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[52]
A Stochastic Approximation Method , urldate =
Herbert Robbins and Sutton Monro , journal =. A Stochastic Approximation Method , urldate =
-
[53]
Nonparametric regression using deep neural networks with
Schmidt-Hieber, Johannes , journal =. Nonparametric regression using deep neural networks with. doi:10.1214/19-AOS1875 , year=
-
[54]
Advances in Neural Information Processing Systems , volume=
Deep learning is adaptive to intrinsic dimensionality of model smoothness in anisotropic Besov space , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
International Conference on Artificial Intelligence and Statistics , pages=
Regularization matters: A nonparametric perspective on overparametrized neural network , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[56]
International Conference on Learning Representations , year=
A non-parametric regression viewpoint: Generalization of overparametrized deep relu network under noisy observations , author=. International Conference on Learning Representations , year=
-
[57]
Proceedings of The 28th Conference on Learning Theory , pages =
Competing with the Empirical Risk Minimizer in a Single Pass , author =. Proceedings of The 28th Conference on Learning Theory , pages =. 2015 , editor =
2015
-
[58]
SIAM Journal on optimization , volume=
Robust stochastic approximation approach to stochastic programming , author=. SIAM Journal on optimization , volume=. 2009 , publisher=
2009
-
[59]
Logarithmic Regret Algorithms for Online Convex Optimization
Hazan, Elad and Kalai, Adam and Kale, Satyen and Agarwal, Amit. Logarithmic Regret Algorithms for Online Convex Optimization. Learning Theory. 2006
2006
-
[60]
The Journal of Machine Learning Research , volume=
Beyond the regret minimization barrier: optimal algorithms for stochastic strongly-convex optimization , author=. The Journal of Machine Learning Research , volume=. 2014 , publisher=
2014
-
[61]
29th International Conference on Machine Learning, ICML 2012 , pages=
Making gradient descent optimal for strongly convex stochastic optimization , author=. 29th International Conference on Machine Learning, ICML 2012 , pages=
2012
-
[62]
International conference on machine learning , pages=
On the importance of initialization and momentum in deep learning , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[63]
Understanding the role of momentum in non-convex optimization: Practical insights from a
Defazio, Aaron , journal=. Understanding the role of momentum in non-convex optimization: Practical insights from a
-
[64]
arXiv preprint arXiv:2002.10376 , year=
The two regimes of deep network training , author=. arXiv preprint arXiv:2002.10376 , year=
arXiv 2002
-
[65]
, author=
Adaptive subgradient methods for online learning and stochastic optimization. , author=. Journal of machine learning research , volume=
-
[66]
University of Toronto, Technical Report , volume=
Lecture 6.5-rmsprop, coursera: Neural networks for machine learning , author=. University of Toronto, Technical Report , volume=
-
[67]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[68]
Scientific data , volume=
Multitask learning and benchmarking with clinical time series data , author=. Scientific data , volume=. 2019 , publisher=
2019
-
[69]
International conference on machine learning , pages=
Show, attend and tell: Neural image caption generation with visual attention , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[70]
Advances in neural information processing systems , volume=
Value prediction network , author=. Advances in neural information processing systems , volume=
-
[71]
Malladi, Sadhika and Lyu, Kaifeng and Panigrahi, Abhishek and Arora, Sanjeev , journal=. On the
-
[72]
Why (and when) does local
Gu, Xinran and Lyu, Kaifeng and Huang, Longbo and Arora, Sanjeev , journal=. Why (and when) does local
-
[73]
The marginal value of momentum for small learning rate
Wang, Runzhe and Malladi, Sadhika and Wang, Tianhao and Lyu, Kaifeng and Li, Zhiyuan , journal=. The marginal value of momentum for small learning rate
-
[74]
Novak, Roman and Xiao, Lechao and Hron, Jiri and Lee, Jaehoon and Alemi, Alexander A and Sohl-Dickstein, Jascha and Schoenholz, Samuel S , journal=
-
[75]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[76]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 1998 , publisher=
1998
-
[77]
2018 Information Theory and Applications Workshop (ITA) , pages=
Stochastic gradient descent performs variational inference, converges to limit cycles for deep networks , author=. 2018 Information Theory and Applications Workshop (ITA) , pages=. 2018 , organization=
2018
-
[78]
Advances in Neural Information Processing Systems , volume=
Continuous-time models for stochastic optimization algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[80]
Stochastic Processes and their Applications , volume=
Reverse-time diffusion equation models , author=. Stochastic Processes and their Applications , volume=. 1982 , publisher=
1982
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.