The Routing Plateau: Understanding and Breaking the Accuracy Limits of LLM Routers
Pith reviewed 2026-06-29 14:04 UTC · model grok-4.3
The pith
LLM routers reach similar accuracy because they learn global performance trends rather than query-specific signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
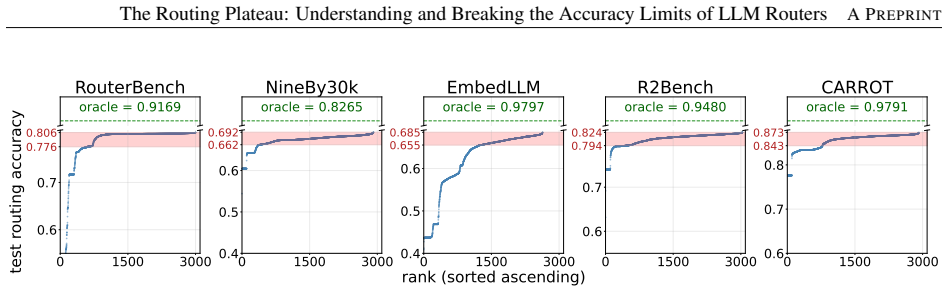
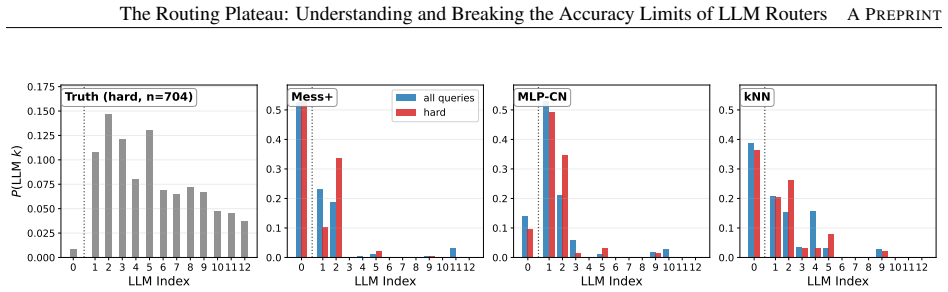
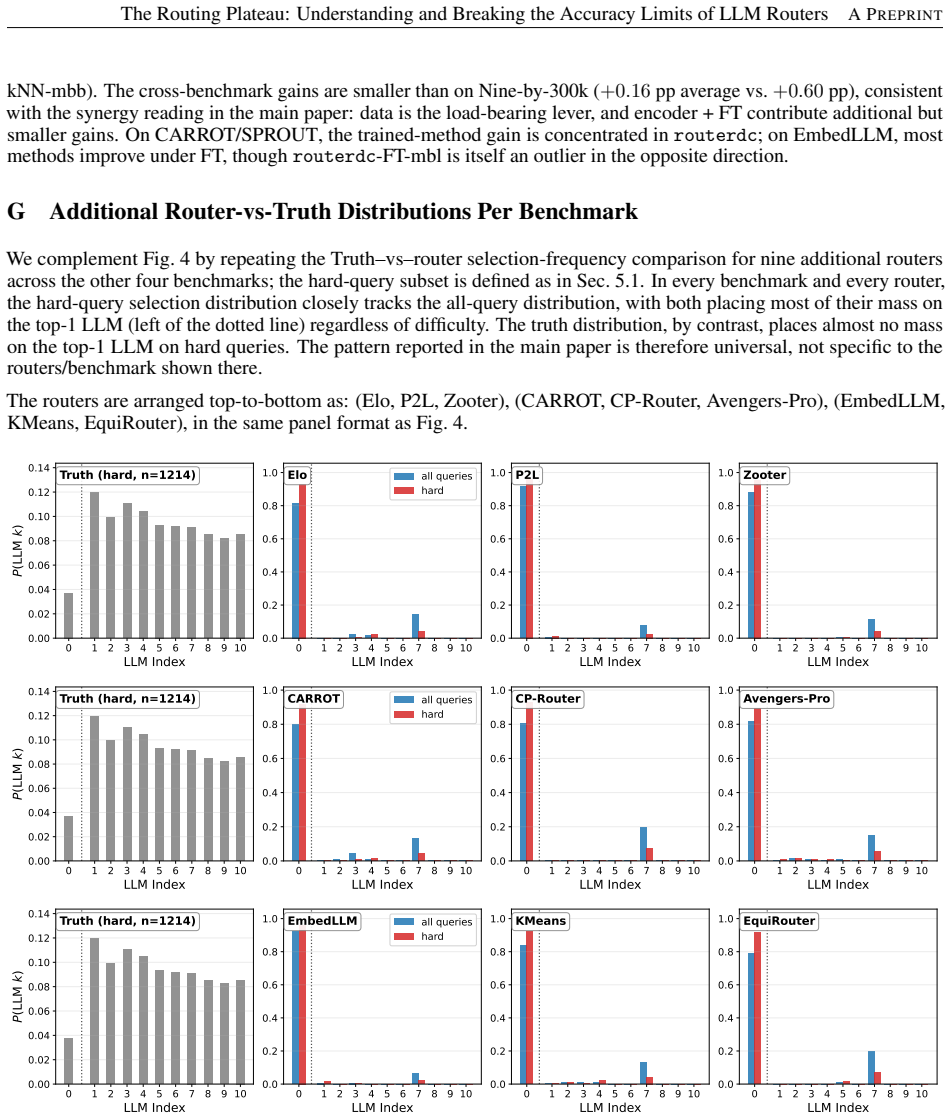
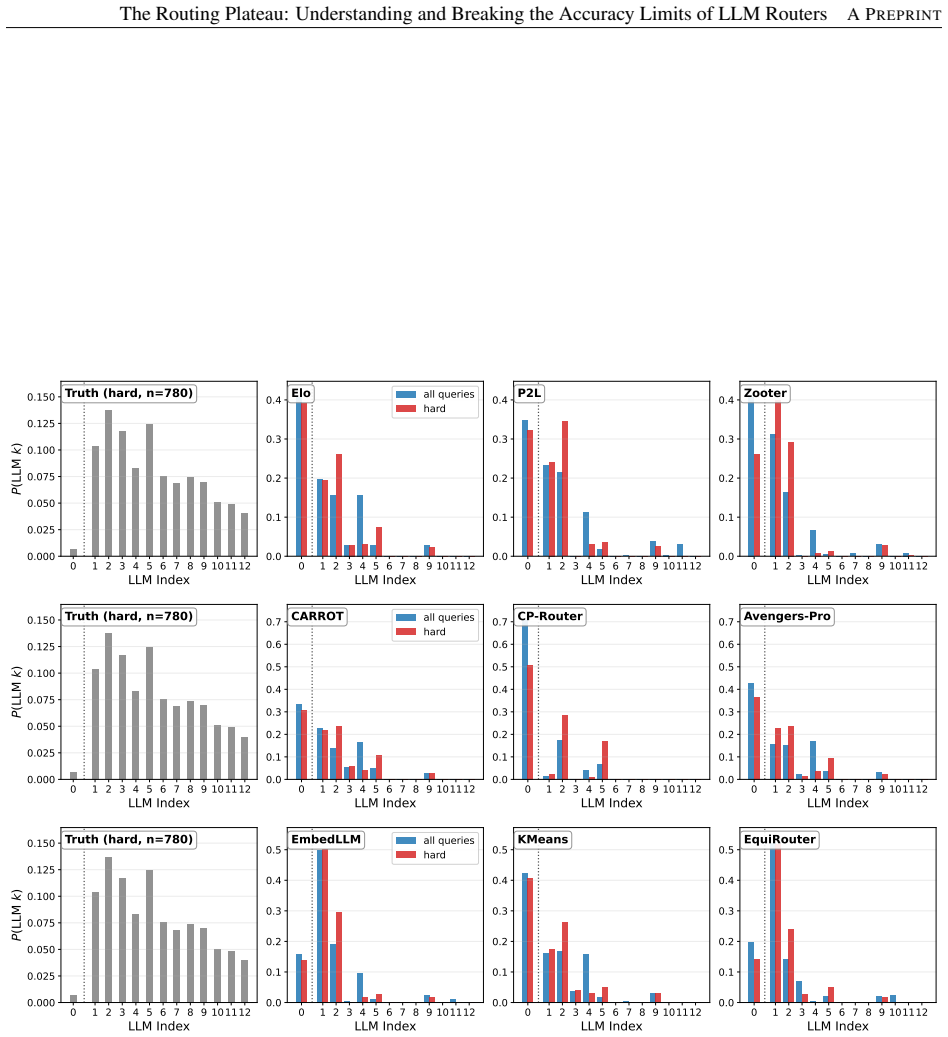
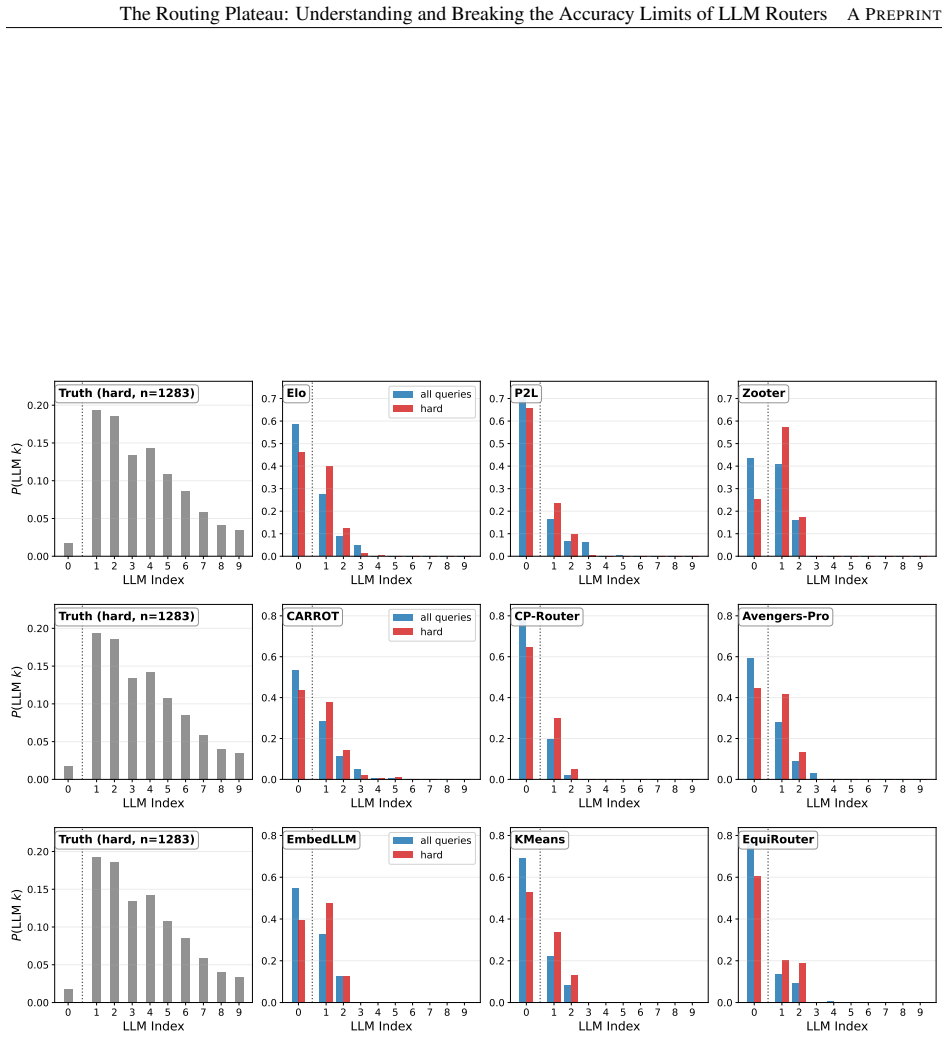
The routing plateau is largely caused by a predictability bottleneck: current routers mainly learn global averaged model-performance trends rather than fine-grained query-specific routing signals. As a result, they solve overlapping easy queries but collectively fail on hard queries that require instance-specific routing decisions.
What carries the argument
the predictability bottleneck, where routers capture only averaged model-performance trends across queries instead of instance-specific signals
If this is right
- Larger training datasets raise routing accuracy beyond the plateau.
- Stronger encoders raise routing accuracy beyond the plateau.
- End-to-end fine-tuning raises routing accuracy beyond the plateau.
- Current routers collectively fail on hard queries that need instance-specific decisions.
Where Pith is reading between the lines
- Routers could improve by adding explicit signals for query difficulty to target the cases where global trends are insufficient.
- Training on more diverse or synthetic hard queries might reduce the overlap in solved cases across methods.
- In practice the plateau implies that routing will continue to yield only modest cost savings on complex or varied query streams unless the bottleneck is directly addressed.
Load-bearing premise
That similar performance across the 21 methods on the five benchmarks reflects a fundamental limit in predictable signals rather than shared benchmark or implementation constraints.
What would settle it
A router using explicit query-specific performance features that reaches accuracy clearly above the narrow range observed for the 21 methods on the same benchmarks would falsify the bottleneck explanation.
Figures




read the original abstract
LLM routing has become a popular approach to improve the cost-quality trade-off of LLM services by dynamically selecting a model for each query. Recent work has explored a broad range of routing methods, including clustering-based routers, learned classifiers, pairwise ranking, and confidence-based approaches. Our extensive study of 21 routing methods across five benchmarks reveals a consistent phenomenon that we call the routing plateau: many methods, including kNN, achieve very similar accuracy and converge to a narrow performance range that remains far below the oracle router. Our investigation shows that the plateau is largely caused by a predictability bottleneck: current routers mainly learn global averaged model-performance trends rather than fine-grained query-specific routing signals. As a result, they solve overlapping easy queries but collectively fail on hard queries that require instance-specific routing decisions. We further study how to move beyond the plateau and find that larger training datasets, stronger encoders, and end-to-end fine-tuning can further improve routing accuracy. These findings characterize the common limits of current routing methods and provide insights and actionable directions for the community to build more effective routing systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study of 21 LLM routing methods across five benchmarks, documenting a consistent 'routing plateau' in which diverse approaches (kNN, classifiers, rankers, etc.) converge to similar accuracy levels well below the oracle router. The central claim is that this plateau arises from a predictability bottleneck: routers primarily capture global averaged model-performance trends rather than fine-grained, query-specific signals, causing them to solve overlapping easy queries while failing on hard instances. The authors further examine mitigations, reporting gains from larger training sets, stronger encoders, and end-to-end fine-tuning.
Significance. If substantiated, the work usefully characterizes shared limits of current routing techniques and supplies concrete directions for improvement. The breadth of the comparison (21 methods) is a positive feature that highlights the robustness of the observed plateau. The empirical nature of the study, however, requires tighter statistical controls and direct evidence for the proposed causal mechanism to elevate its impact.
major comments (2)
- [Abstract / investigation section] Abstract and the investigation of the plateau: the attribution of the narrow performance band to a predictability bottleneck rests on the convergence of 21 methods, yet the manuscript provides no direct analysis showing that router decisions correlate more strongly with per-model average accuracy than with query embeddings or other instance-level features after controlling for benchmark statistics. Without this separation, the causal link remains under-supported and could instead reflect correlated model accuracies inherent to the five benchmarks.
- [Results section] Results describing the 21 methods and five benchmarks: the abstract and main results report consistent performance across methods but supply no details on statistical significance testing, error bars, data splits, or controls for implementation variance. This omission weakens the claim that the plateau is a fundamental phenomenon rather than an artifact of experimental setup.
minor comments (1)
- [Benchmark description] The manuscript would benefit from explicit discussion of how the five benchmarks were chosen and whether their query distributions may induce correlated model performances by construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the causal evidence and experimental rigor, which we will address in revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract / investigation section] Abstract and the investigation of the plateau: the attribution of the narrow performance band to a predictability bottleneck rests on the convergence of 21 methods, yet the manuscript provides no direct analysis showing that router decisions correlate more strongly with per-model average accuracy than with query embeddings or other instance-level features after controlling for benchmark statistics. Without this separation, the causal link remains under-supported and could instead reflect correlated model accuracies inherent to the five benchmarks.
Authors: We agree that a direct correlation analysis would provide stronger support for the proposed mechanism. While the convergence of 21 diverse methods (classifiers, rankers, kNN, etc.) already suggests the bottleneck is not an artifact of any single approach, we will add in the revised manuscript an explicit analysis comparing router decision correlations with global per-model accuracy averages versus instance-level features (e.g., query embeddings), after controlling for benchmark-level statistics. This will help separate the predictability bottleneck from benchmark-inherent correlations. revision: yes
-
Referee: [Results section] Results describing the 21 methods and five benchmarks: the abstract and main results report consistent performance across methods but supply no details on statistical significance testing, error bars, data splits, or controls for implementation variance. This omission weakens the claim that the plateau is a fundamental phenomenon rather than an artifact of experimental setup.
Authors: We acknowledge the importance of these details for establishing robustness. In the revised version we will expand the results section to include: (i) error bars and standard deviations from multiple independent runs with different random seeds, (ii) statistical significance tests (e.g., paired t-tests across methods), (iii) explicit descriptions of train/test splits and benchmark preprocessing, and (iv) controls for implementation variance such as hyperparameter sensitivity checks. These additions will better substantiate that the plateau is not an experimental artifact. revision: yes
Circularity Check
Empirical comparison study with no derivations or self-referential reductions
full rationale
The paper reports direct measurements of routing accuracy across 21 methods on five benchmarks, observing convergence to a narrow performance band. The central claim attributes this to a predictability bottleneck (routers learning global trends over instance-specific signals) as an interpretive inference from those measurements. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the similarity result is not constructed from the paper's own inputs by definition. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five benchmarks are representative of real-world query distributions for LLM routing
Reference graph
Works this paper leans on
-
[1]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms. InNAACL-HLT, 2019
2019
-
[2]
On the Cross-lingual Transferability of Monolingual Representations
Mikel Artetxe, Sebastian Ruder, and Dani Yogatama. On the Cross-lingual Transferability of Monolingual Representations. InACL, 2020
2020
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program Synthesis with Large Language Models, 2021. URLhttps://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset, 2018. URL https: //arxiv.org/abs/1611.09268
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Semantic Parsing on Freebase from Question- Answer Pairs
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic Parsing on Freebase from Question- Answer Pairs. InEMNLP, 2013
2013
-
[6]
Iván Vicente Moreno Cencerrado, Arnau Padrés Masdemont, Anton Gonzalvez Hawthorne, David Demitri Africa, and Lorenzo Pacchiardi. No Answer Needed: Predicting LLM Answer Accuracy from QQuestion-Only Linear Probes.arXiv preprint arXiv:2509.10625, 2025
-
[7]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating Large Language Models Trained on Code, 2021. URLhttps://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Shuhao Chen, Weisen Jiang, Baijiong Lin, James T. Kwok, and Yu Zhang. RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models, 2024. URL https://arxiv.org/abs/ 2409.19886
-
[9]
FinQA: A Dataset of Numerical Reasoning over Financial Data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. FinQA: A Dataset of Numerical Reasoning over Financial Data. InEMNLP, 2021
2021
-
[10]
QuAC: Question Answering in Context
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. QuAC: Question Answering in Context. InEMNLP, 2018
2018
-
[11]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions. InNAACL-HLT, 2019. 9 The Routing Plateau: Understanding and Breaking the Accuracy Limits of LLM RoutersA PREPRINT
2019
-
[12]
TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages.Transactions of the Association for Computational Linguistics, 8:454–470, 2020
Jonathan H Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki. TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages.Transactions of the Association for Computational Linguistics, 8:454–470, 2020
2020
-
[13]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge, 2018. URL https://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems, 2021. URLhttps://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [15]
-
[16]
SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine
Matthew Dunn, Levent Sagun, Mike Higgins, V Ugur Guney, V olkan Cirik, and Kyunghyun Cho. SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine, 2017. URL https://arxiv.org/abs/ 1704.05179
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
GraphRouter: A Graph-based Router for LLM Selections, 2025
Tao Feng, Yanzhen Shen, and Jiaxuan You. GraphRouter: A Graph-based Router for LLM Selections, 2025. URL https://arxiv.org/abs/2410.03834
-
[18]
Evan Frick, Connor Chen, Joseph Tennyson, Tianle Li, Wei-Lin Chiang, Anastasios N. Angelopoulos, and Ion Stoica. Prompt-to-Leaderboard, 2025. URLhttps://arxiv.org/abs/2502.14855
-
[19]
Aligning AI With Shared Human Values
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning AI With Shared Human Values. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[20]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[21]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring Mathematical Problem Solving With the MATH Dataset. InNeurIPS Datasets and Benchmarks Track, 2021
2021
-
[22]
RouterBench: A Benchmark for Multi-LLM Routing System
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. RouterBench: A Benchmark for Multi-LLM Routing System, 2024. URL https://arxiv.org/abs/2403.12031
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code, 2024. URLhttps://arxiv.org/abs/2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams.Applied Sciences, 11(14), 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams.Applied Sciences, 11(14), 2021
2021
-
[25]
Universal Model Routing for Efficient LLM Inference, 2025
Wittawat Jitkrittum, Harikrishna Narasimhan, Ankit Singh Rawat, Jeevesh Juneja, Congchao Wang, Zifeng Wang, Alec Go, Chen-Yu Lee, Pradeep Shenoy, Rina Panigrahy, Aditya Krishna Menon, and Sanjiv Kumar. Universal Model Routing for Efficient LLM Inference, 2025. URLhttps://arxiv.org/abs/2502.08773
-
[26]
QASC: A Dataset for Question Answering via Sentence Composition
Tushar Khot, Peter Clark, Michal Guerquin, Peter Jansen, and Ashish Sabharwal. QASC: A Dataset for Question Answering via Sentence Composition. InAAAI, 2020
2020
-
[27]
The NarrativeQA Reading Comprehension Challenge.Transactions of the Association for Computational Linguistics, 6:317–328, 2018
Tomáš Koˇciský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Ed- ward Grefenstette. The NarrativeQA Reading Comprehension Challenge.Transactions of the Association for Computational Linguistics, 6:317–328, 2018
2018
-
[28]
Natural Questions: A Benchmark for Question Answering Research.Transactions of the Association for Computational Linguistics, 7:452–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural Questions: A Benchmark for Question Answering Research.Transacti...
2019
-
[29]
When Routing Collapses: On the Degenerate Convergence of LLM Routers, 2026
Guannan Lai and Han-Jia Ye. When Routing Collapses: On the Degenerate Convergence of LLM Routers, 2026. URLhttps://arxiv.org/abs/2602.03478
-
[30]
MLQA: Evaluating Cross-lingual Extractive Question Answering
Patrick Lewis, Barlas Oguz, Ruty Rinott, Sebastian Riedel, and Holger Schwenk. MLQA: Evaluating Cross-lingual Extractive Question Answering. InACL, 2020. 10 The Routing Plateau: Understanding and Breaking the Accuracy Limits of LLM RoutersA PREPRINT
2020
-
[31]
Hao Li, Yiqun Zhang, Zhaoyan Guo, Chenxu Wang, Shengji Tang, Qiaosheng Zhang, Yang Chen, Biqing Qi, Peng Ye, Lei Bai, Zhen Wang, and Shuyue Hu. LLMRouterBench: A Massive Benchmark and Unified Framework for LLM Routing, 2026. URLhttps://arxiv.org/abs/2601.07206
-
[32]
Lihong Li, Wei Chu, John Langford, and Robert E. Schapire. A contextual-bandit approach to personalized news article recommendation. InProceedings of the 19th international conference on World wide web, WWW ’10, page 661–670. ACM, April 2010. doi: 10.1145/1772690.1772758. URL http://dx.doi.org/10.1145/1772690. 1772758
-
[33]
Rethinking Predictive Modeling for LLM Routing: When Simple kNN Beats Complex Learned Routers,
Yang Li. Rethinking Predictive Modeling for LLM Routing: When Simple kNN Beats Complex Learned Routers,
-
[34]
URLhttps://arxiv.org/abs/2505.12601
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring How Models Mimic Human Falsehoods. InACL, 2022
2022
-
[36]
Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. InACL, 2017
2017
-
[37]
OptLLM: Optimal Assignment of Queries to Large Language Models, 2024
Yueyue Liu, Hongyu Zhang, Yuantian Miao, Van-Hoang Le, and Zhiqiang Li. OptLLM: Optimal Assignment of Queries to Large Language Models, 2024. URLhttps://arxiv.org/abs/2405.15130
-
[38]
Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models, 2023
Keming Lu, Hongyi Yuan, Runji Lin, Junyang Lin, Zheng Yuan, Chang Zhou, and Jingren Zhou. Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models, 2023. URL https://arxiv.org/abs/ 2311.08692
-
[39]
RouterArena: An Open Platform for Comprehensive Comparison of LLM Routers, 2025
Yifan Lu, Rixin Liu, Jiayi Yuan, Xingqi Cui, Shenrun Zhang, Hongyi Liu, and Jiarong Xing. RouterArena: An Open Platform for Comprehensive Comparison of LLM Routers, 2025. URL https://arxiv.org/abs/2510. 00202
2025
-
[40]
A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers
Shen-Yun Miao, Chao-Chun Liang, and Keh-Yih Su. A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers. InACL, 2020
2020
-
[41]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. InEMNLP, 2018
2018
-
[42]
RoRF: Routing on Random Forests
Not Diamond. RoRF: Routing on Random Forests. https://github.com/Not-Diamond/RoRF, 2025. Ac- cessed: 2026-04-25
2025
-
[43]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. RouteLLM: Learning to Route LLMs with Preference Data, 2025. URL https: //arxiv.org/abs/2406.18665
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering. InConference on Health, Inference, and Learning (CHIL), 2022
2022
-
[45]
Are NLP Models really able to Solve Simple Math Word Problems? InNAACL-HLT, 2021
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP Models really able to Solve Simple Math Word Problems? InNAACL-HLT, 2021
2021
-
[46]
Qwen Team. Qwen2.5 Technical Report, 2024. URLhttps://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ Questions for Machine Comprehension of Text. InEMNLP, 2016
2016
-
[48]
CoQA: A Conversational Question Answering Challenge
Siva Reddy, Danqi Chen, and Christopher D Manning. CoQA: A Conversational Question Answering Challenge. Transactions of the Association for Computational Linguistics, 7:249–266, 2019
2019
-
[49]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A Graduate-Level Google-Proof Q&A Benchmark, 2023. URL https://arxiv.org/abs/2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Quizbowl: The Case for Incremental Question Answering, 2019
Pedro Rodriguez, Shi Feng, Mohit Iyyer, He He, and Jordan Boyd-Graber. Quizbowl: The Case for Incremental Question Answering, 2019. URLhttps://arxiv.org/abs/1904.04792
-
[51]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An Adversarial Winograd Schema Challenge at Scale. InAAAI, 2020
2020
-
[52]
Fly-Swat or Cannon? Cost-Effective Language Model Choice via Meta-Modeling
Marija Sakota, Maxime Peyrard, and Robert West. Fly-Swat or Cannon? Cost-Effective Language Model Choice via Meta-Modeling. InProceedings of the 17th ACM International Conference on Web Search and Data Mining, WSDM ’24, page 606–615. ACM, March 2024. doi: 10.1145/3616855.3635825. URL http: //dx.doi.org/10.1145/3616855.3635825. 11 The Routing Plateau: Unde...
-
[53]
Social IQa: Commonsense Reasoning about Social Interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social IQa: Commonsense Reasoning about Social Interactions. InEMNLP-IJCNLP, 2019
2019
-
[54]
Carrot: A cost aware rate optimal router, 2025
Seamus Somerstep, Felipe Maia Polo, Allysson Flavio Melo de Oliveira, Prattyush Mangal, Mírian Silva, Onkar Bhardwaj, Mikhail Yurochkin, and Subha Maity. CARROT: A Cost Aware Rate Optimal Router, 2025. URL https://arxiv.org/abs/2502.03261
-
[55]
MPNet: Masked and Permuted Pre-training for Language Understanding, 2020
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MPNet: Masked and Permuted Pre-training for Language Understanding, 2020. URLhttps://arxiv.org/abs/2004.09297
-
[56]
IRT-Router: Effective and Interpretable Multi-LLM Routing via Item Response Theory, 2025
Wei Song, Zhenya Huang, Cheng Cheng, Weibo Gao, Bihan Xu, GuanHao Zhao, Fei Wang, and Runze Wu. IRT-Router: Effective and Interpretable Multi-LLM Routing via Item Response Theory, 2025. URL https: //arxiv.org/abs/2506.01048
-
[57]
CP-Router: An Uncertainty-Aware Router Between LLM and LRM, 2025
Jiayuan Su, Fulin Lin, Zhaopeng Feng, Han Zheng, Teng Wang, Zhenyu Xiao, Xinlong Zhao, Zuozhu Liu, Lu Cheng, and Hongwei Wang. CP-Router: An Uncertainty-Aware Router Between LLM and LRM, 2025. URL https://arxiv.org/abs/2505.19970
-
[58]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. InNAACL-HLT, 2019
2019
-
[59]
NewsQA: A Machine Comprehension Dataset
Adam Trischler, Tong Wang, Xingdi Yuan, Justin Harris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. NewsQA: A Machine Comprehension Dataset. In2nd Workshop on Representation Learning for NLP (RepL4NLP), 2017
2017
-
[60]
An overview of the BIOASQ large-scale biomedical semantic indexing and question answering competition.BMC Bioinformatics, 16(138), 2015
George Tsatsaronis, Georgios Balikas, Prodromos Malakasiotis, Ioannis Partalas, Matthias Zschunke, Michael R Alvers, Dirk Weissenborn, Anastasia Krithara, Sergios Petridis, Dimitris Polychronopoulos, et al. An overview of the BIOASQ large-scale biomedical semantic indexing and question answering competition.BMC Bioinformatics, 16(138), 2015
2015
-
[61]
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. InNeurIPS, 2019
2019
-
[62]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers, 2020. URL https://arxiv.org/ abs/2002.10957
-
[63]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark, 2024. URLhttps://arxiv.org/abs/2406.01574
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, and Iacopo Poli. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference, 20...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Crowdsourcing Multiple Choice Science Questions
Johannes Welbl, Nelson F Liu, and Matt Gardner. Crowdsourcing Multiple Choice Science Questions. In Proceedings of the 3rd Workshop on Noisy User-generated Text, 2017
2017
-
[66]
Constructing Datasets for Multi-hop Reading Com- prehension Across Documents.Transactions of the Association for Computational Linguistics, 6:287–302, 2018
Johannes Welbl, Pontus Stenetorp, and Sebastian Riedel. Constructing Datasets for Multi-hop Reading Com- prehension Across Documents.Transactions of the Association for Computational Linguistics, 6:287–302, 2018
2018
-
[67]
Herbert Woisetschläger, Ryan Zhang, Shiqiang Wang, and Hans-Arno Jacobsen. MESS+: Dynamically Learned Inference-Time LLM Routing in Model Zoos with Service Level Guarantees, 2025. URL https://arxiv.org/ abs/2505.19947
-
[68]
Hanqi Xiao, Vaidehi Patil, Hyunji Lee, Elias Stengel-Eskin, and Mohit Bansal. Generalized Correctness Mod- els: Learning Calibrated and Model-Agnostic Correctness Predictors from Historical Patterns.arXiv preprint arXiv:2509.24988, 2025
-
[69]
C-Pack: Packed Resources For General Chinese Embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-Pack: Packed Resources For General Chinese Embeddings, 2023. URLhttps://arxiv.org/abs/2309.07597
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
R2-Router: A New Paradigm for LLM Routing with Reasoning
Jiaqi Xue, Qian Lou, Jiarong Xing, and Heng Huang. R2-Router: A New Paradigm for LLM Routing with Reasoning, 2026. URLhttps://arxiv.org/abs/2602.02823
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[71]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christo- pher D Manning. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InEMNLP, 2018. 12 The Routing Plateau: Understanding and Breaking the Accuracy Limits of LLM RoutersA PREPRINT
2018
-
[72]
ChatMusician: Understanding and Generating Music Intrinsically with LLM, 2024
Ruibin Yuan, Hanfeng Lin, Yi Wang, Zeyue Tian, Shangda Wu, Tianhao Shen, Ge Zhang, Yuhang Wu, Cong Liu, Ziya Zhou, et al. ChatMusician: Understanding and Generating Music Intrinsically with LLM, 2024. URL https://arxiv.org/abs/2402.16153
-
[73]
HellaSwag: Can a Machine Really Finish Your Sentence? InACL, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a Machine Really Finish Your Sentence? InACL, 2019
2019
-
[74]
Model Spider: Learning to Rank Pre-Trained Models Efficiently, 2023
Yi-Kai Zhang, Ting-Ji Huang, Yao-Xiang Ding, De-Chuan Zhan, and Han-Jia Ye. Model Spider: Learning to Rank Pre-Trained Models Efficiently, 2023. URLhttps://arxiv.org/abs/2306.03900
-
[75]
Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing
Yiqun Zhang, Hao Li, Jianhao Chen, Hangfan Zhang, Peng Ye, Lei Bai, and Shuyue Hu. Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing. InProceedings of the 2025 The Seventh International Conference on Distributed Artificial Intelligence, DAI ’25, page 122–129. ACM, November 2025. doi: 10.1145/3772429.3772445. URLhttp...
-
[76]
Morley Mao
Zesen Zhao, Shuowei Jin, and Z. Morley Mao. Eagle: Efficient Training-Free Router for Multi-LLM Inference,
- [77]
-
[78]
When does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset
Lucia Zheng, Neel Guha, Brandon R Anderson, Peter Henderson, and Daniel E Ho. When does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset. InICAIL, 2021
2021
-
[79]
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models, 2023. URL https://arxiv.org/abs/2304.06364
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
Richard Zhuang, Tianhao Wu, Zhaojin Wen, Andrew Li, Jiantao Jiao, and Kannan Ramchandran. EmbedLLM: Learning Compact Representations of Large Language Models, 2024. URL https://arxiv.org/abs/2410. 02223. 13 The Routing Plateau: Understanding and Breaking the Accuracy Limits of LLM RoutersA PREPRINT A Broader Impact LLM routing is a cost-quality optimizati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.