Beyond Homophily: Towards Generalized Graph Reconstruction Attack and Defense
Pith reviewed 2026-06-27 19:59 UTC · model grok-4.3
The pith
Approximating GNN layers as a Markov chain of topology-dependent representations enables stronger attacks that reconstruct training adjacency and defenses that suppress it with little accuracy cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
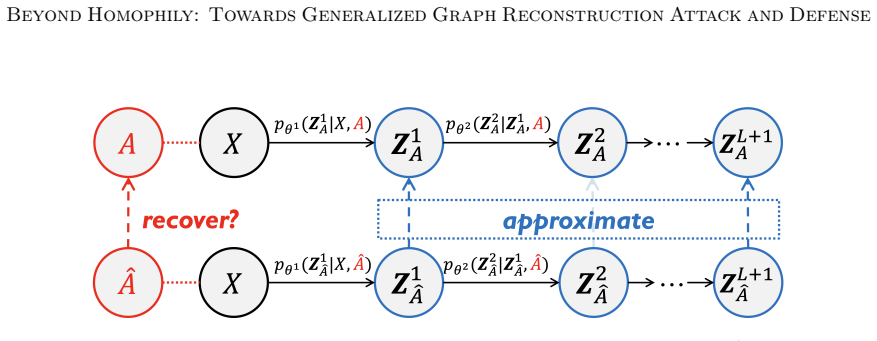
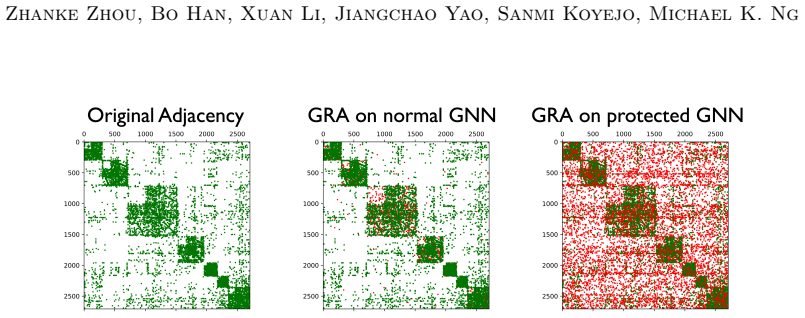
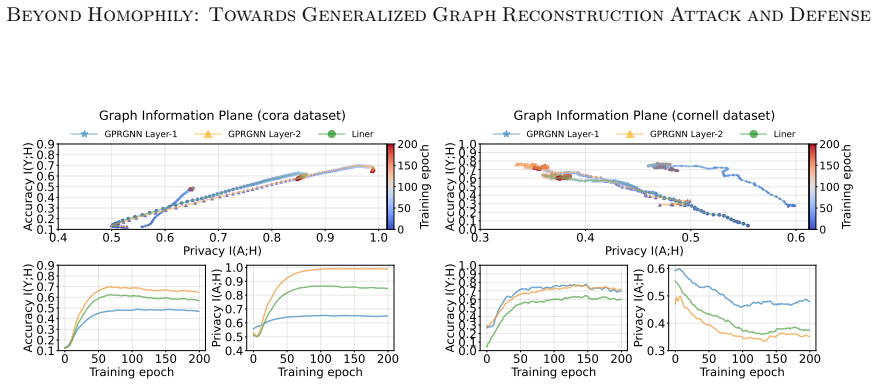
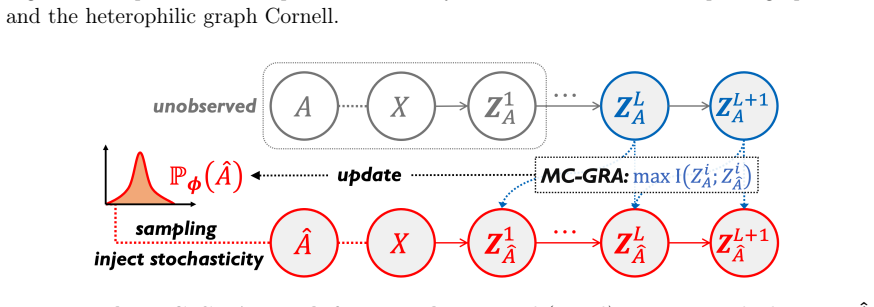
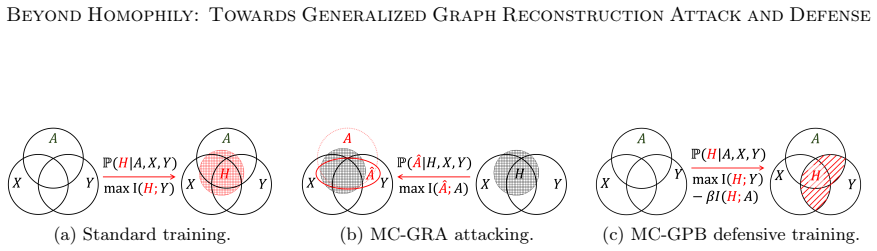
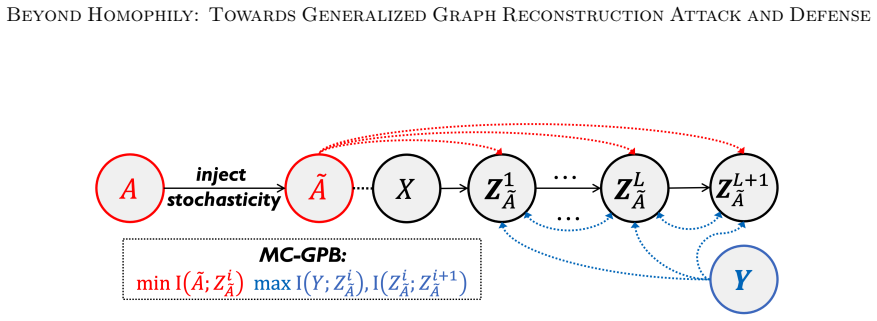
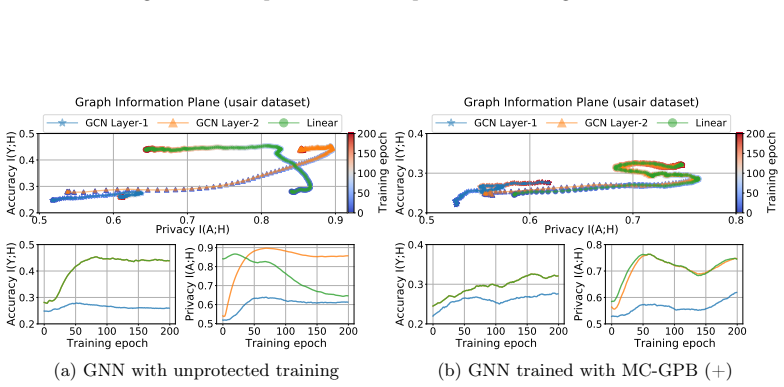
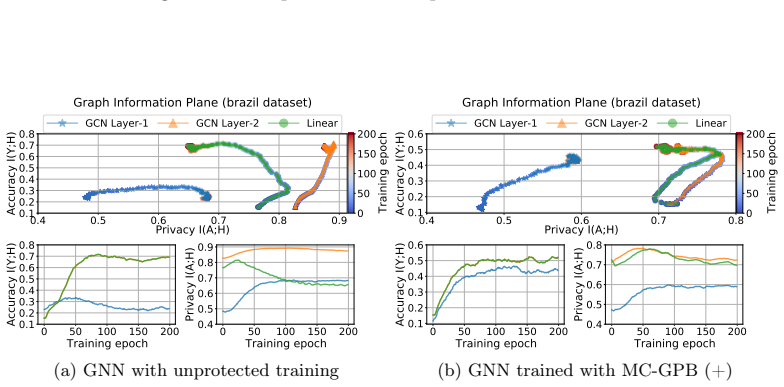
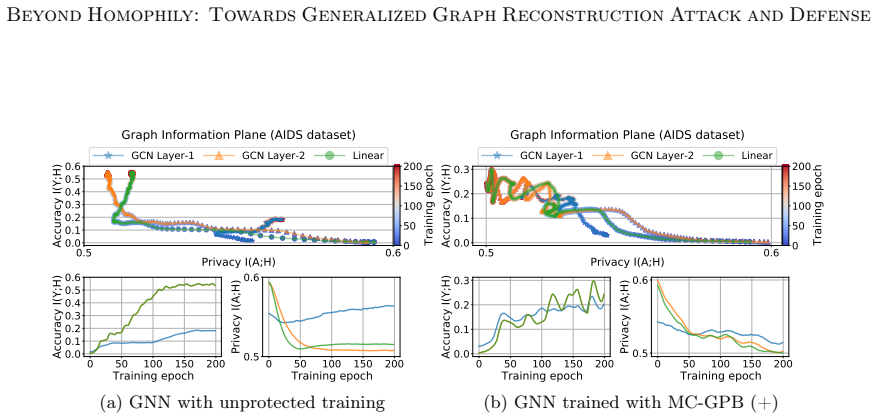
The paper claims that GNN inference admits a Markov chain approximation in which each layer produces representations whose dependence on the input topology can be tracked explicitly. Under this view the authors construct MC-GRA, an attack that searches for a surrogate adjacency whose induced representations align with those of the target model at every layer, and MC-GPB, a defense that suppresses adjacency-dependent information across the same chain subject to a classification-accuracy constraint. Systematic experiments on both homophilic and heterophilic benchmarks show that the attack recovers adjacency more faithfully than prior methods while the defense reduces reconstruction success wit
What carries the argument
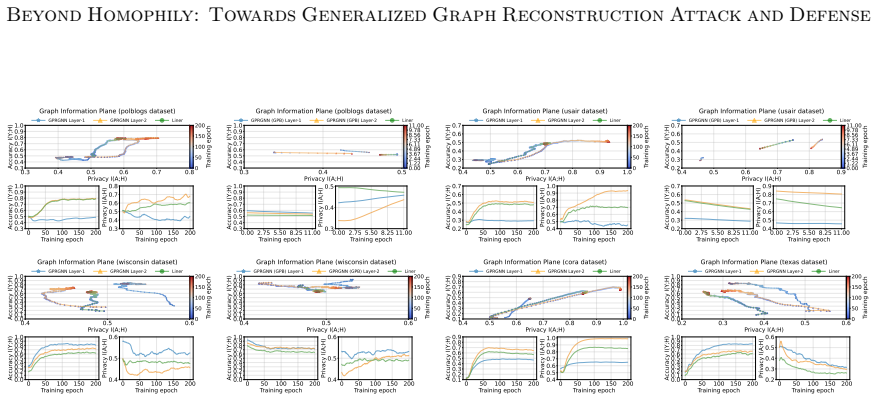
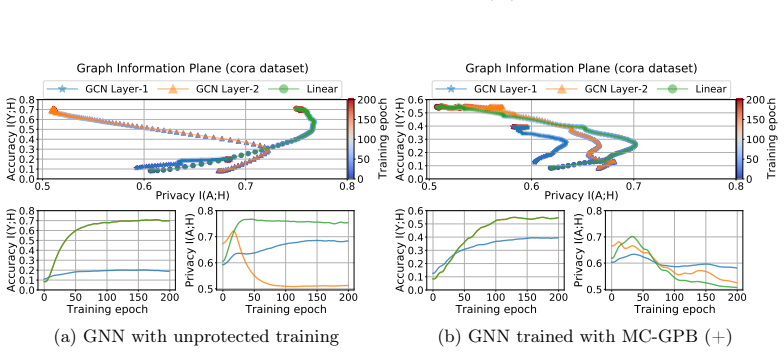
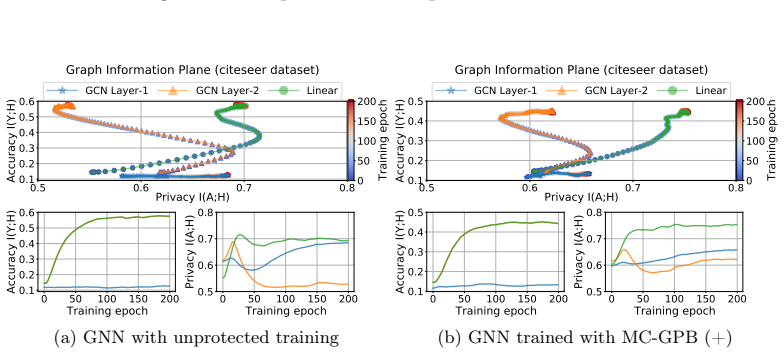
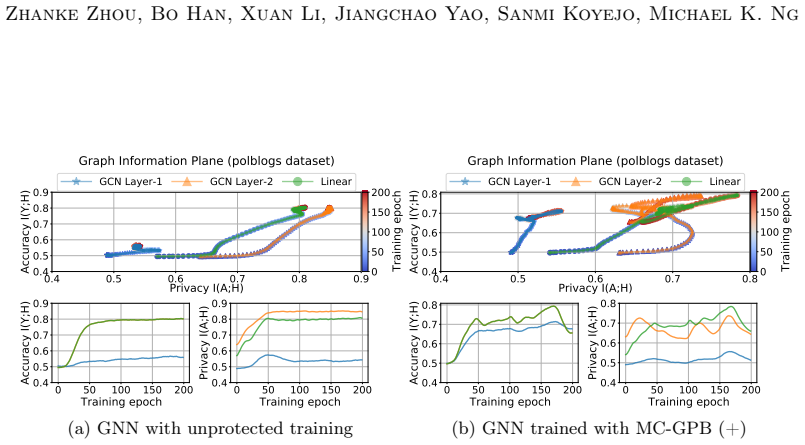
The Markov chain approximation that models the layered GNN forward computation as a sequence of topology-dependent representations, used to align surrogate and target representations for attack and to suppress adjacency signals for defense.
If this is right
- Reconstruction attacks achieve higher fidelity than prior methods on both homophilic and heterophilic graphs.
- Defenses suppress adjacency leakage while incurring only minor drops in classification accuracy.
- Leakage strength varies systematically with graph homophily, heterophily, and the GNN's inductive bias.
- The same Markov-chain view supports complementary attack and defense methods rather than treating them separately.
Where Pith is reading between the lines
- The same layer-wise alignment technique could be tested on deeper or attention-based GNN variants to check whether the Markov approximation remains useful.
- Deployed GNNs on social or transaction data may require routine application of the defense to limit exposure of private edges.
- The privacy-utility trade-off curve produced by the defense offers a concrete benchmark for comparing other privacy mechanisms on graphs.
Load-bearing premise
The layered forward computation of a GNN can be treated as a Markov chain of topology-dependent representations with enough accuracy to guide both attack optimization and defense suppression.
What would settle it
An experiment in which optimizing a surrogate adjacency under the Markov chain alignment objective fails to produce higher reconstruction fidelity than existing attack baselines, or in which the corresponding defense reduces reconstruction success only at the cost of large accuracy loss.
Figures
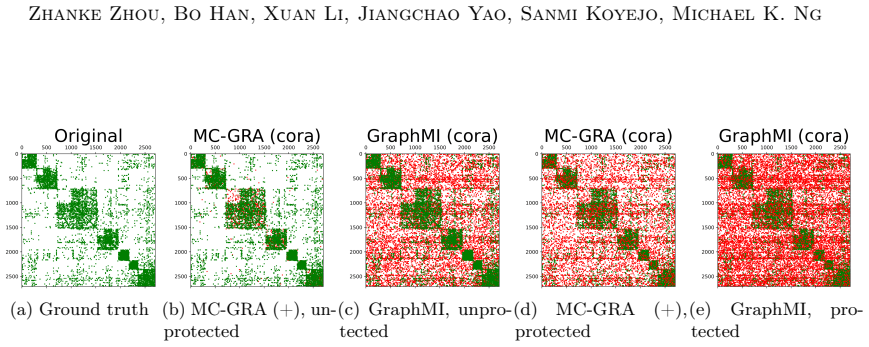
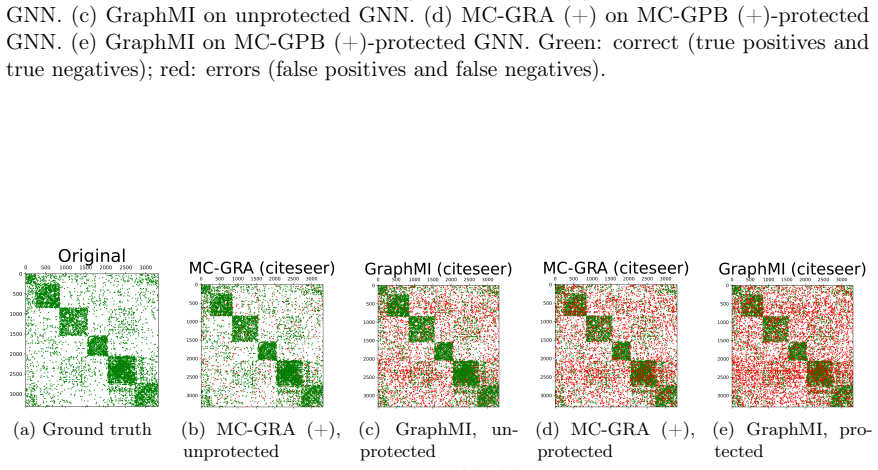
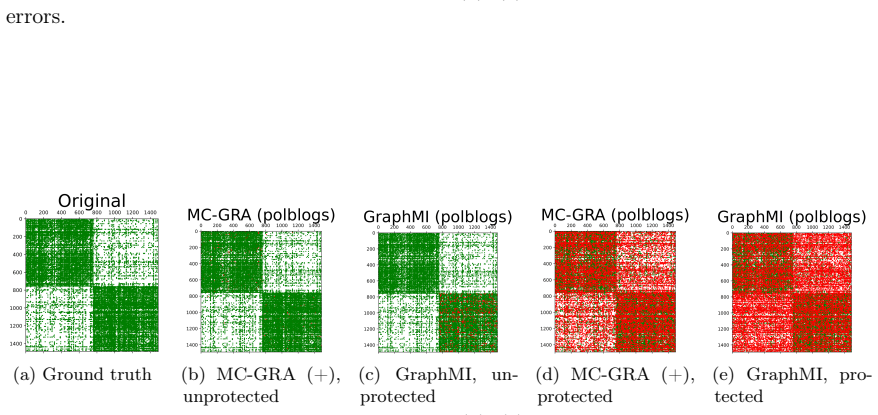
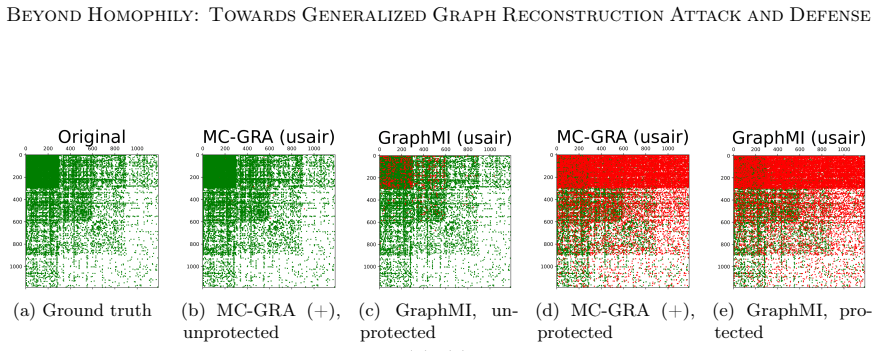
read the original abstract
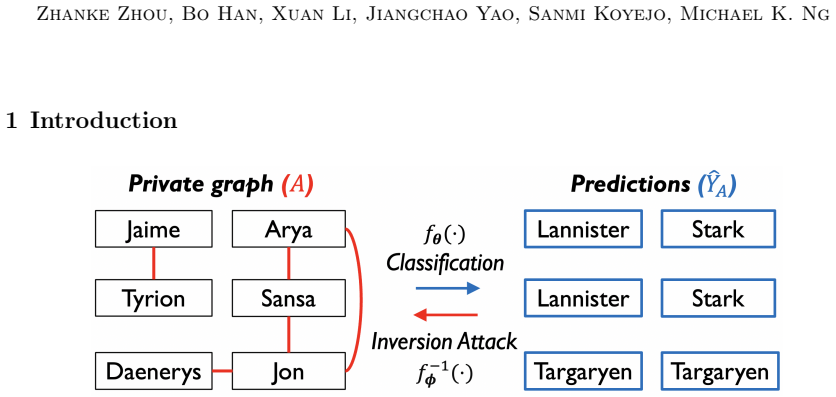
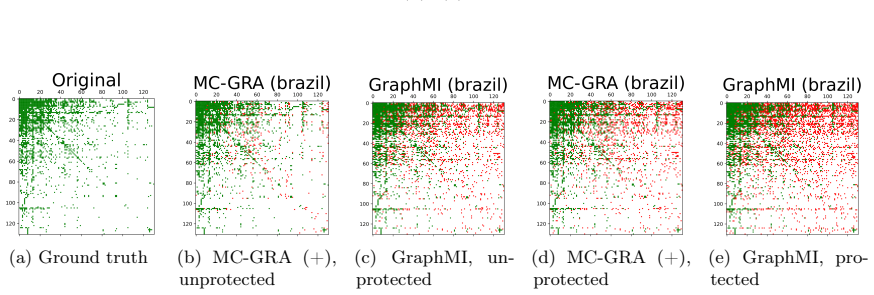
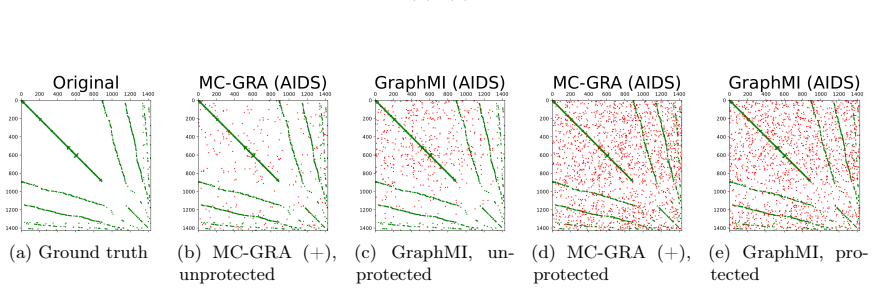
Graph neural networks (GNNs) are widely deployed on relational data, yet they can leak sensitive or proprietary information about the training graph adjacency, e.g., social ties, transactions, and interactions. This work studies graph reconstruction attacks (GRA), a form of model inversion that reconstructs the training adjacency from a trained GNN, given different levels of attacker-side information. We first provide a systematic characterization of when and why adjacency becomes recoverable through features, labels, embeddings, and predictions, with leakage modulated by graph homophily, heterophily, and the model's inductive bias. Motivated by these findings, we view GNN inference through a Markov chain approximation lens, treating the layered forward computation as a chain of topology-dependent representations. Building on this view, we develop complementary attack and defense methods. On the attack side, we propose MC-GRA (+), which reconstructs the adjacency by optimizing a surrogate adjacency whose GNN-induced representations align with those of the target model at each layer. On the defense side, we propose MC-GPB (+), which suppresses adjacency-dependent information throughout the representation chain while aiming to preserve classification accuracy under a privacy-utility trade-off. Experiments across homophilic/heterophilic graph benchmarks and GNNs show that our attacks improve reconstruction fidelity over prior methods, while our defenses reduce reconstruction success with only minor accuracy loss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modeling GNN forward passes via a Markov chain approximation of topology-dependent layer representations enables a generalized graph reconstruction attack (MC-GRA) that optimizes a surrogate adjacency to match target-model representations at each layer, together with a complementary defense (MC-GPB) that suppresses adjacency-dependent information under a privacy-utility trade-off. Systematic characterization of leakage under homophily/heterophily and inductive bias is provided, and experiments on homophilic/heterophilic benchmarks are said to show higher reconstruction fidelity for the attack and lower reconstruction success for the defense with only minor accuracy degradation.
Significance. If the Markov-chain view is accurate and the empirical gains are robust, the work supplies the first systematic treatment of GRA that explicitly targets both homophilic and heterophilic regimes and supplies concrete, complementary attack and defense primitives; this could inform privacy analysis of deployed GNNs on relational data.
major comments (2)
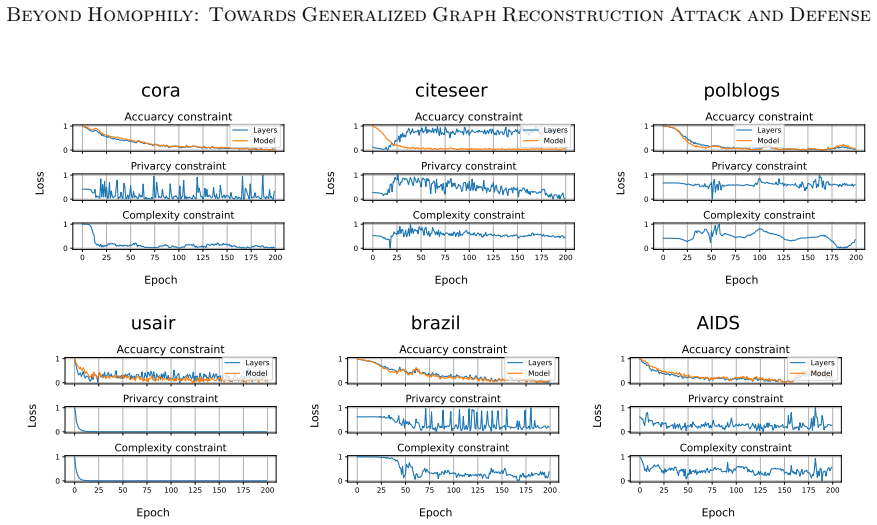
- [Method (Markov chain approximation)] The Markov chain approximation of layered GNN computation is load-bearing for both MC-GRA and MC-GPB; the manuscript must supply either error bounds on the approximation, an ablation that measures how closely the chain matches exact layer-wise representations, or a sensitivity study showing that attack/defense performance degrades when the approximation is replaced by exact forward passes.
- [Experiments] The central empirical claim (improved reconstruction fidelity and reduced attack success with minor accuracy loss) is asserted without reported ablation tables, statistical significance tests, or controls for post-hoc hyper-parameter selection; the experiments section must include these to establish that the reported gains are not artifacts of the evaluation protocol.
minor comments (2)
- Define the notation MC-GRA (+) and MC-GPB (+) explicitly; the parenthetical is used in the abstract but never explained.
- Add a short related-work paragraph that situates the Markov-chain lens against prior message-passing analyses or information-flow studies in GNNs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested validations and statistical controls.
read point-by-point responses
-
Referee: [Method (Markov chain approximation)] The Markov chain approximation of layered GNN computation is load-bearing for both MC-GRA and MC-GPB; the manuscript must supply either error bounds on the approximation, an ablation that measures how closely the chain matches exact layer-wise representations, or a sensitivity study showing that attack/defense performance degrades when the approximation is replaced by exact forward passes.
Authors: We agree that the Markov chain approximation is central to both methods. The manuscript motivates the view from the leakage characterization but does not provide quantitative validation against exact layer-wise passes. In the revision we will add a sensitivity study that substitutes exact forward passes (where computationally feasible) for the approximation and reports the resulting impact on reconstruction fidelity and defense performance. revision: yes
-
Referee: [Experiments] The central empirical claim (improved reconstruction fidelity and reduced attack success with minor accuracy loss) is asserted without reported ablation tables, statistical significance tests, or controls for post-hoc hyper-parameter selection; the experiments section must include these to establish that the reported gains are not artifacts of the evaluation protocol.
Authors: We acknowledge the need for stronger statistical support. The revised manuscript will add ablation tables for the core components of MC-GRA and MC-GPB, report results across multiple random seeds with standard deviations and significance tests, and document the hyper-parameter selection protocol to address post-hoc selection concerns. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
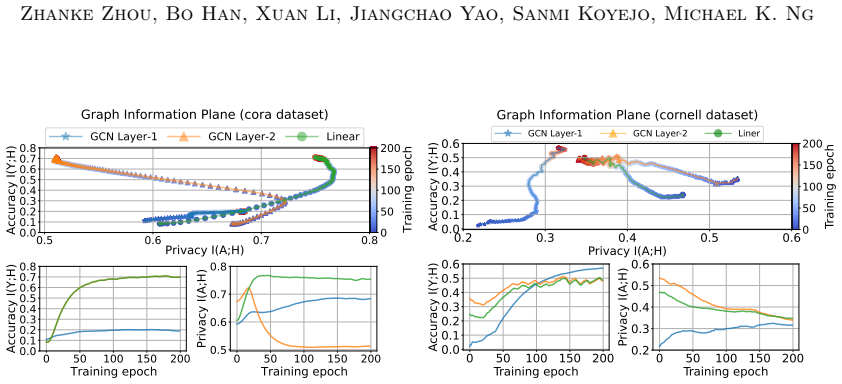
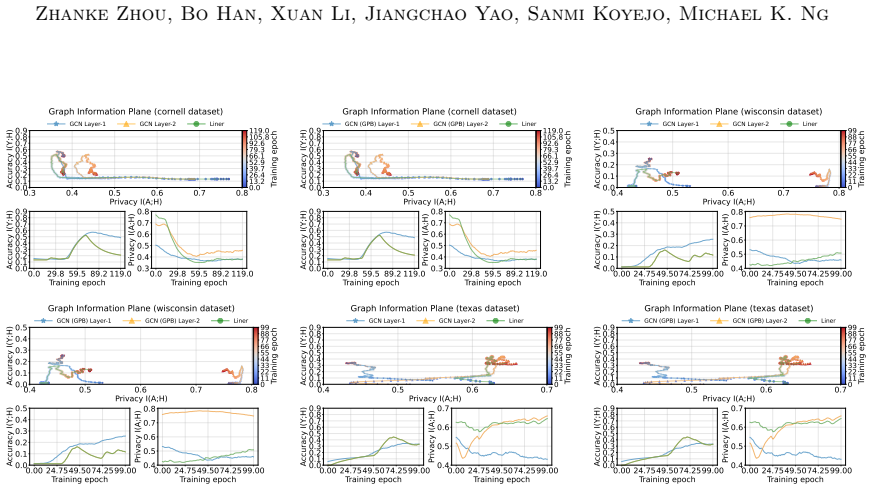
The paper motivates MC-GRA and MC-GPB via a Markov-chain view of layered GNN forward passes, then defines the attack as direct optimization of a surrogate adjacency to match per-layer representations and the defense as suppression of adjacency-dependent signals under a utility constraint. These are independent optimization objectives, not quantities fitted on one subset and then reported as predictions on the same data. No self-definitional equations, no fitted-input-called-prediction pattern, and no load-bearing self-citations that collapse the central result to its inputs appear in the abstract or claim description. Experiments on external homophilic/heterophilic benchmarks supply independent validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GNN forward passes can be usefully approximated as a Markov chain whose transition structure depends on the unknown adjacency
invented entities (2)
-
MC-GRA
no independent evidence
-
MC-GPB
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adamic and N
L. Adamic and N. Glance. The political blogosphere and the 2004 us election: divided they blog. InProceedings of the 3rd international workshop on Link discovery,
2004
-
[2]
S. Hidano and T. Murakami. Degree-preserving randomized response for graph neural networks under local differential privacy.arXiv preprint arXiv:2202.10209,
-
[3]
V. Ioannidis, Zheng, and G. Karypis. Few-shot link prediction via graph neural networks for covid-19 drug-repurposing.arXiv preprint arXiv:2007.10261,
arXiv 2007
-
[4]
Jayaraman, L
B. Jayaraman, L. Wang, K. Knipmeyer, Q. Gu, and D. Evans. Revisiting membership inference under realistic assumptions.Proceedings on Privacy Enhancing Technologies, 2021(2):348–368,
2021
-
[5]
M. Khosla. Privacy and transparency in graph machine learning: A unified perspective. arXiv preprint arXiv:2207.10896,
- [6]
-
[7]
A. M. Saxe, Y. Bansal, J. Dapello, M. Advani, A. Kolchinsky, B. D. Tracey, and D. D. Cox. On the information bottleneck theory of deep learning.Journal of Statistical Mechanics: Theory and Experiment, 2019(12):124020,
2019
-
[8]
R. Shwartz-Ziv and N. Tishby. Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810,
-
[9]
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199,
-
[10]
67 Zhanke Zhou, Bo Han, Xuan Li, Jiangchao Yao, Sanmi Koyejo, Michael K. Ng N. Tishby, F. Pereira, and W. Bialek. The information bottleneck method.arXiv preprint physics/0004057,
-
[11]
X. Wang, X. Liu, and C. Hsieh. Graphdefense: Towards robust graph convolutional networks. arXiv preprint arXiv:1911.04429,
arXiv 1911
-
[12]
Z. Yang, E. Chang, and Z. Liang. Adversarial neural network inversion via auxiliary knowledge alignment.arXiv preprint arXiv:1902.08552,
Pith/arXiv arXiv 1902
-
[13]
M. Zhang, P. Li, Y. Xia, K. Wang, and L. Jin. Labeling trick: A theory of using graph neural networks for multi-node representation learning. InNeurIPS, 2021a. R. Zhang, S. Hidano, and F. Koushanfar. Text revealer: Private text reconstruction via model inversion attacks against transformers.arXiv preprint arXiv:2209.10505, 2022a. Y. Zhang, R. Jia, H. Pei,...
-
[14]
Z. Zhang, Q. Liu, Z. Huang, H. Wang, C. Lu, C. Liu, and E. Chen. Graphmi: Extracting private graph data from graph neural networks. InIJCAI, 2021b. Z. Zhang, M. Chen, M. Backes, Y. Shen, and Y. Zhang. Inference attacks against graph neural networks. InUSENIX Security, 2022b. T. Zhao, G. Liu, D. Wang, W. Yu, and M. Jiang. Learning from counterfactual links...
-
[15]
=H(W t |W 1). A.2 Proof of Theorem 8 ProofWe prove the theorem for the layer-map template (GCN-type form) stated in the main text; the argument uses only the data processing inequality for deterministic measurable maps. We first recall two standard facts about mutual information under measurable transformations. Lemma 24(Invariance under bijections).Let X...
1999
-
[16]
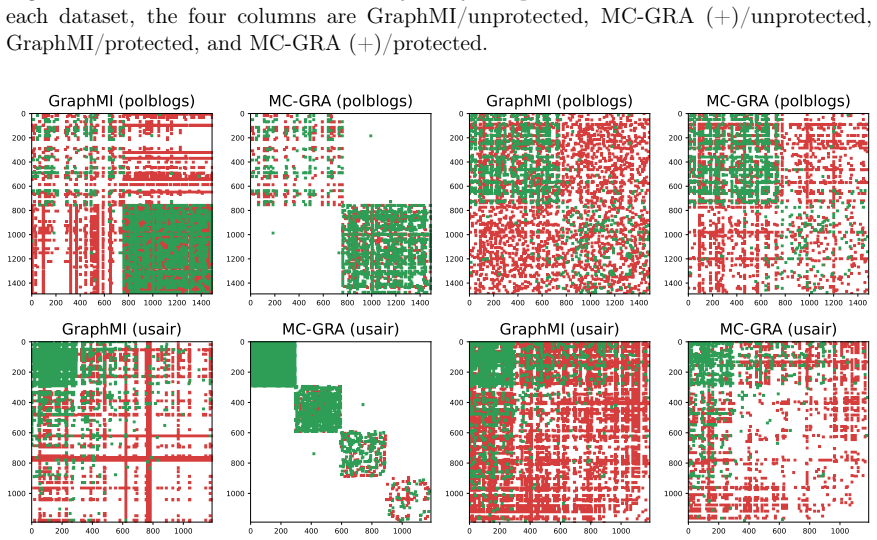
Node features do not always exist (e.g., Polblogs, USA, Brazil), so this setting is practically relevant
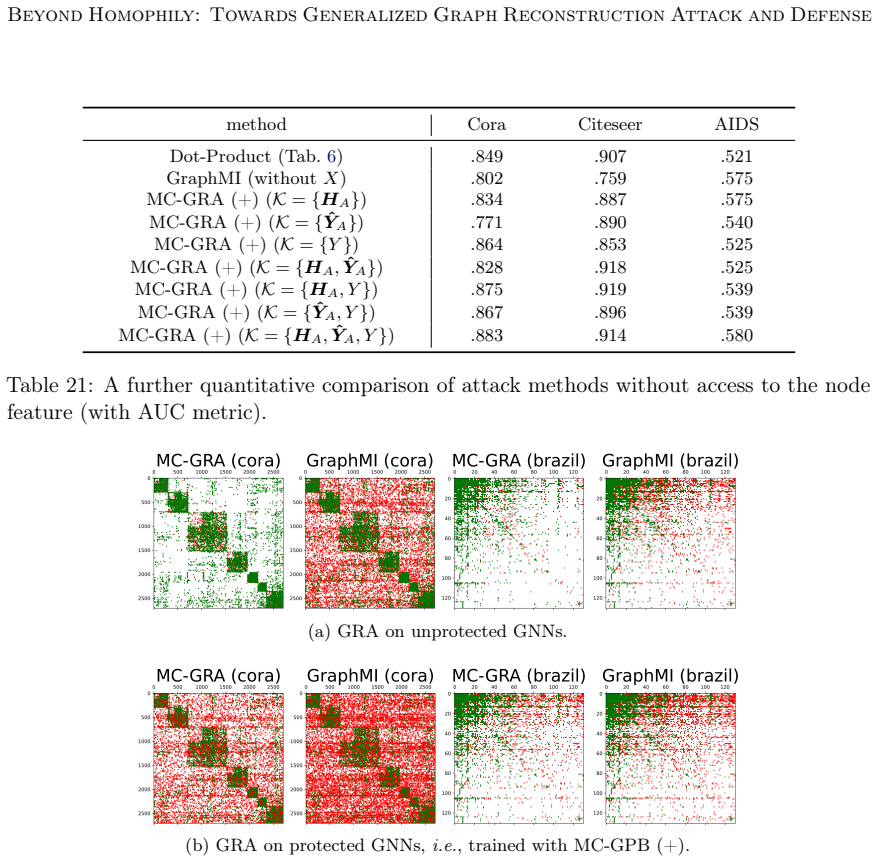
show that MC-GRA (+) remains effective whenX is omitted; adjacency can be recovered from labels, hidden representations, and predictions alone. Node features do not always exist (e.g., Polblogs, USA, Brazil), so this setting is practically relevant. Why does classification accuracy sometimes improve under MC-GPB (+)? Tab. 11 shows that MC-GPB (+) can impr...
2022
-
[17]
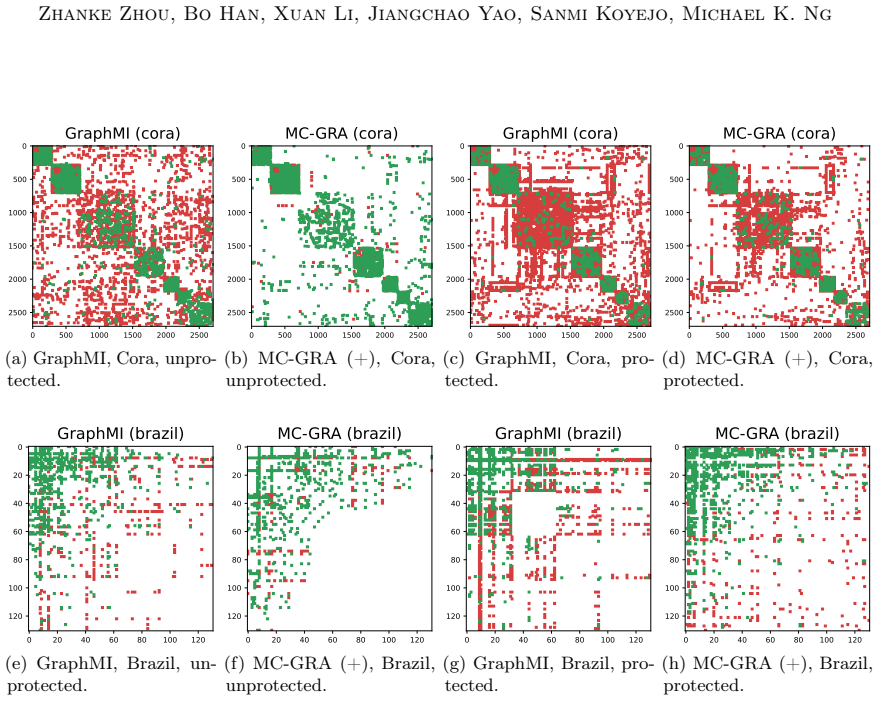
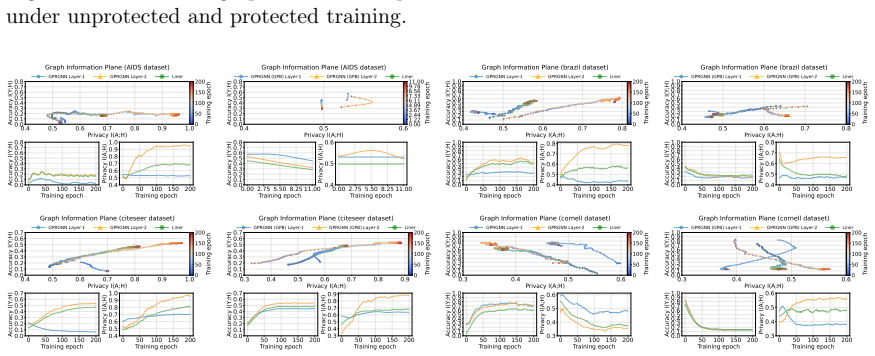
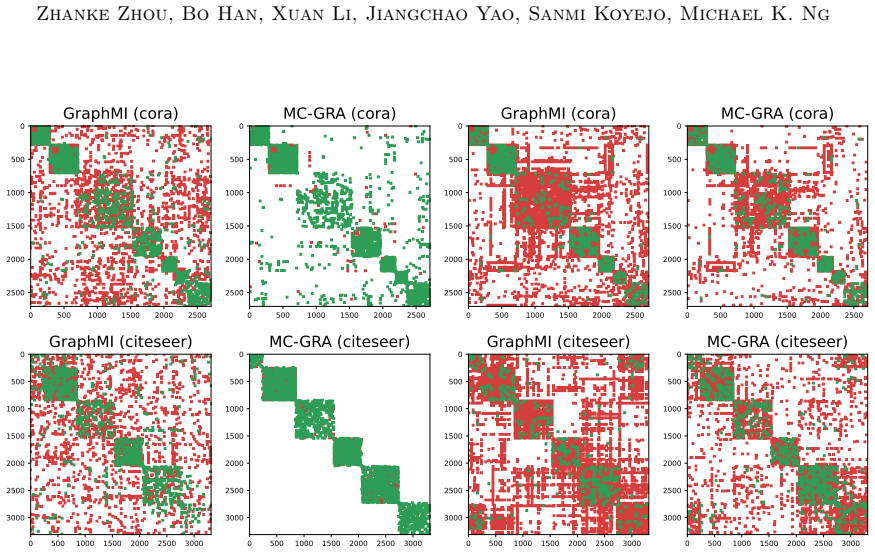
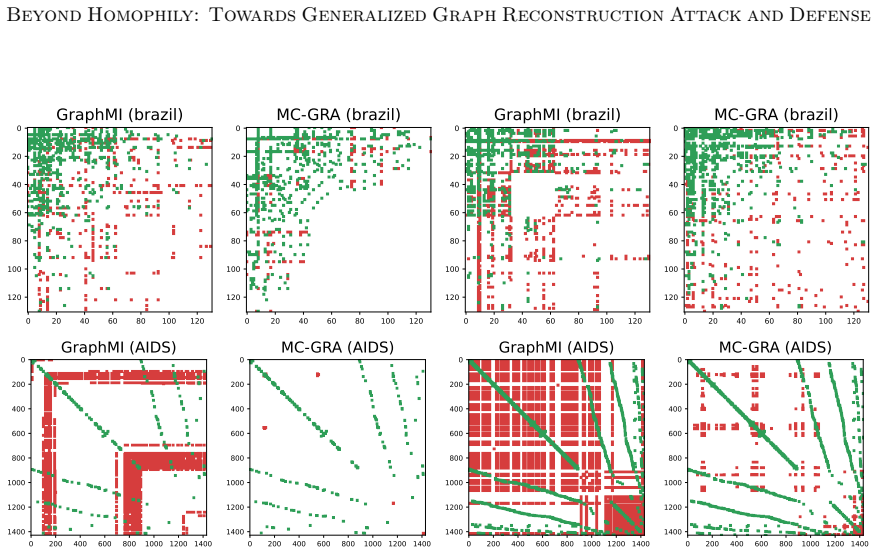
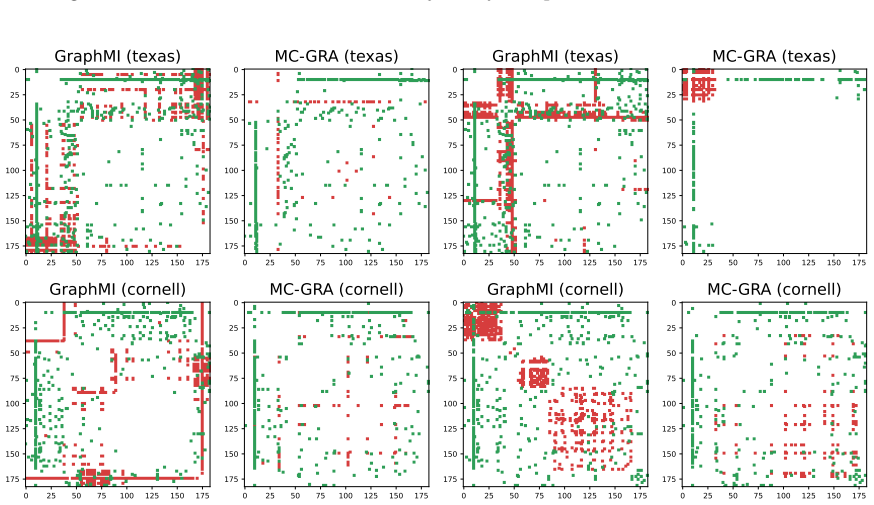
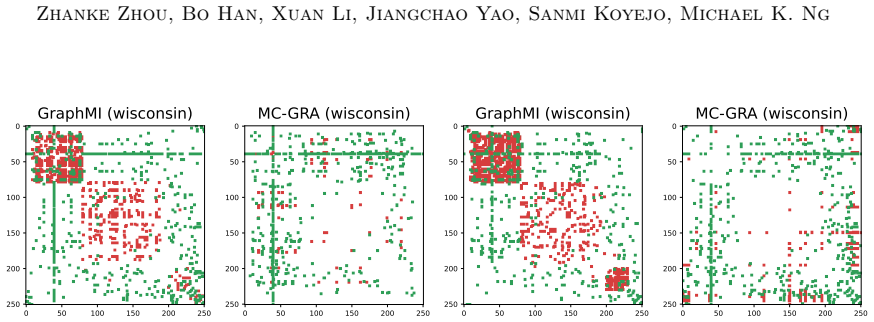
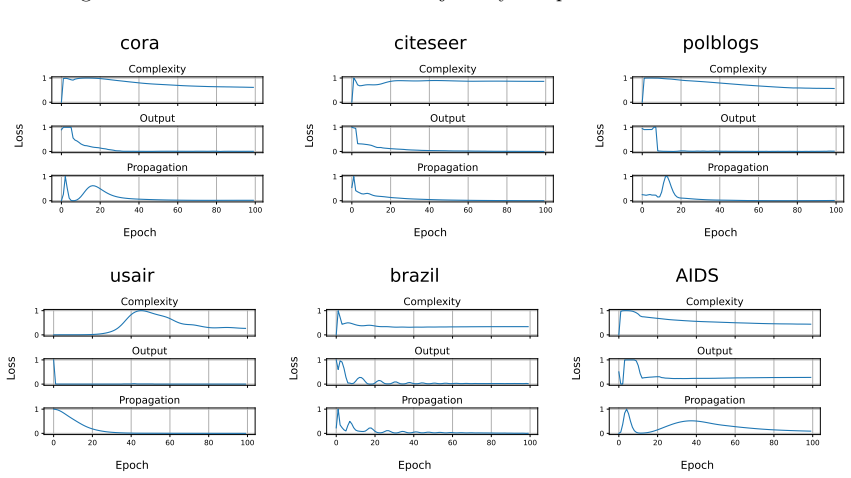
Green: correct; red: errors. Additional qualitative results with the updated plotting pipeline.To complement the visualizations above, we include additional figures from the same plotting pipeline as in the main paper, grouped by model and task. Tracking the MI terms.We show the learning curves of MC-GRA (+) and MC- GPB (+) on each dataset below. For MC-G...
arXiv 2013
-
[18]
These methods share a focus on generative priors and gradient-based search in a learned or fixed latent space
further reduces computational cost and broadens applicability by decoupling the generator from the classifier; a single off-the-shelf GAN suffices to attack multiple targets with minimal fine-tuning, demonstrating that MIA remains practical even under substantial domain shifts. These methods share a focus on generative priors and gradient-based search in ...
2000
-
[19]
observes that the cross-entropy objective adopted in earlier attacks (Zhang et al., 2020; Chen et al.,
2020
-
[20]
91 Zhanke Zhou, Bo Han, Xuan Li, Jiangchao Yao, Sanmi Koyejo, Michael K
introduces a coarse-to-fine refinement stage that boosts visual quality in strict black-box settings. 91 Zhanke Zhou, Bo Han, Xuan Li, Jiangchao Yao, Sanmi Koyejo, Michael K. Ng 0 50 100 150 200 250 0 50 100 150 200 250 GraphMI (wisconsin) 0 50 100 150 200 250 0 50 100 150 200 250 MC-GRA (wisconsin) 0 50 100 150 200 250 0 50 100 150 200 250 GraphMI (wisco...
2014
-
[21]
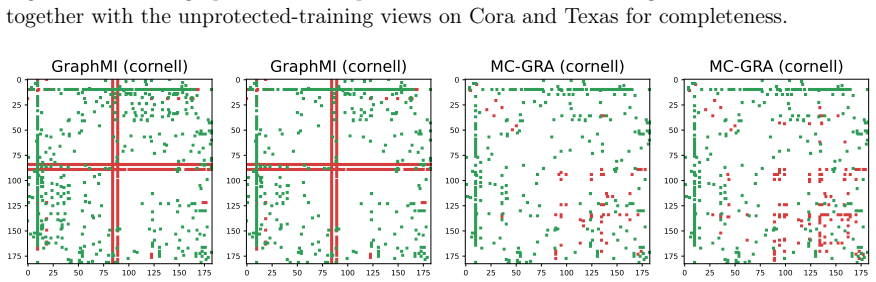
Although both defenses heavily distort the attacker’s reconstructions, they also degrade accuracy, underscoring the difficulty of achieving a favorable privacy-utility trade-off
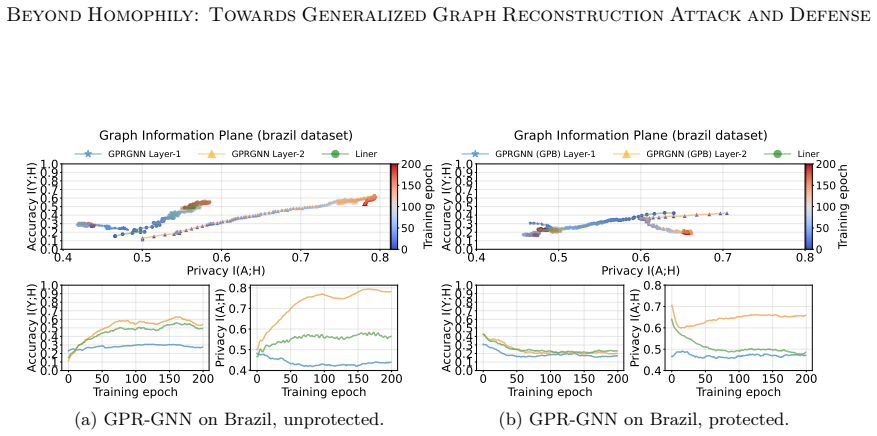
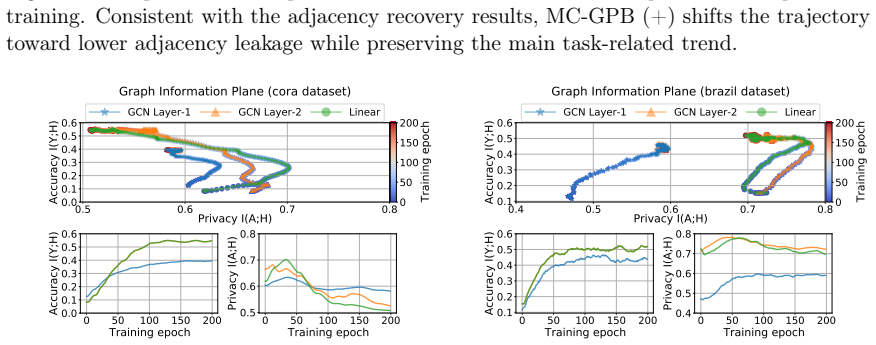
simultaneously suppresses I(X; Z), removing redundant cues from latent features, and maximizes I(Y ; Z)to preserve task relevance. Although both defenses heavily distort the attacker’s reconstructions, they also degrade accuracy, underscoring the difficulty of achieving a favorable privacy-utility trade-off. Therefore, principled and practical defenses ag...
2021
-
[22]
Information-theoretic attacks instead train an auxiliary decoder to infer words directly from embeddings (Song and Raghunathan, 2020), and GEIA (Li et al.,
treats inversion as controlled embedding optimization, iteratively refining candidate text so its embedding converges to a target. Information-theoretic attacks instead train an auxiliary decoder to infer words directly from embeddings (Song and Raghunathan, 2020), and GEIA (Li et al.,
2020
-
[23]
Defenses.Most defenses perturb the embedding space to obscure the mapping between internal representations and plaintext
eliminates query dependence: it first steals a surrogate model and then adversarially trains an inversion decoder against that surrogate, enabling fully query-free attacks. Defenses.Most defenses perturb the embedding space to obscure the mapping between internal representations and plaintext. Chen et al. (2024) prepend a language-ID mask to token embeddi...
2024
-
[24]
removes this constraint: a sparse encoder-decoder conditioned solely on generated text recovers system prompts with high cosine similarity to the originals, showing that output-level defenses remain an open problem. Beyond the centralized setting surveyed above, graph reconstruction attacks have also been studied in federated learning settings, where grad...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.