Differentially Private Synthetic Data via APIs 4: Tabular Data
Pith reviewed 2026-06-27 19:57 UTC · model grok-4.3
The pith
Tab-PE evolves synthetic tabular data under differential privacy to better preserve high-order correlations than marginal-based methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
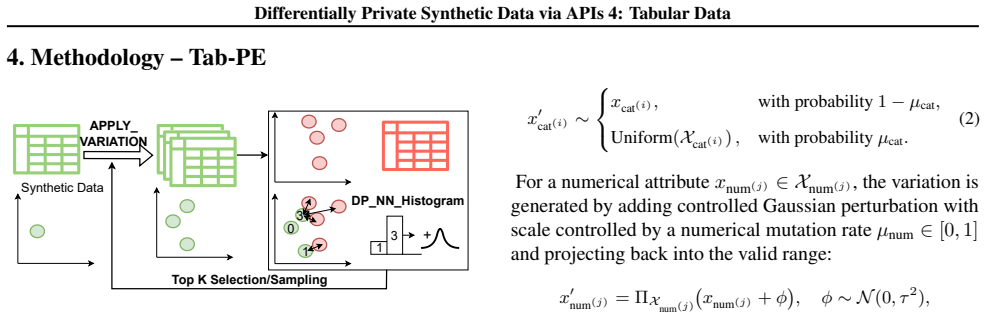
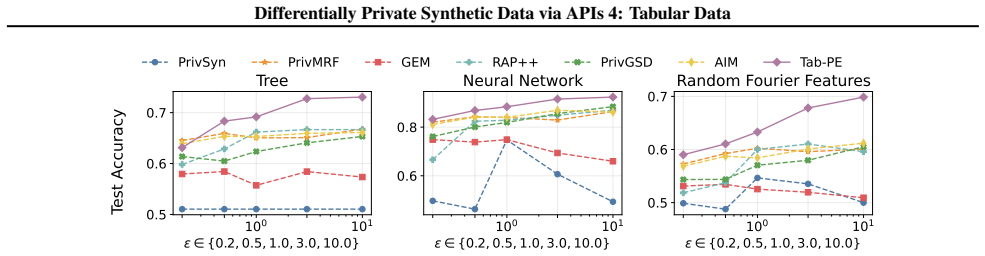
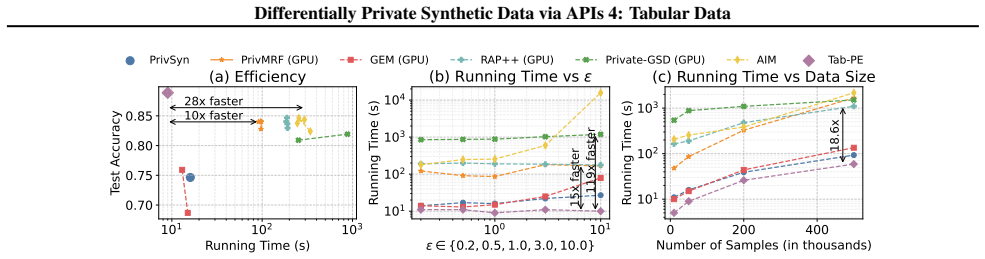
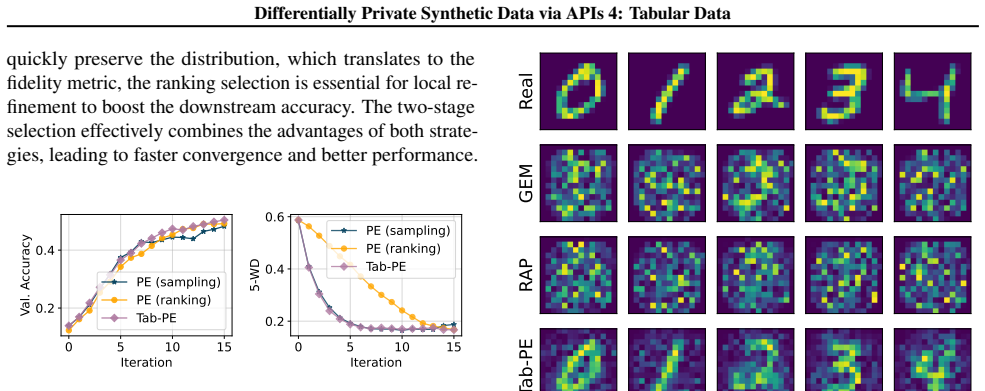
Tab-PE iteratively improves a candidate dataset via an evolutionary process that leverages tabular-specialized operators to produce variations, privately scores them, and selects the highest-quality samples to retain and propagate. In contrast to the original PE, which relies on large foundation models, Tab-PE employs heuristic operators with significantly lower computational costs. Through extensive experiments on real-world and simulation datasets, Tab-PE substantially outperforms prior baselines on datasets exhibiting high-order correlations, improving classification accuracy by up to 10 percent while running 28 times faster than AIM.
What carries the argument
Tab-PE evolutionary loop, which applies tabular heuristic operators to generate variations, privately evaluates quality, and propagates top samples under differential privacy.
If this is right
- Synthetic tabular data produced by Tab-PE supports higher-accuracy machine learning models on tasks involving feature interactions.
- The approach scales to larger tabular datasets because the operators avoid the cost of foundation models.
- Differential privacy can be enforced on tabular synthesis while retaining more utility on correlated features than low-order marginal methods allow.
Where Pith is reading between the lines
- The same evolutionary pattern with domain-specific cheap operators may apply to other structured data formats beyond tables.
- Lowering dependence on large models could make differentially private synthesis practical in resource-limited settings.
- Designing additional operators tuned to specific correlation patterns might further close the utility gap on particular datasets.
Load-bearing premise
Heuristic operators with low computational cost are sufficient to generate useful variations that capture high-order correlations under differential privacy constraints.
What would settle it
A controlled test on a dataset with documented high-order correlations in which Tab-PE fails to exceed AIM in classification accuracy or runtime after multiple evolution iterations.
Figures








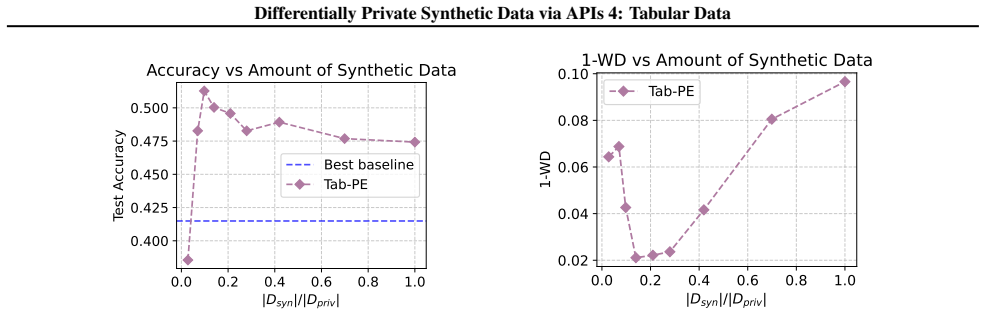
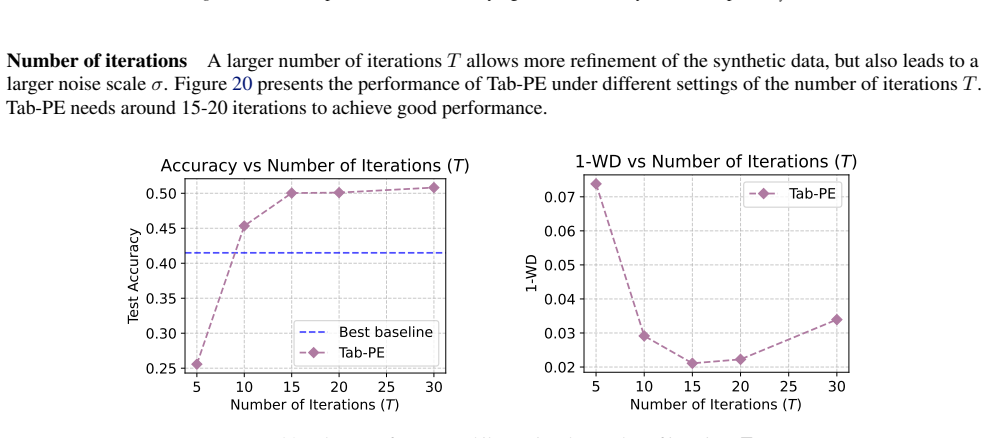

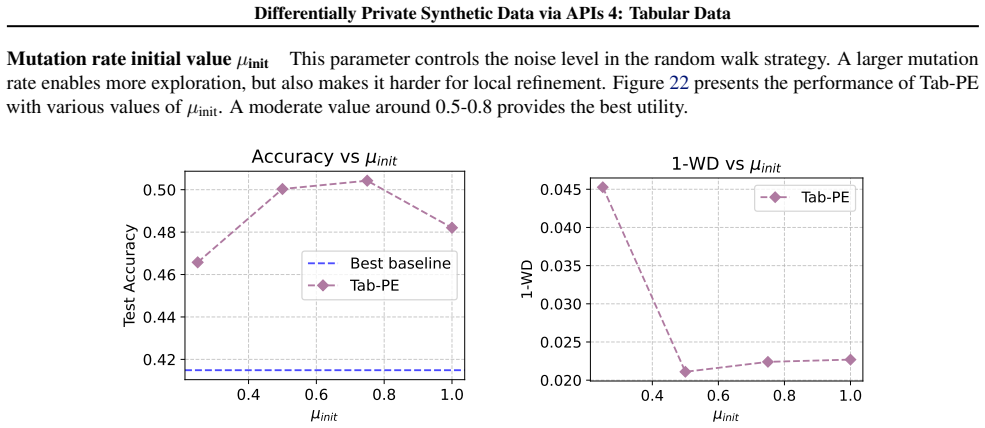
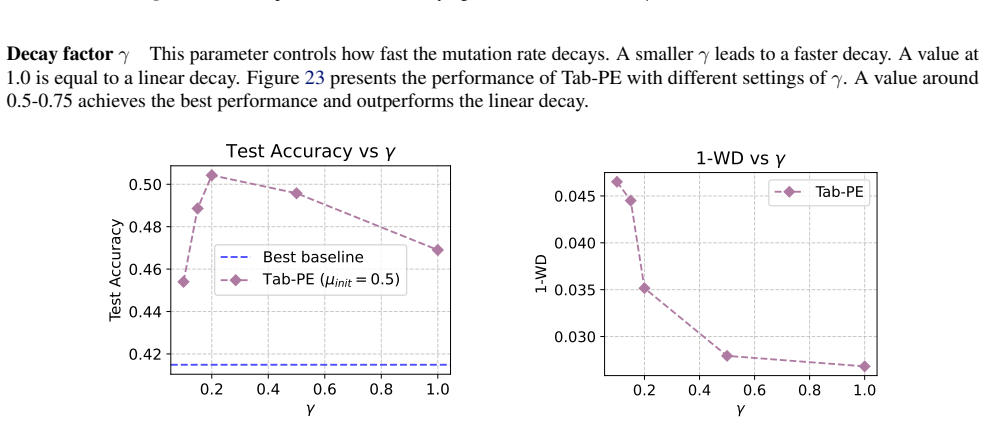
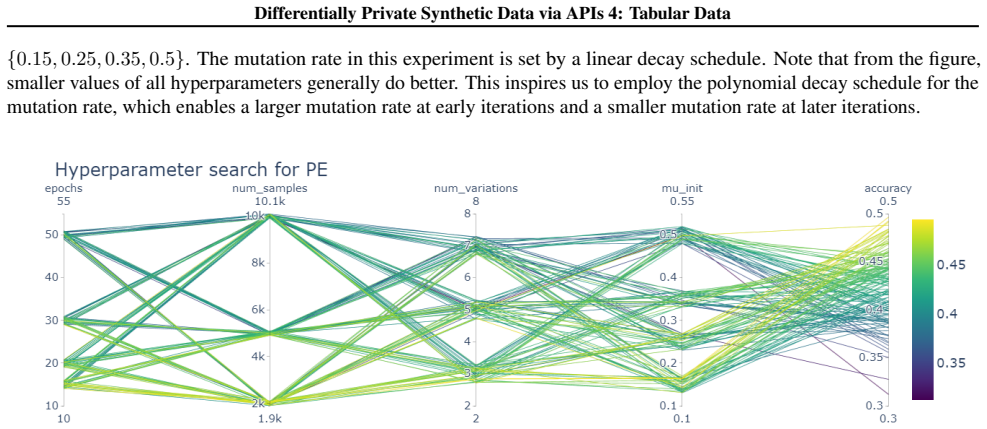
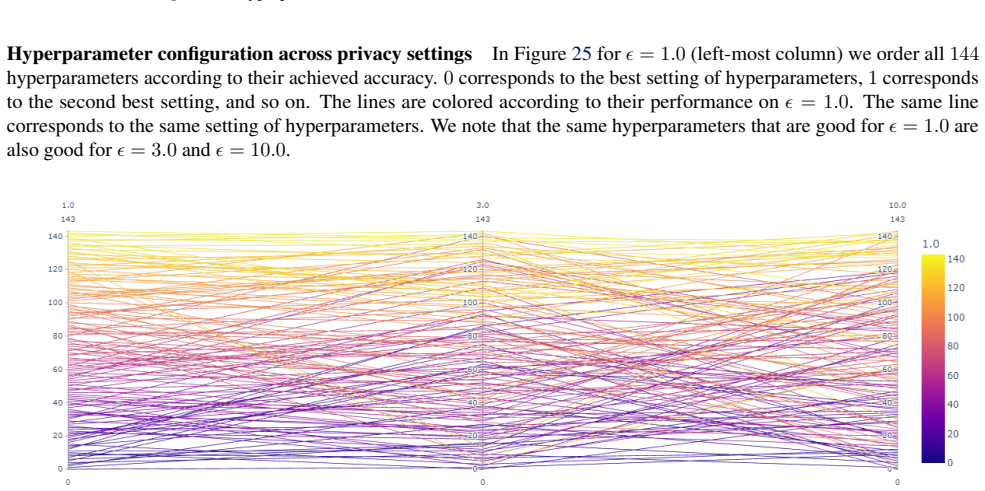
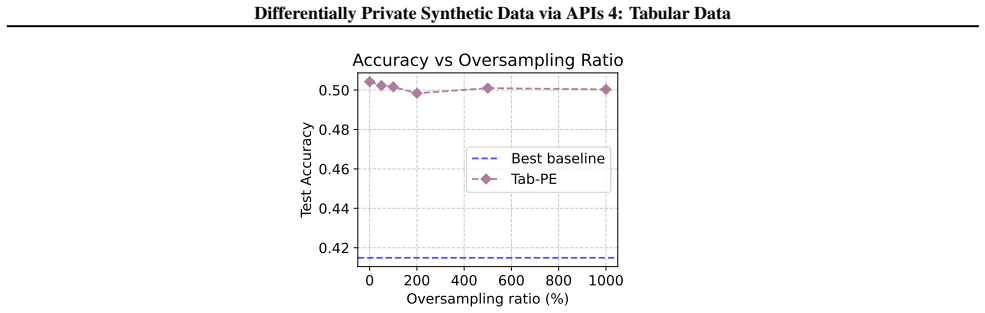
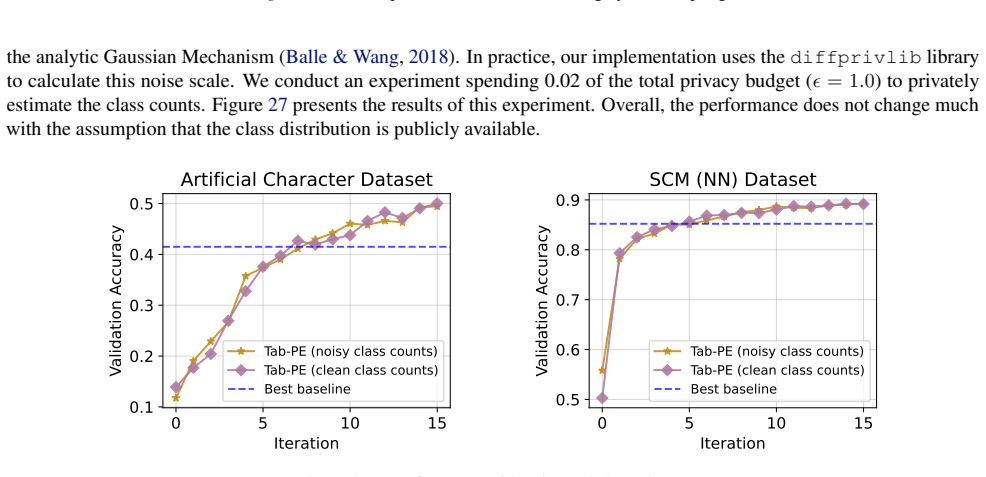
read the original abstract
This paper investigates the problem of generating synthetic tabular data with differential privacy (DP) guarantees, enabling data sharing in sensitive domains. Despite extensive study, state-of-the-art methods often focus on minimizing low-order marginal query errors and overlook the challenges posed by high-order correlations. To address this gap, we extend the Private Evolution (PE) framework, originally developed for DP-compliant image and text synthesis, to tabular data. We introduce Tab-PE -- an algorithm for synthetic tabular data generation under DP constraints. Tab-PE iteratively improves a candidate dataset via an evolutionary process that leverages tabular-specialized operators to produce variations, privately scores them, and selects the highest-quality samples to retain and propagate. In contrast to the original PE, which relies on large foundation models, Tab-PE employs heuristic operators with significantly lower computational costs, making PE more practical and scalable for tabular data. Through extensive experiments on real-world and simulation datasets, we demonstrate that Tab-PE substantially outperforms prior baselines on datasets exhibiting high-order correlations. Compared to the best baseline -- AIM, Tab-PE improves classification accuracy by up to 10% while running 28 times faster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the Private Evolution (PE) framework to tabular data via Tab-PE, which uses heuristic operators (instead of foundation models) in an evolutionary loop of variation generation, private scoring, and selection to produce DP synthetic tabular data. It claims that on datasets with high-order correlations, Tab-PE outperforms the best baseline (AIM) by up to 10% classification accuracy while running 28x faster, addressing limitations of prior methods focused on low-order marginals.
Significance. If the empirical claims hold and the heuristic operators demonstrably recover high-order interactions under DP, the work would provide a practical, scalable alternative to both marginal-based DP synthesizers and expensive foundation-model PE methods for tabular data, with direct utility for downstream ML tasks in sensitive domains.
major comments (3)
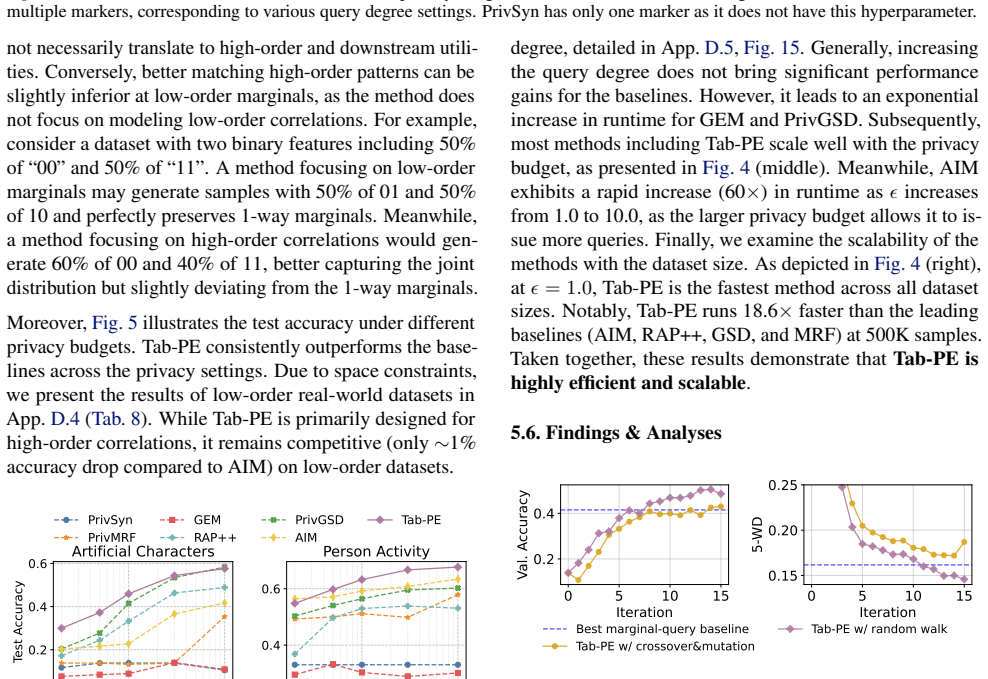
- [Abstract and §3 (algorithm description)] The central claim that Tab-PE captures high-order correlations (Abstract) rests on the heuristic operators generating variations that allow private selection to recover k-way interactions for k>2. No explicit construction, proof sketch, or targeted ablation is provided showing that low-cost local edits (row/column swaps, single-feature perturbations) propagate higher-order signals rather than merely refining low-order marginals under the added DP noise.
- [§4] §4 (experiments): the reported gains (up to 10% accuracy, 28x speed vs. AIM) are presented without error bars, statistical significance tests, or dataset characterizations that quantify the degree of high-order correlation present; this makes it impossible to attribute improvements specifically to high-order recovery versus better low-order fidelity.
- [§4.3] No ablation isolating the contribution of the evolutionary loop versus the private scoring/selection step is reported, leaving open whether the advertised high-order advantage is load-bearing or could be achieved by simpler marginal methods with the same operators.
minor comments (2)
- [§3] Notation for privacy parameters (ε, δ) and the exact form of the private scoring function should be stated explicitly in §3 rather than left implicit from the original PE papers.
- The title references 'via APIs 4'; a brief sentence situating Tab-PE relative to the prior papers in the series would improve context.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point-by-point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3 (algorithm description)] The central claim that Tab-PE captures high-order correlations (Abstract) rests on the heuristic operators generating variations that allow private selection to recover k-way interactions for k>2. No explicit construction, proof sketch, or targeted ablation is provided showing that low-cost local edits (row/column swaps, single-feature perturbations) propagate higher-order signals rather than merely refining low-order marginals under the added DP noise.
Authors: We agree that the current manuscript lacks an explicit discussion or targeted ablation clarifying how the heuristic operators enable recovery of k>2 interactions. The operators are intended to allow iterative mixing that propagates higher-order signals through selection, but this rationale is only implicit. In the revised version we will add a short explanatory paragraph in §3 describing the mechanism by which local edits can surface higher-order dependencies under the evolutionary loop, together with a focused ablation measuring higher-order marginal fidelity. revision: yes
-
Referee: [§4] §4 (experiments): the reported gains (up to 10% accuracy, 28x speed vs. AIM) are presented without error bars, statistical significance tests, or dataset characterizations that quantify the degree of high-order correlation present; this makes it impossible to attribute improvements specifically to high-order recovery versus better low-order fidelity.
Authors: The referee correctly notes the absence of error bars, significance testing, and quantitative high-order correlation metrics. These omissions weaken attribution of gains. We will revise §4 to report means and standard deviations over multiple independent runs, include paired statistical tests for accuracy differences, and add dataset characterizations (e.g., average k-way mutual information for k=3,4) that quantify the presence of higher-order structure. revision: yes
-
Referee: [§4.3] No ablation isolating the contribution of the evolutionary loop versus the private scoring/selection step is reported, leaving open whether the advertised high-order advantage is load-bearing or could be achieved by simpler marginal methods with the same operators.
Authors: We acknowledge that an ablation separating the iterative evolutionary loop from a single application of the operators plus private scoring is missing. Such an experiment would clarify whether iteration is essential. In the revised manuscript we will add this ablation in §4.3, comparing full Tab-PE against a non-iterative baseline that applies the same operators and scoring once, to demonstrate the contribution of the evolutionary process to high-order fidelity. revision: yes
Circularity Check
No significant circularity in empirical claims
full rationale
The paper describes an algorithmic extension (Tab-PE) of the Private Evolution framework using heuristic operators for DP synthetic tabular data and supports its claims solely through empirical experiments comparing classification accuracy and runtime against baselines like AIM. No mathematical derivations, equations, fitted parameters, or uniqueness theorems are present that could reduce any prediction or result to inputs by construction. Any reference to the original PE framework functions as background rather than a load-bearing self-citation chain for the new empirical results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Differentially Private Synthetic Data via Foundation Model APIs 2: Text , author=. 2024 , eprint=
2024
-
[2]
arXiv preprint arXiv:2502.05505 , year=
Differentially private synthetic data via apis 3: Using simulators instead of foundation model , author=. arXiv preprint arXiv:2502.05505 , year=
-
[3]
Differentially Private Synthetic Data via Foundation Model
Zinan Lin and Sivakanth Gopi and Janardhan Kulkarni and Harsha Nori and Sergey Yekhanin , booktitle=. Differentially Private Synthetic Data via Foundation Model. 2024 , url=
2024
-
[4]
30th USENIX Security Symposium (USENIX Security 21) , pages=
PrivSyn: Differentially private data synthesis , author=. 30th USENIX Security Symposium (USENIX Security 21) , pages=
-
[5]
Proceedings of the VLDB Endowment , volume=
Data synthesis via differentially private markov random fields , author=. Proceedings of the VLDB Endowment , volume=. 2021 , publisher=
2021
-
[6]
Advances in Neural Information Processing Systems , year=
Private Synthetic Data for Multitask Learning and Marginal Queries , author=. Advances in Neural Information Processing Systems , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Iterative methods for private synthetic data: Unifying framework and new methods , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
2021 , eprint=
Differentially Private Query Release Through Adaptive Projection , author=. 2021 , eprint=
2021
-
[9]
International Conference on Machine Learning , pages=
Generating private synthetic data with genetic algorithms , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[10]
arXiv preprint arXiv:2201.12677 , year=
Aim: An adaptive and iterative mechanism for differentially private synthetic data , author=. arXiv preprint arXiv:2201.12677 , year=
-
[11]
arXiv preprint arXiv:2411.03351 , year=
Tabular data synthesis with differential privacy: A survey , author=. arXiv preprint arXiv:2411.03351 , year=
-
[12]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Synthetic Tabular Data: Methods, Attacks and Defenses , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[13]
2025 , eprint=
Benchmarking Differentially Private Tabular Data Synthesis , author=. 2025 , eprint=
2025
-
[14]
2022 , eprint=
Benchmarking Differentially Private Synthetic Data Generation Algorithms , author=. 2022 , eprint=
2022
-
[15]
Jingang Qu and David Holzm. Tab. Forty-second International Conference on Machine Learning , year=
-
[16]
Sajjadi, Mehdi S. M. and Bachem, Olivier and Lucic, Mario and Bousquet, Olivier and Gelly, Sylvain , booktitle =. Assessing Generative Models via Precision and Recall , volume =
-
[17]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Accurate predictions on small data with a tabular foundation model , author=. Nature , year=. doi:10.1038/s41586-024-08328-6 , publisher=
-
[18]
International Conference on Learning Representations 2023 , year=
TabPFN: A transformer that solves small tabular classification problems in a second , author=. International Conference on Learning Representations 2023 , year=
2023
-
[19]
arXiv preprint arXiv:2502.06555 , year=
Is API Access to LLMs Useful for Generating Private Synthetic Tabular Data? , author=. arXiv preprint arXiv:2502.06555 , year=
-
[20]
The algorithmic foundations of differential privacy.Found
Dwork, Cynthia and Roth, Aaron , title =. 2014 , issue_date =. doi:10.1561/0400000042 , journal =
-
[21]
Differential Privacy
Dwork, Cynthia. Differential Privacy. Automata, Languages and Programming. 2006
2006
-
[22]
Deep Neural Networks and Tabular Data: A Survey , year=
Borisov, Vadim and Leemann, Tobias and Seßler, Kathrin and Haug, Johannes and Pawelczyk, Martin and Kasneci, Gjergji , journal=. Deep Neural Networks and Tabular Data: A Survey , year=
-
[23]
Li, Haoran and Xiong, Li and Zhang, Lifan and Jiang, Xiaoqian , title =. Proc. VLDB Endow. , month = aug, pages =. 2014 , issue_date =. doi:10.14778/2733004.2733059 , abstract =
-
[24]
2024 , eprint=
Differentially Private Tabular Data Synthesis using Large Language Models , author=. 2024 , eprint=
2024
-
[25]
Chen, Tianqi and Guestrin, Carlos , title =. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2016 , isbn =. doi:10.1145/2939672.2939785 , abstract =
-
[26]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Gaussian differential privacy , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2022 , publisher=
2022
-
[27]
International conference on machine learning , pages=
Improving the gaussian mechanism for differential privacy: Analytical calibration and optimal denoising , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[28]
and Acar, B
Guvenir, H. and Acar, B. and Muderrisoglu, H. , title =. 1992 , howpublished =
1992
-
[29]
and Lustrek, M
Vidulin, V. and Lustrek, M. and Kaluza, B. and Piltaver, R. and Krivec, J. , title =. 2010 , howpublished =
2010
-
[30]
Contrastive Private Data Synthesis via Weighted Multi-
Tianyuan Zou and Yang Liu and Peng Li and Yufei Xiong and Jianqing Zhang and Jingjing Liu and Xiaozhou Ye and Ye Ouyang and Ya-Qin Zhang , booktitle=. Contrastive Private Data Synthesis via Weighted Multi-. 2025 , url=
2025
-
[31]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Hou, Charlie and Shrivastava, Akshat and Zhan, Hongyuan and Conway, Rylan and Le, Trang and Sagar, Adithya and Fanti, Giulia and Lazar, Daniel , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[32]
Forty-second International Conference on Machine Learning , year=
Private Federated Learning using Preference-Optimized Synthetic Data , author=. Forty-second International Conference on Machine Learning , year=
-
[33]
2025 , url=
Jianqing Zhang and Yang Liu and JIE FU and Yang Hua and Tianyuan Zou and Jian Cao and Qiang Yang , booktitle=. 2025 , url=
2025
-
[34]
2025 , eprint=
Private Evolution Converges , author=. 2025 , eprint=
2025
-
[35]
2021 , eprint=
Winning the NIST Contest: A scalable and general approach to differentially private synthetic data , author=. 2021 , eprint=
2021
-
[36]
and Srivastava, Divesh and Xiao, Xiaokui , title =
Zhang, Jun and Cormode, Graham and Procopiuc, Cecilia M. and Srivastava, Divesh and Xiao, Xiaokui , title =. 2017 , issue_date =. doi:10.1145/3134428 , journal =
-
[37]
2021 , eprint=
DPSyn: Experiences in the NIST Differential Privacy Data Synthesis Challenges , author=. 2021 , eprint=
2021
-
[38]
2019 , cdate=
Ryan McKenna and Daniel Sheldon and Gerome Miklau , title=. 2019 , cdate=
2019
-
[39]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Donhauser, Konstantin and Abad, Javier and Hulkund, Neha and Yang, Fanny , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[40]
2018 , eprint=
Differentially Private Generative Adversarial Network , author=. 2018 , eprint=
2018
-
[41]
2019 , url=
Jinsung Yoon and James Jordon and Mihaela van der Schaar , booktitle=. 2019 , url=
2019
-
[42]
2023 , eprint=
DP-TBART: A Transformer-based Autoregressive Model for Differentially Private Tabular Data Generation , author=. 2023 , eprint=
2023
-
[43]
2023 , eprint=
Privately generating tabular data using language models , author=. 2023 , eprint=
2023
-
[44]
2024 , eprint=
Joint Selection: Adaptively Incorporating Public Information for Private Synthetic Data , author=. 2024 , eprint=
2024
-
[45]
Zhang, Jun and Xiao, Xiaokui and Xie, Xing , title =. 2016 , isbn =. doi:10.1145/2882903.2882928 , booktitle =
-
[46]
2024 , eprint=
Harnessing large-language models to generate private synthetic text , author=. 2024 , eprint=
2024
-
[47]
Transactions on Machine Learning Research , issn=
Differentially Private Diffusion Models , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[48]
2025 , eprint=
DPImageBench: A Unified Benchmark for Differentially Private Image Synthesis , author=. 2025 , eprint=
2025
-
[49]
2025 , eprint=
Struct-Bench: A Benchmark for Differentially Private Structured Text Generation , author=. 2025 , eprint=
2025
-
[50]
Diffprivlib: the
Holohan, Naoise and Braghin, Stefano and Mac Aonghusa, P. Diffprivlib: the. 2019 , journal =
2019
-
[51]
Information Theoretical Analysis of Multivariate Correlation , year=
Watanabe, Satosi , journal=. Information Theoretical Analysis of Multivariate Correlation , year=
-
[52]
2024 IEEE Symposium on Security and Privacy (SP) , year=
SoK: Privacy-Preserving Data Synthesis , author=. 2024 IEEE Symposium on Security and Privacy (SP) , year=
2024
-
[53]
2025 , eprint=
How to DP-fy Your Data: A Practical Guide to Generating Synthetic Data With Differential Privacy , author=. 2025 , eprint=
2025
-
[54]
Du, Yuntao and Li, Ninghui , title =. 2025 , isbn =. doi:10.1145/3719027.3765067 , booktitle =
-
[55]
2021 , eprint=
Kamino: Constraint-Aware Differentially Private Data Synthesis , author=. 2021 , eprint=
2021
-
[56]
Maddock, Samuel and Cormode, Graham and Maple, Carsten , title =. 2024 , isbn =. doi:10.1145/3637528.3671990 , booktitle =
-
[57]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Pang, Wei and Shafieinejad, Masoumeh and Liu, Lucy and Hazlewood, Stephanie and He, Xi , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[58]
2025 , eprint=
Differentially Private Synthetic Data Generation for Relational Databases , author=. 2025 , eprint=
2025
-
[59]
arXiv preprint arXiv:2506.07555 , year=
Synthesize Privacy-Preserving High-Resolution Images via Private Textual Intermediaries , author=. arXiv preprint arXiv:2506.07555 , year=
-
[60]
1996 , howpublished =
Becker, Barry and Kohavi, Ronny , title =. 1996 , howpublished =
1996
-
[61]
Moro, S. and Rita, P. and Cortez, P. , title =. 2014 , howpublished =. doi:10.24432/C5K306 , url =
-
[62]
Advances in Neural Information Processing Systems , volume=
Retiring Adult: New Datasets for Fair Machine Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
and Roth, Aaron , booktitle=
Hsu, Justin and Gaboardi, Marco and Haeberlen, Andreas and Khanna, Sanjeev and Narayan, Arjun and Pierce, Benjamin C. and Roth, Aaron , booktitle=. Differential Privacy: An Economic Method for Choosing Epsilon , year=
-
[64]
2023 , eprint=
Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe , author=. 2023 , eprint=
2023
-
[65]
2026 , eprint=
Privately Fine-Tuned LLMs Preserve Temporal Dynamics in Tabular Data , author=. 2026 , eprint=
2026
-
[66]
2025 , eprint=
GEM+: Scalable State-of-the-Art Private Synthetic Data with Generator Networks , author=. 2025 , eprint=
2025
-
[67]
2025 , eprint=
Beyond One-Size-Fits-All: Neural Networks for Differentially Private Tabular Data Synthesis , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.