Theoretical Foundations of Continual Learning via Drift-Plus-Penalty
Pith reviewed 2026-06-27 19:04 UTC · model grok-4.3
The pith
A drift-plus-penalty framework regulates the stability-plasticity trade-off in continual learning through virtual queues with convergence guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
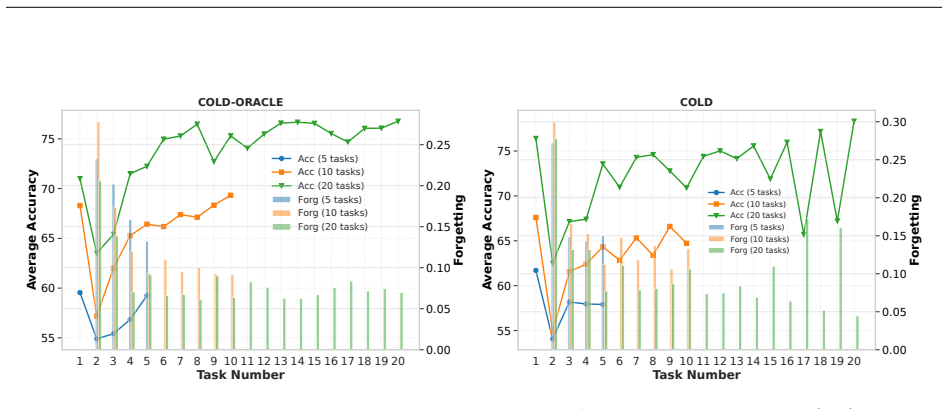
COLD minimizes the loss on the current task while updating a virtual queue that accumulates deviations from long-term stability on previous tasks. The drift-plus-penalty update balances the drift in the queue with a penalty term, and the authors prove that this yields bounded stability deviations and convergence to an optimal point characterized by the control parameter V. The oracle variant COLD-ORACLE serves as a reference, and both demonstrate controllable forgetting behavior.
What carries the argument
The virtual queue that tracks cumulative stability deviations from prior tasks, updated via the drift-plus-penalty rule to enforce the stability-plasticity balance.
Load-bearing premise
The virtual queue mechanism accurately tracks long-term stability deviations on prior tasks in replay-based continual learning, allowing the Drift-Plus-Penalty updates to enforce the desired stability-plasticity trade-off without additional unmodeled dynamics.
What would settle it
If the measured stability deviation on old tasks grows unbounded as the number of tasks increases despite following the virtual queue updates, the convergence guarantees would not hold.
Figures




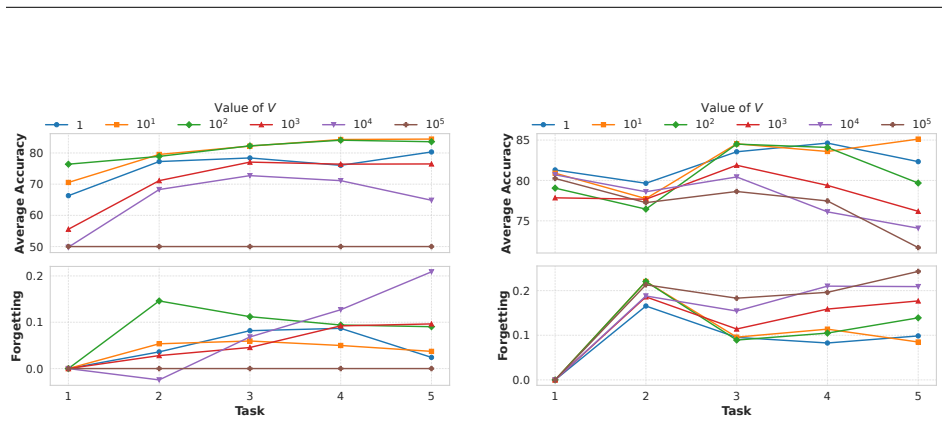
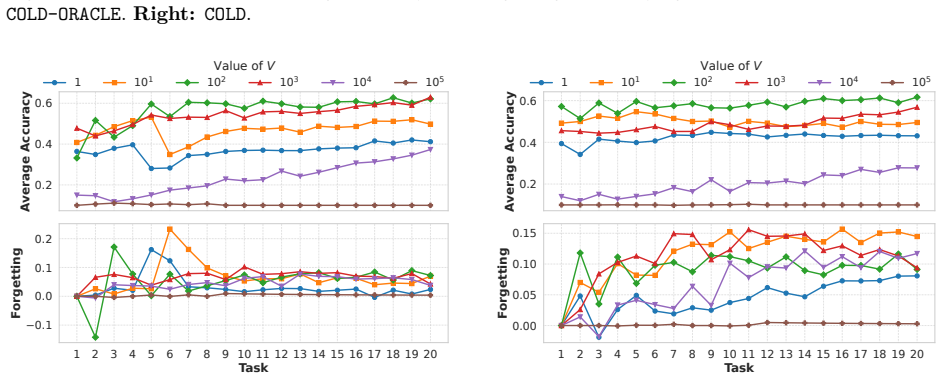
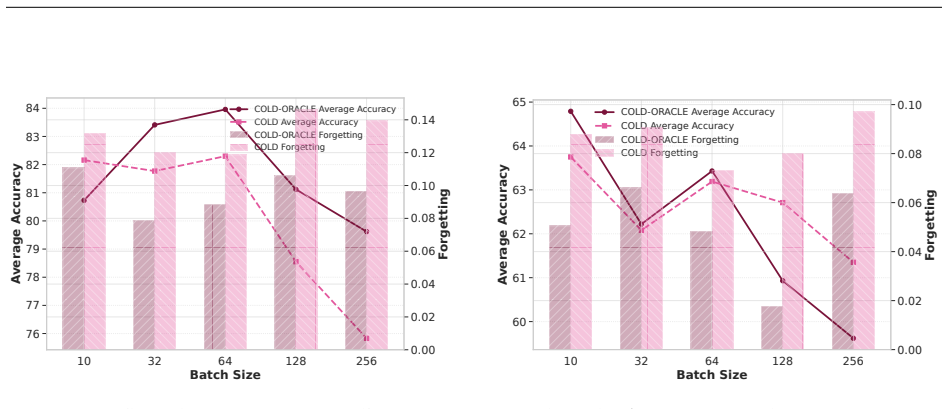



read the original abstract
In many real-world settings, data streams are nonstationary and arrive sequentially, requiring learning systems to adapt continuously without retraining from scratch. Continual learning (CL) addresses this challenge by incorporating new tasks while mitigating catastrophic forgetting, where learning new information degrades performance on previously acquired knowledge. We introduce a control-theoretic perspective on CL that explicitly regulates the evolution of forgetting, framing adaptation as a controlled process subject to long-term stability constraints. We focus on replay-based CL, where a finite memory buffer stores representative samples from prior tasks. We propose COntinual Learning with Drift-Plus-Penalty (COLD), a continual learning framework based on the Drift-Plus-Penalty (DPP) principle from stochastic optimization. To facilitate analysis, we also consider an oracle variant, COLD-ORACLE, as a reference benchmark. At each task, both methods minimize the current task loss while maintaining a virtual queue that tracks deviations from long-term stability on previously learned tasks, capturing the stability-plasticity trade-off as a regulated dynamical process. We establish stability and convergence guarantees that characterize this trade-off through a tunable control parameter. Experiments on standard benchmarks demonstrate that COLD consistently outperforms a broad range of state-of-the-art CL methods while providing competitive and controllable forgetting behavior through explicit regulation of stability and plasticity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
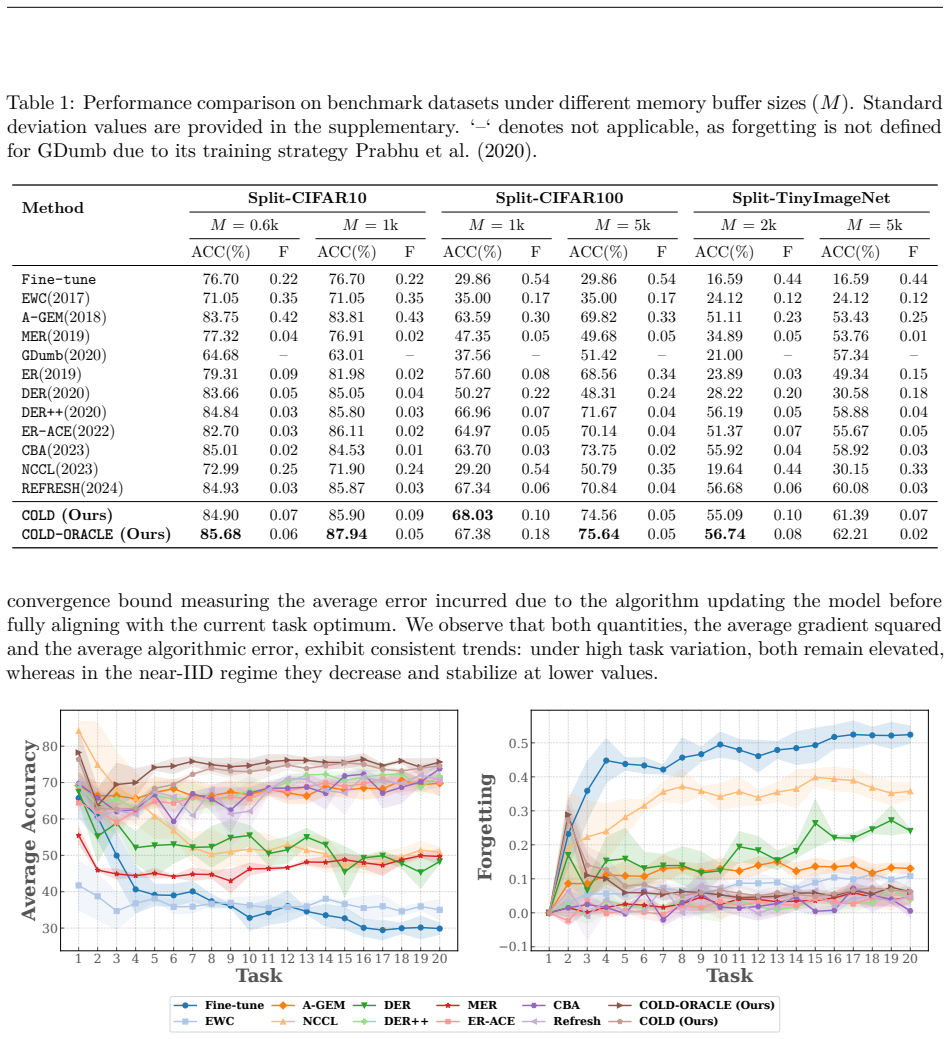
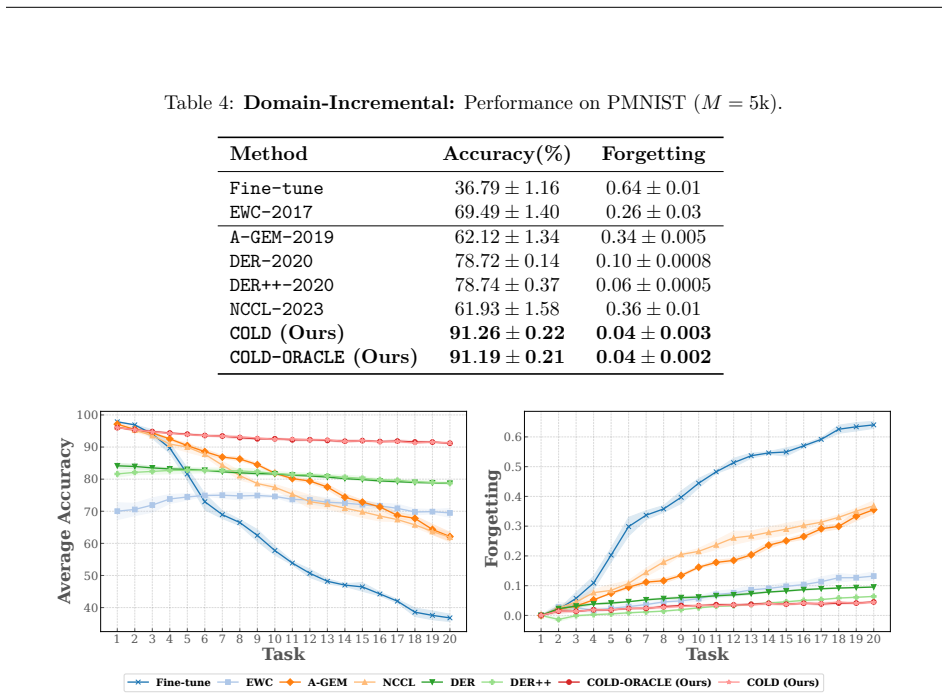
Summary. The paper proposes COLD, a replay-based continual learning method that applies the Drift-Plus-Penalty framework from stochastic optimization. At each task it minimizes the current-task loss subject to a virtual queue that tracks long-term stability deviations on prior tasks; a tunable parameter V controls the stability-plasticity trade-off. The authors claim Lyapunov-drift-based stability and convergence guarantees that bound time-average forgetting to a target controlled by V, together with an oracle variant COLD-ORACLE. Experiments on standard benchmarks are reported to show consistent outperformance over existing CL methods while allowing explicit regulation of forgetting.
Significance. If the convergence guarantees survive the empirical nature of replay buffers, the work supplies a principled control-theoretic lens on the stability-plasticity trade-off and a practical mechanism for tunable forgetting. The explicit linkage of DPP to replay-based CL is a novel framing that could influence future algorithm design in non-stationary learning settings.
major comments (2)
- [§4 (stability theorem / Lyapunov drift bound)] The Lyapunov-drift analysis (presumably Theorem 1 or the stability result in §4) treats the instantaneous stability deviation y(t) as drawn from the true prior-task distribution. In replay-based CL, y(t) is evaluated on samples from a finite, evolving buffer whose empirical distribution differs from the true distribution; the paper does not appear to absorb the resulting bias or additional variance into the O(1/V) term. This discrepancy is load-bearing for the claimed convergence of time-average forgetting.
- [§3.2 (virtual queue definition) and §4 (drift analysis)] The virtual-queue update Q(t+1) = [Q(t) + y(t) − ε]^+ is analyzed under the assumption that the queue process remains stable for any fixed V. Because buffer updates occur after each new task and the sampling rule changes, it is unclear whether the standard DPP bounded-drift argument continues to hold without additional terms that depend on buffer size or update frequency.
minor comments (2)
- [Abstract and §3] Notation for the control parameter V and the target ε should be introduced once and used consistently; the abstract refers to a 'tunable control parameter' without naming it.
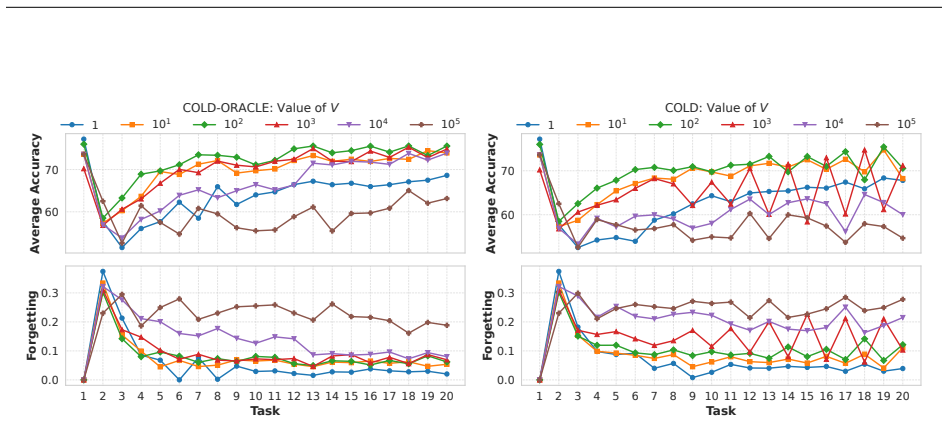
- [§5 (experiments)] The experimental section should report the precise buffer sizes, replay sampling strategies, and the range of V values tested so that the claimed controllability of forgetting can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. Below we respond point-by-point to the major concerns, clarifying the scope of our theoretical results and indicating the revisions we will make.
read point-by-point responses
-
Referee: [§4 (stability theorem / Lyapunov drift bound)] The Lyapunov-drift analysis (presumably Theorem 1 or the stability result in §4) treats the instantaneous stability deviation y(t) as drawn from the true prior-task distribution. In replay-based CL, y(t) is evaluated on samples from a finite, evolving buffer whose empirical distribution differs from the true distribution; the paper does not appear to absorb the resulting bias or additional variance into the O(1/V) term. This discrepancy is load-bearing for the claimed convergence of time-average forgetting.
Authors: We agree that the Lyapunov-drift analysis in Section 4 is derived under the assumption that y(t) is computed with respect to the true prior-task distributions. This corresponds exactly to the COLD-ORACLE variant introduced in the paper. For the practical COLD method that uses a finite replay buffer, y(t) is an empirical estimate, and the resulting approximation error is not folded into the O(1/V) bound. We will revise the manuscript to (i) explicitly state that the formal stability and convergence guarantees apply to COLD-ORACLE, (ii) add a discussion of the sampling bias and variance induced by finite buffers, and (iii) provide a high-probability bound on the deviation between empirical and true y(t) under standard assumptions on buffer size and uniform sampling. This will make the distinction between the oracle guarantees and the practical approximation transparent. revision: partial
-
Referee: [§3.2 (virtual queue definition) and §4 (drift analysis)] The virtual-queue update Q(t+1) = [Q(t) + y(t) − ε]^+ is analyzed under the assumption that the queue process remains stable for any fixed V. Because buffer updates occur after each new task and the sampling rule changes, it is unclear whether the standard DPP bounded-drift argument continues to hold without additional terms that depend on buffer size or update frequency.
Authors: The virtual-queue dynamics are written in the standard DPP form, and the drift analysis relies on the usual boundedness of y(t) and the choice of V. However, because the buffer is updated after each task and the sampling distribution therefore evolves, the process y(t) is not strictly stationary. We acknowledge that the manuscript does not derive additional drift terms that would explicitly depend on buffer size or update frequency. We will revise Section 4 to either (a) state the additional assumptions under which the standard bounded-drift argument remains valid (e.g., sufficiently large buffers and slow buffer evolution) or (b) introduce a modified drift bound that accounts for the non-stationarity induced by buffer updates. Either approach will be accompanied by a clear statement of the conditions required for queue stability. revision: yes
Circularity Check
No significant circularity; derivation applies external DPP principle to CL
full rationale
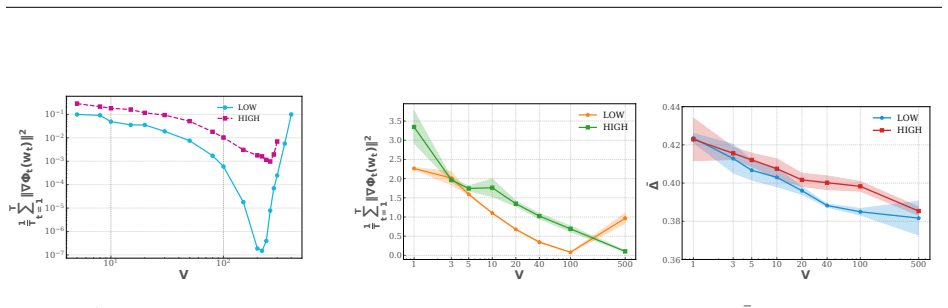
The paper frames COLD as an application of the established Drift-Plus-Penalty principle from stochastic optimization to replay-based continual learning, using virtual queues to enforce long-term stability constraints and deriving stability/convergence guarantees via a tunable parameter. No equations, fitting procedures, or self-citations appear in the abstract or description that reduce any claimed prediction or theorem to the paper's own inputs by construction. The central claims rest on the external DPP framework rather than self-definition or renamed empirical patterns, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- tunable control parameter
Reference graph
Works this paper leans on
-
[1]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem. arXiv preprint arXiv:1812.00420 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://papers.nips.cc/paper_ files/paper/2019/hash/2c04ecb5b9afa19f3b8c9f7b30c6b43e-Abstract.html. Li Deng. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142,
2019
-
[3]
Ya Le and Xuan S
URL https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf . Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge
2009
-
[4]
ISSN 0018-9286. doi: 10.1109/TAC.2012.2191874. Michael J Neely. Energy optimal control for time-varying wireless networks. IEEE Trans. on Inf. Theory , 52(7):2915–2934,
-
[5]
Online Learning: A Modern Introduction Using Convex Optimization
Francesco Orabona. A modern introduction to online learning. arXiv preprint arXiv:1912.13213 ,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[6]
URL https://proceedings.neurips.cc/paper_files/paper/2019/file/ fa7cdfad1a5aaf8370ebeda47a1ff1c3-Paper.pdf. Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks. arXiv preprint arXiv:1606.04671,
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
Projection-free algorithms for online convex optimization with adversarial constraints
20 Dhruv Sarkar, Aprameyo Chakrabartty, Subhamon Supantha, Palash Dey, and Abhishek Sinha. Projection-free algorithms for online convex optimization with adversarial constraints. arXiv preprint arXiv:2501.16919,
-
[8]
Rahul Vaze and Abhishek Sinha. o( √ T ) static regret and instance dependent constraint violation for con- strained online convex optimization. arXiv preprint arXiv:2502.05019 ,
-
[9]
Wenhan Xu, Jiashuo Jiang, Lei Deng, and Danny Hin-Kwok Tsang
URL https://proceedings.mlr.press/v235/wu24ab.html. Wenhan Xu, Jiashuo Jiang, Lei Deng, and Danny Hin-Kwok Tsang. A lyapunov drift-plus-penalty method tailored for reinforcement learning with queue stability. arXiv preprint arXiv:2506.04291 ,
-
[10]
Further, in the first inequality, we have used the fact that summing (Φ t− 1(wt− 1)−Φ t(wt)) over t results in Φ 0(w0)−Φ T (wT ) = −Φ T (wT )≤0
] , ≤V DΦ [T ] δ + 1 T δ T∑ t=1 ∆ t(wt, wt− 1), (40) where ¯Q[t−1] := 1 t− 1 ∑t− 1 k=1 Qk[t−1], and DΦ [T ] = 1 T ∑T t=1 supw|Φ t(w)−Φ t− 1(w)|. Further, in the first inequality, we have used the fact that summing (Φ t− 1(wt− 1)−Φ t(wt)) over t results in Φ 0(w0)−Φ T (wT ) = −Φ T (wT )≤0. While telescoping the last term, we have used the fact that ˆΦ 0(w0)...
2022
-
[11]
79±1. 16 0 . 64±0. 01 EWC-2017
2017
-
[12]
49±1. 40 0 . 26±0. 03 A-GEM-2019
2019
-
[13]
12±1. 34 0 . 34±0. 005 DER-2020
2020
-
[14]
72±0. 14 0 . 10±0. 0008 DER++-2020
2020
-
[15]
74±0. 37 0 . 06±0. 0005 NCCL-2023
2023
-
[18]
81±4. 24 0 . 43±0. 02 69 . 82±3. 36 0 . 33±0. 01 53 . 43±0. 10 0 . 25±0. 0005 MER-2019
2019
-
[19]
91±0. 43 0 . 02±0. 02 49 . 68±2. 14 0 . 05±0. 02 53 . 76±0. 38 0 . 004±0. 002 GDumb-2020
2020
-
[20]
05±0. 70 0 . 04±0. 001 48 . 31±0. 50 0 . 24±0. 004 30 . 58±0. 29 0 . 18±0. 16 DER++-2020
2020
-
[21]
80±0. 92 0 . 03±0. 005 71 . 67±1. 25 0 . 04±0. 007 58 . 88±0. 55 0 . 04±0. 002 ER-ACE-2022
2022
-
[22]
11±0. 27 0 . 02±0. 01 70 . 14±1. 36 0 . 04±0. 01 55 . 67±2. 81 0 . 05±0. 02 CBA-2023
2023
-
[23]
53±0. 44 0 . 006±0. 001 73 . 75±2. 20 0 . 02±0. 01 58 . 92±2. 47 0 . 03±0. 01 NCCL-2023
2023
-
[24]
90±1. 29 0 . 24±0. 01 50 . 79±1. 38 0 . 35±0. 02 30 . 15±1. 65 0 . 33±0. 02 REFRESH-2024
2024
-
[25]
70±5. 31 0 . 22±0. 06 29 . 86±1. 54 0 . 54±0. 02 16 . 59±0. 86 0 . 44±0. 01 EWC-2017
2017
-
[26]
05±4. 72 0 . 35±0. 04 35 . 00±2. 76 0 . 17±0. 004 24 . 12±0. 75 0 . 12±0. 002 A-GEM-2019
2019
-
[27]
75±3. 68 0 . 42±0. 02 63 . 59±3. 74 0 . 30±0. 006 51 . 11±1. 00 0 . 23±0. 004 MER-2019
2019
-
[28]
32±2. 72 0 . 04±0. 02 47 . 35±1. 17 0 . 05±0. 001 34 . 89±0. 45 0 . 05±0. 001 GDumb-2020
2020
-
[29]
66±0. 93 0 . 05±0. 02 50 . 27±1. 38 0 . 22±0. 01 28 . 22±0. 86 0 . 20±0. 18 DER++-2020
2020
-
[30]
84±1. 34 0 . 03±0. 01 66 . 96±0. 91 0 . 07±0. 004 56 . 19±1. 00 0 . 05±0. 01 ER-ACE-2022
2022
-
[31]
70±1. 17 0 . 03±0. 02 64 . 97±2. 11 0 . 05±0. 04 51 . 37±1. 33 0 . 07±0. 01 CBA-2023
2023
-
[32]
01±0. 77 0 . 02±0. 008 63 . 70±2. 54 0 . 03±0. 01 55 . 92±1. 99 0 . 04±0. 01 NCCL-2023
2023
-
[33]
99±7. 93 0 . 25±0. 09 29 . 20±1. 45 0 . 54±0. 02 19 . 64±1. 38 0 . 44±0. 01 REFRESH-2024
2024
-
[34]
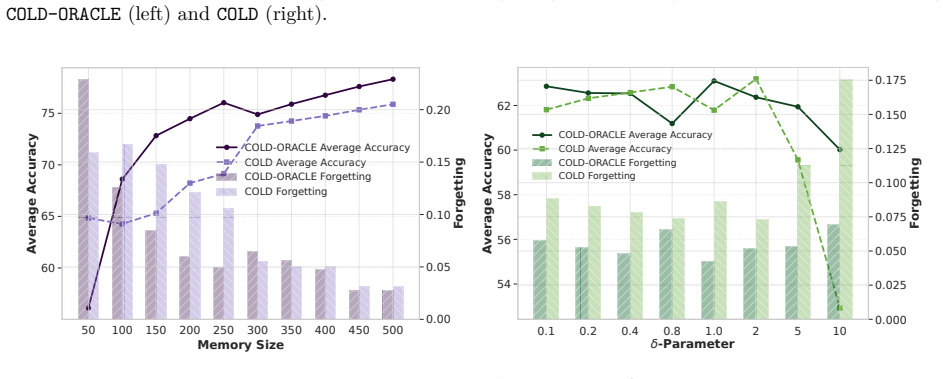
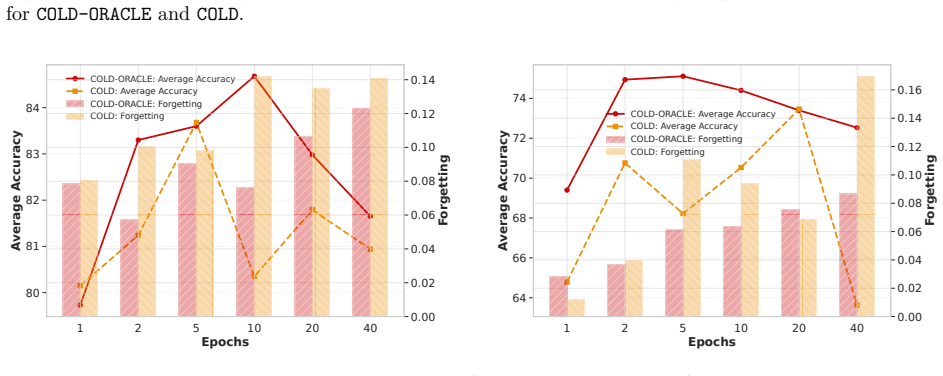
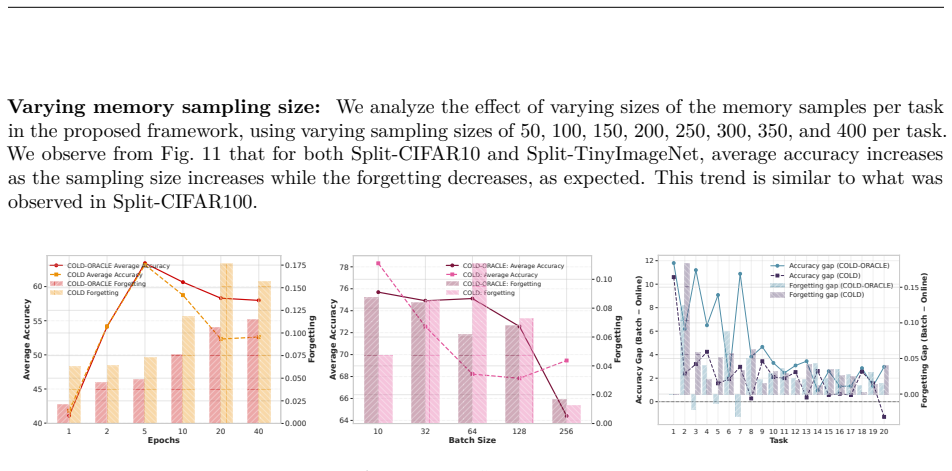
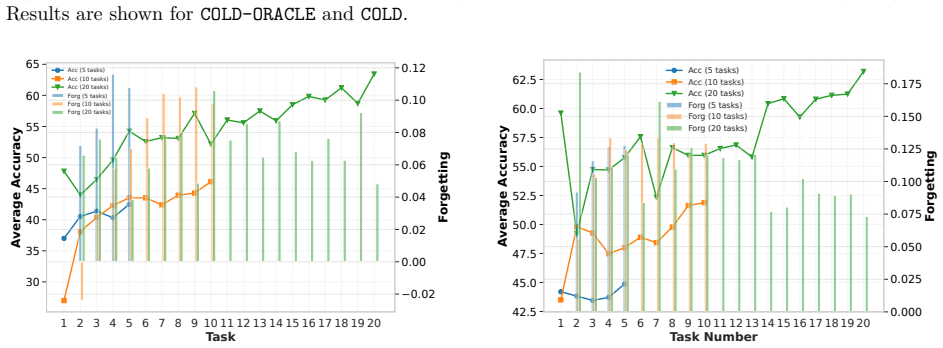
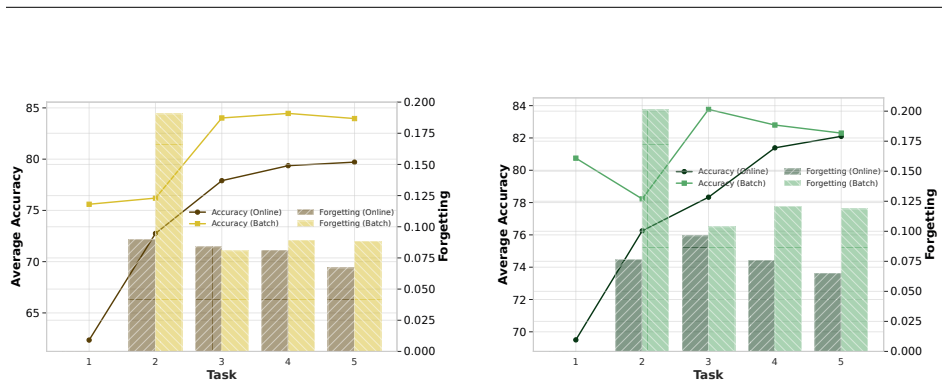
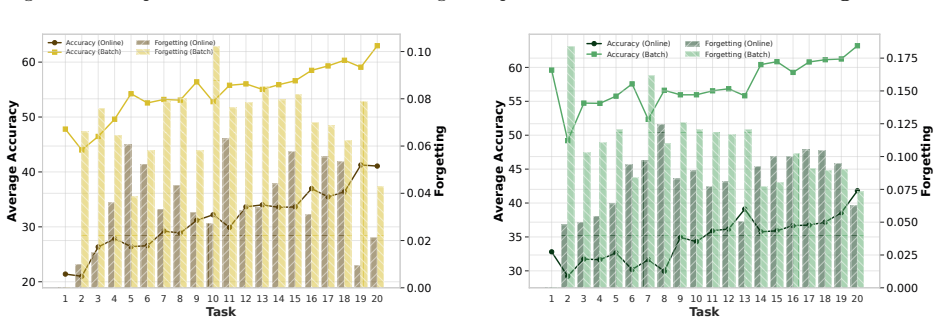
Increasing the epoch further results in higher forgetting, as depicted in the figure
combination on both the proposed algorithms. Increasing the epoch further results in higher forgetting, as depicted in the figure. Fig. 13 (Right) illustrates the average accuracy and forgetting gaps across tasks when comparing the online setting ( 1 epoch) with smaller batch settings. The batch setting achieves higher accuracy, as reflected by the positive...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.