A Geometric Measure of Linear Separability for Neural Representations
Pith reviewed 2026-06-27 18:22 UTC · model grok-4.3
The pith
The directional linear separability measure (LSM) provides a finite-sample diagnostic for one-sided affine separability of neural representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
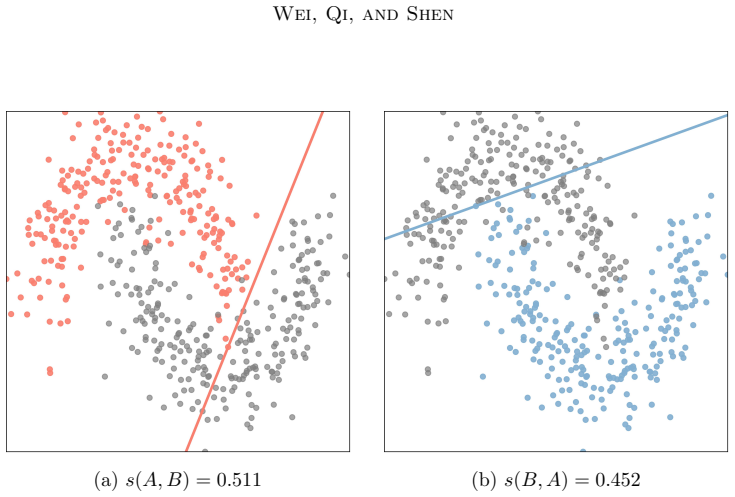
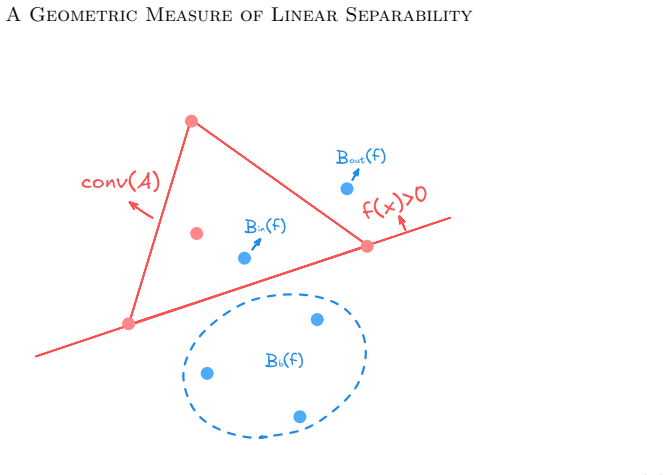
LSM is defined by searching over affine halfspaces that contain all samples from target class A and taking the smallest intrusion fraction from set B, normalized by the size of A. This quantity has a supporting-hyperplane characterization, relates directly to optimal affine classification accuracy, and remains unchanged under full-rank linear embeddings. The paper shows how to estimate it via penalty-based optimization and uses it to examine gated nonlinearities.
What carries the argument
The directional linear separability measure (LSM): the minimal normalized intrusion of competing samples into an affine halfspace that contains the entire target class.
If this is right
- It establishes a direct relation between LSM and the accuracy of the optimal affine classifier.
- LSM values are invariant under full-rank linear re-embeddings of the feature space.
- The measure can be estimated in high dimensions using a penalty-based search over affine parameters.
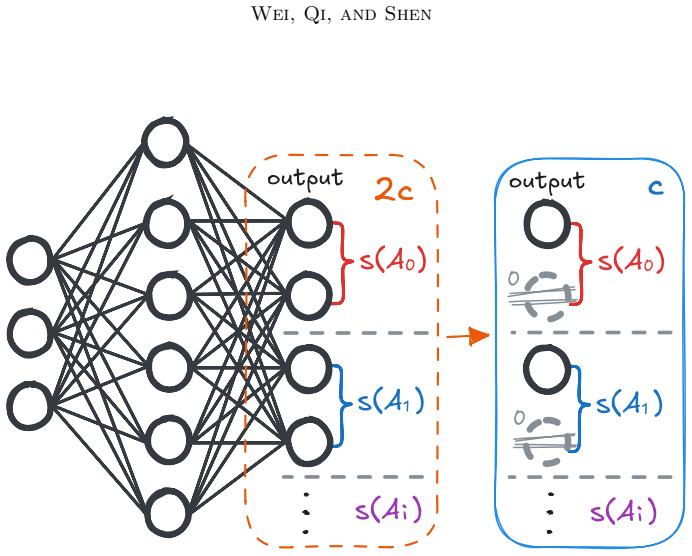
- It applies to coordinatewise gated nonlinearities treated as finite-sample geometric operators.
- Empirical computations reveal class-wise intrusion patterns across standard deep learning architectures and components.
Where Pith is reading between the lines
- LSM might allow tracking how training dynamics affect separability without retraining downstream classifiers.
- Different architectures could be ranked by their LSM profiles on the same data.
- Low LSM for certain classes could flag the need for targeted data augmentation or architectural changes.
Load-bearing premise
The minimal normalized intrusion into the best affine halfspace containing the target class meaningfully reflects the geometry that matters for linear readouts, no matter which procedure finds that halfspace.
What would settle it
Computing LSM with two independent halfspace search methods on the same fixed representations and finding large discrepancies in the reported values would show the measure depends on the search procedure.
Figures
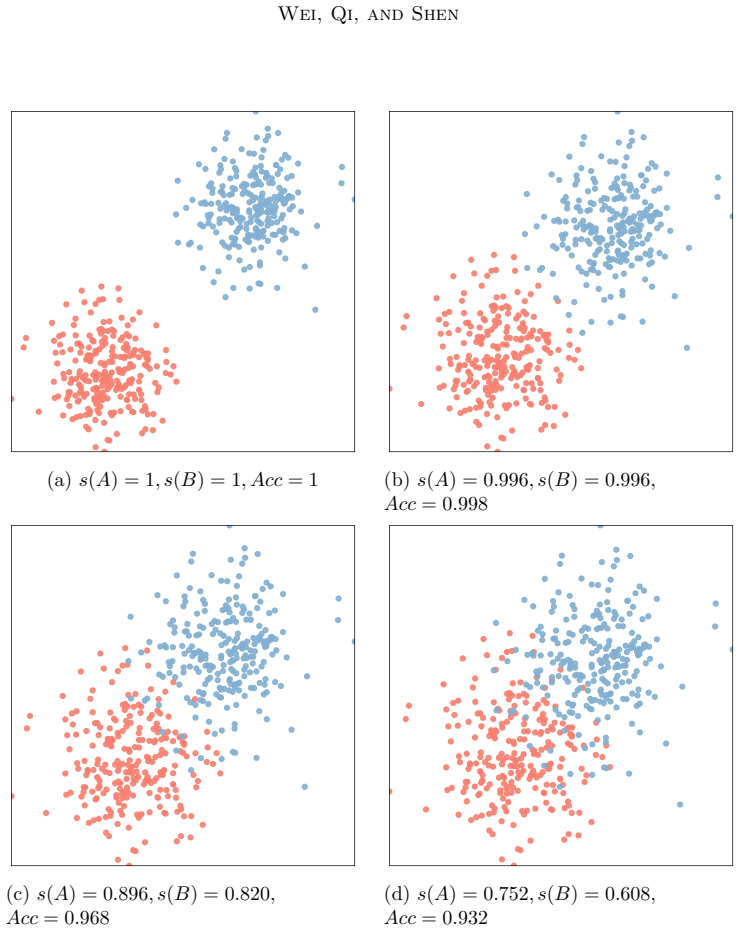
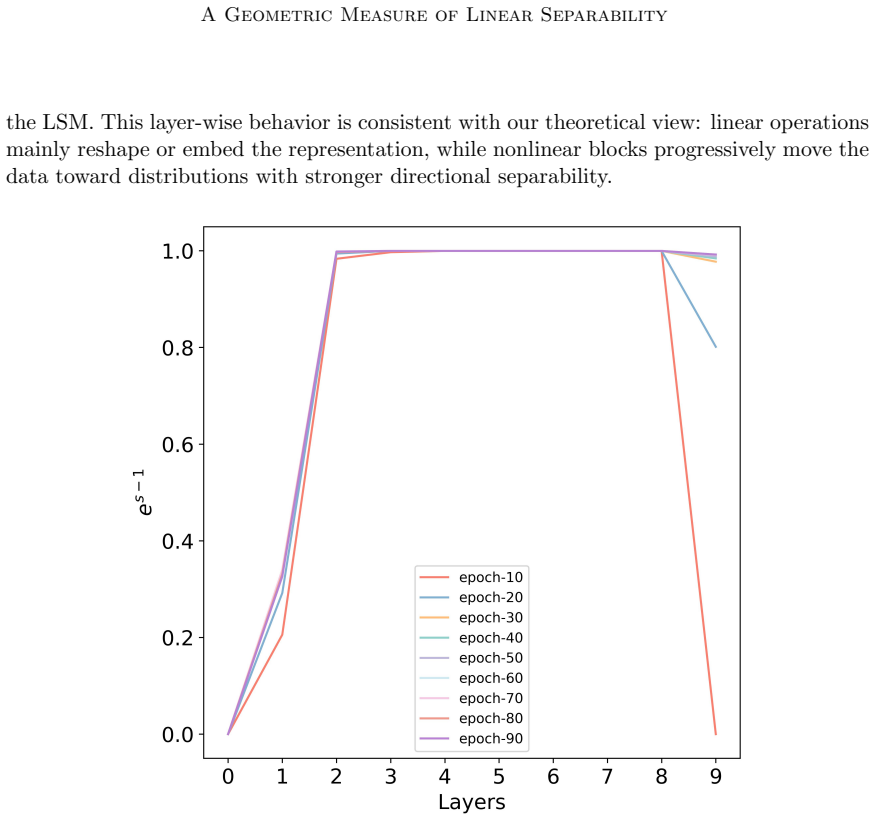
read the original abstract
Modern neural classifiers commonly rely on linear readouts, yet predictive metrics alone do not characterize the class-wise geometry of the representations on which such readouts operate. We introduce the directional linear separability measure (LSM), a finite-sample diagnostic for one-sided affine separability. For a target class A and a competing set B, LSM searches over affine halfspaces that contain all samples in A and measures the smallest competing-sample intrusion that must remain on the target side, normalized by |A|. The resulting quantity is asymmetric, class-wise, target-normalized, and applicable to finite representations extracted from neural networks. We establish its supporting-hyperplane characterization, relate it to optimal affine classification accuracy, and prove invariance under full-rank linear embeddings. These results separate changes caused by linear reparameterization from those caused by information loss or nonlinear geometric transformations. We also give a penalty-based affine search for estimating class-wise LSM in high-dimensional features, with reported values computed from the original discrete preservation and violation criterion. Finally, we analyze coordinatewise gated nonlinearities as finite-sample geometric operators and empirically use LSM to diagnose class-wise intrusion across common deep-learning components and architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the directional linear separability measure (LSM), a finite-sample diagnostic for one-sided affine separability of neural representations. For target class A and competing set B, LSM searches affine halfspaces containing all points in A and reports the smallest normalized intrusion from B. It establishes a supporting-hyperplane characterization, relates LSM to optimal affine classification accuracy, proves invariance under full-rank linear embeddings, supplies a penalty-based search procedure for high-dimensional estimation (with reported values using the original discrete criterion), and applies the measure empirically to gated nonlinearities and common architectures.
Significance. If the central claims hold, LSM supplies an asymmetric, target-normalized geometric diagnostic that isolates linear-reparameterization effects from information loss, complementing accuracy-based metrics. The invariance result and explicit relation to affine accuracy are useful formal contributions; the empirical use on coordinatewise gated nonlinearities demonstrates diagnostic value for representation geometry.
major comments (2)
- [Estimation section] Estimation section: LSM is defined as the minimal normalized intrusion over all affine halfspaces containing A, yet the penalty-based optimizer used for high-dimensional features is supplied without a recovery guarantee or approximation bound. If the search returns a strictly larger intrusion than the true minimum, the reported numerical values differ from the quantity whose supporting-hyperplane characterization and invariance are proved, breaking the link between theory and the empirical diagnostics.
- [Relation to accuracy (near §3)] Relation to accuracy (near §3): the claimed equivalence between LSM and optimal affine classification accuracy is stated for the exact minimal-intrusion halfspace; without verification that the discrete or penalty search attains this minimum on the reported datasets, the empirical accuracy-LSM plots do not directly corroborate the theoretical relation.
minor comments (2)
- [Notation] Notation for the normalized intrusion could be introduced with an explicit equation number rather than inline description to improve readability when the invariance proof is referenced.
- [Abstract and Experiments] The abstract states that reported values use the original discrete criterion, but the main text should clarify in one sentence which experiments use the exact discrete search versus the penalty approximation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the identification of key points regarding the estimation procedure and its relation to the theoretical claims. We address each major comment below and will incorporate revisions to clarify the distinctions between exact and estimated quantities.
read point-by-point responses
-
Referee: [Estimation section] Estimation section: LSM is defined as the minimal normalized intrusion over all affine halfspaces containing A, yet the penalty-based optimizer used for high-dimensional features is supplied without a recovery guarantee or approximation bound. If the search returns a strictly larger intrusion than the true minimum, the reported numerical values differ from the quantity whose supporting-hyperplane characterization and invariance are proved, breaking the link between theory and the empirical diagnostics.
Authors: We acknowledge the validity of this observation. The penalty-based search is presented as a computational tool for high dimensions, and the manuscript specifies that reported values are computed using the discrete criterion on the resulting halfspaces. This means the reported values correspond to the intrusion of the found halfspace rather than necessarily the minimal one. We will revise the estimation section to explicitly note that the procedure yields an upper bound on the true LSM and to discuss the implications for interpreting the empirical results in light of the theoretical characterizations. A small-scale validation comparing the optimizer to exhaustive search in low dimensions will be added if feasible. revision: yes
-
Referee: [Relation to accuracy (near §3)] Relation to accuracy (near §3): the claimed equivalence between LSM and optimal affine classification accuracy is stated for the exact minimal-intrusion halfspace; without verification that the discrete or penalty search attains this minimum on the reported datasets, the empirical accuracy-LSM plots do not directly corroborate the theoretical relation.
Authors: The theoretical relation is indeed derived for the exact LSM. The empirical plots utilize the LSM values obtained from the search procedure. In the revision, we will update the text near §3 to indicate that the plots demonstrate the relationship using the estimated LSM and that deviations from the theoretical curve could be attributable to suboptimality in the search. We will also emphasize that the equivalence holds exactly only for the minimal intrusion. revision: yes
Circularity Check
No circularity: LSM is a direct definitional search over halfspaces with independent supporting-hyperplane proofs
full rationale
The paper defines LSM explicitly as the minimal normalized intrusion over affine halfspaces containing all target samples A (asymmetric, target-normalized). It proves supporting-hyperplane characterization, relation to optimal affine accuracy, and invariance under full-rank linear embeddings directly from this definition. The penalty-based search is introduced only as an estimation tool for high dimensions; the text states that reported values are computed from the original discrete preservation/violation criterion. No fitted parameters are renamed as predictions, no self-citations are load-bearing for the core claims, and no ansatz or uniqueness result is smuggled in. The derivation chain is self-contained against the stated geometric definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1162/coli a 00422. Y. Bengio, A. Courville, and P. Vincent. Representation learning: A review and new perspectives.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8): 1798–1828,
-
[2]
doi: 10.1109/TPAMI.2013.50. K. P. Bennett and E. J. Bredensteiner. Duality and geometry in SVM classifiers. In Proceedings of the Seventeenth International Conference on Machine Learning, pages 57– 64,
-
[3]
doi: 10.1007/BF00994018. T. M. Cover. Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition.IEEE Transactions on Electronic Computers, EC-14 (3):326–334,
-
[4]
doi: 10.1109/PGEC.1965.264137. D. L. Donoho and M. Gasko. Breakdown properties of location estimates based on halfspace depth and projected outlyingness.The Annals of Statistics, 20(4):1803–1827,
-
[5]
doi: 10.1214/aos/1176348890. R. A. Fisher. The use of multiple measurements in taxonomic problems.Annals of Eugenics, 7(2):179–188,
-
[6]
doi: 10.1111/j.1469-1809.1936.tb02137.x. D. Hendrycks and K. Gimpel. Gaussian error linear units (GELUs),
-
[7]
Hewitt and P
J. Hewitt and P. Liang. Designing and interpreting probes with control tasks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 2733–2743. Association for Computational Linguistics,
2019
-
[8]
doi: 10.18653/v1/D19-1275. T. K. Ho and M. Basu. Complexity measures of supervised classification problems.IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(3):289–300,
-
[9]
doi: 10.1109/34.990132. A. Jacot, F. Gabriel, and C. Hongler. Neural tangent kernel: Convergence and generalization in neural networks. InAdvances in Neural Information Processing Systems, volume 31, pages 8580–8589,
-
[10]
doi: 10.1038/nature14539. A. C. Lorena, L. P. F. Garcia, J. Lehmann, M. C. P. Souto, and T. K. Ho. How complex is your classification problem? a survey on measuring classification complexity.ACM Computing Surveys, 52(5):1–34,
-
[11]
doi: 10.1145/3347711. G. F. Mont´ ufar, R. Pascanu, K. Cho, and Y. Bengio. On the number of linear regions of deep neural networks. InAdvances in Neural Information Processing Systems, volume 27, pages 2924–2932,
-
[12]
doi: 10.1073/pnas.2015509117. T. Pimentel, J. Valvoda, R. H. Maudslay, R. Zmigrod, A. Williams, and R. Cotterell. Information-theoretic probing for linguistic structure. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4609–4622. Association for Computational Linguistics,
-
[13]
doi: 10.18653/v1/2020.acl-main.420. M. Raghu, J. Gilmer, J. Yosinski, and J. Sohl-Dickstein. SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. InAdvances in Neural Information Processing Systems, volume 30, 2017a. M. Raghu, B. Poole, J. Kleinberg, S. Ganguli, and J. Sohl-Dickstein. On the expressive pow...
-
[14]
doi: 10.1037/h0042519. 36 A Geometric Measure of Linear Separability J. W. Tukey. Mathematics and the picturing of data. InProceedings of the International Congress of Mathematicians, volume 2, pages 523–531. Canadian Mathematical Congress,
-
[15]
Voita and I
E. Voita and I. Titov. Information-theoretic probing with minimum description length. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Process- ing, pages 183–196. Association for Computational Linguistics,
2020
-
[16]
doi: 10.18653/v1/ 2020.emnlp-main.14. C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. Understanding deep learning requires rethinking generalization. InInternational Conference on Learning Representa- tions,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.