Synthetic but Not Realistic: The Evaluation Challenge in Generative Modelling for Structured Electronic Medical Records
Pith reviewed 2026-06-27 17:17 UTC · model grok-4.3
The pith
Generative models for structured EMRs reproduce marginal distributions but fail to preserve subgroup structure, effect estimates, and dependency structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
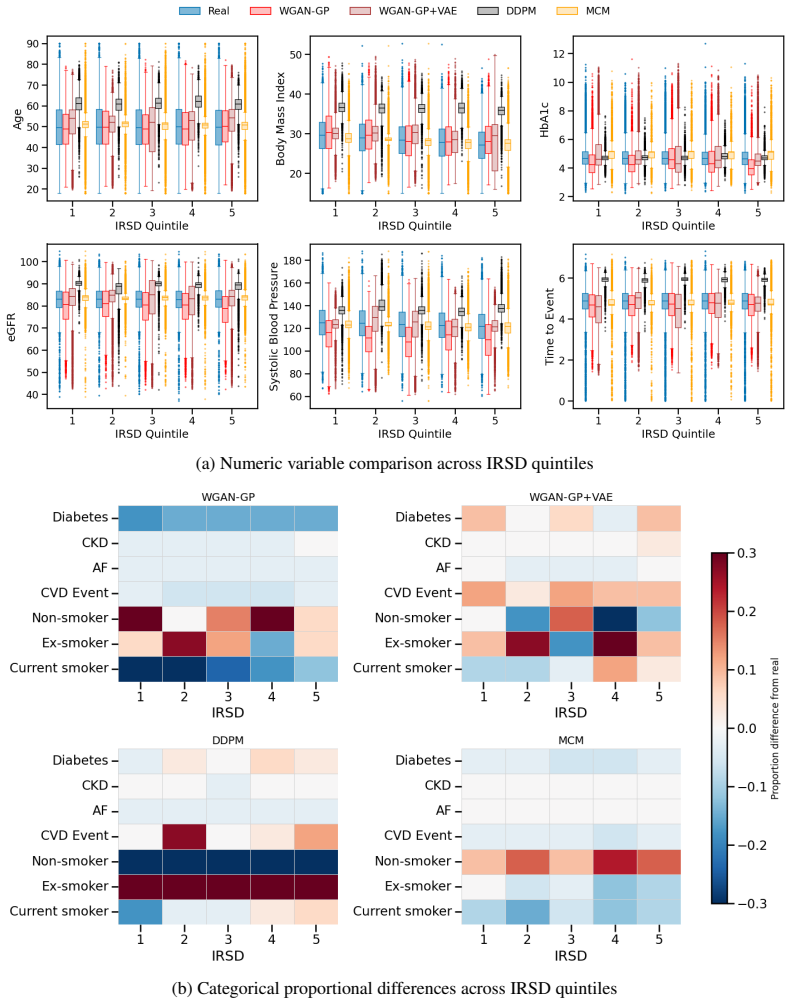
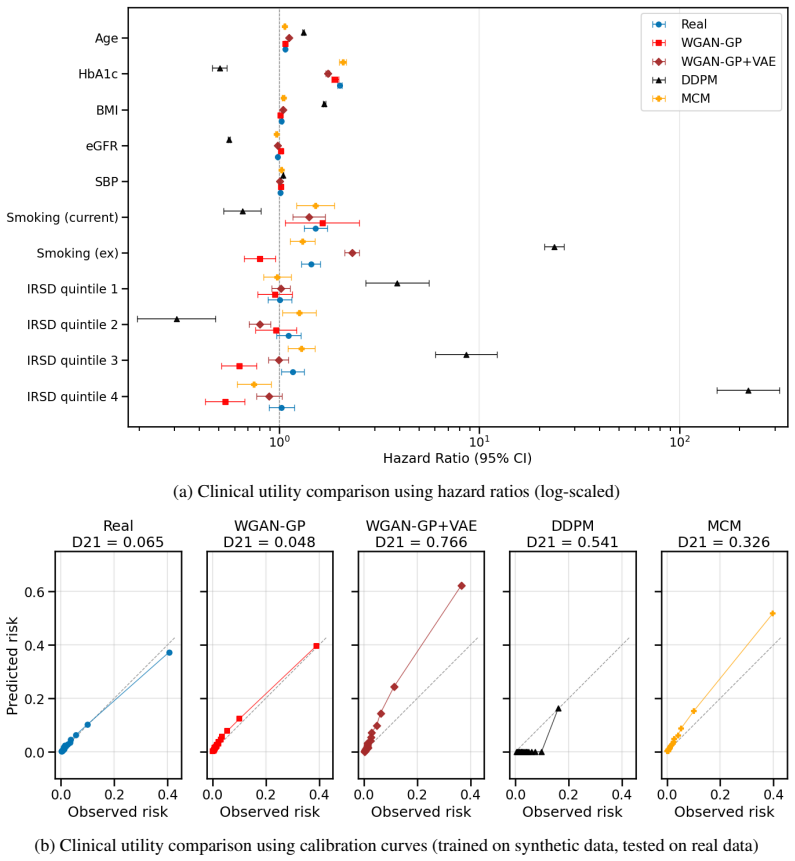
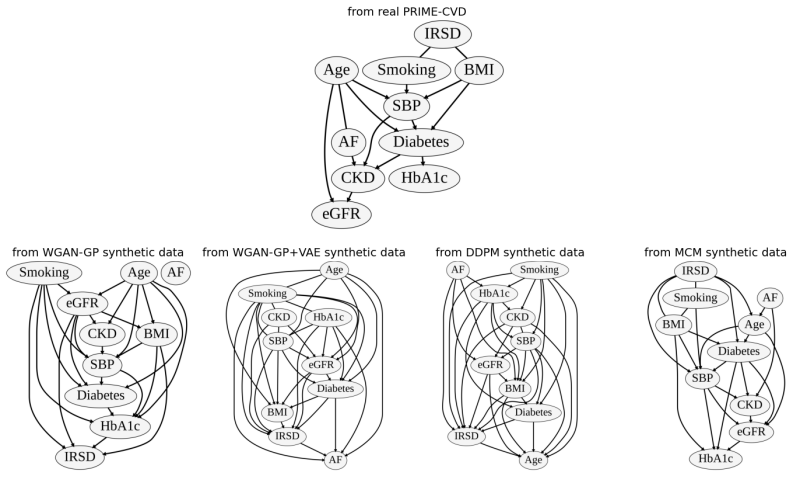
While all models reproduce marginal distributions, none simultaneously preserve subgroup structure, effect estimates, and dependency structure. Models with strong distributional fidelity can exhibit poor calibration and distorted relationships, leading to unreliable inference. These results show that current evaluation practices can overestimate synthetic data quality and motivate domain-informed assessment based on the ability to support valid clinical and scientific conclusions.
What carries the argument
Multi-dimensional evaluation framework grounded in epidemiology that measures descriptive fidelity, clinical utility, and structural validity on the PRIME-CVD cohort with known ground-truth structure.
If this is right
- Generative models must be checked for their ability to answer predictive and causal questions, not only descriptive statistics.
- High performance on marginal distributions does not ensure correct calibration or preserved relationships.
- Standard evaluation practices risk overstating the quality of synthetic EMR data for downstream use.
- Valid clinical and scientific conclusions from synthetic data require domain-specific structural checks.
Where Pith is reading between the lines
- Synthetic EMRs from these models may produce misleading effect estimates if used in place of real data for observational studies.
- The observed gap between distributional match and structural preservation suggests future models should target dependency structure explicitly.
- Applying the same three-part test to other high-stakes domains could reveal whether the same evaluation shortfall exists elsewhere.
Load-bearing premise
The epidemiology-grounded three-part framework plus the PRIME-CVD cohort's known ground-truth structure is enough to conclude that current generative models cannot support valid clinical conclusions in EMR settings in general.
What would settle it
A generative model that, when trained on the PRIME-CVD cohort, simultaneously preserves subgroup structure, effect estimates, and dependency structure at levels comparable to the real data.
Figures

read the original abstract
Synthetic healthcare data are widely proposed as privacy-preserving substitutes for real patient data, yet their evaluation remains dominated by statistical similarity and predictive performance that do not reflect clinical validity. We introduce a multi-dimensional evaluation framework grounded in epidemiology, assessing descriptive fidelity, clinical utility, and structural validity, corresponding to descriptive, predictive, and causal questions. We evaluate four representative generative paradigms - GAN-based, VAE-boosted, diffusion-based, and masked modelling - using PRIME-CVD, a 50,000-person cohort with known ground-truth structure. While all models reproduce marginal distributions, none simultaneously preserve subgroup structure, effect estimates, and dependency structure. Notably, models with strong distributional fidelity can exhibit poor calibration and distorted relationships, leading to unreliable inference. These results show that current evaluation practices can overestimate synthetic data quality and motivate domain-informed assessment based on the ability to support valid clinical and scientific conclusions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multi-dimensional evaluation framework for synthetic EMR data, grounded in epidemiology, with three axes: descriptive fidelity, clinical utility, and structural validity. Using the PRIME-CVD cohort (50k persons with known ground-truth structure), it evaluates four generative paradigms (GAN-based, VAE-boosted, diffusion-based, masked modelling). The central empirical finding is that all models reproduce marginal distributions but none simultaneously preserve subgroup structure, effect estimates, and dependency structure; models with strong distributional fidelity can still show poor calibration and distorted relationships.
Significance. If the results hold, the work is significant for demonstrating that standard statistical-similarity metrics can overestimate the utility of synthetic EMR data for clinical inference. The framework's grounding in descriptive/predictive/causal questions and the use of a cohort with independent ground-truth structure provide a concrete, falsifiable basis for the critique of current evaluation practices. This could shift the field toward domain-informed assessment that better supports valid scientific conclusions.
major comments (2)
- [Abstract and conclusion] Abstract and conclusion: the claim that current generative models cannot support valid clinical conclusions rests on results from a single 50k-person cohort (PRIME-CVD). No additional datasets, representativeness argument, or sensitivity analysis across cohort characteristics is described. This is load-bearing for the generalization beyond the specific PRIME-CVD setting.
- [Methods] Methods (implied by abstract): the support for the central claim that 'none simultaneously preserve subgroup structure, effect estimates, and dependency structure' cannot be fully verified without the exact metrics, statistical tests, and full experimental protocol for each dimension of the framework.
minor comments (1)
- [Abstract] The abstract would benefit from explicitly naming the four paradigms evaluated and the precise metrics used for each of the three evaluation axes.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the work.
read point-by-point responses
-
Referee: [Abstract and conclusion] Abstract and conclusion: the claim that current generative models cannot support valid clinical conclusions rests on results from a single 50k-person cohort (PRIME-CVD). No additional datasets, representativeness argument, or sensitivity analysis across cohort characteristics is described. This is load-bearing for the generalization beyond the specific PRIME-CVD setting.
Authors: We agree that the empirical demonstration is limited to the PRIME-CVD cohort, which was selected specifically because it provides known ground-truth structure for evaluating structural validity. This choice enables the central falsifiable test but does constrain broad generalization claims. In revision we will modify the abstract and conclusion to state that the findings are demonstrated on PRIME-CVD and that the framework is intended to be applied to other cohorts with comparable ground-truth information. We will also add an explicit limitations paragraph discussing cohort-specific factors and the desirability of multi-cohort validation. These changes will be made without altering the core empirical result. revision: yes
-
Referee: [Methods] Methods (implied by abstract): the support for the central claim that 'none simultaneously preserve subgroup structure, effect estimates, and dependency structure' cannot be fully verified without the exact metrics, statistical tests, and full experimental protocol for each dimension of the framework.
Authors: The manuscript already specifies the three evaluation axes, the concrete metrics (e.g., subgroup-stratified Kolmogorov-Smirnov distances, calibration slopes for effect estimates, and mutual-information or partial-correlation measures for dependencies), and the statistical tests used to assess preservation. To improve verifiability we will expand the Methods section with a dedicated subsection that lists every metric formula, the exact hypothesis tests (including multiplicity corrections), and the full experimental protocol, and we will release the corresponding code repository upon acceptance. These additions will make every quantitative claim directly reproducible from the provided description. revision: yes
Circularity Check
Empirical evaluation on external cohort with independent ground truth; no derivations or self-referential reductions
full rationale
The paper introduces a multi-dimensional evaluation framework grounded in epidemiology and applies it to compare four generative model classes on the PRIME-CVD cohort, which supplies independent ground-truth structure. All claims rest on direct empirical measurements of marginals, subgroups, effect estimates, and dependencies rather than any mathematical derivation, fitted parameter renamed as prediction, or self-citation chain. No equations or ansatzes appear that could reduce outputs to inputs by construction. The central finding—that no model simultaneously preserves all three validity dimensions—is therefore an independent observation relative to the input data and framework definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Enriching data science and health care education: Application and impact of synthetic data sets through the health gym project.JMIR Medical Education, 10(1):e51388, 2024
Nicholas I-Hsien Kuo, Oscar Perez-Concha, Mark Hanly, Emmanuel Mnatzaganian, Brandon Hao, Marcus Di Sipio, Guolin Yu, Jash Vanjara, Ivy Cerelia Valerie, et al. Enriching data science and health care education: Application and impact of synthetic data sets through the health gym project.JMIR Medical Education, 10(1):e51388, 2024
2024
-
[2]
Evaluating the impact of health care data completeness for deep generative models.Methods of Information in Medicine, 62 (01/02):031–039, 2023
Benjamin Smith, Senne Van Steelandt, and Anahita Khojandi. Evaluating the impact of health care data completeness for deep generative models.Methods of Information in Medicine, 62 (01/02):031–039, 2023
2023
-
[3]
Synthetic data in machine learning for medicine and healthcare.Nature Biomedical Engineering, 5(6):493–497, 2021
Richard J Chen, Ming Y Lu, Tiffany Y Chen, Drew FK Williamson, and Faisal Mahmood. Synthetic data in machine learning for medicine and healthcare.Nature Biomedical Engineering, 5(6):493–497, 2021
2021
-
[4]
Transformation of medical care through gene therapy and human rights to life and health–balancing risks and benefits.European Journal of Health Law, 29(3-5):359–380, 2022
Anne Kjersti Befring. Transformation of medical care through gene therapy and human rights to life and health–balancing risks and benefits.European Journal of Health Law, 29(3-5):359–380, 2022
2022
-
[5]
Survey on synthetic data generation, evaluation methods and gans.Mathematics, 10(15):2733, 2022
Alvaro Figueira and Bruno Vaz. Survey on synthetic data generation, evaluation methods and gans.Mathematics, 10(15):2733, 2022
2022
-
[6]
Synthetic data generation: State of the art in health care domain.Computer Science Review, 48:100546, 2023
Hajra Murtaza, Musharif Ahmed, Naurin Farooq Khan, Ghulam Murtaza, Saad Zafar, and Ambreen Bano. Synthetic data generation: State of the art in health care domain.Computer Science Review, 48:100546, 2023
2023
-
[7]
Can i trust my fake data–a comprehensive quality assessment framework for synthetic tabular data in healthcare.International Journal of Medical Informatics, 185:105413, 2024
Vibeke Binz Vallevik, Aleksandar Babic, Serena E Marshall, Severin Elvatun, Helga MB Brøgger, Sharmini Alagaratnam, Bjørn Edwin, Narasimha R Veeraragavan, Anne Kjersti Befring, and Jan F Nygård. Can i trust my fake data–a comprehensive quality assessment framework for synthetic tabular data in healthcare.International Journal of Medical Informatics, 185:1...
2024
-
[8]
How to use a subgroup analysis: users’ guide to the medical literature.Jama, 311(4), 2014
Xin Sun, John PA Ioannidis, Thomas Agoritsas, Ana C Alba, and Gordon Guyatt. How to use a subgroup analysis: users’ guide to the medical literature.Jama, 311(4), 2014
2014
-
[9]
Estimating causal effects from epidemiological data
Miguel A Hernán and James M Robins. Estimating causal effects from epidemiological data. Journal of Epidemiology & Community Health, 60(7):578–586, 2006
2006
-
[10]
Use of directed acyclic graphs (dags) to identify confounders in applied health research: review and recommendations.International journal of epidemiology, 50(2):620–632, 2021
Peter WG Tennant, Eleanor J Murray, Kellyn F Arnold, Laurie Berrie, Matthew P Fox, Sarah C Gadd, Wendy J Harrison, Claire Keeble, Lynsie R Ranker, Johannes Textor, et al. Use of directed acyclic graphs (dags) to identify confounders in applied health research: review and recommendations.International journal of epidemiology, 50(2):620–632, 2021
2021
-
[11]
Prime- cvd: A parametrically rendered informatics medical environment for education in cardiovascular risk modelling.medRxiv, pages 2026–03, 2026
Nicholas I-Hsien Kuo, Marzia Hoque Tania, Blanca Gallego Luxan, and Louisa Jorm. Prime- cvd: A parametrically rendered informatics medical environment for education in cardiovascular risk modelling.medRxiv, pages 2026–03, 2026
2026
-
[12]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[13]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[14]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. InInternational conference on machine learning, pages 214–223. Pmlr, 2017
2017
-
[15]
Improved training of wasserstein gans.Advances in neural information processing systems, 30, 2017
Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of wasserstein gans.Advances in neural information processing systems, 30, 2017
2017
-
[16]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015. 10
2015
-
[17]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[18]
Extracting and composing robust features with denoising autoencoders
Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. InProceedings of the 25th international conference on Machine learning, pages 1096–1103, 2008
2008
-
[19]
Context encoders: Feature learning by inpainting
Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2536–2544, 2016
2016
-
[20]
Deep variational information bottleneck
Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. Deep variational information bottleneck. InInternational Conference on Learning Representations, 2017
2017
-
[21]
Autoencoding beyond pixels using a learned similarity metric
Anders Boesen Lindbo Larsen, Søren Kaae Sønderby, Hugo Larochelle, and Ole Winther. Autoencoding beyond pixels using a learned similarity metric. InInternational conference on machine learning, pages 1558–1566. PMLR, 2016
2016
-
[22]
Generative adversarial networks are special cases of artificial curiosity (1990) and also closely related to predictability minimization (1991).Neural Networks, 127: 58–66, 2020
Jürgen Schmidhuber. Generative adversarial networks are special cases of artificial curiosity (1990) and also closely related to predictability minimization (1991).Neural Networks, 127: 58–66, 2020
1990
-
[23]
NIPS 2016 Tutorial: Generative Adversarial Networks
Ian Goodfellow. Nips 2016 tutorial: Generative adversarial networks.arXiv preprint arXiv:1701.00160, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
The health gym: synthetic health-related datasets for the development of reinforcement learning algorithms
Nicholas I-Hsien Kuo, Mark N Polizzotto, Simon Finfer, Federico Garcia, Anders Sönnerborg, Maurizio Zazzi, Michael Böhm, Rolf Kaiser, Louisa Jorm, and Sebastiano Barbieri. The health gym: synthetic health-related datasets for the development of reinforcement learning algorithms. Scientific data, 9(1):693, 2022
2022
-
[25]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[26]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[27]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[28]
Behrt: transformer for electronic health records.Scientific reports, 10(1):7155, 2020
Yikuan Li, Shishir Rao, José Roberto Ayala Solares, Abdelaali Hassaine, Rema Ramakrishnan, Dexter Canoy, Yajie Zhu, Kazem Rahimi, and Gholamreza Salimi-Khorshidi. Behrt: transformer for electronic health records.Scientific reports, 10(1):7155, 2020
2020
-
[29]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[31]
Weak baselines and reporting biases lead to overoptimism in machine learning for fluid-related partial differential equations.Nature machine intelligence, 6(10):1256–1269, 2024
Nick McGreivy and Ammar Hakim. Weak baselines and reporting biases lead to overoptimism in machine learning for fluid-related partial differential equations.Nature machine intelligence, 6(10):1256–1269, 2024
2024
-
[32]
Sulla determinazione empirica di una legge didistribuzione.Giorn Dell’inst Ital Degli Att, 4:89–91, 1933
Kolmogorov An. Sulla determinazione empirica di una legge didistribuzione.Giorn Dell’inst Ital Degli Att, 4:89–91, 1933
1933
-
[33]
Table for estimating the goodness of fit of empirical distributions.The annals of mathematical statistics, 19(2):279–281, 1948
Nickolay Smirnov. Table for estimating the goodness of fit of empirical distributions.The annals of mathematical statistics, 19(2):279–281, 1948
1948
-
[34]
On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951. 11
1951
-
[35]
Similarity-based methods for word sense disambiguation
Ido Dagan, Lillian Lee, and Fernando Pereira. Similarity-based methods for word sense disambiguation. In35th Annual Meeting of the Association for Computational Linguistics and 8th Conference of the European Chapter of the Association for Computational Linguistics, pages 56–63, 1997
1997
-
[36]
Learning via hilbert space embedding of distributions.University of Sydney (2008), 17, 2008
Le Song. Learning via hilbert space embedding of distributions.University of Sydney (2008), 17, 2008
2008
-
[37]
A class of wasserstein metrics for probability distribu- tions.Michigan Mathematical Journal, 31(2):231–240, 1984
Clark R Givens and Rae Michael Shortt. A class of wasserstein metrics for probability distribu- tions.Michigan Mathematical Journal, 31(2):231–240, 1984
1984
-
[38]
Principal component analysis: A natural approach to data exploration.ACM Computing Surveys (CSUR), 54(4):1–34, 2021
Felipe L Gewers, Gustavo R Ferreira, Henrique F De Arruda, Filipi N Silva, Cesar H Comin, Diego R Amancio, and Luciano da F Costa. Principal component analysis: A natural approach to data exploration.ACM Computing Surveys (CSUR), 54(4):1–34, 2021
2021
-
[39]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[40]
The central role of the propensity score in observational studies for causal effects.Biometrika, 70(1):41–55, 1983
Paul R Rosenbaum and Donald B Rubin. The central role of the propensity score in observational studies for causal effects.Biometrika, 70(1):41–55, 1983
1983
-
[41]
Adrian Ybañez, Rosein Ancheta, Samantha Shane Evangelista, Joerabell Lourdes Aro, Fatima Maturan, Nadine May Atibing, Egberto Selerio, Kafferine Yamagishi, and Lanndon Ocampo. How can we use machine learning for characterizing organizational identification-a study using clustering with picture fuzzy datasets.International Journal of Information Management...
2023
-
[42]
Comparison of tabular synthetic data generation techniques using propensity and cluster log metric.International Journal of Information Management Data Insights, 3(2): 100177, 2023
Aryan Pathare, Ramchandra Mangrulkar, Kartik Suvarna, Aryan Parekh, Govind Thakur, and Aruna Gawade. Comparison of tabular synthetic data generation techniques using propensity and cluster log metric.International Journal of Information Management Data Insights, 3(2): 100177, 2023
2023
-
[43]
Generating and evaluating cross-sectional synthetic electronic healthcare data: preserving data utility and patient privacy.Computational Intelligence, 37(2):819–851, 2021
Zhenchen Wang, Puja Myles, and Allan Tucker. Generating and evaluating cross-sectional synthetic electronic healthcare data: preserving data utility and patient privacy.Computational Intelligence, 37(2):819–851, 2021
2021
-
[44]
A multi-dimensional evaluation of synthetic data generators.IEEE Access, 10:11147–11158, 2022
Fida K Dankar, Mahmoud K Ibrahim, and Leila Ismail. A multi-dimensional evaluation of synthetic data generators.IEEE Access, 10:11147–11158, 2022
2022
-
[45]
Synthetic tab- ular data evaluation in the health domain covering resemblance, utility, and privacy dimensions
Mikel Hernadez, Gorka Epelde, Ane Alberdi, Rodrigo Cilla, and Debbie Rankin. Synthetic tab- ular data evaluation in the health domain covering resemblance, utility, and privacy dimensions. Methods of information in medicine, 62(S 01):e19–e38, 2023
2023
-
[46]
How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models
Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela Van Der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International conference on machine learning, pages 290–306. PMLR, 2022
2022
-
[47]
Evaluating identity disclosure risk in fully synthetic health data: model development and validation.Journal of medical Internet research, 22(11):e23139, 2020
Khaled El Emam, Lucy Mosquera, and Jason Bass. Evaluating identity disclosure risk in fully synthetic health data: model development and validation.Journal of medical Internet research, 22(11):e23139, 2020
2020
-
[48]
Nicholas I-Hsien Kuo, Blanca Gallego, Louisa Jorm, et al. Ck4gen: A knowledge distillation framework for generating high-utility synthetic survival datasets in healthcare.arXiv preprint arXiv:2410.16872, 2024
-
[49]
Estimating 5-year absolute risk of cardiovascular disease using routinely collected electronic medical records from australian general practices.Heart, 2025
Nicholas I-Hsien Kuo, Sebastiano Barbieri, Clare Arnott, Blanca Gallego, Ziba Gandomkar, Shahana Ferdousi, Kirsty Douglas, Mark Woodward, and Louisa Jorm. Estimating 5-year absolute risk of cardiovascular disease using routinely collected electronic medical records from australian general practices.Heart, 2025
2025
-
[50]
Ruth Walker and Janet E Hiller. The index of relative socio-economic disadvantage: general population views on indicators used to determine area-based disadvantage.Australian and New Zealand journal of public health, 29(5):442–447, 2005. 12
2005
-
[51]
PRIME-CVD Data Asset 1: DAG-Simulated Cardiovascular Risk Cohort for Medical Informatics Education
Nicholas I-Hsien Kuo. PRIME-CVD Data Asset 1: DAG-Simulated Cardiovascular Risk Cohort for Medical Informatics Education. https://figshare.com/articles/dataset/ PRIME-CVD_Data_Asset_1_DAG-Simulated_Cardiovascular_Risk_Cohort_for_ Medical_Informatics_Education/31395765, February 2026
-
[52]
Nicholas I-Hsien Kuo, Federico Garcia, Anders Sönnerborg, Michael Böhm, Rolf Kaiser, Maurizio Zazzi, Mark Polizzotto, Louisa Jorm, Sebastiano Barbieri, et al. Generating synthetic clinical data that capture class imbalanced distributions with generative adversarial networks: Example using antiretroviral therapy for hiv.Journal of Biomedical Informatics, 1...
2023
-
[53]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[54]
Synthetic health-related longitudinal data with mixed-type variables generated using diffusion models
Nicholas I-Hsien Kuo, Federico Garcia, Anders Sonnerborg, Michael Bohm, Rolf Kaiser, Maurizio Zazzi, Louisa Jorm, and Sebastiano Barbieri. Synthetic health-related longitudinal data with mixed-type variables generated using diffusion models. InNeurIPS 2023 Workshop on Synthetic Data Generation with Generative AI, 2023
2023
-
[55]
Nicholas I-Hsien Kuo, Blanca Gallego, and Louisa Jorm. Attention-based synthetic data generation for calibration-enhanced survival analysis: a case study for chronic kidney disease using electronic health records.Journal of Biomedical Informatics, page 104928, 2025
2025
-
[56]
Centrum voor Wiskunde en Informatica Amsterdam, 1995
Guido Van Rossum, Fred L Drake, et al.Python reference manual, volume 111. Centrum voor Wiskunde en Informatica Amsterdam, 1995
1995
-
[57]
identifying variables that independently predict
John B Carlin. “identifying variables that independently predict. . . ” is not a well-defined research task.Journal of Clinical Epidemiology, 189, 2026
2026
-
[58]
The distinction between causal, predictive, and descriptive research–there is still room for improvement.Journal of Clinical Epidemiology, page 111960, 2025
Brett P Dyer. The distinction between causal, predictive, and descriptive research–there is still room for improvement.Journal of Clinical Epidemiology, page 111960, 2025
2025
-
[59]
John Wiley & Sons, 2002
John D Kalbfleisch and Ross L Prentice.The statistical analysis of failure time data. John Wiley & Sons, 2002
2002
-
[60]
Regression models and life-tables.Journal of the royal statistical society: Series B (methodological), 34(2):187–202, 1972
David R Cox. Regression models and life-tables.Journal of the royal statistical society: Series B (methodological), 34(2):187–202, 1972
1972
-
[61]
Calibration: the achilles heel of predictive analytics.BMC medicine, 17(1):230, 2019
Ben Van Calster, David J McLernon, Maarten Van Smeden, Laure Wynants, and Ewout W Steyerberg. Calibration: the achilles heel of predictive analytics.BMC medicine, 17(1):230, 2019
2019
-
[62]
Learning equivalence classes of bayesian-network structures
David Maxwell Chickering. Learning equivalence classes of bayesian-network structures. Journal of machine learning research, 2(Feb):445–498, 2002
2002
-
[63]
Structural Intervention Distance (SID) for Evaluating Causal Graphs
Jonas Peters and Peter Bühlmann. Structural intervention distance (sid) for evaluating causal graphs.arXiv preprint arXiv:1306.1043, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[64]
Smote: synthetic minority over-sampling technique.Journal of artificial intelligence research, 16: 321–357, 2002
Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique.Journal of artificial intelligence research, 16: 321–357, 2002
2002
-
[65]
Differential privacy
Cynthia Dwork. Differential privacy. InEncyclopedia of Cryptography, Security and Privacy, pages 649–652. Springer, 2025
2025
-
[66]
Array programming with numpy.nature, 585(7825):357–362, 2020
Charles R Harris, K Jarrod Millman, Stéfan J Van Der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J Smith, et al. Array programming with numpy.nature, 585(7825):357–362, 2020
2020
-
[67]
Data structures for statistical computing in python.scipy, 445(1):51–56, 2010
Wes McKinney et al. Data structures for statistical computing in python.scipy, 445(1):51–56, 2010. 13
2010
-
[68]
Scipy 1.0: fundamental algorithms for scientific computing in python.Nature methods, 17(3):261–272, 2020
Pauli Virtanen, Ralf Gommers, Travis E Oliphant, Matt Haberland, Tyler Reddy, David Courna- peau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, et al. Scipy 1.0: fundamental algorithms for scientific computing in python.Nature methods, 17(3):261–272, 2020
2020
-
[69]
Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
2011
-
[70]
Matplotlib: A 2d graphics environment.Computing in science & engineering, 9(3):90–95, 2007
John D Hunter. Matplotlib: A 2d graphics environment.Computing in science & engineering, 9(3):90–95, 2007
2007
-
[71]
Seaborn: statistical data visualization.Journal of open source software, 6 (60):3021, 2021
Michael L Waskom. Seaborn: statistical data visualization.Journal of open source software, 6 (60):3021, 2021
2021
-
[72]
lifelines: survival analysis in python.Journal of Open Source Software, 4(40):1317, 2019
Cameron Davidson-Pilon. lifelines: survival analysis in python.Journal of Open Source Software, 4(40):1317, 2019
2019
-
[73]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[74]
Causal-learn: Causal discovery in python.Journal of Machine Learning Research, 25(60):1–8, 2024
Yujia Zheng, Biwei Huang, Wei Chen, Joseph Ramsey, Mingming Gong, Ruichu Cai, Shohei Shimizu, Peter Spirtes, and Kun Zhang. Causal-learn: Causal discovery in python.Journal of Machine Learning Research, 25(60):1–8, 2024
2024
-
[75]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. 14 Appendix: Additional Details to the Main Text Purpose of this Appendix.This appendix provides detailed methodological, implementation, and supplementary result information supporting the main text. It ensures reproducibility, clarifies evalu...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[76]
an auxiliary autoencoder update on embedded real samples,
-
[77]
multiple critic updates using the WGAN-GP objective,
-
[78]
one generator update using the adversarial and correlation-alignment losses. Formally, the model optimises min G,A max D Exreal[D(xreal)]−E z[D(G(z))] +λ GP ·GP +λ corr · Lcorr +L A, with the understanding that LA is applied only to the auxiliary autoencoder parameters, while the adversarial objectives govern the generator and critic updates. In the imple...
-
[79]
samplex 0 from real data,
-
[80]
sample timestept∼ U {1, . . . , T},
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.