Generalized Rank-based Evaluation for Knowledge Graph Completion: Perspectives, Framework, and Analyses
Pith reviewed 2026-06-27 17:14 UTC · model grok-4.3
The pith
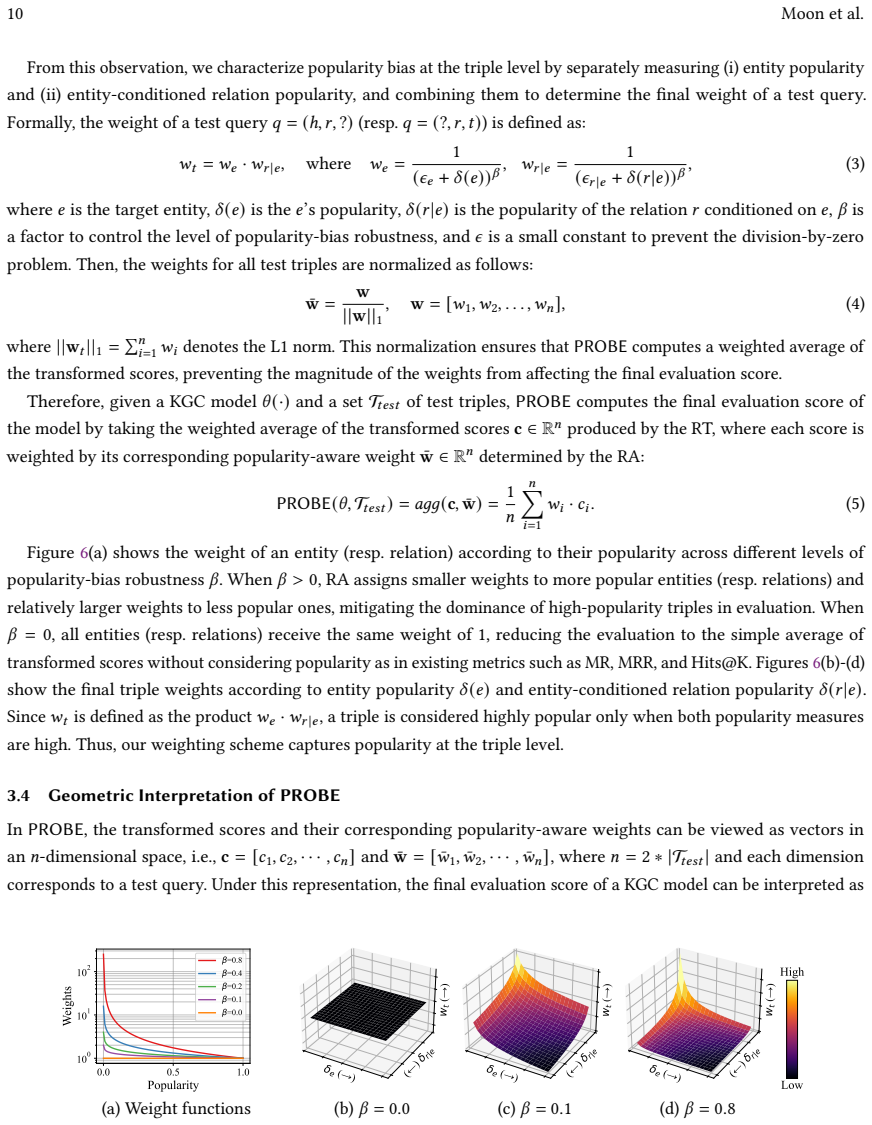
PROBE is a generalized rank-based framework for evaluating knowledge graph completion models that meets all six reliability properties while existing metrics do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
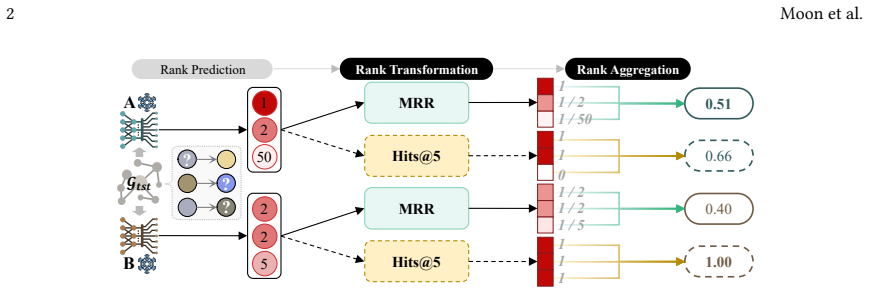
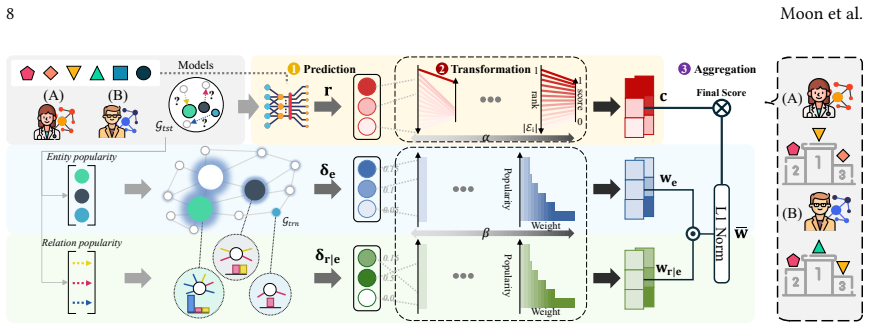
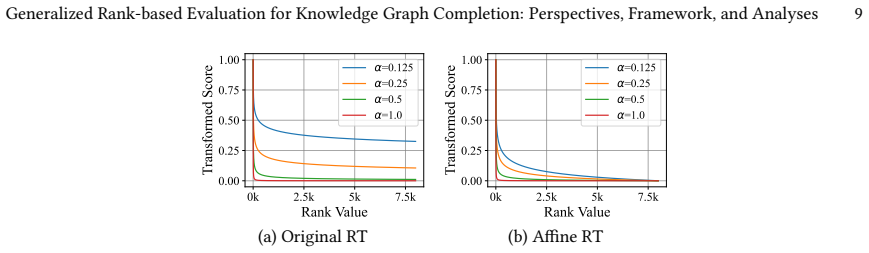
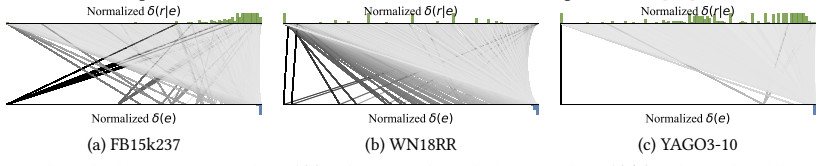
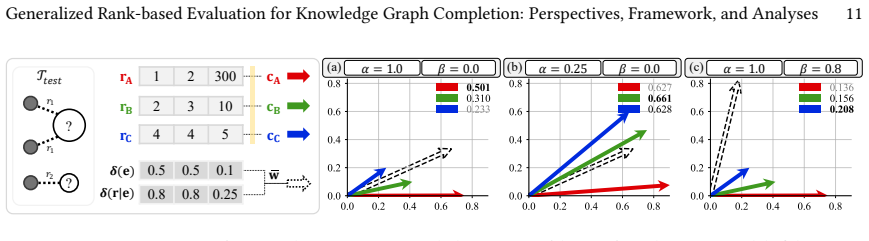
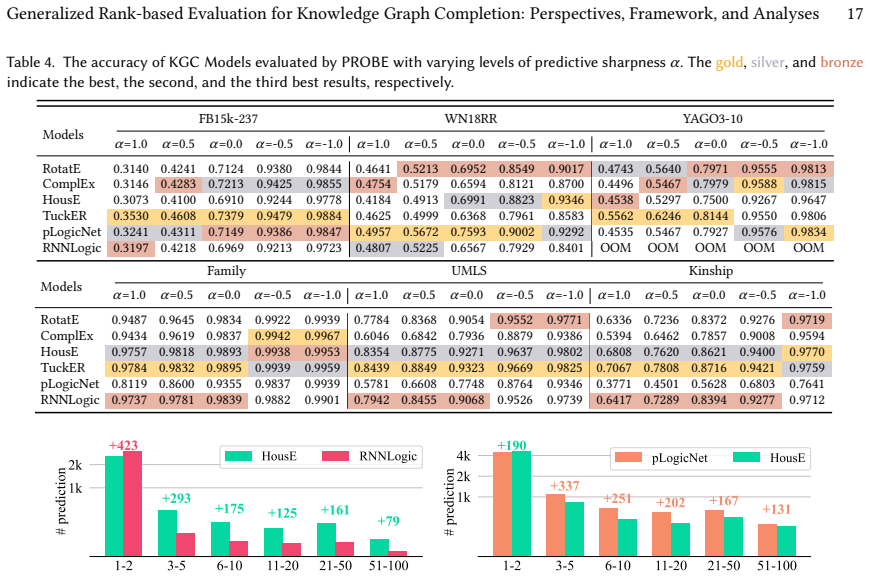
PROBE consists of a rank transformer that estimates each prediction's score according to a user-chosen level of predictive sharpness and a rank aggregator that combines those scores according to a user-chosen level of popularity-bias robustness. The framework satisfies all six key properties defined for reliable KGC evaluation and, because of the open-world nature of knowledge graphs, better preserves the relative ordering of models when only incomplete facts are observed, yielding a more consistent estimate of intrinsic model performance than existing rank-based metrics.
What carries the argument
The PROBE framework, which uses a rank transformer to adjust prediction scores for a target predictive sharpness and a rank aggregator to combine them for a target popularity-bias robustness.
If this is right
- Existing metrics can produce misleading model rankings when predictive sharpness or popularity bias is important for the application.
- PROBE allows practitioners to select evaluation behavior by setting two explicit parameters rather than relying on fixed metrics.
- Model comparisons remain stable when test sets are incomplete, which is the usual case for real KGs.
- Theoretical guarantees show that PROBE meets every listed reliability property while prior metrics fail at least one.
- Empirical results across multiple models and datasets confirm that different metrics can reverse model orderings depending on the perspective.
Where Pith is reading between the lines
- If applications differ in how much they value sharp top-k predictions versus robustness to entity popularity, PROBE's parameters could be tuned per task rather than using a single default metric.
- The same rank-transformer and aggregator construction might apply to other ranking evaluation settings where open-world incompleteness is present.
- Standardizing on a small number of property-satisfying metrics could reduce the practice of reporting only the metric that favors a new model.
- The framework assumes the two perspectives can be controlled independently; interactions between sharpness and robustness settings would need separate verification.
Load-bearing premise
That the six defined properties are the necessary and sufficient criteria for reliable KGC evaluation and that the rank transformer and aggregator can be built to meet any chosen sharpness and robustness levels without creating new inconsistencies.
What would settle it
A controlled experiment in which the true ranking of two KGC models on a fully observed test set is known, then the same models are re-evaluated on successively smaller random subsets of that test set; if PROBE's relative ordering flips more often than the ground-truth ordering while existing metrics do not, the consistency claim is falsified.
Figures

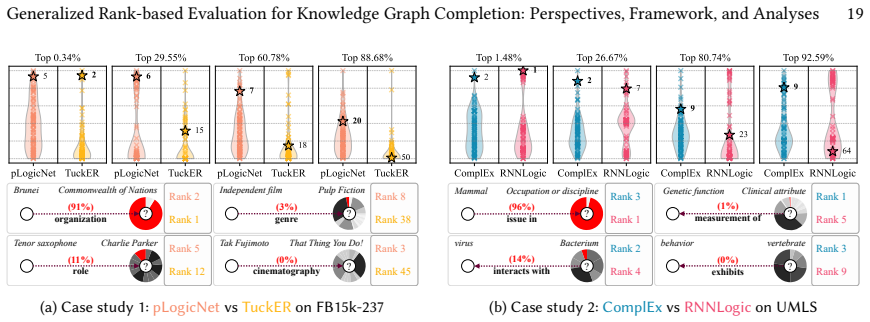
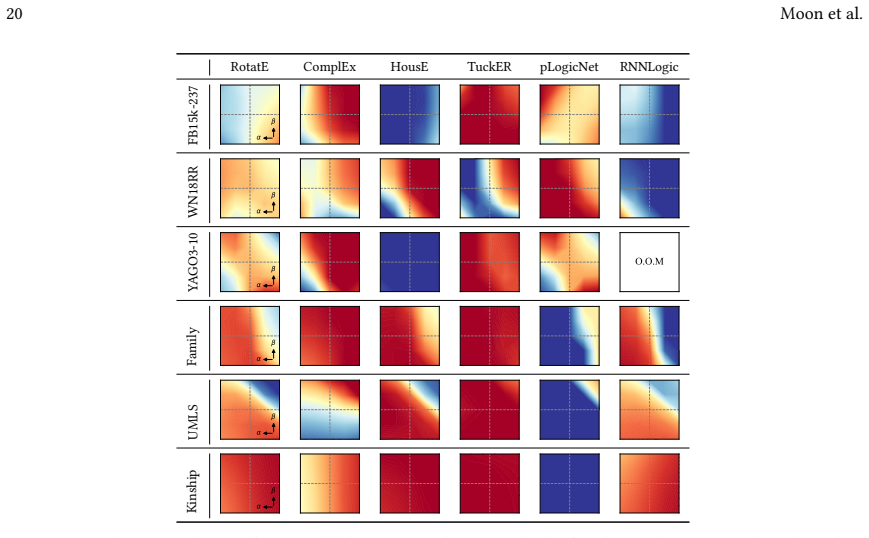
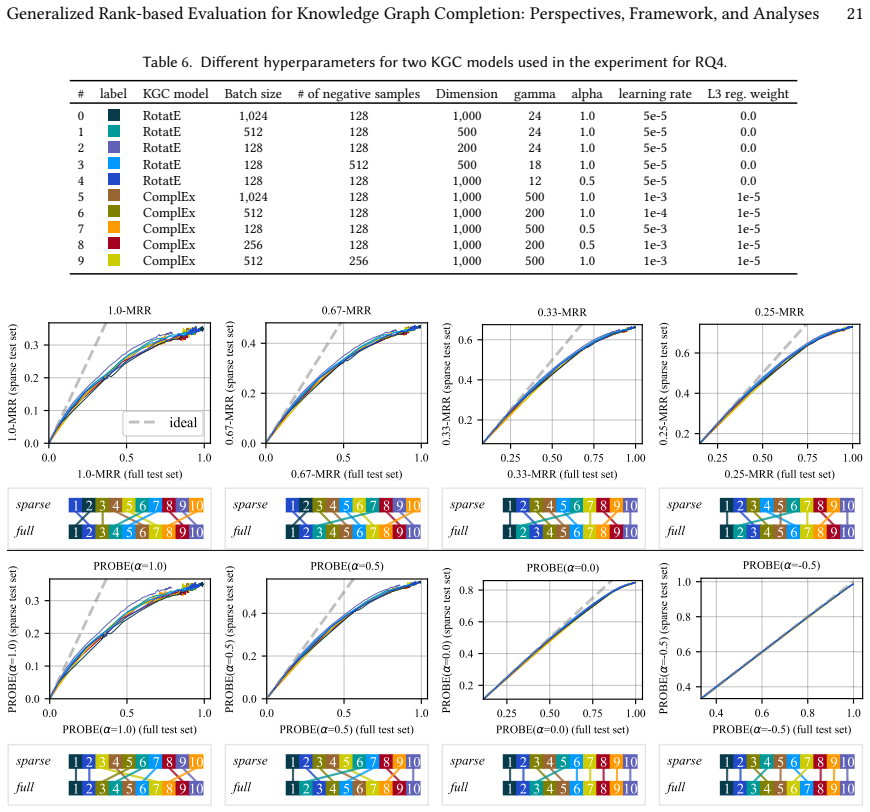
read the original abstract
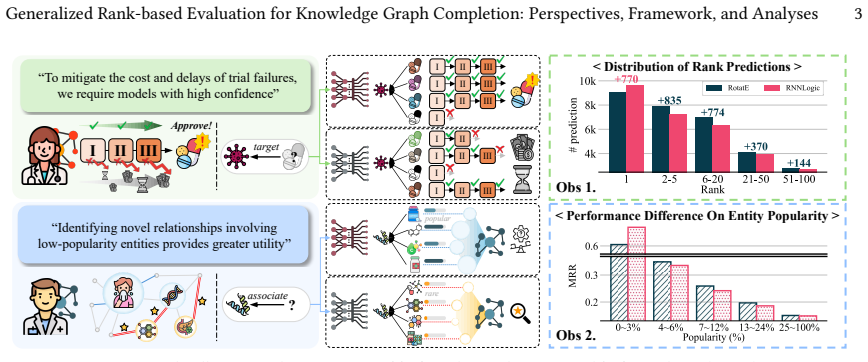
Knowledge graph completion (KGC) aims to predict missing facts from an observed knowledge graph (KG), playing a crucial role in a wide range of real-world applications such as drug discovery, recommender systems, and retrieval-augmented generation (RAG). Although numerous KGC models have been proposed, the evaluation of KGC remains underexplored, despite its critical role in reliably assessing model performance and selecting appropriate models for real-world applications. In this paper, we introduce two important perspectives for KGC evaluation that are overlooked by existing evaluation metrics, (P1) predictive sharpness and (P2) popularity-bias robustness. To address both perspectives, we propose a generalized evaluation framework, PROBE, which consists of a rank transformer (RT) that estimates the score of each prediction based on a desired level of predictive sharpness and a rank aggregator (RA) that determines the final evaluation score by aggregating all prediction scores according to a desired level of popularity-bias robustness. We theoretically analyze PROBE by defining six key properties for reliable KGC evaluation and prove that PROBE satisfies all the properties, while existing metrics fail to satisfy some. In particular, due to the open-world nature of KGs, an evaluation metric should preserve the relative performance of KGC models even when only incomplete facts are observed. We show that PROBE better maintains such consistency, providing a more reliable estimate of intrinsic model performance than existing metrics. Extensive experiments with six KGC models on six real-world KGs reveal that existing metrics may over- or under-estimate model performance depending on different evaluation perspectives, whereas PROBE enables a more comprehensive, flexible, and consistent evaluation of KGC models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing KGC evaluation metrics overlook predictive sharpness (P1) and popularity-bias robustness (P2). It introduces the PROBE framework consisting of a rank transformer (RT) that adjusts prediction scores for a user-specified sharpness level and a rank aggregator (RA) that aggregates scores for a user-specified robustness level. The authors define six key properties for reliable KGC evaluation, prove that PROBE satisfies all six while prior metrics fail some, and report experiments on six models and six KGs showing that PROBE better preserves relative model rankings under incomplete observations arising from the open-world assumption.
Significance. If the proofs are rigorous, the work supplies a flexible, parameterized evaluation approach that directly targets two practically relevant perspectives and supplies explicit theoretical guarantees. The emphasis on consistency under incomplete observations is a useful contribution given the open-world nature of KGs. The provision of machine-checkable-style proofs (if they are fully detailed) and reproducible experimental comparisons would strengthen the assessment.
major comments (1)
- [Theoretical Analysis] Theoretical Analysis section: The six properties are defined with reference to the target sharpness and robustness levels that RT and RA are constructed to achieve; the proofs that PROBE satisfies the properties therefore appear to hold by construction from the definitions of RT and RA. This raises a question of whether the properties constitute independent external criteria or are satisfied tautologically once the parameterization is chosen.
minor comments (2)
- [Abstract] Abstract: The six key properties are referenced but not enumerated; listing them (even briefly) would allow readers to assess the scope of the theoretical claims immediately.
- [Experiments] Experiments: The specific numerical values chosen for the sharpness and robustness parameters in the reported runs should be stated explicitly together with a brief sensitivity analysis or justification that they correspond to realistic application requirements.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and the recommendation for minor revision. We address the major comment below.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical Analysis section: The six properties are defined with reference to the target sharpness and robustness levels that RT and RA are constructed to achieve; the proofs that PROBE satisfies the properties therefore appear to hold by construction from the definitions of RT and RA. This raises a question of whether the properties constitute independent external criteria or are satisfied tautologically once the parameterization is chosen.
Authors: The six properties are independently motivated by the two evaluation perspectives (P1: predictive sharpness; P2: popularity-bias robustness) that arise from practical challenges in KGC under the open-world assumption, as stated in the introduction and Section 3. The properties are parameterized because PROBE is explicitly a generalized framework allowing user-specified levels; the definitions are not circular but reflect the desired behavior any reliable metric should exhibit at those levels. The non-triviality is shown by the fact that prior metrics fail some properties despite being able to be viewed as special cases. The proofs establish that the specific RT and RA constructions achieve the properties for arbitrary targets, which existing approaches do not. We will add one clarifying paragraph in the revised Section 4 to explicitly separate the motivation of the properties from the construction of PROBE. revision: partial
Circularity Check
No significant circularity identified
full rationale
The supplied material contains no equations, property definitions, or proof steps that would allow quoting a specific reduction (e.g., a property defined in terms of the RT/RA construction or a prediction that is the fitted input by construction). The central claim is a theoretical proof that PROBE satisfies six defined properties while prior metrics fail some; absent the actual definitions or derivation, this cannot be shown to collapse to self-definition or self-citation load-bearing. The framework is presented as a new construction addressing two perspectives, with the proof treated as independent verification. This is the most common honest finding for a paper whose internal logic is not exhibited as circular in the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ivana Balazevic, Carl Allen, and Timothy Hospedales. 2019. TuckER: Tensor Factorization for Knowledge Graph Completion. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, Chin...
-
[2]
Dongmin Bang, Sangsoo Lim, Sangseon Lee, and Sun Kim. 2023. Biomedical knowledge graph learning for drug repurposing by extending guilt-by-association to multiple layers.Nature Communications14, 1 (2023), 3570
2023
-
[3]
Max Berrendorf, Evgeniy Faerman, Laurent Vermue, and Volker Tresp. 2020. On the ambiguity of rank-based evaluation of entity alignment or link prediction methods.arXiv preprint arXiv:2002.06914(2020)
arXiv 2020
-
[4]
Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. InProceedings of the 2008 ACM SIGMOD International Conference on Management of Data. 1247–1250
2008
-
[5]
Stephen Bonner, Ian P Barrett, Cheng Ye, Rowan Swiers, Ola Engkvist, Andreas Bender, Charles Tapley Hoyt, and William L Hamilton. 2022. A review of biomedical datasets relating to drug discovery: a knowledge graph perspective.Briefings in Bioinformatics23, 6 (2022), bbac404
2022
-
[6]
Stephen Bonner, Ufuk Kirik, Ola Engkvist, Jian Tang, and Ian P Barrett. 2022. Implications of topological imbalance for representation learning on biomedical knowledge graphs.Briefings in bioinformatics23, 5 (2022), bbac279
2022
-
[7]
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. InAdvances in Neural Information Processing Systems, Vol. 26
2013
-
[8]
Andrew Carlson, Justin Betteridge, Bryan Kisiel, Burr Settles, Estevam Hruschka, and Tom Mitchell. 2010. Toward an architecture for never-ending language learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 24. 1306–1313
2010
-
[9]
Boyu Chen, Zirui Guo, Zidan Yang, Yuluo Chen, Junze Chen, Zhenghao Liu, Chuan Shi, and Cheng Yang. 2025. Pathrag: Pruning graph-based retrieval augmented generation with relational paths.arXiv preprint arXiv:2502.14902(2025)
arXiv 2025
-
[10]
Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2018. Convolutional 2D knowledge graph embeddings. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 32. Generalized Rank-based Evaluation for Knowledge Graph Completion: Perspectives, Framework, and Analyses 23
2018
-
[11]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph RAG approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
Pith/arXiv arXiv 2024
-
[12]
Shangbin Feng, Zilong Chen, Wenqian Zhang, Qingyao Li, Qinghua Zheng, Xiaojun Chang, and Minnan Luo. 2021. Kgap: Knowledge graph augmented political perspective detection in news media.arXiv preprint arXiv:2108.03861(2021)
arXiv 2021
-
[13]
Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Xing Xie, Hui Xiong, and Qing He. 2020. A survey on knowledge graph-based recommender systems.IEEE Transactions on Knowledge and Data Engineering34, 8 (2020), 3549–3568
2020
-
[14]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2024. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779(2024)
Pith/arXiv arXiv 2024
-
[15]
Yanchao Hao, Yuanzhe Zhang, Kang Liu, Shizhu He, Zhanyi Liu, Hua Wu, and Jun Zhao. 2017. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 221–231
2017
-
[16]
Charles Tapley Hoyt, Max Berrendorf, Mikhail Galkin, Volker Tresp, and Benjamin M Gyori. 2022. A unified framework for rank-based evaluation metrics for link prediction in knowledge graphs.arXiv preprint arXiv:2203.07544(2022)
arXiv 2022
-
[17]
Xiao Huang, Jingyuan Zhang, Dingcheng Li, and Ping Li. 2019. Knowledge graph embedding based question answering. InProceedings of the twelfth ACM international conference on web search and data mining. 105–113
2019
-
[18]
Myung-Hwan Jang, Yunyong Ko, Hyuck-Moo Gwon, Ikhyeon Jo, Yongjun Park, and Sang-Wook Kim. 2023. SAGE: A Storage-Based Approach for Scalable and Efficient Sparse Generalized Matrix-Matrix Multiplication. InProceedings of the ACM International Conference on Information and Knowledge Management (CIKM). 923–933
2023
-
[19]
Xinke Jiang, Ruizhe Zhang, Yongxin Xu, Rihong Qiu, Yue Fang, Zhiyuan Wang, Jinyi Tang, Hongxin Ding, Xu Chu, Junfeng Zhao, et al . 2025. HyKGE: A hypothesis knowledge graph enhanced RAG framework for accurate and reliable medical LLMs responses. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
2025
-
[20]
Yunyong Ko, Seongeun Ryu, Soeun Han, Youngseung Jeon, Jaehoon Kim, Sohyun Park, Hanghang Han, Kyungsik Tong, and Sang-Wook Kim. 2023. KHAN: Knowledge-Aware Hierarchical Attention Networks for Accurate Political Stance Prediction. InProceedings of the ACM Web Conference (WWW)(Austin, TX, USA). Association for Computing Machinery (ACM), 1572–1583. doi:10.11...
-
[21]
Yunyong Ko, Jae-Seo Yu, Hong-Kyun Bae, Yongjun Park, Dongwon Lee, and Sang-Wook Kim. 2021. MASCOT: A Quantization Framework for Efficient Matrix Factorization in Recommender Systems. InProceedings of the IEEE International Conference on Data Mining (ICDM). IEEE, 290–299
2021
-
[22]
Rui Li, Jianan Zhao, Chaozhuo Li, Di He, Yiqi Wang, Yuming Liu, Hao Sun, Senzhang Wang, Weiwei Deng, Yanming Shen, et al. 2022. House: Knowledge graph embedding with householder parameterization. InInternational Conference on Machine Learning. PMLR, 13209–13224
2022
-
[23]
Xuan Lin, Zhe Quan, Zhi-Jie Wang, Tengfei Ma, and Xiangxiang Zeng. 2020. KGNN: Knowledge graph neural network for drug-drug interaction prediction.. InIJCAI, Vol. 380. 2739–2745
2020
-
[24]
Shuwen Liu, Bernardo Grau, Ian Horrocks, and Egor Kostylev. 2021. Indigo: GNN-based inductive knowledge graph completion using pair-wise encoding. InAdvances in Neural Information Processing Systems, Vol. 34. 2034–2045
2021
-
[25]
Haoran Luo, Guanting Chen, Yandan Zheng, Xiaobao Wu, Yikai Guo, Qika Lin, Yu Feng, Zemin Kuang, Meina Song, Yifan Zhu, et al . 2025. Hypergraphrag: Retrieval-augmented generation via hypergraph-structured knowledge representation.arXiv preprint arXiv:2503.21322
arXiv 2025
-
[26]
Xin Lv, Yankai Lin, Yixin Cao, Lei Hou, Juanzi Li, Zhiyuan Liu, Peng Li, and Jie Zhou. 2022. Do pre-trained models benefit knowledge graph completion? a reliable evaluation and a reasonable approach. InFindings of the association for computational linguistics: ACL 2022. 3570–3581
2022
-
[27]
Farzaneh Mahdisoltani, Joanna Biega, and Fabian M Suchanek. 2013. YAGO3: A knowledge base from multilingual Wikipedias. InCIDR
2013
-
[28]
Nicholas Matsumoto, Jay Moran, Hyunjun Choi, Miguel E Hernandez, Mythreye Venkatesan, Paul Wang, and Jason H Moore. 2024. KRAGEN: a knowledge graph-enhanced RAG framework for biomedical problem solving using large language models.Bioinformatics40, 6 (2024), btae353
2024
-
[29]
George A Miller. 1995. WordNet: a lexical database for English.Commun. ACM38, 11 (1995), 39–41
1995
-
[30]
Aisha Mohamed, Shameem Parambath, Zoi Kaoudi, and Ashraf Aboulnaga. 2020. Popularity agnostic evaluation of knowledge graph embeddings. InConference on Uncertainty in Artificial Intelligence. PMLR, 1059–1068
2020
-
[31]
Sooho Moon and Yunyong Ko. 2026. How Sharp and Bias-Robust is a Model? Dual Evaluation Perspectives on Knowledge Graph Completion. In Proceedings of the nineteenth ACM international conference on web search and data mining
2026
-
[32]
Maximilian Nickel, Volker Tresp, Hans-Peter Kriegel, et al. 2011. A three-way model for collective learning on multi-relational data.. InIcml, Vol. 11. 3104482–3104584
2011
-
[33]
Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. 2024. Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering36, 7 (2024), 3580–3599
2024
-
[34]
Kunxun Qi, Jianfeng Du, and Hai Wan. 2024. Bi-directional Learning of Logical Rules with Type Constraints for Knowledge Graph Completion. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. 1899–1908
2024
-
[35]
Meng Qu, Junkun Chen, Louis-Pascal Xhonneux, Yoshua Bengio, and Jian Tang. 2021. RNNLogic: Learning Logic Rules for Reasoning on Knowledge Graphs. InInternational Conference on Learning Representations (ICLR). https://openreview.net/forum?id=tGZu6DlbreV
2021
-
[36]
Meng Qu and Jian Tang. 2019. Probabilistic logic neural networks for reasoning. InAdvances in Neural Information Processing Systems, Vol. 32
2019
-
[37]
Tara Safavi and Danai Koutra. 2020. CoDEx: A Comprehensive Knowledge Graph Completion Benchmark. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 24 Moon et al
2020
-
[38]
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. InThe Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, Proceedings 15. Springer, 593–607
2018
-
[39]
Harry Shomer, Wei Jin, Wentao Wang, and Jiliang Tang. 2023. Toward degree bias in embedding-based knowledge graph completion. InProceedings of the ACM web conference 2023. 705–715
2023
-
[40]
Fabian M Suchanek, Gjergji Kasneci, and Gerhard Weikum. 2007. YAGO: a core of semantic knowledge. InProceedings of the 16th International Conference on World Wide Web. 697–706
2007
-
[41]
Kai Sun, Huajie Jiang, Yongli Hu, and Baocai Yin. 2024. Incorporating multi-level sampling with adaptive aggregation for inductive knowledge graph completion.ACM transactions on knowledge discovery from data18, 5 (2024), 1–16
2024
-
[42]
Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. 2019. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=HkgEQnRqYQ
2019
-
[43]
Zhiqing Sun, Shikhar Vashishth, Soumya Sanyal, Partha Talukdar, and Yiming Yang. 2020. A Re-evaluation of Knowledge Graph Completion Methods. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 5516–5522. doi:10.18653/v1/2020.acl-main.489
-
[44]
Sudhanshu Tiwari, Iti Bansal, and Carlos R Rivero. 2021. Revisiting the evaluation protocol of knowledge graph completion methods for link prediction. InProceedings of the Web Conference 2021. 809–820
2021
-
[45]
Kristina Toutanova and Danqi Chen. 2015. Observed versus latent features for knowledge base and text inference. InProceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality. 57–66
2015
-
[46]
Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. 2016. Complex embeddings for simple link prediction. In Proceedings of International Conference on Machine Learning. PMLR, 2071–2080
2016
-
[47]
Shikhar Vashishth, Soumya Sanyal, Vikram Nitin, and Partha Talukdar. 2020. Composition-based Multi-Relational Graph Convolutional Networks. InProceedings of International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=BylA_C4tPr
2020
-
[48]
Daniel Vella and Jean-Paul Ebejer. 2022. Few-shot learning for low-data drug discovery.Journal of Chemical Information and Modeling63, 1 (2022), 27–42
2022
-
[49]
Hongwei Wang, Fuzheng Zhang, Xing Xie, and Minyi Guo. 2018. DKN: Deep knowledge-aware network for news recommendation. InProceedings of the Web Conference (WWW). 1835–1844
2018
-
[50]
Hongwei Wang, Miao Zhao, Xing Xie, Wenjie Li, and Minyi Guo. 2019. Knowledge graph convolutional networks for recommender systems. InThe world wide web conference. 3307–3313
2019
-
[51]
Zihao Wang, Kwunping Lai, Piji Li, Lidong Bing, and Wai Lam. 2019. Tackling Long-Tailed Relations and Uncommon Entities in Knowledge Graph Completion. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computation...
-
[52]
Wenhan Xiong, Mo Yu, Shiyu Chang, Xiaoxiao Guo, and William Yang Wang. 2018. One-Shot Relational Learning for Knowledge Graphs. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Brussels, Belgium, 1980–1990. doi:10.18653/v1/D18-1223
-
[53]
Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2015. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. InProceedings of International Conference on Learning Representations (ICLR), Poster Track. https://arxiv.org/abs/1412.6575
Pith/arXiv arXiv 2015
-
[54]
Fan Yang, Zhilin Yang, and William W Cohen. 2017. Differentiable learning of logical rules for knowledge base reasoning. InAdvances in Neural Information Processing Systems, Vol. 30
2017
-
[55]
Haotong Yang, Zhouchen Lin, and Muhan Zhang. 2022. Rethinking knowledge graph evaluation under the open-world assumption. InAdvances in Neural Information Processing Systems, Vol. 35. 8374–8385
2022
-
[56]
Michihiro Yasunaga, Hongyu Ren, Antoine Bosselut, Percy Liang, and Jure Leskovec. 2021. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 535–546
2021
-
[57]
Qing Ye, Chang-Yu Hsieh, Ziyi Yang, Yu Kang, Jiming Chen, Dongsheng Cao, Shibo He, and Tingjun Hou. 2021. A unified drug–target interaction prediction framework based on knowledge graph and recommendation system.Nature communications12, 1 (2021), 6775
2021
-
[58]
Wen-tau Yih, Xiaodong He, and Christopher Meek. 2014. Semantic parsing for single-relation question answering. InProceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 643–648
2014
-
[59]
Xiangxiang Zeng, Xinqi Tu, Yuansheng Liu, Xiangzheng Fu, and Yansen Su. 2022. Toward better drug discovery with knowledge graph.Current Opinion in Structural Biology72 (2022), 114–126
2022
-
[60]
Rui Zhang, Dimitar Hristovski, Dalton Schutte, Andrej Kastrin, Marcelo Fiszman, and Halil Kilicoglu. 2021. Drug repurposing for COVID-19 via knowledge graph completion.Journal of Biomedical Informatics115 (2021), 103696
2021
-
[61]
Wenqian Zhang, Shangbin Feng, Zilong Chen, Zhenyu Lei, Jundong Li, and Minnan Luo. 2022. KCD: Knowledge Walks and Textual Cues Enhanced Political Perspective Detection in News Media. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 4129–4140
2022
-
[62]
Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander Smola, and Le Song. 2018. Variational reasoning for question answering with knowledge graph. InProceedings of the AAAI conference on artificial intelligence, Vol. 32. Generalized Rank-based Evaluation for Knowledge Graph Completion: Perspectives, Framework, and Analyses 25
2018
-
[63]
Yongqi Zhang and Quanming Yao. 2022. Knowledge graph reasoning with relational digraph. InProceedings of the ACM web conference 2022. 912–924
2022
-
[64]
Sijin Zhou, Xinyi Dai, Haokun Chen, Weinan Zhang, Kan Ren, Ruiming Tang, Xiuqiang He, and Yong Yu. 2020. Interactive recommender system via knowledge graph-enhanced reinforcement learning. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 179–188
2020
-
[65]
Chaoyu Zhu, Xiaoqiong Xia, Nan Li, Fan Zhong, Zhihao Yang, and Lei Liu. 2023. RDKG-115: Assisting drug repurposing and discovery for rare diseases by trimodal knowledge graph embedding.Computers in Biology and Medicine164 (2023), 107262
2023
-
[66]
Zhaocheng Zhu, Zuobai Zhang, Louis-Pascal Xhonneux, and Jian Tang. 2021. Neural Bellman-Ford networks: A general graph neural network framework for link prediction. InAdvances in Neural Information Processing Systems, Vol. 34. 29476–29490
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.