Heterophily-Aware Adaptive Knowledge Distillation for Hypergraph Neural Networks
Pith reviewed 2026-06-27 17:39 UTC · model grok-4.3
The pith
HADES quantifies node heterophily to adaptively weight teacher knowledge in hypergraph distillation, often producing students that exceed teacher accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
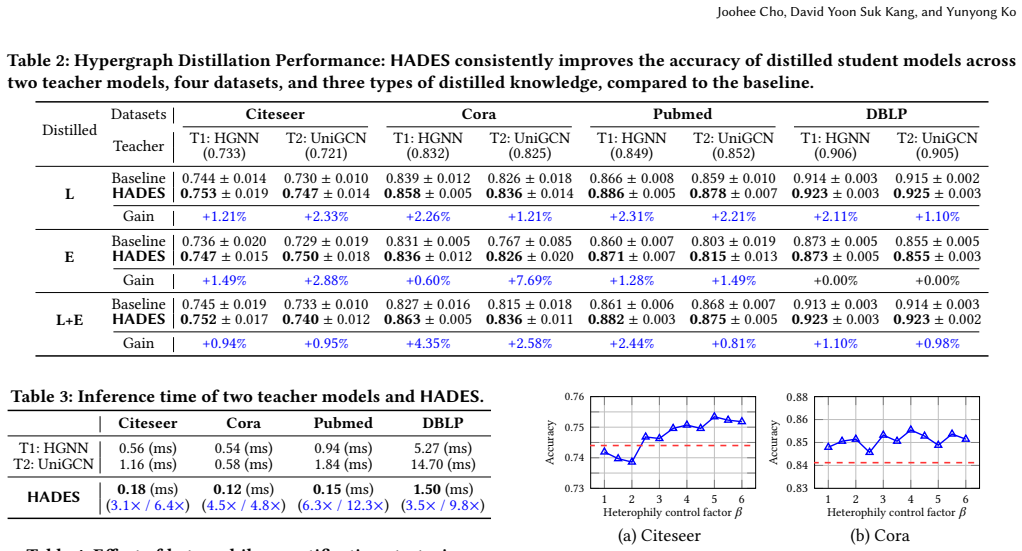
HADES quantifies node heterophily and leverages it as an estimate of teacher reliability to modulate the transfer of teacher knowledge during distillation. Experimental results on real-world hypergraphs demonstrate that HADES consistently improves student performance across different HNN teachers and distillation objectives. In many cases, the resulting student models surpass the predictive performance of their teachers while achieving up to 12.3 times faster inference.
What carries the argument
Node-level heterophily score used as a reliability weight to modulate the teacher-student loss term during distillation.
If this is right
- Student models improve over standard distillation for any tested HNN teacher.
- Students exceed teacher accuracy on multiple real-world hypergraphs.
- Inference speed reaches 12.3 times that of the teacher.
- Gains appear under varied distillation objectives.
Where Pith is reading between the lines
- The same heterophily-to-reliability mapping could be tested on ordinary graph neural networks where edge diversity also varies.
- The approach might extend to other tasks that already compute local diversity measures, such as community detection.
- Scaling experiments on hypergraphs with millions of nodes would show whether the per-node heterophily calculation remains practical.
Load-bearing premise
Lower performance on heterophilic nodes directly marks lower teacher reliability that can be read from heterophily alone.
What would settle it
A dataset where teacher accuracy on high-heterophily nodes is equal to or higher than on low-heterophily nodes would show the reliability estimate is not supported by the heterophily signal.
Figures
read the original abstract
Hypergraph knowledge distillation aims to retain the predictive performance of a hypergraph neural network (HNN) teacher while reducing inference costs through a lightweight student model. In this work, we observe that HNNs exhibit substantially lower prediction performance on heterophilic nodes connected through semantically diverse hyperedges, indicating that the reliability of teacher knowledge varies across nodes. Motivated by this observation, we propose HADES, a heterophily-aware adaptive distillation method for hypergraph neural networks. HADES quantifies node heterophily and leverages it as an estimate of teacher reliability to modulate the transfer of teacher knowledge during distillation. Experimental results on real-world hypergraphs demonstrate that HADES consistently improves student performance across different HNN teachers and distillation objectives. In many cases, the resulting student models surpass the predictive performance of their teachers while achieving up to 12.3 times faster inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HADES, a heterophily-aware adaptive knowledge distillation method for hypergraph neural networks. It observes that HNN teachers show lower accuracy on nodes with high heterophily (measured via hyperedge diversity) and uses this scalar to modulate per-node teacher knowledge transfer during distillation. The central claim is that this yields student models with improved performance over standard distillation—often surpassing the teacher—while achieving up to 12.3× faster inference on real-world hypergraphs.
Significance. If the heterophily-reliability link and resulting gains hold under rigorous validation, the work would offer a practical way to improve distillation efficiency for HNNs on heterophilic data, where uniform teacher trust is suboptimal. The occasional student > teacher outcome is noteworthy if reproducible, but the absence of parameter-free derivations or machine-checked elements limits its foundational impact.
major comments (3)
- [Abstract] Abstract and introduction: the core mechanism treats the heterophily scalar (derived from hyperedge diversity) as a direct proxy for per-node teacher reliability without any reported correlation analysis, scatter plot, or ablation that quantifies how strongly this scalar predicts actual teacher errors; this assumption is load-bearing for the adaptation claim.
- [Experimental results] Experimental results section: reported gains (including student outperforming teacher) are presented without error bars, multiple random seeds, or statistical significance tests, making it impossible to assess whether the heterophily modulation is the causal driver versus other regularizers or hyperparameter choices.
- [Method] Method description: no explicit formula or pseudocode is referenced for how the heterophily value scales the distillation loss or soft-label weight; without this, the precise adaptation rule cannot be reproduced or stress-tested against the skeptic concern that gains may arise independently of the heterophily term.
minor comments (1)
- [Abstract] The abstract mentions 'up to 12.3 times faster inference' but does not clarify whether this is measured on the same hardware or accounts for preprocessing overhead of the heterophily computation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity, reproducibility, and empirical validation. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the core mechanism treats the heterophily scalar (derived from hyperedge diversity) as a direct proxy for per-node teacher reliability without any reported correlation analysis, scatter plot, or ablation that quantifies how strongly this scalar predicts actual teacher errors; this assumption is load-bearing for the adaptation claim.
Authors: The manuscript motivates the approach from the empirical observation that HNN teachers exhibit lower accuracy on nodes with high heterophily (measured by hyperedge diversity). We agree that an explicit quantification of the correlation between this scalar and teacher errors would strengthen the load-bearing assumption. In the revised version, we will add a dedicated analysis subsection with scatter plots of heterophily versus teacher error rates across datasets, Pearson correlation coefficients, and an ablation study isolating the effect of the heterophily-based weighting. revision: yes
-
Referee: [Experimental results] Experimental results section: reported gains (including student outperforming teacher) are presented without error bars, multiple random seeds, or statistical significance tests, making it impossible to assess whether the heterophily modulation is the causal driver versus other regularizers or hyperparameter choices.
Authors: We acknowledge that the current experimental presentation lacks these elements, which are necessary to establish the reliability of the reported gains. The revised experimental results section will include averages and standard deviations over five random seeds, error bars in all plots, and paired t-tests for statistical significance between HADES and baseline distillation methods to better isolate the contribution of the heterophily modulation. revision: yes
-
Referee: [Method] Method description: no explicit formula or pseudocode is referenced for how the heterophily value scales the distillation loss or soft-label weight; without this, the precise adaptation rule cannot be reproduced or stress-tested against the skeptic concern that gains may arise independently of the heterophily term.
Authors: Section 3.2 of the manuscript presents the adaptive weighting formula that scales the distillation loss term by the per-node heterophily value. To improve reproducibility and directly address concerns about the heterophily term's role, we will add explicit pseudocode (as Algorithm 1) for the full distillation procedure and will reference the scaling formula more prominently in the text with a dedicated equation number. revision: partial
Circularity Check
No circularity: heterophily derived from graph structure, not from distillation objective or self-fit
full rationale
The paper defines node heterophily via hyperedge diversity on the input hypergraph structure and uses the resulting scalar to modulate per-node distillation weights. This is presented as an empirical observation (lower teacher accuracy on heterophilic nodes) turned into a weighting heuristic, not as a quantity fitted to the KD loss or defined in terms of teacher reliability. No equations reduce the heterophily measure to the distillation target by construction, no self-citation chain carries the central claim, and the method remains an external input derived from data topology rather than from the optimization itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Song Bai, Feihu Zhang, and Philip H.S. Torr. 2021. Hypergraph convolution and hypergraph attention.Pattern Recognition110 (2021), 107637. doi:10.1016/j. patcog.2020.107637
work page doi:10.1016/j 2021
-
[2]
Eli Chien, Chao Pan, Jianhao Peng, and Olgica Milenkovic. 2021. You are allset: A multiset function framework for hypergraph neural networks.arXiv preprint arXiv:2106.13264(2021)
arXiv 2021
-
[4]
Yihe Dong, Will Sawin, and Yoshua Bengio. 2020. HNHN: Hypergraph Networks with Hyperedge Neurons.ICML Graph Representation Learning and Beyond Workshop(2020). https://arxiv.org/abs/2006.12278
arXiv 2020
-
[5]
Ko et al. 2025. Enhancing hyperedge prediction with context-aware self- supervised learning.IEEE Transactions on Knowledge and Data Engineering (TKDE)(2025)
2025
-
[6]
Yifan Feng, Yihe Luo, Shihui Ying, and Yue Gao. 2024. LightHGNN: Distill- ing hypergraph neural networks into MLPs for 100x faster inference. InThe International Conference on Learning Representations
2024
-
[7]
Yifan Feng, Haoxuan You, Zizhao Zhang, Rongrong Ji, and Yue Gao. 2019. Hy- pergraph neural networks. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 3558–3565
2019
-
[8]
Saman Forouzandeh, Parham Moradi Dowlatabadi, and Mahdi Jalili. 2025. Dis- tillhgnn: A knowledge distillation approach for high-speed hypergraph neural networks. InInternational Conference on Learning Representations, Vol. 2025. 36743–36764
2025
-
[9]
Shengbo Gong, Jiajun Zhou, Chenxuan Xie, and Qi Xuan. 2023. Neighborhood Homophily-based Graph Convolutional Network. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management(Birming- ham, United Kingdom)(CIKM ’23). Association for Computing Machinery, New York, NY, USA, 3908–3912. doi:10.1145/3583780.3615195
-
[10]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
Pith/arXiv arXiv 2015
-
[11]
Jing Huang and Jie Yang. 2021. Unignn: a unified framework for graph and hypergraph neural networks.arXiv preprint arXiv:2105.00956(2021)
arXiv 2021
-
[12]
Yunyong Ko, Da Eun Lee, Song Kyung Yu, and Sang-Wook Kim. 2025. Learning Short-Term and Long-Term Patterns of High-Order Dynamics in Real-World Networks. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 4900–4904
2025
-
[13]
Xuan Liu, Song Congzhi, Shichao Liu, Xionghui Zhou, and Wen Zhang. 2022. Multi-way relation-enhanced hypergraph representation learning for anti-cancer drug synergy prediction.Bioinformatics38 (08 2022). doi:10.1093/bioinformatics/ btac579
-
[14]
Yi Liu, Hongrui Xuan, Bohan Li, Meng Wang, Tong Chen, and Hongzhi Yin
-
[15]
Self-Supervised Dynamic Hypergraph Recommendation based on Hyper- Relational Knowledge Graph. InProceedings of the 32nd ACM International Con- ference on Information and Knowledge Management(Birmingham, United King- dom)(CIKM ’23). Association for Computing Machinery, New York, NY, USA, 1617–1626. doi:10.1145/3583780.3615054
-
[16]
Zhiyao Shu, Xiangguo Sun, and Hong Cheng. 2024. When LLM Meets Hy- pergraph: A Sociological Analysis on Personality via Online Social Networks. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Computing Machinery, New York, NY, USA, 2087–2096. doi:10.1145/3627673.3679646
-
[17]
Fali Wang, Tianxiang Zhao, Junjie Xu, and Suhang Wang. 2024. HC-GST: Heterophily-aware Distribution Consistency based Graph Self-training. InPro- ceedings of the 33rd ACM International Conference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Computing Machinery, New York, NY, USA, 2326–2335. doi:10.1145/3627673.3679622
-
[18]
Junjie Xu, Enyan Dai, Dongsheng Luo, Xiang Zhang, and Suhang Wang. 2024. Shape-aware Graph Spectral Learning. InProceedings of the 33rd ACM Inter- national Conference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Computing Machinery, New York, NY, USA, 2692–2701. doi:10.1145/3627673.3679604
-
[19]
Rongwei Xu, Zitai Qiu, Pengfei Ding, Yan Wang, Jia Wu, Amin Beheshti, and Guanfeng Liu. 2026. Adaptive and Reinforcement-Guided Contrastive Hyper- graph Distillation. InProceedings of the Nineteenth ACM International Conference on Web Search and Data Mining. 778–787
2026
-
[20]
Bencheng Yan, Chaokun Wang, Gaoyang Guo, and Yunkai Lou. 2020. Tinygnn: Learning efficient graph neural networks. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 1848–1856
2020
-
[21]
Song Kyung Yu, Da Eun Lee, Yunyong Ko, and Sang-Wook Kim. 2025. Hygen: Regularizing negative hyperedge generation for accurate hyperedge prediction. InCompanion Proceedings of the ACM on Web Conference 2025. 1500–1504
2025
-
[22]
Wenqing Zheng, Edward W Huang, Nikhil Rao, Sumeet Katariya, Zhangyang Wang, and Karthik Subbian. 2022. Cold Brew: Distilling Graph Node Representa- tions with Incomplete or Missing Neighborhoods. InInternational Conference on Learning Representations. https://openreview.net/forum?id=1ugNpm7W6E
2022
-
[23]
Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. 2020. Beyond homophily in graph neural networks: current limitations and effective designs. InProceedings of the 34th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’20). Curran Associates Inc., Red Hook, NY, USA, Article 653, 12 pages
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.