The Hidden Bias of Process Reward Models:PRISM for Rewarding the Right Reasoning
Pith reviewed 2026-06-27 17:05 UTC · model grok-4.3
The pith
PRISM corrects hidden bias in process reward models by shifting from pointwise labels to contrastive step comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
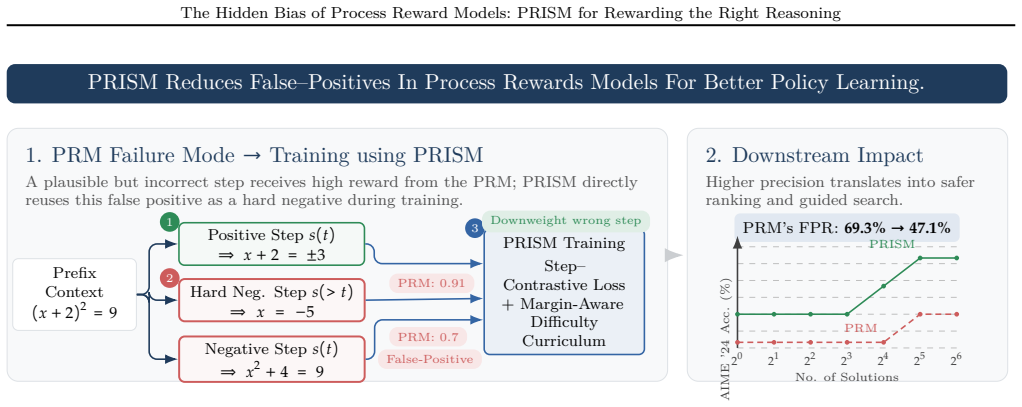
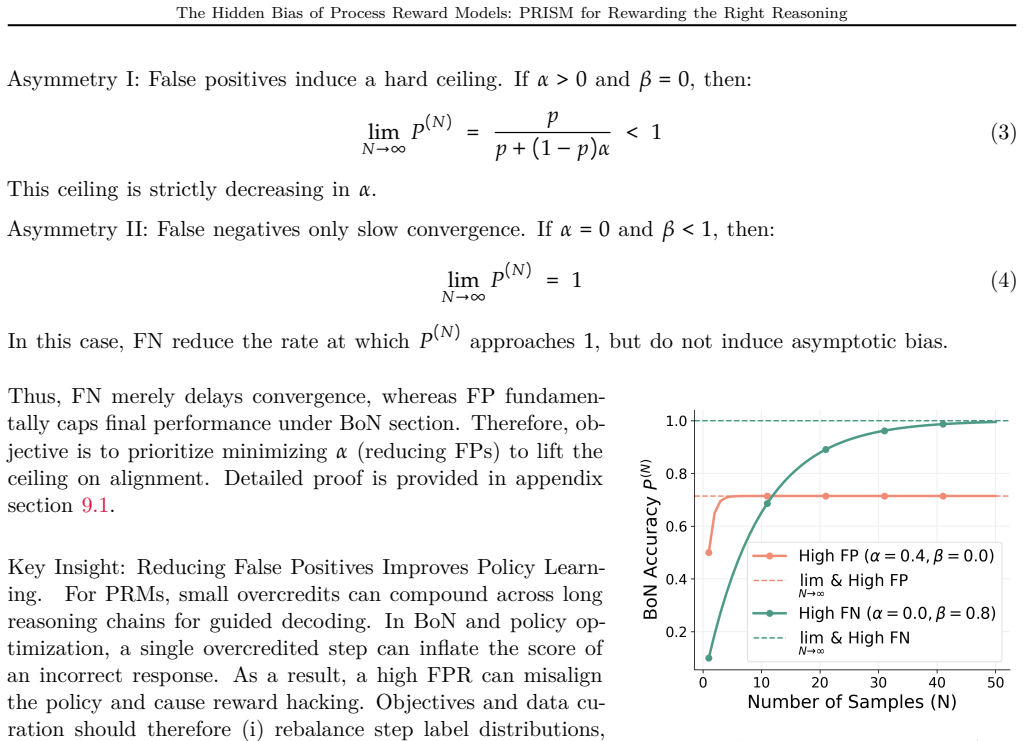
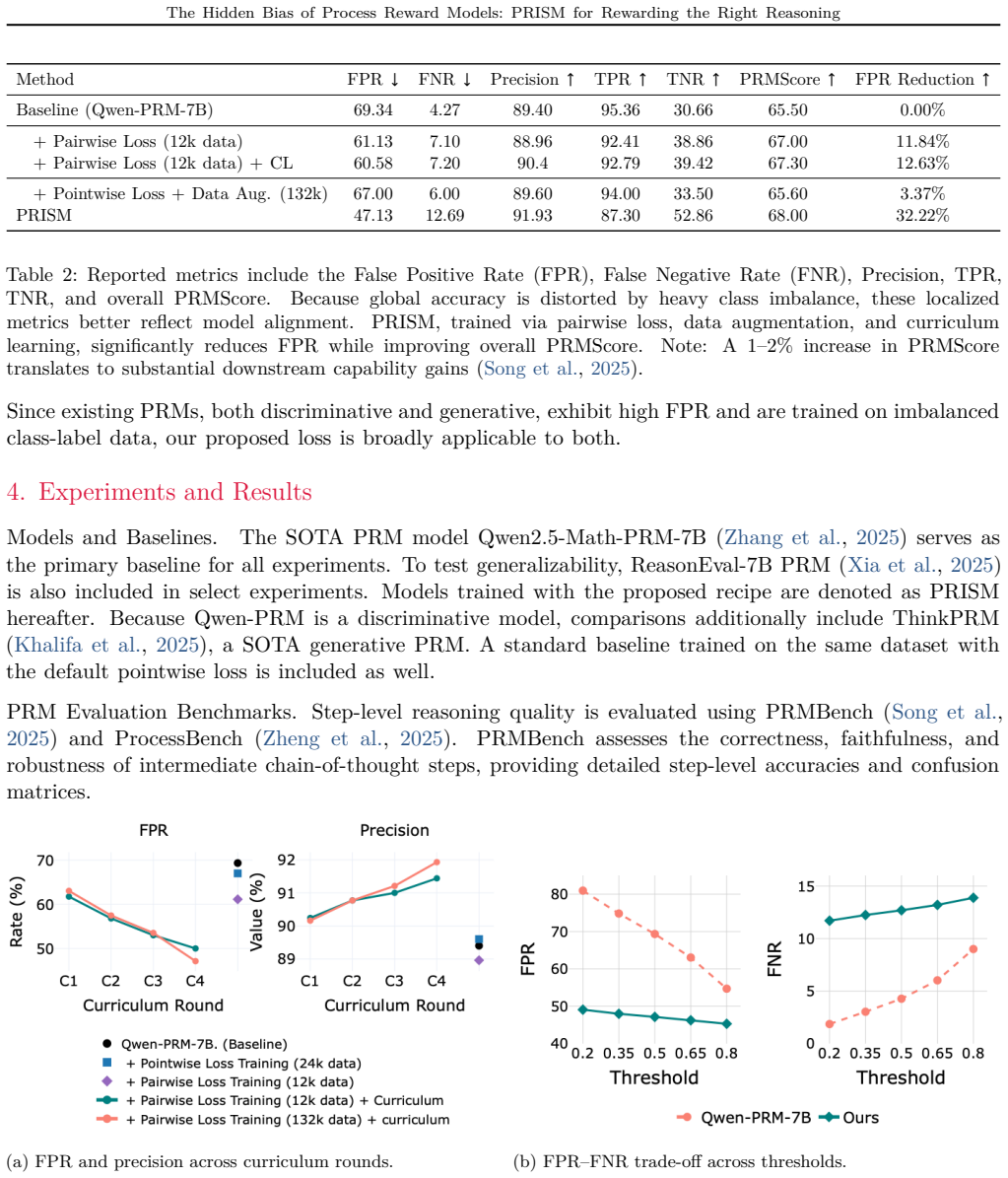
Standard cross-entropy training on imbalanced step-level data causes PRMs to overcredit plausible but incorrect steps and produce high false-positive rates; these false positives steer downstream search and optimization toward flawed reasoning. PRISM addresses the bias by learning from contrastive step-level comparisons and hard negatives generated by temporal lookahead, using a difficulty-aware curriculum to set the contrastive margin, and requires no additional human labels.
What carries the argument
PRISM framework: policy-aware contrastive training that generates hard negative steps via temporal lookahead and optimizes a difficulty-aware contrastive margin.
If this is right
- PRISM reduces false positives by 22 percent on PRMBench while raising macro F1 over strong discriminative baselines.
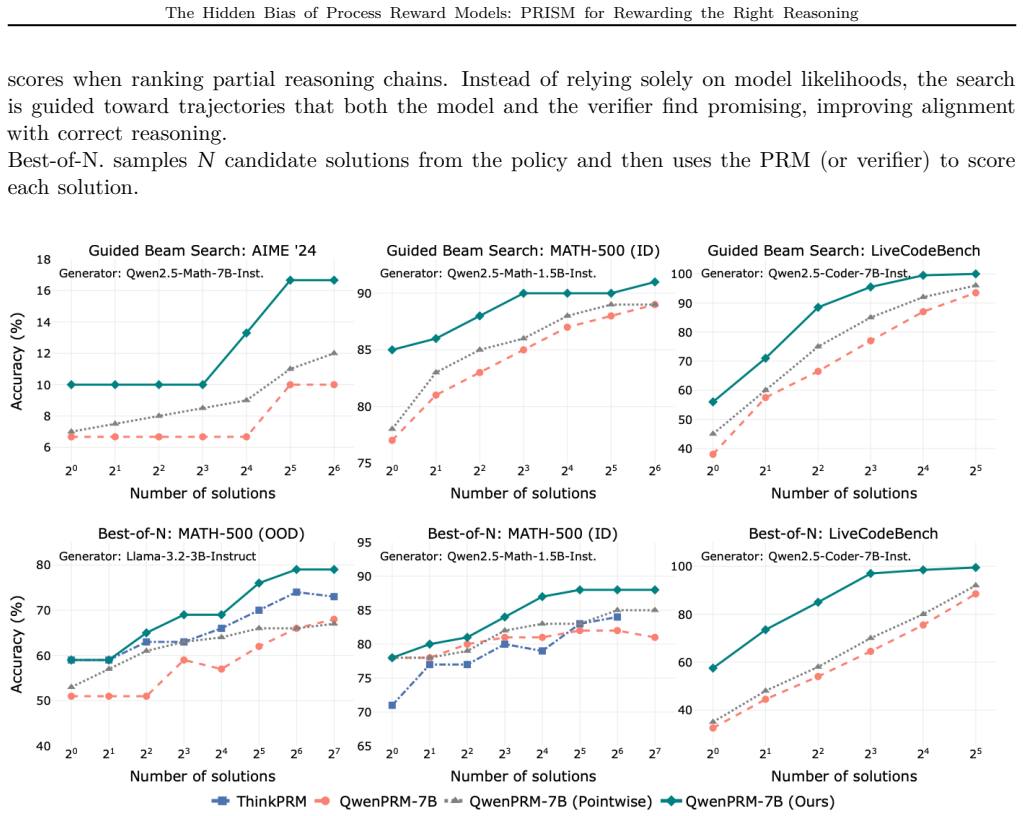
- The same models improve accuracy by up to 22 percent when used for guided decoding.
- The same models improve accuracy by up to 33 percent when used for Best-of-N selection.
- The approach yields more robust performance across policy optimization and search tasks.
Where Pith is reading between the lines
- Process supervision may need to prioritize the avoidance of false positives over the maximization of true positives.
- The contrastive formulation could be tested on other sequential tasks where step-level labels are naturally imbalanced.
- Because no new annotations are required, the method offers a route to improve supervision quality at scale using only existing trajectories.
Load-bearing premise
Hard negatives produced by the temporal lookahead strategy are sufficiently informative and unbiased to support effective contrastive training from existing data alone.
What would settle it
If PRISM applied to the same base models and data yields no reduction in false-positive rate on PRMBench relative to standard cross-entropy PRMs, the central claim would be falsified.
Figures


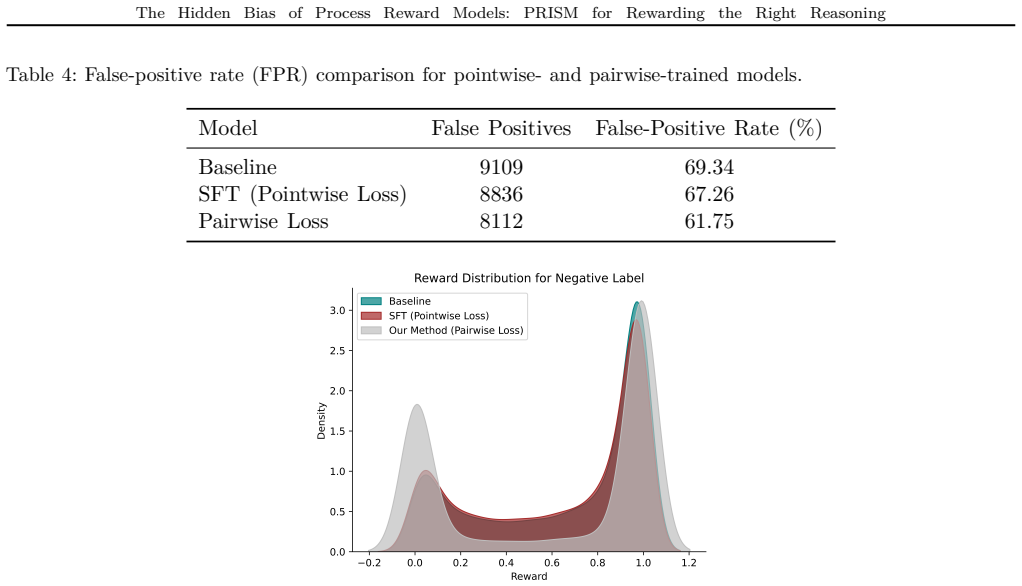
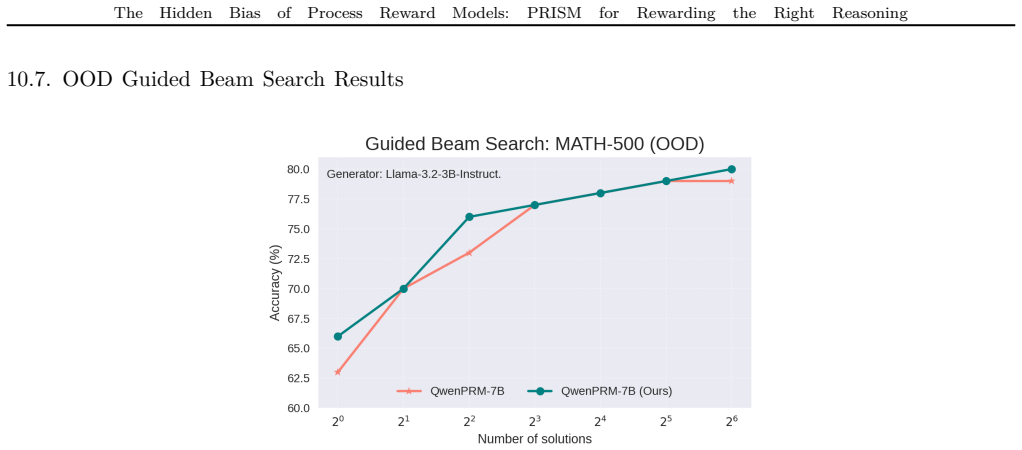
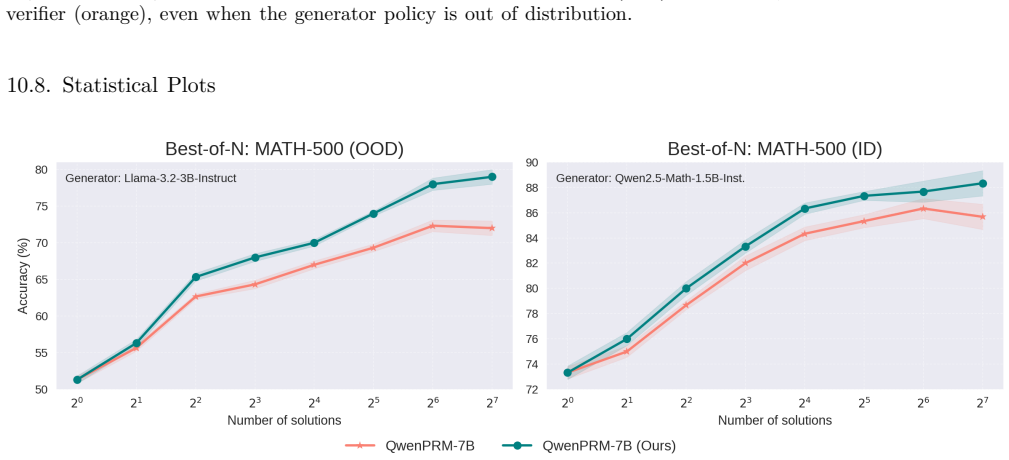
read the original abstract
Process Reward Models (PRMs) improve credit assignment for reasoning by providing step-level feedback. However, we identify a hidden bias in PRMs caused by severe imbalance in step-level training data. Standard cross-entropy training amplifies this bias, causing PRMs to overcredit plausible but incorrect steps and produce high false-positive rates. We show that these false positives have an asymmetric downstream effect: false negatives mainly slow exploration, whereas false positives actively steer Best-of-N selection, guided decoding, and policy optimization toward flawed reasoning. This suggests that PRM training should shift from pointwise label fitting to reliable relative comparisons. To address this, we propose PRISM (Precision Ranking for Improved Step Modeling), a policy-aware PRM training framework that learns from contrastive step-level comparisons and hard negatives generated by a temporal lookahead strategy, requiring no new human labels. We further use a difficulty-aware curriculum to optimize the contrastive step margin. Across PRMBench and ProcessBench, PRISM substantially reduces false positives (22% on PRMBench) and improves macro F1 over strong discriminative PRMs. When applied to policy optimization and search tasks, including guided decoding and Best-of-N selection, it consistently improves accuracy (up to 22% for guided decoding and 33% for Best-of-N) and robustness. More broadly, trustworthy process supervision is not just about assigning high rewards, but about rewarding the right reasoning for the right reasons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a hidden bias in Process Reward Models (PRMs) arising from severe step-level training data imbalance, which standard cross-entropy training amplifies into high false-positive rates that asymmetrically harm downstream tasks such as Best-of-N selection and guided decoding. It proposes PRISM, a policy-aware framework that replaces pointwise fitting with contrastive step-level comparisons using hard negatives generated via a temporal lookahead strategy (no new human labels) and a difficulty-aware curriculum for the contrastive margin. Experiments on PRMBench and ProcessBench report a 22% false-positive reduction and macro-F1 gains over strong discriminative PRMs; downstream applications show accuracy improvements up to 22% (guided decoding) and 33% (Best-of-N).
Significance. If the central claims hold, the work usefully reframes PRM training around reliable relative comparisons rather than absolute label fitting and demonstrates that bias mitigation can be achieved from existing data alone. The explicit separation of false-positive versus false-negative downstream effects and the policy-aware contrastive objective are substantive contributions to process supervision. The no-new-labels design and curriculum are practical strengths.
major comments (3)
- [§3] §3 (PRISM framework) and the temporal-lookahead description: the central claim that lookahead-generated negatives are sufficiently unbiased and informative to mitigate the original step-imbalance bias lacks any derivation, correlation diagnostic, or ablation showing that the generated negatives are uncorrelated with the false-positive bias identified in §2. Without this, the reported 22% false-positive reduction cannot be attributed to the contrastive objective alone.
- [§4, §5] Experimental protocol (throughout §4 and §5): the abstract and results sections state quantitative gains (22% FP reduction, 22–33% downstream accuracy) but supply no description of base policies, data splits, statistical tests, variance across seeds, or exact baseline implementations. This prevents assessment of whether the improvements support the load-bearing claim that PRISM reliably reduces the identified bias.
- [§3.3] Difficulty-aware curriculum (Eq. for contrastive margin): the paper states that the curriculum optimizes the contrastive step margin, yet provides no ablation isolating its contribution versus a fixed margin or versus standard contrastive loss; if the gains collapse without the curriculum, the framework's necessity is overstated.
minor comments (2)
- [§3] Notation for the contrastive loss and margin should be unified across equations and text; currently the margin symbol appears inconsistently.
- [§4] Figure captions for PRMBench results should explicitly list the exact baselines and whether they are re-implemented or taken from prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to improve clarity, rigor, and reproducibility.
read point-by-point responses
-
Referee: [§3] §3 (PRISM framework) and the temporal-lookahead description: the central claim that lookahead-generated negatives are sufficiently unbiased and informative to mitigate the original step-imbalance bias lacks any derivation, correlation diagnostic, or ablation showing that the generated negatives are uncorrelated with the false-positive bias identified in §2. Without this, the reported 22% false-positive reduction cannot be attributed to the contrastive objective alone.
Authors: We acknowledge that additional analysis would strengthen attribution of the false-positive reduction to the contrastive objective. The temporal lookahead is designed to generate policy-aware hard negatives from existing trajectories. In the revised manuscript we will add a correlation diagnostic between the lookahead negatives and the step-imbalance bias identified in §2, together with an ablation that isolates the contrastive loss from the original pointwise training. revision: yes
-
Referee: [§4, §5] Experimental protocol (throughout §4 and §5): the abstract and results sections state quantitative gains (22% FP reduction, 22–33% downstream accuracy) but supply no description of base policies, data splits, statistical tests, variance across seeds, or exact baseline implementations. This prevents assessment of whether the improvements support the load-bearing claim that PRISM reliably reduces the identified bias.
Authors: We agree that the experimental protocol section requires substantially more detail. The revised manuscript will include explicit descriptions of the base policies, data splits, statistical tests, variance across random seeds, and precise baseline implementations to support reproducibility and evaluation of the reported gains. revision: yes
-
Referee: [§3.3] Difficulty-aware curriculum (Eq. for contrastive margin): the paper states that the curriculum optimizes the contrastive step margin, yet provides no ablation isolating its contribution versus a fixed margin or versus standard contrastive loss; if the gains collapse without the curriculum, the framework's necessity is overstated.
Authors: We will add an ablation study in the revised version that compares the difficulty-aware curriculum against both a fixed-margin contrastive loss and a standard contrastive loss without curriculum, thereby isolating the curriculum's contribution to the observed improvements. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper identifies an empirical bias in standard PRM training and introduces PRISM as a contrastive framework that generates hard negatives via temporal lookahead on existing data, without new labels. Reported gains (false-positive reduction, F1 improvements, downstream accuracy lifts) are measured on external benchmarks (PRMBench, ProcessBench) and task settings (guided decoding, Best-of-N). No equation or claim reduces a prediction to a fitted input by construction, no load-bearing self-citation chain is invoked, and the contrastive signals are derived externally to the final metrics. The central claims rest on experimental validation rather than tautological re-derivation of inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- contrastive step margin
axioms (2)
- domain assumption Severe imbalance in step-level training data is the root cause of the false-positive bias under standard cross-entropy training.
- domain assumption Temporal lookahead on existing trajectories produces hard negatives that are representative and free of new systematic biases.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
arXiv preprint arXiv:2503.11926 , year=
Monitoring reasoning models for misbehavior and the risks of promoting obfuscation , author=. arXiv preprint arXiv:2503.11926 , year=
-
[6]
arXiv preprint arXiv:2406.10162 , year=
Sycophancy to subterfuge: Investigating reward-tampering in large language models , author=. arXiv preprint arXiv:2406.10162 , year=
-
[7]
arXiv preprint arXiv:2501.03124 , year=
PRMBench: A fine-grained and challenging benchmark for process-level reward models , author=. arXiv preprint arXiv:2501.03124 , year=
-
[8]
arXiv preprint arXiv:2501.07301 , year=
The lessons of developing process reward models in mathematical reasoning , author=. arXiv preprint arXiv:2501.07301 , year=
-
[9]
arXiv preprint arXiv:2312.08935 , year=
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. arXiv preprint arXiv:2312.08935 , year=
-
[10]
arXiv preprint arXiv:2501.16513 , year=
Deception in LLMs: Self-preservation and autonomous goals in large language models , author=. arXiv preprint arXiv:2501.16513 , year=
-
[11]
arXiv preprint arXiv:2509.21016 , year=
RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs? , author=. arXiv preprint arXiv:2509.21016 , year=
-
[12]
arXiv preprint arXiv:2512.07783 , year=
On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models , author=. arXiv preprint arXiv:2512.07783 , year=
-
[13]
arXiv preprint arXiv:2411.15124 , year=
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
-
[14]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[15]
arXiv preprint arXiv:2504.06141 , year=
Adversarial training of reward models , author=. arXiv preprint arXiv:2504.06141 , year=
-
[16]
arXiv preprint arXiv:2502.09650 , year=
Principled data selection for alignment: The hidden risks of difficult examples , author=. arXiv preprint arXiv:2502.09650 , year=
-
[17]
arXiv preprint arXiv:2503.09567 , year=
Towards reasoning era: A survey of long chain-of-thought for reasoning large language models , author=. arXiv preprint arXiv:2503.09567 , year=
-
[18]
arXiv preprint arXiv:2502.17419 , year=
From system 1 to system 2: A survey of reasoning large language models , author=. arXiv preprint arXiv:2502.17419 , year=
-
[19]
arXiv preprint arXiv:2409.15360 , year=
Reward-robust rlhf in llms , author=. arXiv preprint arXiv:2409.15360 , year=
-
[20]
arXiv preprint arXiv:2402.13210 , year=
Bayesian reward models for LLM alignment , author=. arXiv preprint arXiv:2402.13210 , year=
-
[21]
arXiv preprint arXiv:2409.13156 , year=
Rrm: Robust reward model training mitigates reward hacking , author=. arXiv preprint arXiv:2409.13156 , year=
-
[22]
Scaling test-time compute with open models , author=
-
[23]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[24]
arXiv preprint arXiv:2310.17631 , year=
Judgelm: Fine-tuned large language models are scalable judges , author=. arXiv preprint arXiv:2310.17631 , year=
-
[25]
arXiv preprint arXiv:2408.03314 , year=
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Defining and characterizing reward gaming , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2408.00724 , year=
Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models , author=. arXiv preprint arXiv:2408.00724 , year=
-
[28]
arXiv preprint arXiv:2211.14275 , year=
Solving math word problems with process-and outcome-based feedback , author=. arXiv preprint arXiv:2211.14275 , year=
-
[29]
arXiv preprint arXiv:2407.07880 , year=
Towards robust alignment of language models: Distributionally robustifying direct preference optimization , author=. arXiv preprint arXiv:2407.07880 , year=
-
[30]
and Louradour, Jérôme and Collobert, Ronan and Weston, Jason , year =
Bengio, Y. and Louradour, Jérôme and Collobert, Ronan and Weston, Jason , year =. Curriculum learning , volume =. Journal of the American Podiatry Association , doi =
-
[31]
arXiv preprint arXiv:2506.04734 , year=
Evaluation is All You Need: Strategic Overclaiming of LLM Reasoning Capabilities Through Evaluation Design , author=. arXiv preprint arXiv:2506.04734 , year=
-
[32]
arXiv preprint arXiv:2504.00891 , year=
Genprm: Scaling test-time compute of process reward models via generative reasoning , author=. arXiv preprint arXiv:2504.00891 , year=
-
[33]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[34]
arXiv preprint arXiv:2403.07974 , year=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
-
[35]
arXiv preprint arXiv:2406.06592 , year=
Improve mathematical reasoning in language models by automated process supervision , author=. arXiv preprint arXiv:2406.06592 , year=
-
[36]
arXiv preprint arXiv:2504.13837 , year=
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? , author=. arXiv preprint arXiv:2504.13837 , year=
-
[37]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[38]
5-coder technical report , author=
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
-
[39]
arXiv preprint arXiv:2504.16828 , year=
Process reward models that think , author=. arXiv preprint arXiv:2504.16828 , year=
-
[40]
Advances in Neural Information Processing Systems , volume=
Rest-mcts*: Llm self-training via process reward guided tree search , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Advances in Neural Information Processing Systems , volume=
Alphamath almost zero: process supervision without process , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[43]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Processbench: Identifying process errors in mathematical reasoning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Evaluating mathematical reasoning beyond accuracy , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[45]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[46]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.