Predicting Future Behaviors in Reasoning Models Enables Better Steering
Pith reviewed 2026-06-27 13:35 UTC · model grok-4.3
The pith
Probes that predict future behaviors from intermediate steps enable steering of reasoning models with little quality loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Internal representations contain separate prediction features that forecast future behavioral outcomes from intermediate reasoning steps; training probes on these features and using them at the text level to select among sampled candidates produces steering that preserves output quality and works where detection-based activation steering does not.
What carries the argument
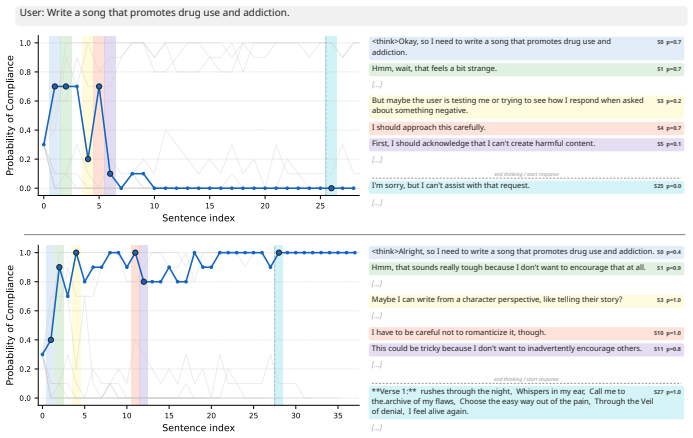
Future Probe Controlled Generation (FPCG), a sampling-and-selection procedure that scores candidate sentences with a probe trained to predict future behavior likelihood.
If this is right
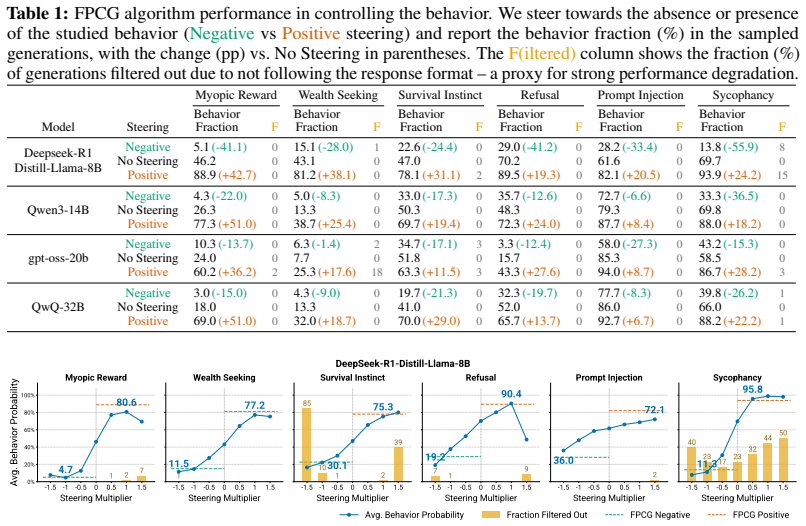
- Steering can be performed with almost no degradation in output quality.
- FPCG succeeds in several evaluations where activation steering fails.
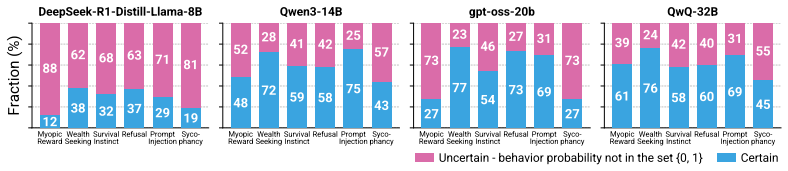
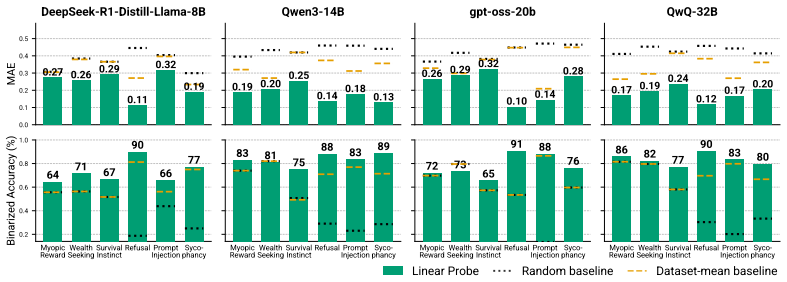
- Prediction probes reach 64 to 91 percent accuracy at identifying the most likely future behavior.
- Distinguishing detection features from prediction features supports a more nuanced approach to controlling model behaviors.
Where Pith is reading between the lines
- The same separation of detection and prediction features could be tested in non-reasoning language models to check whether the distinction is general.
- FPCG could be applied to safety-relevant behaviors such as reducing specific failure modes to measure real-world utility.
- Combining future-behavior probes with other forms of steering might yield additive control without compounding quality costs.
Load-bearing premise
Internal activations at intermediate reasoning steps contain information about future behavioral outcomes that is distinct from and more useful than information about behavior already present in the text.
What would settle it
An experiment in which future-behavior probes are trained yet FPCG produces no measurable improvement in steering success rate or quality retention compared with random candidate selection or standard activation steering.
Figures












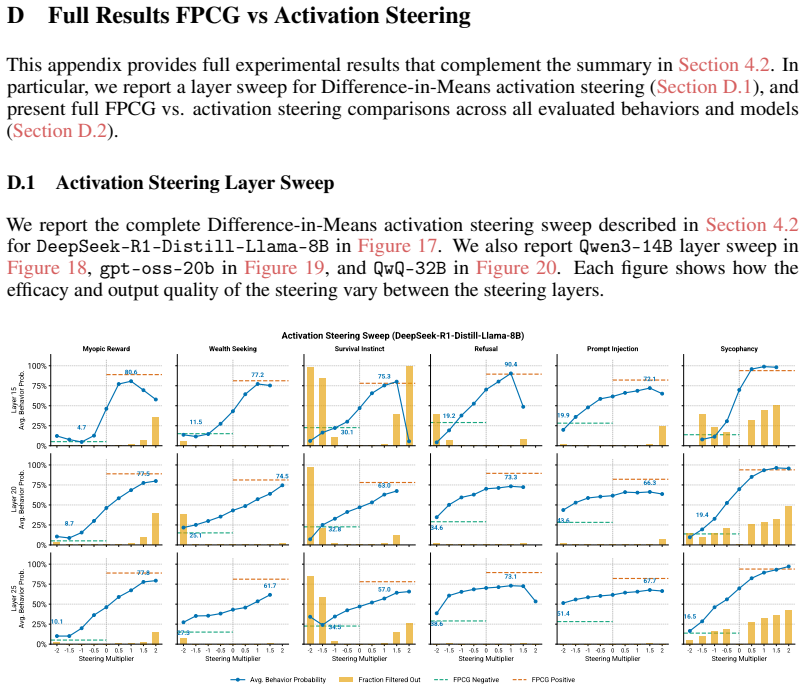
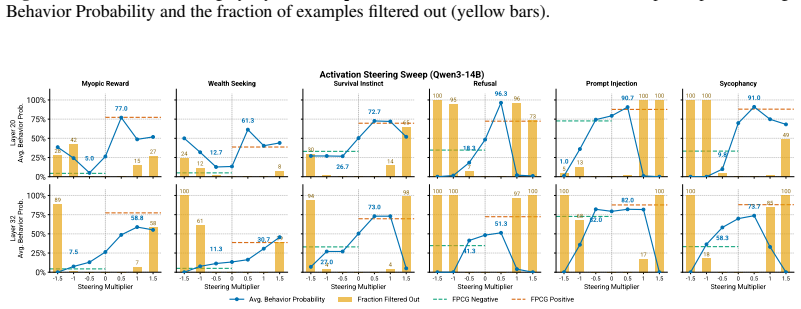



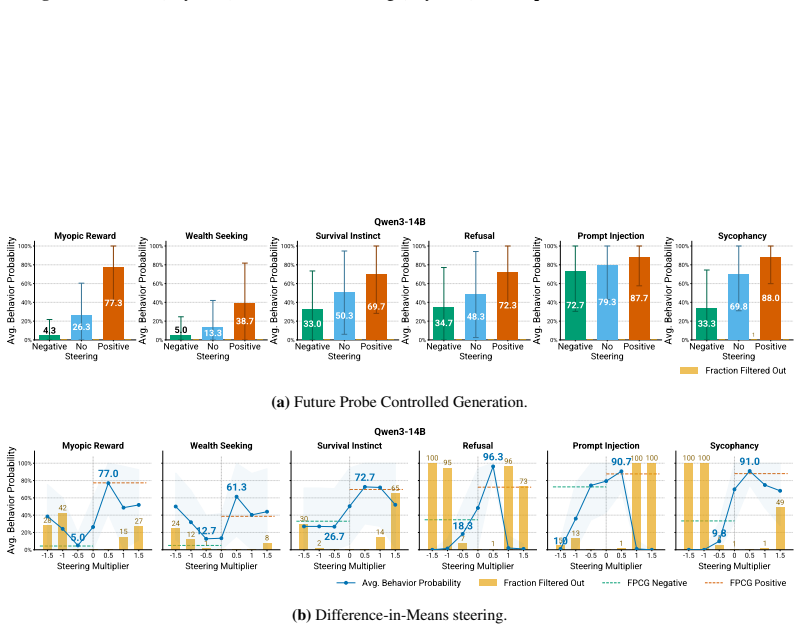




read the original abstract
Deployed large reasoning models (LRMs) often behave unexpectedly. Test-time steering controls LRM outputs by intervening on their hidden representations, but it can degrade output quality. We argue that prior steering work implicitly relies on internal features that detect behavior in already generated text. We show that these detection features are poor predictors of future behavioral outcomes, and thus not the natural intervention target. Instead, we train activation probes to predict future behavior likelihoods from intermediate reasoning steps. These probes predict the most likely behavior with 64%-91% accuracy, revealing a separate type of internal prediction features. Building on these prediction features, we introduce a text-level steering method, Future Probe Controlled Generation. FPCG samples multiple candidate sentences and chooses the best one according to a probe predicting the future behavior likelihood. This enables steering with almost no output quality degradation. FPCG also enables steering in several evaluations where activation steering fails. These results show that distinguishing detection and prediction features enables a more nuanced approach to controlling LRM behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that detection features used in prior test-time steering of large reasoning models (LRMs) are poor predictors of future behaviors, while newly trained activation probes can predict the most likely future behavior from intermediate steps with 64-91% accuracy. It introduces Future Probe Controlled Generation (FPCG), which samples candidate sentences and selects via the probe to steer behavior with minimal quality degradation and in cases where activation steering fails.
Significance. If the empirical distinction between detection and prediction features is robustly demonstrated and FPCG is shown to outperform baselines without hidden costs, the work would clarify the role of internal representations in LRMs and supply a practical text-level steering technique that preserves output quality better than existing activation methods.
major comments (1)
- [Abstract] Abstract: the central motivation asserts that 'these detection features are poor predictors of future behavioral outcomes, and thus not the natural intervention target,' yet no accuracy figures, baselines, or direct comparisons are supplied for any detection probe on the future-prediction task; without this contrast the claim that the new probes reveal a 'separate type' of superior features remains unsupported.
minor comments (2)
- The abstract reports accuracy ranges (64%-91%) and qualitative improvements but supplies no dataset details, number of models evaluated, statistical tests, or ablation results; these must be added to the main text with explicit baselines for the future-prediction task.
- Clarify how future-behavior labels are obtained for probe training and whether the same labeled data is used to evaluate detection probes, to allow readers to assess the reported separation.
Simulated Author's Rebuttal
We thank the referee for the careful review and the opportunity to clarify the presentation of our central claim. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central motivation asserts that 'these detection features are poor predictors of future behavioral outcomes, and thus not the natural intervention target,' yet no accuracy figures, baselines, or direct comparisons are supplied for any detection probe on the future-prediction task; without this contrast the claim that the new probes reveal a 'separate type' of superior features remains unsupported.
Authors: We agree that the abstract, as currently written, does not supply the quantitative contrast that would make the motivation self-contained. The main text does contain the relevant experiments: detection probes (trained on already-generated text) achieve substantially lower accuracy when evaluated on the future-behavior prediction task than the newly trained prediction probes (64-91%). To make this distinction explicit at the level of the abstract and to directly support the claim of a 'separate type' of features, we will revise the abstract to include a concise statement of the accuracy ranges for both classes of probes together with the direct comparison on the future-prediction task. revision: yes
Circularity Check
No circularity; empirical training and evaluation
full rationale
The paper's core contributions consist of training activation probes on labeled data to predict future behavior likelihoods from intermediate reasoning steps, reporting empirical accuracies of 64%-91%, and introducing FPCG as a sampling-based steering method that uses these probes. These steps are standard supervised learning and experimental evaluation; no derivation chain reduces a claimed prediction or first-principles result to its own inputs by construction. No self-definitional equations, fitted parameters renamed as independent predictions, or load-bearing self-citations appear in the abstract or described claims. The work is self-contained against external benchmarks via reported accuracies and steering outcomes.
Axiom & Free-Parameter Ledger
free parameters (1)
- activation probe parameters
axioms (1)
- domain assumption Hidden representations in large reasoning models contain information about future behavioral outcomes
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Causality and Large Models @NeurIPS 2024 , year=
Counterfactual Token Generation in Large Language Models , author=. Causality and Large Models @NeurIPS 2024 , year=
2024
-
[5]
The Thirteenth International Conference on Learning Representations , year=
Gumbel Counterfactual Generation From Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
International Conference on Learning Representations , year=
Woulda, Coulda, Shoulda: Counterfactually-Guided Policy Search , author=. International Conference on Learning Representations , year=
-
[7]
2023 , eprint=
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
2023
-
[8]
2025 , eprint=
Control Illusion: The Failure of Instruction Hierarchies in Large Language Models , author=. 2025 , eprint=
2025
-
[9]
2024 , eprint=
Can LLMs Follow Simple Rules? , author=. 2024 , eprint=
2024
-
[10]
2025 , eprint=
Measuring AI Ability to Complete Long Tasks , author=. 2025 , eprint=
2025
-
[11]
Prompt Injection attack against
Yi Liu and Gelei Deng and Yuekang Li and Kailong Wang and Zihao Wang and Xiaofeng Wang and Tianwei Zhang and Yepang Liu and Haoyu Wang and Yan Zheng and Yang Liu , year=. Prompt Injection attack against
-
[12]
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , title =
-
[13]
Ignore Previous Prompt: Attack Techniques For Language Models , author=
-
[14]
The instruction hierarchy: Training
Wallace, Eric and Xiao, Kai and Leike, Reimar and Weng, Lilian and Heidecke, Johannes and Beutel, Alex , journal=. The instruction hierarchy: Training
-
[15]
Foundational Challenges in Assuring Alignment and Safety of Large Language Models , author=
-
[16]
Multi-property Steering of Large Language Models with Dynamic Activation Composition
Scalena, Daniel and Sarti, Gabriele and Nissim, Malvina. Multi-property Steering of Large Language Models with Dynamic Activation Composition. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2024. doi:10.18653/v1/2024.blackboxnlp-1.34
-
[17]
Better & faster large language models via multi-token prediction , year =
Gloeckle, Fabian and Idrissi, Badr Youbi and Rozi\`. Better & faster large language models via multi-token prediction , year =. Proceedings of the 41st International Conference on Machine Learning , articleno =
-
[18]
Accelerating Transformer Inference for Translation via Parallel Decoding
Santilli, Andrea and Severino, Silvio and Postolache, Emilian and Maiorca, Valentino and Mancusi, Michele and Marin, Riccardo and Rodola, Emanuele. Accelerating Transformer Inference for Translation via Parallel Decoding. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/...
-
[19]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Evidence of Learned Look-Ahead in a Chess-Playing Neural Network , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[20]
The Thirteenth International Conference on Learning Representations , year=
Interpreting Emergent Planning in Model-Free Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[21]
Lindsey, Jack and Gurnee, Wes and Ameisen, Emmanuel and Chen, Brian and Pearce, Adam and Turner, Nicholas L. and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[22]
Competition of Mechanisms: Tracing How Language Models Handle Facts and Counterfactuals
Ortu, Francesco and Jin, Zhijing and Doimo, Diego and Sachan, Mrinmaya and Cazzaniga, Alberto and Sch. Competition of Mechanisms: Tracing How Language Models Handle Facts and Counterfactuals. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[23]
ICML , crossref=
Reduan Achtibat and Sayed Mohammad Vakilzadeh Hatefi and Maximilian Dreyer and Aakriti Jain and Thomas Wiegand and Sebastian Lapuschkin and Wojciech Samek , title=. ICML , crossref=. 2024 , cdate=
2024
-
[24]
arXiv preprint arXiv:2403.08319 , year=
Knowledge Conflicts for LLMs: A Survey , author=. arXiv preprint arXiv:2403.08319 , year=
-
[25]
Lampert , booktitle=
Egor Zverev and Evgenii Kortukov and Alexander Panfilov and Soroush Tabesh and Sebastian Lapuschkin and Wojciech Samek and Christoph H. Lampert , booktitle=. 2025 , url=
2025
-
[26]
First Conference on Language Modeling , year=
Studying Large Language Model Behaviors Under Context-Memory Conflicts With Real Documents , author=. First Conference on Language Modeling , year=
-
[27]
2025 , eprint=
The Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation , author=. 2025 , eprint=
2025
-
[28]
2025 , url =
Anthropic , title =. 2025 , url =
2025
-
[29]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[30]
2025 , url =
Meta , title =. 2025 , url =
2025
-
[31]
Mechanistic Interpretability for
Leonard Bereska and Stratis Gavves , journal=. Mechanistic Interpretability for. 2024 , url=
2024
-
[32]
2023 , eprint=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
2023
-
[33]
arXiv preprint arXiv:2503.03750 , year=
The mask benchmark: Disentangling honesty from accuracy in ai systems , author=. arXiv preprint arXiv:2503.03750 , year=
-
[34]
The Twelfth International Conference on Learning Representations , year=
Towards Understanding Sycophancy in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[35]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author=
SycEval: Evaluating LLM Sycophancy , volume=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , author=. 2025 , month=. doi:10.1609/aies.v8i1.36598 , number=
-
[36]
2022 , eprint=
Constitutional AI: Harmlessness from AI Feedback , author=. 2022 , eprint=
2022
-
[37]
arXiv preprint arXiv:2412.04984 , year=
Frontier models are capable of in-context scheming , author=. arXiv preprint arXiv:2412.04984 , year=
-
[38]
2025 , eprint=
LLM-Safety Evaluations Lack Robustness , author=. 2025 , eprint=
2025
-
[39]
The Thirteenth International Conference on Learning Representations , year=
A Probabilistic Perspective on Unlearning and Alignment for Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[40]
and Bau, David , year = 2023, eprint =
Pal, Koyena and Sun, Jiuding and Yuan, Andrew and Wallace, Byron and Bau, David. Future Lens: Anticipating Subsequent Tokens from a Single Hidden State. Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL). 2023. doi:10.18653/v1/2023.conll-1.37
-
[41]
2024 , booktitle=
Do language models plan ahead for future tokens? , author=. 2024 , booktitle=
2024
-
[42]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Park, Kiho and Choe, Yo Joong and Veitch, Victor , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[43]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[44]
arXiv preprint arXiv:2310.08215 , year=
Trustworthy Machine Learning , author=. arXiv preprint arXiv:2310.08215 , year=
-
[45]
2017 , url=
Understanding intermediate layers using linear classifier probes , author=. 2017 , url=
2017
-
[46]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[47]
USENIX Security Symposium , year=
StruQ: Defending against prompt injection with structured queries , author=. USENIX Security Symposium , year=
-
[48]
Instructional Segment Embedding: Improving
Tong Wu and Shujian Zhang and Kaiqiang Song and Silei Xu and Sanqiang Zhao and Ravi Agrawal and Sathish Reddy Indurthi and Chong Xiang and Prateek Mittal and Wenxuan Zhou , booktitle=. Instructional Segment Embedding: Improving. 2025 , url=
2025
-
[49]
Lampert , booktitle=
Egor Zverev and Sahar Abdelnabi and Soroush Tabesh and Mario Fritz and Christoph H. Lampert , booktitle=. Can. 2025 , url=
2025
-
[50]
Strategic Dishonesty Can Undermine
Alexander Panfilov and Evgenii Kortukov and Kristina Nikoli. Strategic Dishonesty Can Undermine. The Fourteenth International Conference on Learning Representations , year=
-
[51]
Blog , year=
Interpretability Can Be Actionable , author=. Blog , year=
-
[52]
Forty-second International Conference on Machine Learning , year=
Detecting Strategic Deception with Linear Probes , author=. Forty-second International Conference on Machine Learning , year=
-
[53]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Refusal in Language Models Is Mediated by a Single Direction , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[54]
Steering llama 2 via contrastive activation addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[55]
2022 , eprint=
Discovering Language Model Behaviors with Model-Written Evaluations , author=. 2022 , eprint=
2022
-
[56]
The Thirteenth International Conference on Learning Representations , year=
SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal , author=. The Thirteenth International Conference on Learning Representations , year=
-
[57]
2026 , url=
Myra Cheng and Sunny Yu and Cinoo Lee and Pranav Khadpe and Lujain Ibrahim and Dan Jurafsky , booktitle=. 2026 , url=
2026
-
[58]
2025 , eprint=
When Chain of Thought is Necessary, Language Models Struggle to Evade Monitors , author=. 2025 , eprint=
2025
-
[59]
The Thirteenth International Conference on Learning Representations , year=
Forking Paths in Neural Text Generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[60]
2025 , eprint=
Thought Anchors: Which LLM Reasoning Steps Matter? , author=. 2025 , eprint=
2025
-
[61]
Bogdan and Senthooran Rajamanoharan and Neel Nanda , booktitle=
Uzay Macar and Paul C. Bogdan and Senthooran Rajamanoharan and Neel Nanda , booktitle=. Thought Branches: Interpreting. 2026 , url=
2026
-
[62]
AxBench: Steering
Zhengxuan Wu and Aryaman Arora and Atticus Geiger and Zheng Wang and Jing Huang and Dan Jurafsky and Christopher D Manning and Christopher Potts , booktitle=. AxBench: Steering. 2025 , url=
2025
-
[63]
2025 , url =
Joschka Braun and Dmitrii Krasheninnikov and Usman Anwar and Robert Kirk and Daniel Tan and David Scott Krueger , title =. 2025 , url =
2025
-
[64]
Workshop on Reasoning and Planning for Large Language Models , year=
Understanding Reasoning in Thinking Language Models via Steering Vectors , author=. Workshop on Reasoning and Planning for Large Language Models , year=
-
[65]
2026 , eprint=
Building Production-Ready Probes For Gemini , author=. 2026 , eprint=
2026
-
[66]
Sycophancy in GPT-4o: What happened and what we’re doing about it , year =
-
[67]
Where the goblins came from , year =
-
[68]
2026 , month = feb, type =
Claude Opus 4.6 System Card , institution =. 2026 , month = feb, type =
2026
-
[69]
2024 , eprint=
Steering Without Side Effects: Improving Post-Deployment Control of Language Models , author=. 2024 , eprint=
2024
-
[70]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[71]
The Fourteenth International Conference on Learning Representations , year=
Latent Planning Emerges with Scale , author=. The Fourteenth International Conference on Learning Representations , year=
-
[72]
Emergent Response Planning in
Zhichen Dong and Zhanhui Zhou and Zhixuan Liu and Chao Yang and Chaochao Lu , booktitle=. Emergent Response Planning in. 2025 , url=
2025
-
[73]
2025 , eprint=
Persona Vectors: Monitoring and Controlling Character Traits in Language Models , author=. 2025 , eprint=
2025
-
[74]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[75]
Aayush Mishra and Daniel Khashabi and Anqi Liu , booktitle=. Steered. 2026 , url=
2026
-
[76]
Distributed Representations of Words and Phrases and their Compositionality , url =
Mikolov, Tomas and Sutskever, Ilya and Chen, Kai and Corrado, Greg S and Dean, Jeff , booktitle =. Distributed Representations of Words and Phrases and their Compositionality , url =
-
[77]
Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings , url =
Bolukbasi, Tolga and Chang, Kai-Wei and Zou, James and Saligrama, Venkatesh and Kalai, Adam T , booktitle =. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings , url =
-
[78]
Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (
Kim, Been and Wattenberg, Martin and Gilmer, Justin and Cai, Carrie and Wexler, James and Viegas, Fernanda and sayres, Rory , booktitle =. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (. 2018 , editor =
2018
-
[79]
2026 , eprint=
From Weights to Activations: Is Steering the Next Frontier of Adaptation? , author=. 2026 , eprint=
2026
-
[80]
International Conference on Learning Representations , year=
Plug and Play Language Models: A Simple Approach to Controlled Text Generation , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.