MoGeFlow: Flowing Through Motion Codebook Geometry for Text-to-Motion Generation
Pith reviewed 2026-06-27 07:46 UTC · model grok-4.3
The pith
Motion codebooks carry decoder-causal geometry that supports continuous flow generation for text-to-motion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
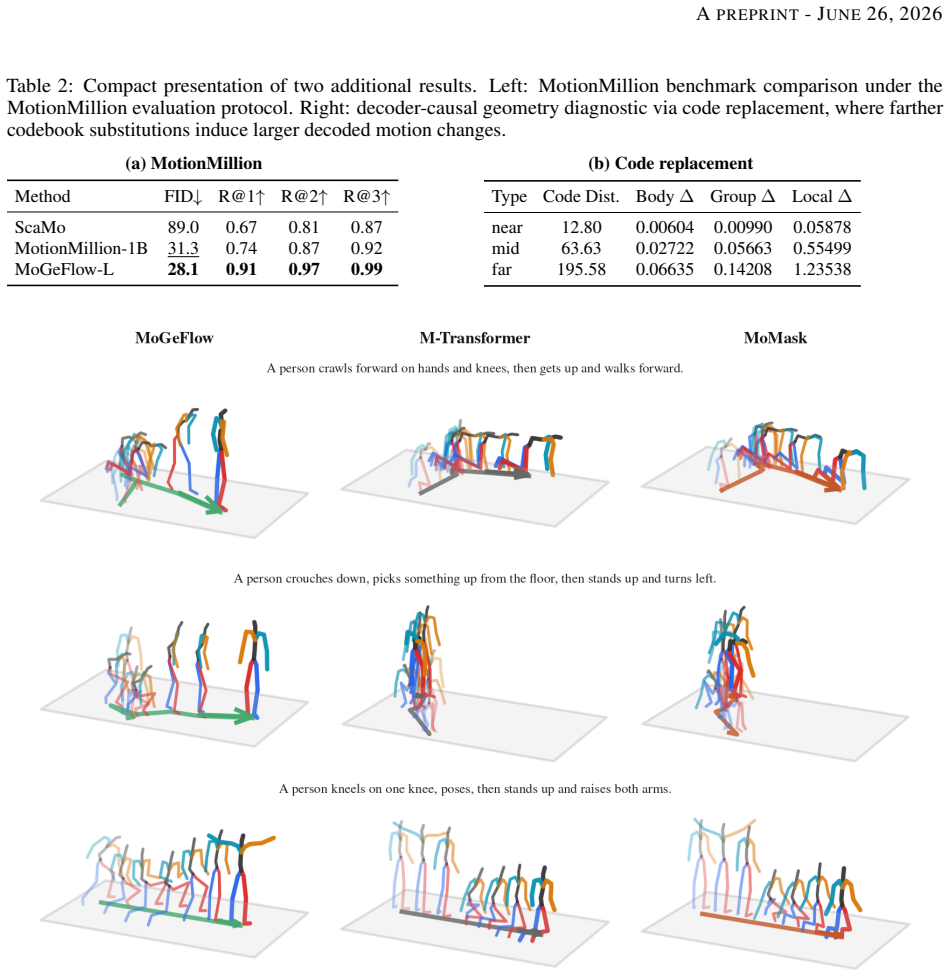
Motion codebooks exhibit measurable, non-random, and decoder-causal geometry. Representing each motion-code frame as a structured set of PartVQ group-specific code embeddings, learning a text-conditioned continuous flow over these frame states, and projecting terminal states back to valid motion codes for frozen decoding yields state-of-the-art text-to-motion results while preserving the compactness and validity of discrete tokenization.
What carries the argument
Text-conditioned continuous flow over structured PartVQ group-specific code embeddings, which replaces categorical code prediction with geometry-aware generation in codebook space.
If this is right
- State-of-the-art R-Precision scores on HumanML3D and KIT-ML.
- Best HumanML3D MultiModal Distance and KIT-ML FID among generated methods.
- Best MotionMillion R@1, R@2, R@3, and FID under the benchmark protocol.
- Generation retains the compactness and validity of discrete motion codes.
Where Pith is reading between the lines
- If codebook geometry is decoder-causal in other domains, flow-based generation could replace index prediction for images or audio as well.
- Continuous flows in embedding space could enable smooth interpolation between motions without additional training.
- Leveraging the geometry might allow smaller codebooks while maintaining output quality.
Load-bearing premise
The observed alignment between code distances and decoded motion distances is decoder-causal and general enough that flowing through the embeddings produces valid motions for new text prompts.
What would settle it
Generating motions by flowing from held-out text prompts to new embedding points and finding that the decoded results are invalid or low-quality would falsify the claim that the geometry supports reliable generation.
Figures

read the original abstract
Vector-quantized motion tokenizers provide a compact discrete interface for text-to-motion generation, but most motion-code priors treat code indices as unordered categorical labels. This view overlooks a key property of motion codes: they are decoder-bound prototypes of physical movement, and their learned codebooks can carry meaningful local kinematic geometry. We verify this property through codebook diagnostics. Distances between learned PartVQ group-specific codes align with local motion-prototype distances, shuffled controls remove this alignment, and replacing codes with progressively farther neighbors induces monotonically larger decoded motion changes. These results show that motion codebooks exhibit measurable, non-random, and decoder-causal geometry. Based on this observation, we propose \textbf{MoGeFlow}, a text-to-motion model that generates through motion codebook geometry. MoGeFlow represents each motion-code frame as a structured set of PartVQ group-specific code embeddings, learns a text-conditioned continuous flow over these frame states, and projects terminal states back to valid motion codes for frozen decoding. This preserves the compactness and validity of discrete tokenization while replacing categorical code prediction with geometry-aware codebook-space generation. Experiments set new state of the art in R-Precision on HumanML3D and KIT-ML, achieve the best HumanML3D MultiModal Distance and KIT-ML FID among generated methods, and obtain the best MotionMillion R@1, R@2, R@3, and FID under the benchmark protocol.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that motion codebooks from PartVQ tokenizers exhibit measurable, non-random, decoder-causal geometry, verified via code-distance alignment with decoded motion distances, removal of alignment under shuffling, and monotonic decoded-motion changes under neighbor replacement. Building on this, MoGeFlow represents each frame as a structured set of PartVQ group-specific embeddings, learns a text-conditioned continuous flow over these states, and projects terminal states back to valid discrete codes for frozen decoding. This yields new state-of-the-art R-Precision on HumanML3D and KIT-ML, best MultiModal Distance and FID among generated methods on those datasets, and best R@1/R@2/R@3/FID on MotionMillion under the benchmark protocol.
Significance. If the geometry diagnostics and flow results hold, the work shows that decoder-bound prototypes in motion codebooks carry exploitable local kinematic structure, enabling continuous generation that preserves discrete validity and outperforms categorical baselines. The explicit diagnostics (alignment, shuffled controls, neighbor monotonicity) supply concrete, falsifiable support for the geometry claim. Reported benchmark gains across three datasets, obtained while projecting back to valid codes, indicate a practical advantage for hybrid discrete-continuous motion synthesis. The reproducible diagnostic protocol and consistent cross-dataset improvements are notable strengths.
major comments (2)
- [Diagnostics section] Diagnostics section: the claim that code distances align with motion-prototype distances is central to the decoder-causal geometry argument, yet the manuscript provides no correlation coefficients, explained-variance values, or statistical tests comparing real vs. shuffled controls; without these quantities the strength of the alignment cannot be assessed quantitatively.
- [Method section] Method section: the text-conditioned flow is described at a high level but the precise objective (e.g., the form of the velocity field or the loss used to train the flow) is not stated; because the flow operates inside the verified embedding geometry, the missing formulation is load-bearing for reproducing the claimed geometry-aware generation.
minor comments (3)
- [Abstract] Abstract and §1: the acronym PartVQ is used without an inline definition or reference to its original formulation; a one-sentence gloss would improve accessibility.
- [Experiments] Experiments: tables reporting R-Precision, FID, and MultiModal Distance would benefit from explicit indication of which metrics are computed on generated vs. ground-truth motions and whether standard deviations across seeds are provided.
- [Figures] Figure captions: several diagnostic plots lack axis labels or legends clarifying what the shuffled-control curves represent; this reduces immediate interpretability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. The two major comments identify opportunities to strengthen the quantitative support for the geometry diagnostics and to improve reproducibility of the flow model. We address each point below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Diagnostics section] Diagnostics section: the claim that code distances align with motion-prototype distances is central to the decoder-causal geometry argument, yet the manuscript provides no correlation coefficients, explained-variance values, or statistical tests comparing real vs. shuffled controls; without these quantities the strength of the alignment cannot be assessed quantitatively.
Authors: We agree that correlation coefficients, explained-variance values, and statistical tests comparing real versus shuffled controls would allow a more rigorous quantitative assessment of the alignment. In the revised manuscript we will add these measures (Pearson/Spearman correlations, R^{2} values, and appropriate significance tests) to the Diagnostics section for both the observed codebook geometry and the shuffled controls. revision: yes
-
Referee: [Method section] Method section: the text-conditioned flow is described at a high level but the precise objective (e.g., the form of the velocity field or the loss used to train the flow) is not stated; because the flow operates inside the verified embedding geometry, the missing formulation is load-bearing for reproducing the claimed geometry-aware generation.
Authors: We acknowledge that the precise velocity-field parameterization and training objective are necessary for full reproducibility. In the revised Method section we will explicitly state the continuous normalizing flow formulation, the velocity-field network architecture, and the exact training loss (including any conditioning and regularization terms) used to learn the text-conditioned flow over the PartVQ embeddings. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper first performs independent diagnostics on a pre-trained PartVQ codebook (code-distance alignment with decoded motion distances, shuffled controls, and monotonicity under neighbor replacement) to establish decoder-causal geometry. These measurements are external to the proposed model. MoGeFlow then constructs a text-conditioned flow in the verified embedding space and projects terminal states back to discrete codes for frozen decoding. Training and evaluation use standard text-to-motion benchmarks with no reduction of the flow objective or reported metrics to quantities fitted from the same diagnostic data. No self-citations, ansatzes, or uniqueness claims are load-bearing, and the central claim remains independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Learned PartVQ codebooks carry measurable local kinematic geometry that is decoder-causal
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
Human Motion Diffusion Model , author =. International Conference on Learning Representations , year =
-
[2]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2024 , doi =
2024
-
[3]
Advances in Neural Information Processing Systems , volume =
Neural Discrete Representation Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
MoMask: Generative Masked Modeling of 3D Human Motions , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[6]
Advances in Neural Information Processing Systems , volume =
MotionGPT: Human Motion as a Foreign Language , author =. Advances in Neural Information Processing Systems , volume =
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
MOGO: Residual Quantized Hierarchical Causal Transformer for Real-Time and Infinite-Length 3D Human Motion Generation , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2026 , doi =
2026
-
[8]
arXiv preprint arXiv:2605.10938 , year =
ELF: Embedded Language Flows , author =. arXiv preprint arXiv:2605.10938 , year =. 2605.10938 , archivePrefix =
-
[9]
International Conference on Learning Representations , year =
Flow Matching for Generative Modeling , author =. International Conference on Learning Representations , year =
-
[10]
arXiv preprint arXiv:2511.18209 , year =
MotionDuet: Dual-Conditioned 3D Human Motion Generation with Video-Regularized Text Learning , author =. arXiv preprint arXiv:2511.18209 , year =. 2511.18209 , archivePrefix =
-
[11]
arXiv preprint arXiv:2605.14731 , year =
UMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars , author =. arXiv preprint arXiv:2605.14731 , year =. 2605.14731 , archivePrefix =
-
[12]
arXiv preprint arXiv:2605.14716 , year =
AnchorRoute: Human Motion Synthesis with Interval-Routed Sparse Control , author =. arXiv preprint arXiv:2605.14716 , year =. 2605.14716 , archivePrefix =
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Generating Diverse and Natural 3D Human Motions from Text , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[14]
European Conference on Computer Vision , pages =
ParCo: Part-Coordinating Text-to-Motion Synthesis , author =. European Conference on Computer Vision , pages =. 2024 , organization =
2024
-
[15]
arXiv preprint arXiv:2604.11083 , year =
FlowCoMotion: Text-to-Motion Generation via Token-Latent Flow Modeling , author =. arXiv preprint arXiv:2604.11083 , year =. 2604.11083 , archivePrefix =
-
[16]
arXiv preprint arXiv:2604.23264 , year =
MotionHiFlow: Text-to-motion via hierarchical flow matching , author =. arXiv preprint arXiv:2604.23264 , year =. 2604.23264 , archivePrefix =
-
[17]
arXiv preprint arXiv:2606.05624 , year=
KV-Control: Parameter-Efficient K/V Injection for Trajectory-Controlled Text-to-Motion , author=. arXiv preprint arXiv:2606.05624 , year=
-
[18]
European Conference on Computer Vision , pages=
TEMOS: Generating Diverse Human Motions from Textual Descriptions , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[19]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[20]
European Conference on Computer Vision , year=
BAMM: Bidirectional Autoregressive Motion Model , author=. European Conference on Computer Vision , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
MoGenTS: Motion Generation Based on Spatial-Temporal Joint Modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Light-T2M: A Lightweight and Fast Model for Text-to-Motion Generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2025 , doi=
2025
-
[23]
arXiv preprint arXiv:2512.10730 , year=
IRG-MotionLLM: Interleaving Motion Generation, Assessment and Refinement for Text-to-Motion Generation , author=. arXiv preprint arXiv:2512.10730 , year=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
EnergyMoGen: Compositional Human Motion Generation with Energy-Based Diffusion Model in Latent Space , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
SALAD: Skeleton-Aware Latent Diffusion for Text-Driven Motion Generation and Editing , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
arXiv preprint arXiv:2507.09122 , year=
SnapMoGen: Human Motion Generation from Expressive Texts , author=. arXiv preprint arXiv:2507.09122 , year=
-
[27]
Big Data , volume=
The KIT Motion-Language Dataset , author=. Big Data , volume=. 2016 , publisher=
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.